
Il existe de nombreux articles expliquant à quoi sert le Python GIL (The Global Interpreter Lock) (je veux dire CPython). En bref, le GIL empêche le code Python propre multithread d'utiliser plusieurs cœurs de processeur.
Cependant, chez Vaex, nous effectuons la plupart des tâches intensives en calcul en C ++ avec le GIL désactivé. C'est une pratique normale pour les bibliothèques Python hautes performances, où Python n'agit que comme une colle de haut niveau.
Le GIL doit être désactivé explicitement, et c'est la responsabilité du programmeur, qu'il peut oublier, ce qui conduira à une utilisation inefficace de la capacité. Récemment, j'ai moi-même été dans le rôle de l'oubli et j'ai trouvé un problème similaire dans Apache Arrow(il s'agit d'une dépendance Vaex, donc lorsque le GIL n'est pas désactivé dans Arrow, nous (et tout le monde) subissons un impact sur les performances).
De plus, lors de l'exécution sur 64 cœurs, les performances Vaex sont parfois loin d'être idéales. Il peut utiliser 4000% du processeur au lieu de 6400%, ce qui ne me convient pas. Au lieu d'insérer au hasard des commutateurs pour étudier cet effet, je veux comprendre ce qui se passe, et si le problème est dans le GIL, alors je veux comprendre pourquoi et comment cela ralentit Vaex.
Pourquoi est-ce que j'écris ceci
Je prévois d'écrire une série d'articles couvrant certains des outils et techniques de profilage et de traçage de Python avec des extensions natives, et comment ces outils peuvent être combinés pour analyser et visualiser les performances de Python avec le GIL activé et désactivé.
Espérons que cela aidera à améliorer le traçage, le profilage et d'autres mesures de performances dans l'écosystème du langage, ainsi que les performances de l'ensemble de l'écosystème Python.
Exigences
Linux
Vous avez besoin d'un accès root à la machine Linux (sudo suffit). Ou demandez à votre administrateur système d'exécuter les commandes ci-dessous pour vous. Pour le reste de cet article, les privilèges utilisateur sont suffisants.
Perf
Assurez-vous que perf est installé, par exemple, sur Ubuntu, vous pouvez le faire comme ceci:
$ sudo yum install perf
Configuration du noyau
Exécuter en tant qu'utilisateur:
# Enable users to run perf (use at own risk)
$ sudo sysctl kernel.perf_event_paranoid=-1
# Enable users to see schedule trace events:
$ sudo mount -o remount,mode=755 /sys/kernel/debug
$ sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
Paquets Python
Nous utiliserons VizTracer et per4m
$ pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"
Suivi de l'état des threads et des processus avec perf
Il n'y a aucun moyen de comprendre l'état du GIL en Python (autre que d'utiliser l' interrogation ) car il n'y a pas d'API pour cela. Nous pouvons surveiller l'état du noyau, et pour cela nous avons besoin de l'outil perf .
Avec son aide (également appelée perf_events), nous pouvons écouter les changements dans l'état des processus et des threads (nous ne sommes intéressés que par le sommeil et l'exécution) et les consigner. Perf peut sembler intimidant, mais c'est un outil puissant. Si vous voulez en savoir plus, je vous recommande de lire l' article de Julia Evans ou le site de Brendan Gregg .
Pour vous connecter, appliquons d'abord perf à un programme simple :
import time
from threading import Thread
def sleep_a_bit():
time.sleep(1)
def main():
t = Thread(target=sleep_a_bit)
t.start()
t.join()
main()
Nous n'écoutons que quelques événements pour réduire le bruit (notez l'utilisation de jokers):
$ perf record -e sched:sched_switch -e sched:sched_process_fork \
-e 'sched:sched_wak*' -- python -m per4m.example0
[ perf record: Woken up 2 times to write data ]
[ perf record: Captured and wrote 0,032 MB perf.data (33 samples) ]
Et nous utiliserons la commande perf script pour générer un résultat lisible adapté à l'analyse.
Texte masqué
$ perf script
:3040108 3040108 [032] 5563910.979408: sched:sched_waking: comm=perf pid=3040114 prio=120 target_cpu=031
:3040108 3040108 [032] 5563910.979431: sched:sched_wakeup: comm=perf pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563910.995616: sched:sched_waking: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995618: sched:sched_wakeup: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995621: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995622: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995624: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R+ ==> next_comm=kworker/31:1 next_pid=2502104 next_prio=120
python 3040114 [031] 5563911.003612: sched:sched_waking: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.003614: sched:sched_wakeup: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.083609: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083612: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083613: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R ==> next_comm=ksoftirqd/31 next_pid=198 next_prio=120
python 3040114 [031] 5563911.108984: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.109059: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.112250: sched:sched_process_fork: comm=python pid=3040114 child_comm=python child_pid=3040116
python 3040114 [031] 5563911.112260: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112262: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112273: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112418: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112450: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112473: sched:sched_wake_idle_without_ipi: cpu=31
swapper 0 [031] 5563911.112476: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112485: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112485: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112489: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112496: sched:sched_switch: prev_comm=python prev_pid=3040116 prev_prio=120 prev_state=S ==> next_comm=swapper/37 next_pid=0 next_prio=120
swapper 0 [031] 5563911.112497: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
swapper 0 [037] 5563912.113490: sched:sched_waking: comm=python pid=3040116 prio=120 target_cpu=037
swapper 0 [037] 5563912.113529: sched:sched_wakeup: comm=python pid=3040116 prio=120 target_cpu=037
python 3040116 [037] 5563912.113595: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563912.113620: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Jetez un œil à la quatrième colonne (temps en secondes): le programme s'est endormi (une seconde s'est écoulée). Ici, nous voyons l'entrée de l'état de sommeil:
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
Cela signifie que le noyau a changé l'état du thread Python en
S
(= dormant).
Une seconde plus tard, le programme s'est réveillé:
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Bien sûr, pour comprendre ce qui se passe, vous devrez collecter les outils. Oui, le résultat peut également être facilement analysé à l'aide de per4m , mais avant de continuer, je souhaite visualiser le flux d'un programme légèrement plus complexe à l' aide de VizTracer .
VizTracer
C'est un traceur Python capable de visualiser le travail qu'un programme est en train de faire dans un navigateur. Appliquons-le à un programme plus complexe :
import threading
import time
def some_computation():
total = 0
for i in range(1_000_000):
total += i
return total
def main():
thread1 = threading.Thread(target=some_computation)
thread2 = threading.Thread(target=some_computation)
thread1.start()
thread2.start()
time.sleep(0.2)
for thread in [thread1, thread2]:
thread.join()
main()
Le résultat de l'opération de traceur:
$ viztracer -o example1.html --ignore_frozen -m per4m.example1 Loading finish Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ... Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB Generating HTML report Report saved.
Voici à quoi ressemble le HTML résultant:
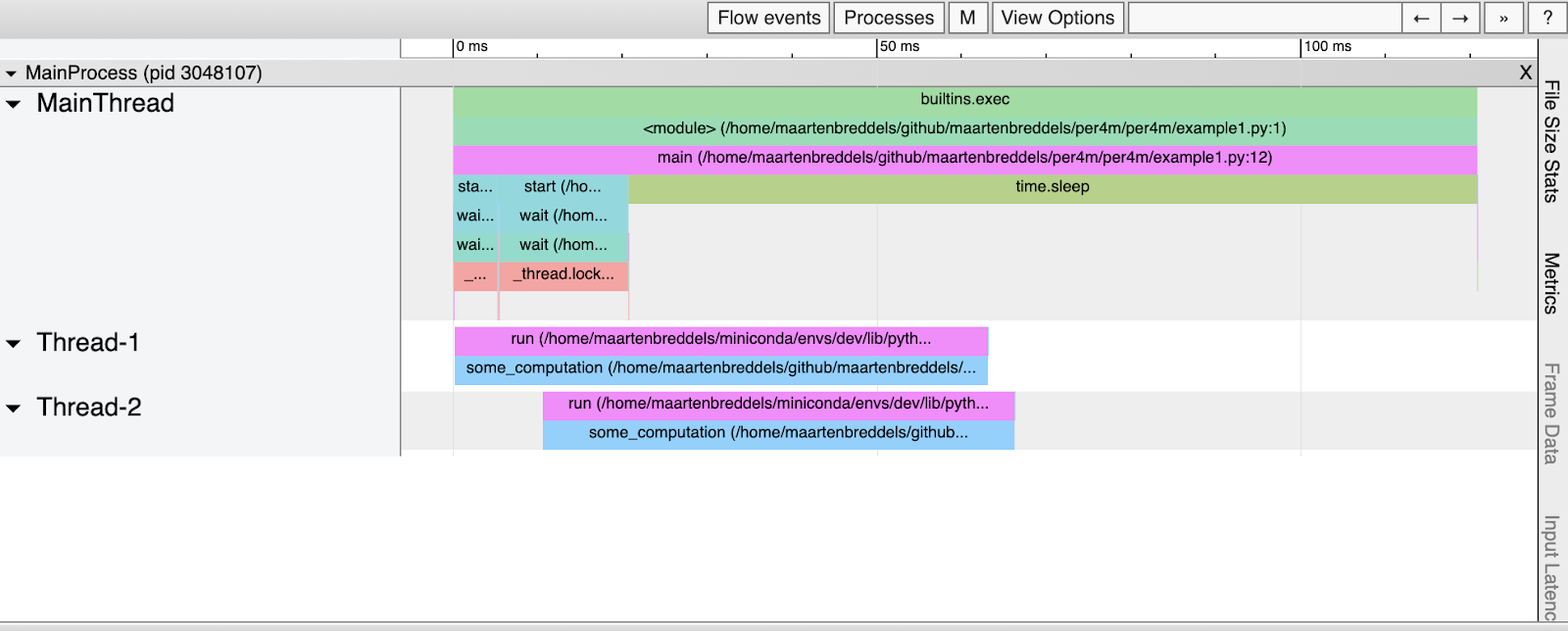
Il semble avoir été
some_computation
exécuté en parallèle (deux fois), bien que nous sachions que le GIL l'empêche. Que se passe t-il ici?
Combinaison de VizTracer et de résultats de perf
Appliquons perf comme dans example0.py. Seulement maintenant, ajoutons un argument
-k CLOCK_MONOTONIC
pour utiliser la même horloge que VizTracer et lui demandons de générer du JSON au lieu de HTML:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' \
-k CLOCK_MONOTONIC -- viztracer -o viztracer1.json --ignore_frozen -m per4m.example1
Nous utilisons ensuite per4m pour convertir les résultats du script perf en JSON que VizTracer peut lire:
$ perf script | per4m perf2trace sched -o perf1.json
Wrote to perf1.json
Maintenant, en utilisant VizTracer, combinons les deux fichiers JSON:
$ viztracer --combine perf1.json viztracer1.json -o example1_state.html Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ... Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB Generating HTML report Report saved.
Voici ce que nous avons:
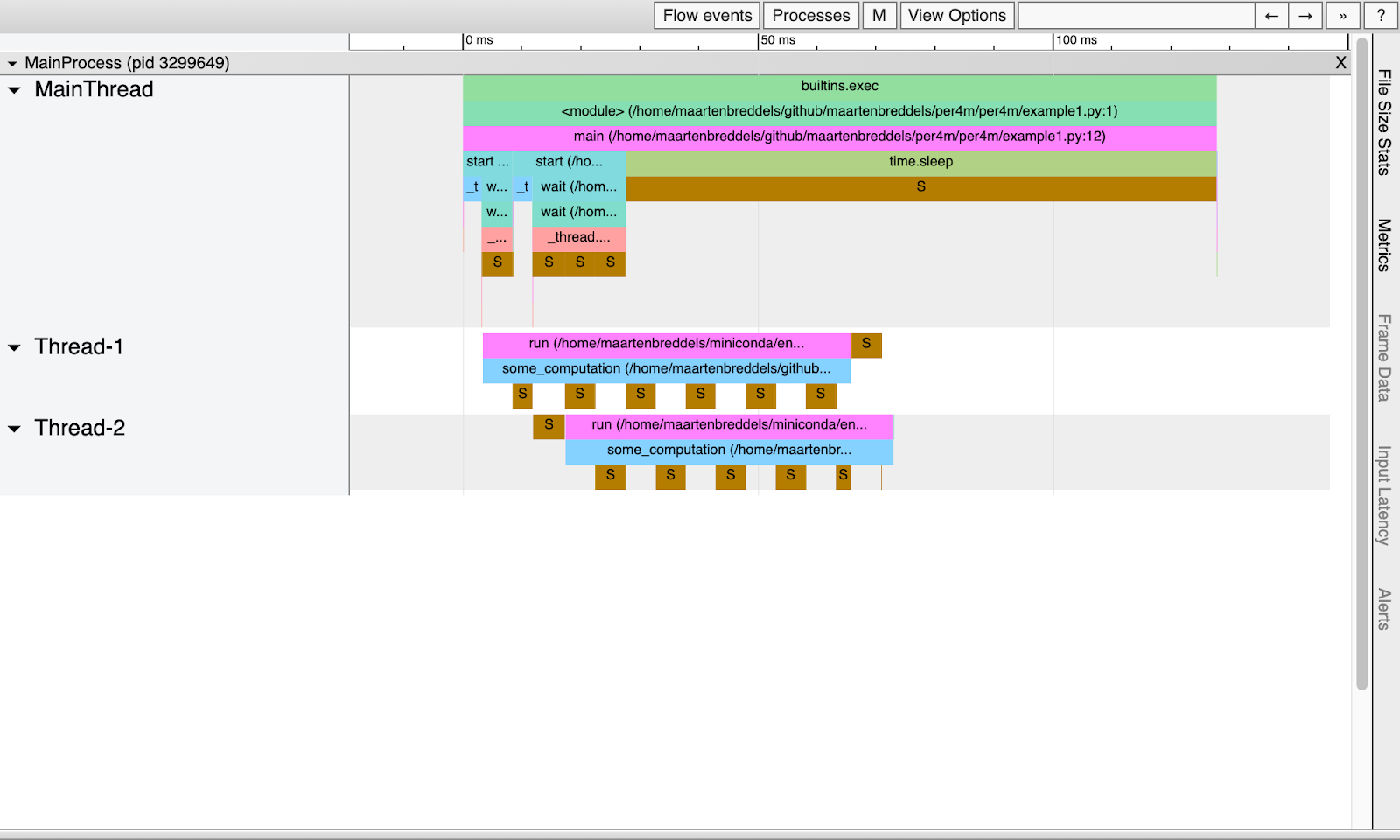
De toute évidence, les threads dorment régulièrement à cause du GIL et ne fonctionnent pas en parallèle.
Remarque : la phase de veille dure environ 5 ms, ce qui correspond à l' intervalle par défaut sys.getswitchinterval
Définition GIL
Notre processus s'endort, mais nous ne voyons pas la différence entre les états de sommeil qui sont initiés par un appel
time.sleep
ou le GIL. Il y a plusieurs façons de faire la différence, regardons-en deux.
À travers la trace de la pile
Avec de l'aide
perf record -g
(ou mieux avec
perf record --call-graph dwarf
, cela implique
-g
), nous obtenons les traces de pile pour chaque événement perf.
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*'\
-k CLOCK_MONOTONIC --call-graph dwarf -- viztracer -o viztracer1-gil.json --ignore_frozen -m per4m.example1
Loading finish
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/viztracer1-gil.json ...
Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB
Report saved.
[ perf record: Woken up 3 times to write data ]
[ perf record: Captured and wrote 0,991 MB perf.data (164 samples) ]
En regardant le résultat du script perf (que nous avons ajouté pour des raisons de performances
--no-inline
), nous obtenons beaucoup d'informations. Regardez l'événement de changement d'état, il s'avère que take_gil a été appelé !
Texte masqué
$ perf script --no-inline | less
...
viztracer 3306851 [059] 5614683.022539: sched:sched_switch: prev_comm=viztracer prev_pid=3306851 prev_prio=120 prev_state=S ==> next_comm=swapper/59 next_pid=0 next_prio=120
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4b92 schedule+0x42 ([kernel.kallsyms])
ffffffff9654a51b futex_wait_queue_me+0xbb ([kernel.kallsyms])
ffffffff9654ac85 futex_wait+0x105 ([kernel.kallsyms])
ffffffff9654daff do_futex+0x10f ([kernel.kallsyms])
ffffffff9654dfef __x64_sys_futex+0x13f ([kernel.kallsyms])
ffffffff964044c7 do_syscall_64+0x57 ([kernel.kallsyms])
ffffffff9700008c entry_SYSCALL_64_after_hwframe+0x44 ([kernel.kallsyms])
7f4884b977b1<a href="https://www.maartenbreddels.com/cdn-cgi/l/email-protection"> [email protected]@GLIBC_2.3.2+0x271 (/usr/lib/x86_64-linux-gnu/libpthread-2.31.so)
55595c07fe6d take_gil+0x1ad (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfaa0b3 PyEval_RestoreThread+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c000872 lock_PyThread_acquire_lock+0x1d2 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe71f3 _PyMethodDef_RawFastCallKeywords+0x263 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d657 call_function+0x3b7 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c074e5d builtin_exec+0x33d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7078 _PyMethodDef_RawFastCallKeywords+0xe8 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c066c39 _PyEval_EvalFrameDefault+0x6549 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb77e0 _PyEval_EvalCodeWithName+0xc80 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b62 _PyFunction_FastCallKeywords+0x582 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb81e2 PyEval_EvalCode+0x22 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0c51d1 run_mod+0x31 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf31d PyRun_FileExFlags+0x9d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf50a PyRun_SimpleFileExFlags+0x1ba (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d05f0 pymain_main+0x3e0 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d067b _Py_UnixMain+0x3b (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
7f48849bc0b2 __libc_start_main+0xf2 (/usr/lib/x86_64-linux-gnu/libc-2.31.so)
55595c075100 _start+0x28 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
…
Remarque : également appelé
pthread_cond_timedwait
, il est utilisé par https://github.com/sumerc/gilstats.py pour eBPF si vous êtes intéressé par d'autres mutex.
Une autre note : notez qu'il n'y a pas de trace de pile Python ici, mais à la place nous en avons
_PyEval_EvalFrameDefault
plus. À l'avenir, je prévois d'écrire comment insérer une trace de pile.
L'outil de conversion
per4m perf2trace
comprend cela et génère un résultat différent lorsque la trace contient
take_gil
:
$ perf script --no-inline | per4m perf2trace sched -o perf1-gil.json
Wrote to perf1-gil.json
$ viztracer --combine perf1-gil.json viztracer1-gil.json -o example1-gil.html
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ...
Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB
Generating HTML report
Report saved.
On a:
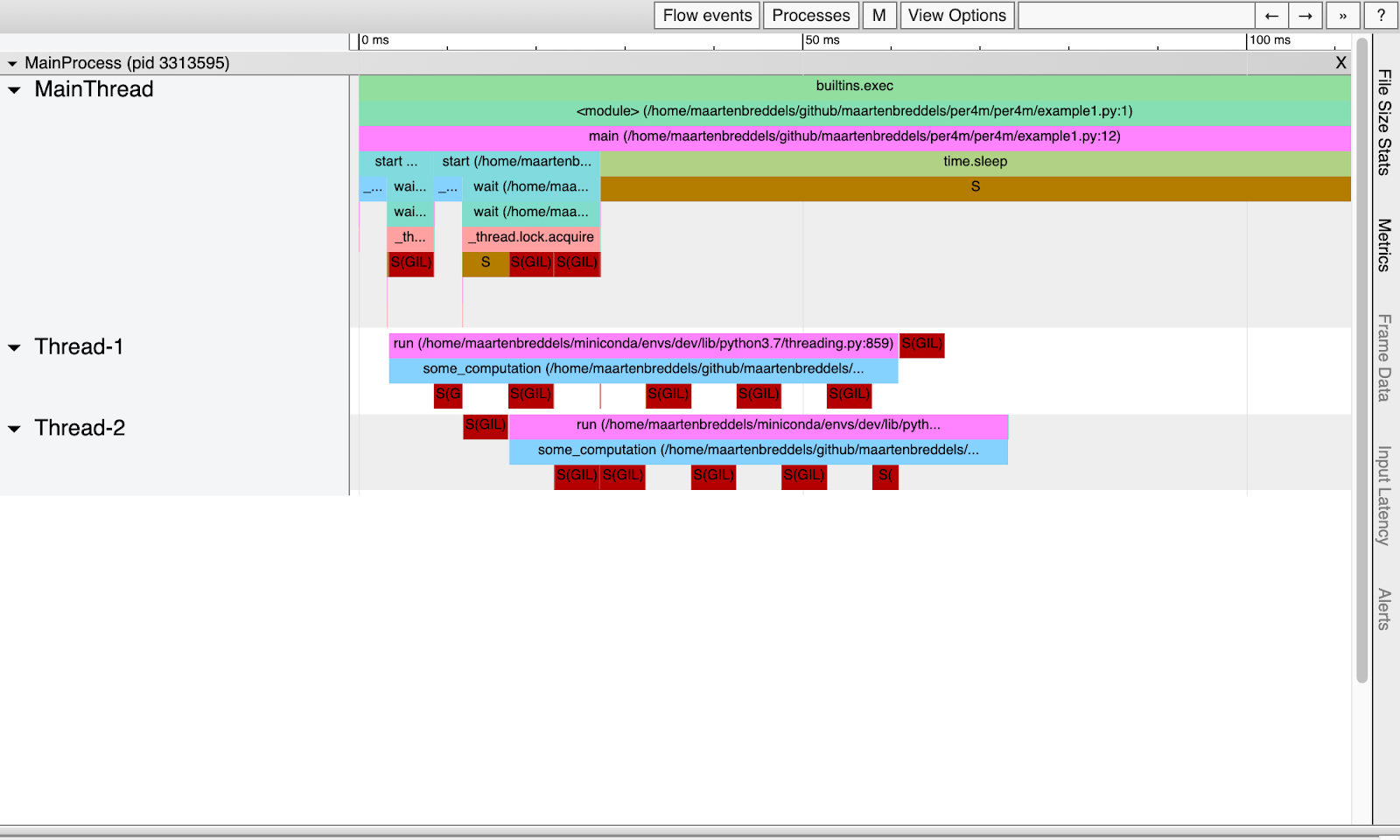
Maintenant, nous pouvons voir exactement où le GIL entre en jeu!
Par sondage (kprobes / uprobes)
Nous savons quand les processus se mettent en veille (en raison du GIL ou pour d'autres raisons), mais si vous voulez en savoir plus sur le moment où le GIL est activé ou désactivé, vous devez savoir quand les résultats sont appelés et renvoyés
take_gil
et
drop_gil
. Cette trace peut être obtenue en sondant avec perf. Dans un environnement utilisateur, les sondes sont des uprobes, qui sont analogues aux kprobes, qui, comme vous l'avez peut-être deviné, fonctionnent dans l'environnement du noyau. Encore une fois, Julia Evans est une excellente source d'informations supplémentaires .
Installez 4 sondes:
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
Added new events:
python:take_gil (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:take_gil_1 (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil_1 -aR sleep 1
Failed to find "take_gil%return",
because take_gil is an inlined function and has no return point.
Added new event:
python:take_gil__return (on take_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil__return -aR sleep 1
Added new events:
python:drop_gil (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:drop_gil_1 (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil_1 -aR sleep 1
Failed to find "drop_gil%return",
because drop_gil is an inlined function and has no return point.
Added new event:
python:drop_gil__return (on drop_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil__return -aR sleep 1
Il y a quelques plaintes, et à cause de celles en ligne
drop_gil
,
take_gil
plusieurs sondes / événements ont été ajoutés (c'est-à-dire que la fonction est présentée plusieurs fois dans le fichier binaire), mais tout fonctionne.
Remarque : j'ai peut-être eu de la chance que mon binaire Python (de conda-forge) ait été compilé afin que le
take_gil
/ correspondant
drop_gil
(et leurs résultats) fonctionne avec succès pour résoudre ce problème.
Veuillez noter que les sondes n'affectent pas les performances, et seulement lorsqu'elles sont "actives" (par exemple, lorsque nous les surveillons à partir de perf), elles exécutent le code sur une branche différente. Pendant la surveillance, les pages affectées sont copiées pour le processus surveillé et les points de contrôle sont insérés aux bons endroits(INT3 pour les processeurs x86). Le point de contrôle déclenche un événement pour perf avec peu de frais généraux. Si vous souhaitez supprimer les sondes, exécutez la commande:
$ sudo perf probe --del 'python*'
Maintenant perf connaît les nouveaux événements qu'il peut écouter, alors réexécutons-le avec un argument supplémentaire
-e 'python:*gil*'
:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' -k CLOCK_MONOTONIC \
-e 'python:*gil*' -- viztracer -o viztracer1-uprobes.json --ignore_frozen -m per4m.example1
Remarque : nous l'avons supprimé
--call-graph dwarf
, sinon perf ne sera pas à temps et nous perdrons des événements.
Ensuite, en utilisant per4m perf2trace, nous le convertissons en JSON, ce qui est compréhensible pour VizTracer, et en même temps nous obtenons de nouvelles statistiques.
$ perf script --no-inline | per4m perf2trace gil -o perf1-uprobes.json
...
Summary of threads:
PID total(us) no gil% has gil% gil wait%
-------- ----------- ----------- ------------ -------------
3353567* 164490.0 65.9 27.3 6.7
3353569 66560.0 0.3 48.2 51.5
3353570 60900.0 0.0 56.4 43.6
High 'no gil' is good, we like low 'has gil',
and we don't want 'gil wait'. (* indicates main thread)
...
Wrote to perf1-uprobes.json
La sous-commande
per4m perf2trace gil
donne également comme résultat gil_load . De là, nous apprenons que les deux threads attendent le GIL environ la moitié du temps, comme prévu.
Avec le même fichier perf.data enregistré par perf, nous pouvons également générer des informations sur l'état d'un thread ou d'un processus. Mais comme nous fonctionnions sans traces de pile, nous ne savons pas si le processus a dormi à cause du GIL ou non.
$ perf script --no-inline | per4m perf2trace sched -o perf1-state.json
Wrote to perf1-state.json
Enfin, mettons les trois résultats ensemble:
$ viztracer --combine perf1-state.json perf1-uprobes.json viztracer1-uprobes.json -o example1-uprobes.html Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1-uprobes.html ... Dumping trace data to json, total entries: 10484, estimated json file size: 1.2MiB Generating HTML report Report saved.
VizTracer donne une bonne idée de qui avait le GIL et qui l'attendait:

Au-dessus de chaque thread est écrit lorsque le thread ou le processus attend le GIL et lorsqu'il est activé (marqué comme LOCK). Notez que ces périodes se chevauchent avec des périodes où le thread ou le processus est éveillé (en cours d'exécution!). Notez également que nous ne voyons qu'un seul thread ou processus en cours d'exécution, comme il se doit à cause du GIL.
Le temps entre les appels
take_gil
, c'est-à-dire entre les verrous (et donc entre dormir ou se réveiller), est exactement le même que dans le tableau ci-dessus dans la colonne gil wait%. La durée d'activation de GIL pour chaque thread, étiquetée LOCK, correspond à l'heure indiquée dans la colonne gil%.
Libérer le Kraken ... ghm, GIL
Nous avons vu comment, lorsqu'un programme Python pur est multithread, le GIL limite les performances en n'autorisant qu'un seul thread ou processus à s'exécuter à la fois (pour un processus Python, bien sûr, et éventuellement dans le futur pour un (sous) interpréteur) . Voyons maintenant ce qui se passe si vous désactivez le GIL, comme cela se produit lors de l'exécution des fonctions NumPy.
Le deuxième exemple s'exécute
some_numpy_computation
qui appelle la fonction NumPy M = 4 fois en parallèle sur deux threads, tandis que le thread principal exécute du code Python pur.
import threading
import time
import numpy as np
N = 1024*1024*32
M = 4
x = np.arange(N, dtype='f8')
def some_numpy_computation():
total = 0
for i in range(M):
total += x.sum()
return total
def main(args=None):
thread1 = threading.Thread(target=some_numpy_computation)
thread2 = threading.Thread(target=some_numpy_computation)
thread1.start()
thread2.start()
total = 0
for i in range(2_000_000):
total += i
for thread in [thread1, thread2]:
thread.join()
main()
Au lieu d'exécuter ce script avec perf et VizTracer, nous utiliserons un utilitaire
per4m giltracer
qui automatise toutes les étapes ci-dessus. Elle le rendra un peu plus intelligent. Fondamentalement, nous allons exécuter perf deux fois, une fois sans trace de pile, et la deuxième fois avec, et importer le module / script avant d'exécuter sa fonction principale pour se débarrasser d'une trace inintéressante comme la même importation. Cela se produira assez rapidement pour que nous ne perdions pas d'événements.
$ giltracer --state-detect -o example2-uprobes.html -m per4m.example2 ...
Totaux des flux:
PID total(us) no gil% has gil% gil wait%
-------- ----------- ----------- ------------ -------------
3373601* 1359990.0 95.8 4.2 0.1
3373683 60276.4 84.6 2.2 13.2
3373684 57324.0 89.2 1.9 8.9
High 'no gil' is good, we like low 'has gil',
and we don't want 'gil wait'. (* indicates main thread)
...
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example2-uprobes.html ...
...
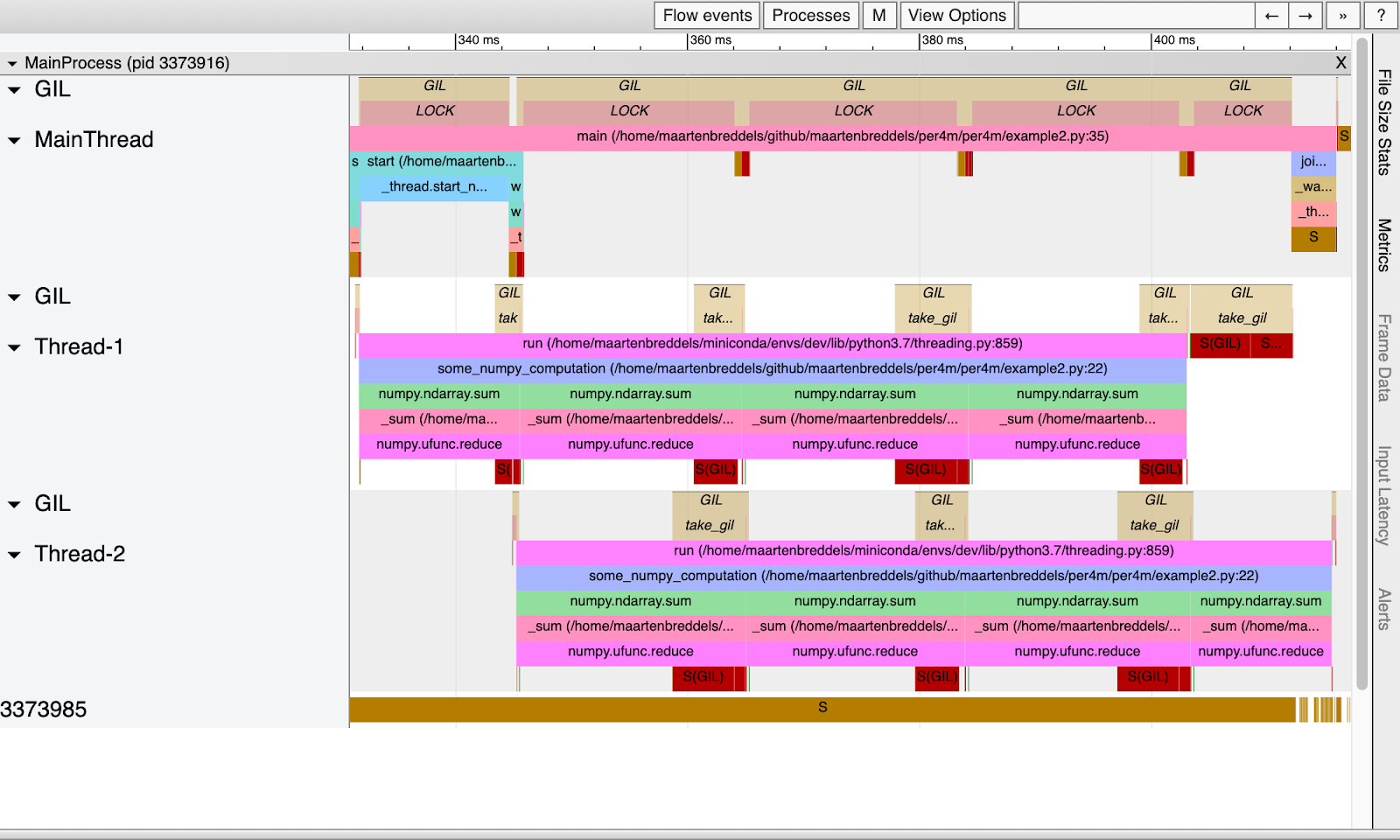
Bien que le thread principal exécute du code Python (GIL est activé pour lui, ce qui est désigné par le mot LOCK), d'autres threads s'exécutent également en parallèle. Notez que dans l'exemple Python pur, nous avons un thread ou un processus en cours d'exécution en même temps. Et ici en fait trois threads sont exécutés en parallèle. Cela est possible car les routines NumPy incluses avec C / C ++ / Fortran ont désactivé le GIL.
Cependant, le GIL affecte toujours les threads, car lorsque la fonction NumPy revient à Python, elle a besoin de récupérer le GIL, comme on le voit dans les longs blocs
take_gil
. Cela prend 10% du temps de chaque thread.
Intégration Jupyter
Étant donné que mon flux de travail implique souvent d'exécuter un MacBook (qui n'exécute pas perf, mais prend en charge dtrace) connecté à une machine Linux à distance, j'utilise le notebook Jupyter pour exécuter du code à distance. Et comme je suis un développeur Jupyter, j'ai dû faire un wrapper avec
cell magic
.
# this registers the giltracer cell magic
%load_ext per4m
%%giltracer
# this call the main define above, but this can also be a multiline code cell
main()
Saving report to /tmp/tmpvi8zw9ut/viztracer.json ...
Dumping trace data to json, total entries: 117, estimated json file size: 13.7KiB
Report saved.
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0,094 MB /tmp/tmpvi8zw9ut/perf.data (244 samples) ]
Wait for perf to finish...
perf script -i /tmp/tmpvi8zw9ut/perf.data --no-inline --ns | per4m perf2trace gil -o /tmp/tmpvi8zw9ut/giltracer.json -q -v
Saving report to /home/maartenbreddels/github/maartenbreddels/fastblog/_notebooks/giltracer.html ...
Dumping trace data to json, total entries: 849, estimated json file size: 99.5KiB
Generating HTML report
Report saved.
Télécharger giltracer.html
Ouvrez giltracer.html dans un nouvel onglet (peut ne pas fonctionner pour des raisons de sécurité)
Conclusion
Avec perf, nous pouvons déterminer les états des processus ou des threads, ce qui aide à comprendre lequel d'entre eux a le GIL activé en Python. Et à l'aide des traces de pile, vous pouvez déterminer que le GIL était la cause du sommeil, et non
time.sleep
, par exemple.
La combinaison des uprobes avec perf vous permet de tracer l'appel et le retour des résultats de fonction
take_gil
et d' obtenir
drop_gil
encore plus d'informations sur l'impact du GIL sur votre programme Python.
Notre travail est facilité par le package expérimental per4m, qui convertit le script perf au format JSON VizTracer, ainsi que certains outils d'orchestration.
Beaucoup de bukaf, n'a pas maîtrisé
Si vous voulez juste voir l'impact du GIL, exécutez ceci une fois:
sudo yum install perf
sudo sysctl kernel.perf_event_paranoid=-1
sudo mount -o remount,mode=755 /sys/kernel/debug
sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"
Exemple d'utilisation:
# module
$ giltracer per4m/example2.py
# script
$ giltracer -m per4m.example2
# add thread/process state detection
$ giltracer --state-detect -m per4m.example2
# without uprobes (in case that fails)
$ giltracer --state-detect --no-gil-detect -m per4m.example2
Plans futurs
J'aurais aimé ne pas avoir à développer ces outils. J'espère avoir pu inspirer quelqu'un à créer de meilleurs produits que les miens. Je veux me concentrer sur l'écriture de code haute performance. Cependant, j'ai de tels projets pour l'avenir:
- Creusez un indicateur de performance dans VizTracer pour examiner les échecs de cache ou les temps d'arrêt du processus.
- Implémentez la trace de pile python dans les traces de performance à combiner avec des outils comme http://www.brendangregg.com/offcpuanalysis.html
- Répétez le même exercice avec dtrace à utiliser sur macOS.
- Détectez automatiquement les fonctions C qui ne désactivent pas le GIL ( https://github.com/vaexio/vaex/pull/1114 , https://github.com/apache/arrow/pull/7756 )
- , https://github.com/h5py/h5py/issues/1516