
Photo de Richard Jacobs sur Unsplash
En novembre 2020, nous avons lancé une migration majeure pour mettre à niveau notre cluster PostgreSQL de 9.6 à 12.4. Dans cet article, je vais vous donner un aperçu rapide de notre architecture chez Coffee Meets Bagel, expliquer comment le temps d'arrêt de la mise à niveau a été réduit à moins de 30 minutes et partager ce que nous avons appris en cours de route.
Architecture
Pour référence: Coffee Meets Bagel est une application de rencontre romantique avec un système de curation. Chaque jour, nos utilisateurs reçoivent un lot limité de candidats de qualité à midi dans leur fuseau horaire. Cela conduit à des modèles de charge hautement prévisibles. Si vous regardez les données de la semaine dernière à partir du moment de la rédaction de l'article, nous obtenons en moyenne 30 000 transactions par seconde, au sommet - jusqu'à 65 000.
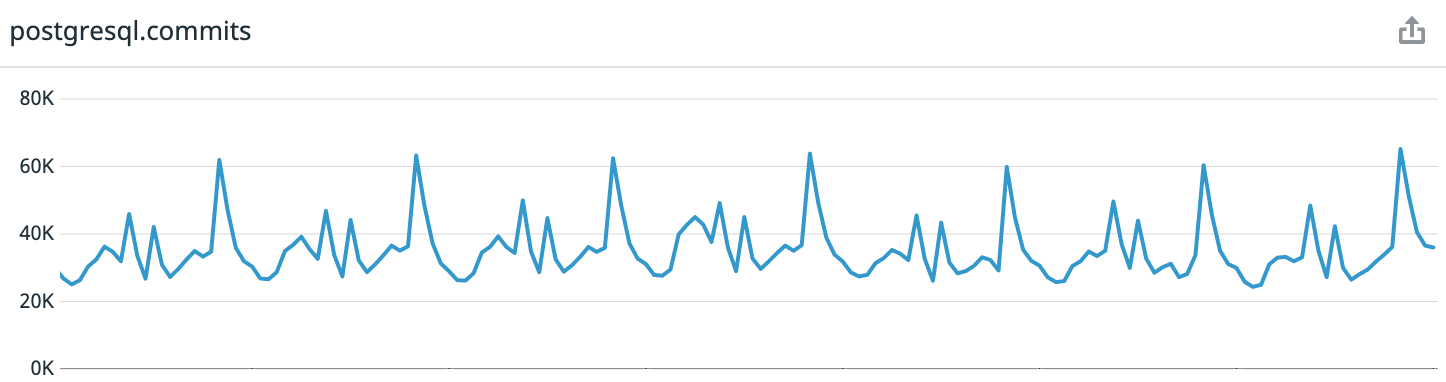
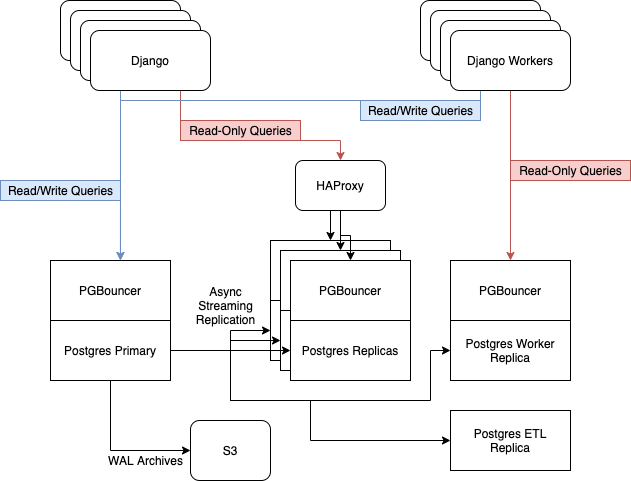
Avant la mise à jour, nous avions 6 serveurs Postgres fonctionnant sur des instances i3.8xlarge sur AWS. Ils contenaient un nœud maître, trois répliques pour servir le trafic Web en lecture seule, équilibré avec HAProxy, un serveur pour les travailleurs asynchrones et un serveur pour ETL [ Extract, Transform, Load ] et Business Intelligence....
Nous comptons sur la réplication en continu intégrée de Postgres pour maintenir notre flotte de répliques à jour.
Raisons de la mise à niveau
Au cours des dernières années, nous avons visiblement ignoré notre couche de données et, par conséquent, elle est légèrement obsolète. Surtout beaucoup de "béquilles" ont été récupérées par notre serveur principal - il est en ligne depuis 3,5 ans. Nous corrigeons diverses bibliothèques et services système sans arrêter le serveur.

Mon candidat pour le subreddit r / uptimeporn
En conséquence, beaucoup de bizarreries se sont accumulées qui vous rendent nerveux. Par exemple, les nouveaux services
systemd
ne sont pas démarrés. J'ai dû configurer le lancement de l'agent
datadog
dans la session
screen
. Parfois, SSH cessait de répondre lorsque la charge du processeur était supérieure à 50% et le serveur lui-même envoyait régulièrement des requêtes de base de données.
Et aussi l'espace libre sur le disque a commencé à approcher des valeurs dangereuses. Comme je l'ai mentionné ci-dessus, Postgres fonctionnait sur des instances i3.8xlarge dans EC2 qui ont 7,6 To de stockage NVMe. Contrairement à EBS, la taille du disque ne peut pas être modifiée dynamiquement ici - ce qui a été initialement prévu le sera. Et nous avons rempli environ 75% du disque. Il est devenu clair que la taille de l'instance devrait être modifiée pour soutenir la croissance future.
Nos exigences
- Temps d'arrêt minimum. Nous nous sommes fixé un objectif de 4 heures de temps d'arrêt total, y compris les pannes imprévues causées par des erreurs de mise à niveau.
- Créez un nouveau cluster de bases de données sur de nouvelles instances pour remplacer le parc actuel de serveurs vieillissants.
- Accédez à i3.16xlarge pour agrandir l'espace.
Nous connaissons trois façons de mettre à niveau Postgres: sauvegarder et restaurer à partir de celui-ci, pg_upgrade et réplication logique pglogical.
Nous avons immédiatement abandonné la première méthode, la restauration à partir d'une sauvegarde: pour notre ensemble de données de 5,7 To, cela prendrait trop de temps. A sa vitesse, pg_upgrade ne répondait pas aux exigences 2 et 3: c'est un outil de migration sur la même machine. Par conséquent, nous avons choisi la réplication logique.
Notre processus
On en a assez écrit sur les principales caractéristiques de pglogical. Par conséquent, au lieu de répéter des vérités communes, je vais simplement donner des articles qui se sont révélés utiles pour moi:
- Mise à niveau de la version majeure avec un temps d'arrêt minimal ;
- Mise à jour de PostgreSQL de 9.4 vers 10.3 avec pglogical ;
- Démystifier pglogical - Tutoriel .
Nous avons créé un nouveau serveur Postgres 12 principal et utilisé pglogical pour synchroniser toutes nos données. Lorsqu'il s'est synchronisé et est passé à répliquer les modifications entrantes, nous avons commencé à lui ajouter des réplicas de streaming. Après avoir configuré la nouvelle réplique de streaming, nous l'avons incluse dans HAProxy et avons supprimé l'une des anciennes versions 9.6.
Ce processus s'est poursuivi jusqu'à l'arrêt complet des serveurs Postgres 9.6, à l'exception du maître. La configuration a pris la forme suivante.

Puis c'est au tour du basculement de cluster (basculement), pour lequel nous avons demandé la fenêtre de maintenance. Le processus de commutation est également bien documenté sur Internet, je ne parlerai donc que des étapes générales:
- Transfert du site en mode travail technique;
- Changer les enregistrements DNS du maître vers un nouveau serveur;
- Synchronisation forcée de toutes les séquences de clés primaires;
- Démarrage manuel du point de contrôle (
CHECKPOINT
) sur l'ancien maître. - Sur le nouvel assistant - exécution de certaines procédures de validation et de test des données;
- Activation du site.
Dans l'ensemble, la transition s'est bien déroulée. Malgré ces changements majeurs dans notre infrastructure, il n'y a pas eu de temps d'arrêt imprévu.
Leçons apprises
Avec le succès global de l'opération, quelques problèmes ont été rencontrés en cours de route. Le pire d'entre eux a failli tuer notre maître Postgres 9.6 ...
Leçon n ° 1: Une synchronisation lente peut être dangereuse
Commençons par un contexte: comment fonctionne la politique? Le processus de l'expéditeur sur le fournisseur (dans ce cas notre ancien assistant 9.6) décode le journal WAL à écriture anticipée, récupère les modifications logiques et les envoie à l'abonné.
Si l'abonné est en retard, le fournisseur stockera les segments WAL de sorte que lorsque l'abonné rattrape, aucune donnée ne soit perdue.
La première fois qu'une table est ajoutée au flux de réplication, pglogical doit d'abord synchroniser les données de la table. Cela se fait avec la commande Postgres
COPY
. Après cela, les segments WAL commencent à s'accumuler sur le fournisseur de sorte que les changements pendant le fonctionnement
COPY
il s'est avéré être transféré à l'abonné après la synchronisation initiale, garantissant ainsi aucune perte de données.
En pratique, cela signifie que lors de la synchronisation d'une table volumineuse sur un système avec une forte charge d'écriture / de modification, vous devez surveiller attentivement l'utilisation du disque. Lors de la première tentative de synchronisation de notre plus grande table (4 To), l'équipe et l'opérateur ont
COPY
travaillé pendant plus d'une journée. Pendant ce temps, le nœud du fournisseur a accumulé plus d'un téraoctet de journaux WAL proactifs.
Comme vous vous en souvenez peut-être d'après ce qui a été dit, nos anciens serveurs de bases de données ne disposaient que de deux téraoctets d'espace disque libre. Nous avons estimé à partir de la plénitude du disque serveur de l'abonné que seul un quart de la table a été copié. Par conséquent, le processus de synchronisation a dû être arrêté immédiatement - le disque sur le maître se serait terminé plus tôt.
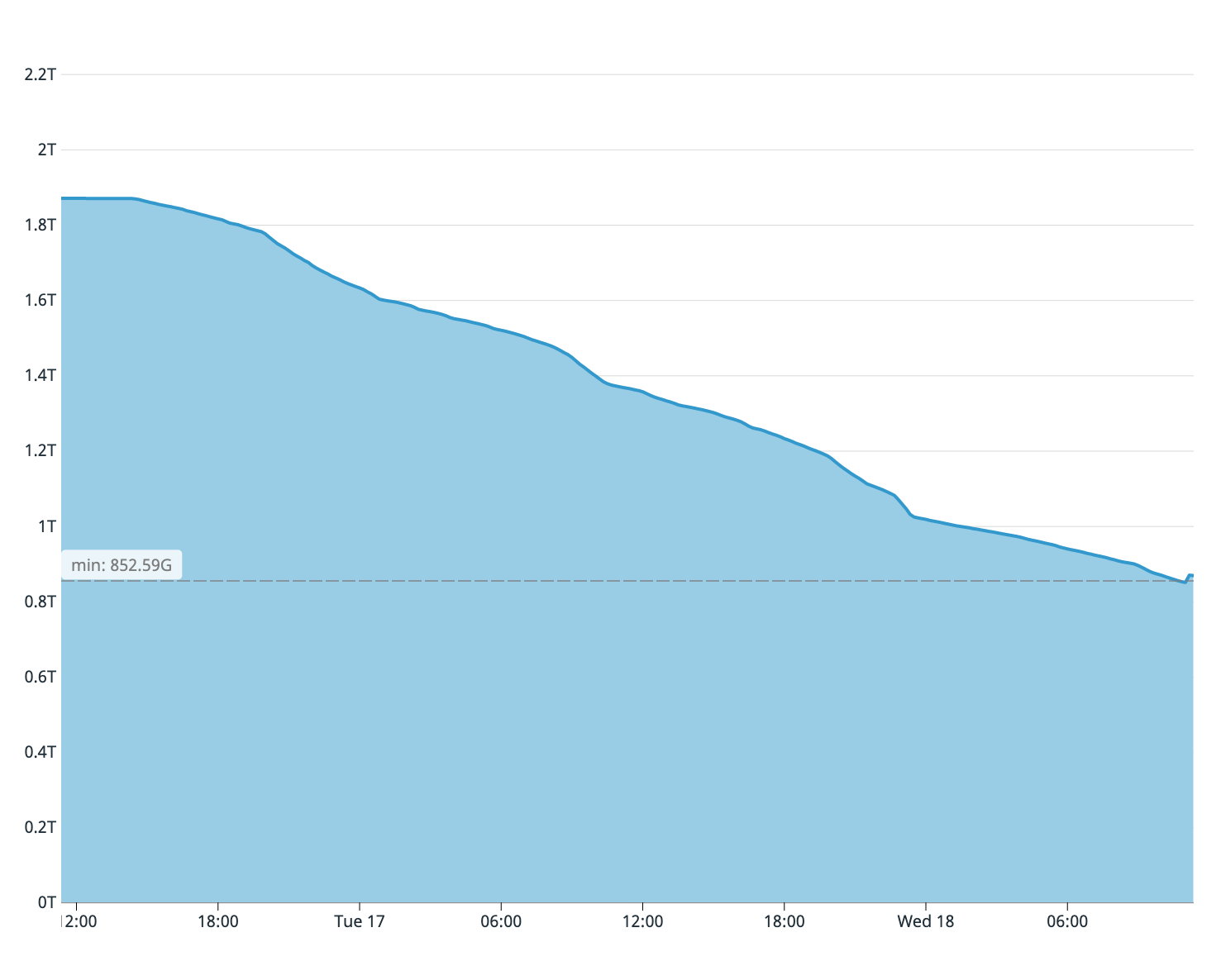
Espace disque disponible sur l'ancien assistant lors de la première tentative de synchronisation
Pour accélérer le processus de synchronisation, nous avons apporté les modifications suivantes à la base de données des abonnés:
- Suppression de tous les index de la table synchronisée;
fsynch
commuté suroff
;- Changé
max_wal_size
en50GB
; - Changé
checkpoint_timeout
en1h
.
Ces quatre étapes accélèrent considérablement le processus de synchronisation chez l'abonné, et notre deuxième tentative de synchronisation de table s'est terminée en 8 heures.
Leçon n ° 2: chaque changement de ligne est enregistré comme un conflit
Lorsque pglogical détecte un conflit, l'application laisse une entrée "
CONFLICT: remote UPDATE on relation PUBLIC.foo. Resolution: apply_remote
" dans les journaux .
Cependant, il s'est avéré que chaque modification de ligne traitée par l'abonné était enregistrée comme un conflit. En quelques heures de réplication, la base de données de l'abonné a laissé des gigaoctets de fichiers journaux en conflit.
Ce problème a été résolu en définissant un paramètre
pglogical.conflict_log_level = DEBUG
dans le fichier
postgresql.conf
.
A propos de l'auteur
 Tommy Lee est ingénieur logiciel senior chez Coffee Meets Bagel. Auparavant, il a travaillé pour Microsoft et Wave HQ, un fabricant canadien de systèmes d'automatisation comptable.
Tommy Lee est ingénieur logiciel senior chez Coffee Meets Bagel. Auparavant, il a travaillé pour Microsoft et Wave HQ, un fabricant canadien de systèmes d'automatisation comptable.