
Avec 12 problèmes derrière nous, il est temps de changer un peu le nom et la conception, mais à l'intérieur, vous attendez toujours des recherches, des démos, des modèles ouverts et des ensembles de données. Découvrez le nouvel opus du Machine Learning Toolkit.
DALL E
Accessibilité: page projet / accès à l'API fermée via liste d'attente
OpenAI a présenté son nouveau modèle de langage de transformateur DALL-E avec 12 milliards de paramètres, formés sur des paires image-texte. Le modèle est basé sur GPT-3 et est utilisé pour synthétiser des images à partir de descriptions textuelles.
En juin dernier, la société a montré comment un modèle entraîné sur des séquences de pixels avec une description précise peut combler les vides dans les images qui sont introduites dans l'entrée. Les résultats étaient déjà impressionnants à l'époque, mais ici l'Open AI a dépassé toutes les attentes. Tout comme GPT-3 synthétise des phrases complètes cohérentes, DALL · E crée des images complexes.

Les modèles sont étonnamment bons pour les objets anthropomorphes (radis promenant le chien) et une combinaison d'objets incompatibles (un escargot en forme de harpe), c'est pourquoi ils ont choisi la fusion de deux noms pour le nom - le surréaliste espagnol Salvador Dali et le robot Pixar WALL-I.
Alors, quels sont les résultats du modèle?
Le modèle est capable de visualiser la profondeur de l'espace, il est donc possible de manipuler une scène en trois dimensions. Il suffit, lors de la description de l'image souhaitée, d'indiquer sous quel angle l'objet doit être vu et sous quel éclairage. À l'avenir, cela permettra la création de véritables représentations 3D.
De plus, le modèle est capable d'appliquer des effets optiques à la scène, par exemple, comme lors de la prise de vue avec un objectif fisheye. Mais jusqu'à présent, il ne supporte pas bien les reflets - le cube dans le miroir n'a pas été synthétisé de manière convaincante. Ainsi, avec des degrés de fiabilité variables, DALL · E à travers le langage naturel fait face aux tâches pour lesquelles les moteurs de modélisation 3D sont utilisés dans l'industrie. Cela lui permet d'être utilisé pour rendre les rendus de conception de pièce.
Le modèle est bien conscient de la géographie et des monuments emblématiques, ainsi que des caractéristiques distinctives des époques individuelles. Elle peut synthétiser une photographie d'un vieux téléphone ou du Golden Gate Bridge à San Francisco.
Avec tout cela, le modèle n'a pas besoin d'une description ultra-précise - il comblera lui-même certaines des lacunes. Comme l'a noté Open AI, plus la description est précise, plus le résultat est mauvais.
Rappelez-vous que le GPT-3 est un modèle sans tir, il n'a pas besoin d'être configuré et formé en plus pour effectuer des tâches spécifiques. En plus de la description, vous pouvez donner un indice pour que le modèle génère la réponse souhaitée. DALL · E fait de même avec le rendu et peut effectuer diverses tâches de conversion d'image en image en fonction des invites. Par exemple, vous pouvez donner une image en entrée et demander à la faire sous la forme d'un croquis.
Étonnamment, les créateurs ne se sont pas fixé un tel objectif et ne l'ont en aucun cas prévu lors de la formation du modèle. La capacité n'a été révélée que lors des tests.
Guidés par cette découverte, les auteurs ont étudié la capacité de DALL · E à résoudre les problèmes logiques du test visuel de QI et se sont fixé pour tâche de ne pas choisir la bonne réponse parmi les options présentées, mais de prédire pleinement l'élément manquant.
En général, le modèle a réussi à continuer correctement la séquence dans la partie des tâches où la compréhension géométrique était requise.
Le modèle n'a pas encore été publié et il n'y a même pas de description approximative de son architecture. À ce stade, vous pouvez demander l'accès à l'API ou consulter l' implémentation non officielle sur PyTorch ( une version non officielle sur TensorFlow est également en cours d' élaboration ).
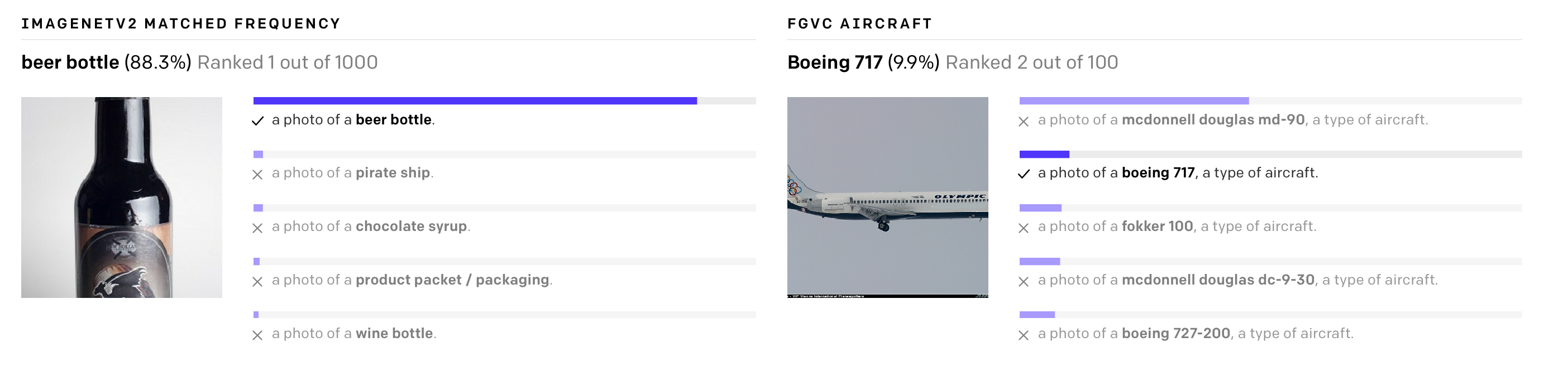
CLIP (Contrastive Language - Image Pre-training)
Accessibilité: Page de projet / Code source Le
Deep Learning a révolutionné la vision par ordinateur, mais les approches actuelles ont encore deux problèmes importants qui remettent en question l'utilisation du DNN dans ce domaine.
Premièrement, la création de jeux de données reste très coûteuse, mais en même temps, elle permet de reconnaître un ensemble très limité d'images visuelles et convient à des tâches étroites. Par exemple, lors de la préparation de l'ensemble de données ImageNet, il a fallu 25 000 personnes pour composer les descriptions de 14 millions d'images pour 22 000 catégories d'objets. Dans le même temps, le modèle ImageNet est bon pour prédire uniquement les catégories qui sont représentées dans l'ensemble de données, et si une autre tâche est requise, les spécialistes devront créer de nouveaux ensembles de données et terminer la formation du modèle.
Deuxièmement, les modèles qui fonctionnent bien dans les benchmarks sont insuffisants dans leur environnement naturel. Les modèles déployés dans le monde réel ne fonctionnent pas aussi bien qu'en laboratoire. En d'autres termes, le modèle est optimisé pour réussir un test spécifique en tant qu'étudiant remplissant les questions d'examen.
Le réseau de neurones ouvert CLIP d'OpenAI vise à résoudre ces problèmes. Le modèle est formé sur un grand nombre d'images et de descriptions textuelles disponibles sur Internet et les traduit en représentations vectorielles, plongements. Ces représentations sont comparées afin que les numéros de l'inscription et de l'image qui lui conviennent soient proches.
CLIP peut être immédiatement testé sur différents benchmarks sans formation sur leurs données. Le modèle effectue des tests de classification sans optimisation directe. Par exemple, le test ObjectNet teste la capacité du modèle à reconnaître des objets à différents endroits et avec des arrière-plans changeants, tandis que ImageNet Rendition et ImageNet Sketch testent la capacité du modèle à reconnaître des images plus abstraites d'objets (pas seulement une banane, mais une banane tranchée ou croquis de banane). CLIP fonctionne également bien sur tous.
CLIP peut être adapté pour effectuer un large éventail de tâches de classification visuelle sans exemples de formation supplémentaires. Pour appliquer CLIP à un nouveau problème, il suffit de donner à l'encodeur les noms des représentations visuelles, et il produira un classificateur linéaire de ces représentations, dont la précision n'est pas inférieure aux modèles formés avec l'enseignant.
Github a déjà une implémentation pour les photos avec Unsplash, qui montre à quel point le modèle regroupe les images. Les designers peuvent déjà l'utiliser pour concevoir des moodboards.
DeBERTa par Microsoft
Disponibilité: Page Source / Projet
Comme d'habitude, les nouvelles d'OpenAI ont éclipsé d'autres annonces, bien qu'il y ait eu un autre événement qui a été activement discuté dans la communauté. Le modèle DeBERTa de Microsoft a surpassé la base humaine sur le test SuperGLUE Natural Language Comprehension (NLU).
Un benchmark basé sur 10 paramètres détermine si l'algorithme «comprend» ce qu'il a lu et fait une note. La note moyenne des non-experts est de 89,8 points et les problèmes que les modèles doivent résoudre sont comparables à un examen d'anglais. DeBERTa a montré 90,3, suivi du T5 + Meena de Google.
Ainsi, le modèle a réussi à dépasser un humain pour la deuxième fois, mais il est à noter que DeBERTa a 1,5 milliard de paramètres d'entraînement, 8 fois moins que T5.
Le modèle représente un nouveau mécanisme d'attention divisé, différent du transformateur d'origine, dans lequel chaque jeton est codé par des vecteurs de contenu et des positions qui ne s'additionnent pas en un seul vecteur, des matrices séparées fonctionnent avec eux.
NeuralMagicEye
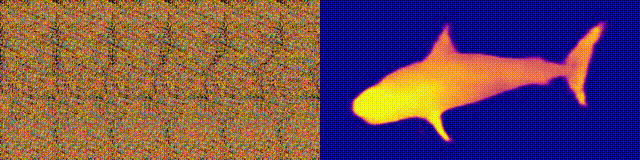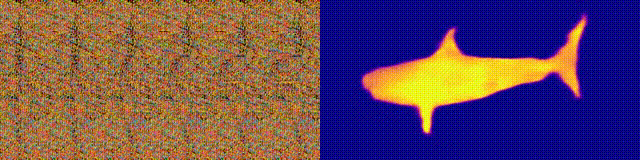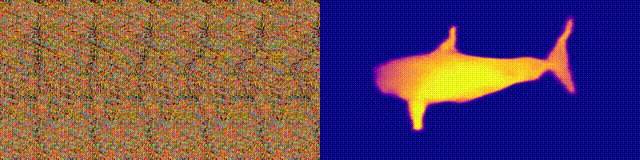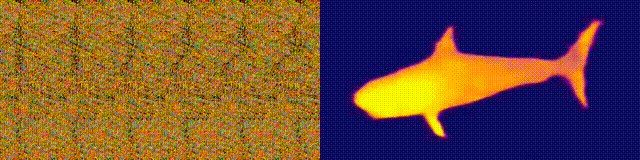
Accessibilité: page / code / colab du projet Vous
vous souvenez des albums Magic Eye avec stéréogrammes? Voici quelque chose de similaire, uniquement pour les autostéréogrammes, dans lesquels les deux parties de la paire stéréoscopique sont dans la même image et codées dans une structure raster, de sorte qu'elle puisse créer des illusions visuelles de tridimensionnalité.
L'auteur de l'étude a formé le modèle CNN pour reconstruire la profondeur de l'autostéréogramme et comprendre son contenu. Pour obtenir l'effet stéréo, le modèle a dû être formé pour détecter et évaluer l'inadéquation des textures quasi-périodiques. Le modèle a été formé sur un jeu de données à partir de modèles 3D, sans enseignant.
La méthode vous permet de restaurer avec précision la profondeur de l'autostéréogramme. Les chercheurs espèrent que cela aidera les personnes ayant une déficience visuelle et que les stéréogrammes pourront être utilisés comme filigranes dans les images.
StyleFlow

Accessibilité: code source
Comme nous l'avons vu plus d'une fois, les GAN inconditionnels (tels que StyleGANs) peuvent créer des images photoréalistes de haute qualité. Cependant, il est rarement possible de gérer le processus de génération en utilisant des attributs sémantiques tout en conservant la qualité de la sortie. En raison de la latence GAN complexe et déroutante, la modification d'un attribut entraîne souvent des modifications indésirables des autres. Ce modèle aide à résoudre ce problème. Par exemple, vous pouvez modifier l'angle de vue, la variation d'éclairage, l'expression, la pilosité faciale, le sexe et l'âge.
Apprivoiser les transformateurs
Accessibilité: page de projet / code source Les
transformateurs sont capables de fournir d'excellents résultats dans une variété d'applications. Mais en termes de puissance de calcul, ils sont très exigeants, ils ne sont donc pas adaptés pour travailler avec des images haute résolution. Les auteurs de l'étude ont combiné un transformateur avec un réseau convolutif à déplacement inductif et ont pu obtenir des images avec une haute résolution.
POse EMbedding

Accessibilité: code source Les
activités quotidiennes, qu'il s'agisse de courir ou de lire un livre, peuvent être considérées comme une séquence de postures, consistant en la position et l'orientation du corps d'une personne dans l'espace. La reconnaissance de pose ouvre un certain nombre de possibilités en RA, contrôle gestuel, etc. Cependant, les données obtenues à partir de l'image 2D diffèrent selon le point de vue de la caméra. Cet algorithme de Google AI reconnaît la similitude des poses sous différents angles, en faisant correspondre les points clés de l'affichage 2D de la pose avec l'incorporation invariante de vue.
Apprendre à apprendre
Accessibilité: code source
Pour apprendre à ramasser ou à placer une bouteille sur la table, il suffit de voir une autre personne le faire. Pour apprendre à faire fonctionner de tels objets, une machine a besoin de récompenses programmées manuellement pour réussir les éléments constitutifs d'une tâche. Avant qu'un robot puisse apprendre à placer une bouteille sur une table, il doit être récompensé pour avoir appris à déplacer la bouteille verticalement. Ce n'est qu'après une série de telles itérations qu'il apprendra à placer la bouteille. Facebook a introduit une méthode qui entraîne une machine en quelques sessions d'observation humaine.
Voilà à quel point le premier mois de cette année a été brillant. Merci d'avoir lu et restez à l'affût des prochaines versions!