
Comment mettre à jour la valeur d'attribut pour tous les enregistrements d'une table? Comment ajouter une clé primaire ou unique à une table? Comment diviser une table en deux? Comment ...
Si l'application peut être indisponible pendant un certain temps pour les migrations, les réponses à ces questions ne sont pas difficiles. Mais que faire si vous avez besoin de migrer à chaud - sans arrêter la base de données et sans déranger les autres pour travailler avec?
Nous essaierons de répondre à ces questions et à d'autres qui se posent lors des migrations de schémas et de données dans PostgreSQL sous la forme de conseils pratiques.
Cet article - performances de décodage lors de la conférence SmartDataConf ( ici vous pouvez trouver la présentation, la vidéo apparaîtra en temps voulu). Il y avait beaucoup de texte, donc le matériel sera divisé en 2 articles:
- migrations de base
- méthodes de mise à jour de grandes tables.
À la fin, il y a un résumé de l'article entier sous la forme d'une feuille de triche de tableau croisé dynamique.
Contenu
Le nœud du problème
Ajouter une colonne
Ajouter une
colonne par défaut Supprimer une colonne
Créer un index
Créer un index sur une table partitionnée
Créer une contrainte NOT NULL
Créer une clé étrangère
Créer une contrainte unique
Créer une clé primaire Aide- mémoire sur la
migration rapide
L'essence du problème
Supposons que nous ayons une application qui fonctionne avec une base de données. Dans la configuration minimale, il peut être composé de 2 nœuds - l'application elle-même et la base de données, respectivement.

Avec ce schéma, les mises à jour d'applications se produisent souvent avec des temps d'arrêt. En même temps, vous pouvez mettre à jour la base de données. Dans une telle situation, le critère principal est le temps, c'est-à-dire que vous devez effectuer la migration le plus rapidement possible afin de minimiser le temps d'indisponibilité du service.
Si l'application se développe et qu'il devient nécessaire d'effectuer des versions sans temps d'arrêt, nous commençons à utiliser plusieurs serveurs d'applications. Il peut y en avoir autant que vous le souhaitez, et ils seront sur différentes versions. Dans ce cas, il devient nécessaire d'assurer la rétrocompatibilité.

Au prochain stade de croissance, les données cessent de s'intégrer dans une seule base de données. Nous commençons également à mettre à l'échelle la base de données - par partitionnement. Étant donné qu'en pratique, il est très difficile de migrer plusieurs bases de données de manière synchrone, cela signifie qu'à un moment donné, elles auront des schémas de données différents. En conséquence, nous travaillerons dans un environnement hétérogène, où les serveurs d'applications peuvent avoir différents codes et bases de données avec différents schémas de données.
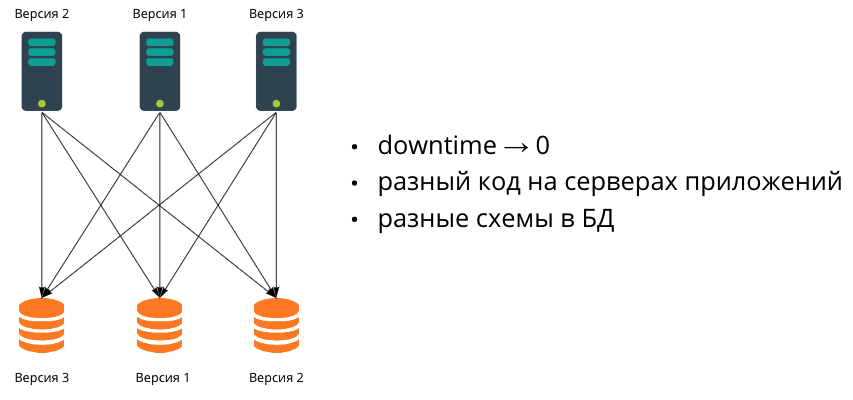
C'est de cette configuration que nous allons parler dans cet article et considérer les migrations les plus populaires écrites par les développeurs - des plus simples aux plus complexes.
Notre objectif est d'effectuer des migrations SQL avec un impact minimal sur les performances des applications, c'est-à-dire modifiez les données ou le schéma de données afin que l'application continue de s'exécuter et que les utilisateurs ne le remarquent pas.
Ajouter une colonne
ALTER TABLE my_table ADD COLUMN new_column INTEGER --
Probablement, toute personne qui travaille avec la base de données a écrit une migration similaire. Si nous parlons de PostgreSQL, alors cette migration est très bon marché et sûre. La commande elle-même, bien qu'elle capture le verrou de plus haut niveau ( AccessExclusive ), est exécutée très rapidement, car sous le capot, il n'y a que l'ajout de méta-informations sur une nouvelle colonne sans réécrire les données de la table elle-même. Dans la plupart des cas, cela se passe inaperçu. Mais des problèmes peuvent survenir si, au moment de la migration, de longues transactions fonctionnent avec cette table. Pour comprendre l'essence du problème, regardons un petit exemple de la façon dont les verrous fonctionnent de manière simplifiée dans PostgreSQL. Cet aspect sera également très important lors de l'examen de la plupart des autres migrations.
Supposons que nous ayons une grande table et que nous sélectionnions toutes les données à partir de celle-ci. En fonction de la taille de la base de données et de la table elle-même, cela peut prendre plusieurs secondes, voire quelques minutes.

Le verrou AccessShare le plus faible qui protège contre les modifications de la structure de la table est acquis pendant la transaction .
À ce moment, une autre transaction arrive, qui essaie juste de faire une requête ALTER TABLE à cette table. La commande ALTER TABLE, comme mentionné précédemment, récupère un verrou AccessExclusive , qui n'est pas du tout compatible avec tout autre verrou . Elle fait la queue.
Cette file d'attente de verrouillage est "ratissée" dans un ordre strict; même si d'autres requêtes viennent après ALTER TABLE (par exemple, également SELECT), qui par elles-mêmes ne sont pas en conflit avec la première requête, elles sont toutes en file d'attente pour ALTER TABLE. En conséquence, l'application "se lève" et attend qu'ALTER TABLE soit exécuté.
Que faire dans une telle situation? Vous pouvez limiter le temps nécessaire pour acquérir un verrou à l'aide de la commande SET lock_timeout . Nous exécutons cette commande avant ALTER TABLE (le mot clé LOCAL signifie que le paramètre n'est valide que dans la transaction en cours, sinon - dans la session en cours):
SET LOCAL lock_timeout TO '100ms'
et si dans 100 millisecondes la commande ne parvient pas à acquérir le verrou, elle échouera. Ensuite, soit nous la redémarrons, en espérant qu'elle réussisse, soit nous cherchons à comprendre pourquoi la transaction prend beaucoup de temps, si cela ne devrait pas être dans notre application. Dans tous les cas, le principal est que nous n'avons pas planté l'application.
Il faut dire que définir un timeout est utile avant toute commande qui attrape un verrou strict.
Ajouter une colonne avec une valeur par défaut
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42
Si cette commande est exécutée dans une ancienne version de PostgreSQL (inférieure à 11), alors elle écrasera toutes les lignes de la table. Évidemment, si la table est grande, cela peut prendre beaucoup de temps. Et comme un verrou strict ( AccessExclusive ) est capturé pendant le temps d'exécution , toutes les requêtes adressées à la table sont également bloquées.
Si PostgreSQL est 11 ou plus récent, cette opération est assez bon marché. Le fait est que dans la 11e version une optimisation a été faite, grâce à laquelle, au lieu de réécrire la table, la valeur par défaut est stockée dans une table spéciale pg_attribute, et plus tard, lors de l'exécution de SELECT, toutes les valeurs vides de cette colonne seront être remplacé à la volée par cette valeur. Dans ce cas, plus tard, lorsque les lignes de la table sont écrasées en raison d'autres modifications, la valeur sera écrite dans ces lignes.
De plus, à partir de la 11ème version, vous pouvez également créer immédiatement une nouvelle colonne et la marquer comme NOT NULL:
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42 NOT NULL
Et si PostgreSQL est plus ancien que 11?
La migration peut se faire en plusieurs étapes. Tout d'abord, nous créons une nouvelle colonne sans contraintes ni valeurs par défaut. Comme indiqué précédemment, c'est bon marché et rapide. Dans la même transaction, nous modifions cette colonne en ajoutant une valeur par défaut.
ALTER TABLE my_table ADD COLUMN new_column INTEGER;
ALTER TABLE my_table ALTER COLUMN new_column SET DEFAULT 42;
Cette division d'une commande en deux peut sembler un peu étrange, mais la mécanique est telle que lorsqu'une nouvelle colonne est créée immédiatement avec une valeur par défaut, elle affecte tous les enregistrements qui sont dans la table, et lorsque la valeur est définie pour un colonne existante (même si ce n'est que ce qui est créé, comme dans notre cas), cela n'affecte que les nouveaux enregistrements.
Ainsi, après avoir exécuté ces commandes, il nous reste à mettre à jour les valeurs qui étaient déjà dans le tableau. En gros, nous devons faire quelque chose comme ceci:
UPDATE my_table set new_column = 42 --
Mais une telle mise à jour «frontale» est en fait impossible, car lors de la mise à jour d'une grande table, nous verrouillons la table entière pendant longtemps. Dans le deuxième article (ici dans le futur, il y aura un lien), nous examinerons quelles stratégies existent pour mettre à jour de grandes tables dans PostgreSQL, mais pour l'instant, nous supposerons que nous avons mis à jour les données, et maintenant les anciennes données et le nouveau sera avec la valeur requise par défaut.
Supprimer une colonne
ALTER TABLE my_table DROP COLUMN new_column --
Ici, la logique est la même que lors de l'ajout d'une colonne: les données de la table ne sont pas modifiées, seules les méta-informations sont modifiées. Dans ce cas, la colonne est marquée comme supprimée et indisponible pour les requêtes. Cela explique le fait que lorsqu'une colonne est supprimée dans PostgreSQL, aucun espace physique n'est libéré (sauf si vous effectuez un VACUUM FULL), c'est-à-dire que les données des anciens enregistrements restent toujours dans la table, mais ne sont pas disponibles lors de l'accès. La désallocation se produit progressivement au fur et à mesure que les lignes de la table sont écrasées.
Ainsi, la migration elle-même est simple, mais, en règle générale, des erreurs sont parfois rencontrées du côté backend. Avant de supprimer une colonne, il y a quelques étapes préparatoires simples à suivre.
- Tout d'abord, vous devez supprimer toutes les restrictions (NOT NULL, CHECK, ...) qui se trouvent sur cette colonne:
ALTER TABLE my_table ALTER COLUMN new_column DROP NOT NULL
- L'étape suivante consiste à garantir la compatibilité du backend. Vous devez vous assurer que la colonne n'est utilisée nulle part. Par exemple, dans Hibernate, vous devez marquer un champ à l'aide d'une annotation
@Transient
. Dans l'OJOQ que nous utilisons, le champ est ajouté aux exceptions à l'aide d'une balise<excludes>
:
<excludes>my_table.new_column</excludes>
Vous devez également examiner de près les requêtes"SELECT *"
- les frameworks peuvent mapper toutes les colonnes dans une structure du code (et vice versa) et, par conséquent, vous pouvez à nouveau faire face au problème d'accès à une colonne inexistante.
Une fois les modifications publiées sur tous les serveurs d'applications, vous pouvez supprimer la colonne.
Création d'index
CREATE INDEX my_table_index ON my_table (name) -- ,
Ceux qui travaillent avec PostgreSQL savent probablement que cette commande verrouille toute la table. Mais depuis la très ancienne version 8.2, il existe le mot - clé CONCURRENTLY , qui permet de créer un index en mode non bloquant.
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name) --
La commande est plus lente, mais n'interfère pas avec les requêtes parallèles.
Cette équipe a une mise en garde. Cela peut échouer - par exemple, lors de la création d'un index unique sur une table contenant des valeurs en double. L'index sera créé, mais il sera marqué comme invalide et ne sera pas utilisé dans les requêtes. L'état de l'index peut être vérifié avec la requête suivante:
SELECT pg_index.indisvalid
FROM pg_class, pg_index
WHERE pg_index.indexrelid = pg_class.oid
AND pg_class.relname = 'my_table_index'
Dans une telle situation, vous devez supprimer l'ancien index, corriger les valeurs de la table, puis le recréer.
DROP INDEX CONCURRENTLY my_table_index
UPDATE my_table ...
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name)
Il est important de noter que la commande REINDEX , qui est uniquement destinée à la reconstruction de l'index, ne fonctionne qu'en mode bloquant jusqu'à la version 12 , ce qui rend son utilisation impossible. PostgreSQL 12 ajoute le support CONCURRENTMENT et peut maintenant être utilisé.
REINDEX INDEX CONCURRENTLY my_table_index -- PG 12
Création d'un index sur une table partitionnée
Nous devrions également discuter de la création d'index pour les tables partitionnées. Dans PostgreSQL, il existe 2 types de partitionnement: par héritage et déclaratif, apparus dans la version 10. Regardons les deux avec un exemple simple.
Supposons que nous souhaitons partitionner une table par date et que chaque partition contiendra des données pendant un an.
Lors du partitionnement par héritage, nous aurons approximativement le schéma suivant.
Table des parents:
CREATE TABLE my_table (
...
reg_date date not null
)
Partitions enfants pour 2020 et 2021:
CREATE TABLE my_table_y2020 (
CHECK ( reg_date >= DATE '2020-01-01' AND reg_date < DATE '2021-01-01' ))
INHERITS (my_table);
CREATE TABLE my_table_y2021 (
CHECK ( reg_date >= DATE '2021-01-01' AND reg_date < DATE '2022-01-01' ))
INHERITS (my_table);
Index par le champ de partitionnement pour chacune des partitions:
CREATE INDEX ON my_table_y2020 (reg_date);
CREATE INDEX ON my_table_y2021 (reg_date);
Laissons la création d'un déclencheur / règle pour insérer des données dans une table.
La chose la plus importante ici est que chacune des partitions est pratiquement une table indépendante qui est gérée séparément. Ainsi, la création de nouveaux index se fait également comme avec les tables régulières:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name);
CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
Regardons maintenant le partitionnement déclaratif.
CREATE TABLE my_table (...) PARTITION BY RANGE (reg_date);
CREATE TABLE my_table_y2020 PARTITION OF my_table FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE my_table_y2021 PARTITION OF my_table FOR VALUES FROM ('2021-01-01') TO ('2021-12-31');
La création d'index dépend de la version de PostgreSQL. Dans la version 10, les index sont créés séparément - comme dans l'approche précédente. Par conséquent, la création de nouveaux index pour une table existante se fait également de la même manière.
Dans la version 11, le partitionnement déclaratif a été amélioré et les tables sont désormais servies ensemble . La création d'un index sur la table parent crée automatiquement des index pour toutes les partitions existantes et nouvelles qui seront créées à l'avenir:
-- PG 11 ()
CREATE INDEX ON my_table (reg_date)
Ceci est utile lors de la création d'une table partitionnée, mais pas lors de la création d'un nouvel index sur une table existante, car la commande saisit un verrou fort lors de la création des index.
CREATE INDEX ON my_table (name) --
Malheureusement, CREATE INDEX ne prend pas en charge le mot clé CONCURRENTLY pour les tables partitionnées. Pour contourner la limitation et migrer sans blocage, vous pouvez effectuer les opérations suivantes.
- Créer un index sur la table parent avec l'option UNIQUEMENT
CREATE INDEX my_table_index ON ONLY my_table (name)
La commande créera un index invalide vide sans créer d'index pour les partitions . - Créez des index pour chacune des partitions:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name); CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
- Attachez les index des partitions à l'index de la table parent:
ALTER INDEX my_table_index ATTACH PARTITION my_table_y2020_index; ALTER INDEX my_table_index ATTACH PARTITION my_table_y2021_index;
Limites
Passons maintenant en revue les contraintes: NOT NULL, les clés étrangères, uniques et primaires.
Création d'une contrainte NOT NULL
ALTER TABLE my_table ALTER COLUMN name SET NOT NULL --
Créer une contrainte de cette manière analysera la table entière - toutes les lignes seront vérifiées pour la condition non nulle, et si la table est grande, cela peut prendre du temps. Le bloc fort capturé par cette commande bloquera toutes les demandes simultanées jusqu'à ce qu'il se termine.
Ce qui peut être fait? PostgreSQL a un autre type de contrainte, CHECK , qui peut être utilisé pour obtenir le résultat souhaité. Cette contrainte teste toute condition booléenne constituée de colonnes de lignes. Dans notre cas, la condition est triviale -
CHECK (name IS NOT NULL)
. Mais surtout, la contrainte CHECK prend en charge l'invalidation (mot-clé
NOT VALID
):
ALTER TABLE my_table ADD CONSTRAINT chk_name_not_null
CHECK (name IS NOT NULL) NOT VALID -- , PG 9.2
La restriction créée de cette manière s'applique uniquement aux enregistrements nouvellement ajoutés et modifiés, et les enregistrements existants ne sont pas vérifiés, la table n'est donc pas analysée.
Pour s'assurer que les enregistrements existants satisfont également à la contrainte, il est nécessaire de la valider (bien sûr, en mettant d'abord à jour les données du tableau):
ALTER TABLE my_table VALIDATE CONSTRAINT chk_name_not_null
La commande parcourt les lignes de la table et vérifie que tous les enregistrements ne sont pas nuls. Mais contrairement à la contrainte habituelle NOT NULL, le verrou capturé dans cette commande n'est pas aussi fort (ShareUpdateExclusive) - il ne bloque pas les opérations d'insertion, de mise à jour et de suppression.
Créer une clé étrangère
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) --
Lorsqu'une clé étrangère est ajoutée, tous les enregistrements de la table enfant sont vérifiés pour une valeur dans le parent. Si la table est volumineuse, cette analyse sera longue et le verrou maintenu sur les deux tables sera également long.
Heureusement, les clés étrangères dans PostgreSQL prennent également en charge NOT VALID, ce qui signifie que nous pouvons utiliser la même approche que celle décrite précédemment avec CHECK. Créons une clé étrangère invalide:
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) NOT VALID
puis nous mettons à jour les données et effectuons la validation:
ALTER TABLE my_table VALIDATE CONSTRAINT fk_group_id
Créer une contrainte unique
ALTER TABLE my_table ADD CONSTRAINT uk_my_table UNIQUE (id) --
Comme dans le cas des contraintes décrites précédemment, la commande capture un verrou strict, sous lequel elle vérifie toutes les lignes de la table par rapport à la contrainte - dans ce cas, l'unicité.
Il est important de savoir que sous le capot, PostgreSQL applique des contraintes uniques en utilisant des index uniques. En d'autres termes, lorsqu'une contrainte est créée, un index unique correspondant avec le même nom est créé pour servir cette contrainte. À l'aide de la requête suivante, vous pouvez trouver l'index de diffusion de la contrainte:
SELECT conindid index_oid, conindid::regclass index_name
FROM pg_constraint
WHERE conname = 'uk_my_table_id'
Dans le même temps utilisé sur la plupart des contraintes de temps de création, il en va de même pour l'index, et sa liaison ultérieure à limiter très rapidement. De plus, si vous avez déjà créé un index unique, vous pouvez le faire vous-même en créant un index à l'aide des mots-clés USING INDEX:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id UNIQUE
USING INDEX uk_my_table_id -- , PG 9.1
Ainsi, l'idée est simple: nous créons un index unique de manière CONCURRENTE, comme nous l'avons vu précédemment, puis créons une contrainte unique basée sur celle-ci.
À ce stade, la question peut se poser - pourquoi créer une contrainte, si l'indice fait exactement ce qui est requis - garantit l'unicité des valeurs? Si nous excluons les indices partiels de la comparaison , alors d'un point de vue fonctionnel, le résultat est vraiment presque identique. La seule différence que nous avons trouvée est que les contraintes peuvent être reportables , mais pas les index. La documentation des anciennes versions de PostgreSQL (jusqu'à la version 9.4 incluse) contenait une note de bas de pageavec l'information que la meilleure façon de créer une contrainte d'unicité est de créer explicitement une contrainte
ALTER TABLE ... ADD CONSTRAINT
, et l'utilisation d'index doit être considérée comme un détail d'implémentation. Cependant, dans les versions plus récentes, cette note de bas de page a été supprimée.
Créer une clé primaire
En plus d'être unique, la clé primaire impose la contrainte non nulle. Si la colonne avait à l'origine une telle contrainte, il ne sera pas difficile de la «transformer» en clé primaire - nous créons également un index unique CONCURRENTMENT, puis la clé primaire:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id PRIMARY KEY
USING INDEX uk_my_table_id -- id is NOT NULL
Il est important de noter que la colonne doit avoir une contrainte NOT NULL "juste" - l'approche CHECK précédemment discutée ne fonctionnera pas.
S'il n'y a pas de limite, alors jusqu'à la 11ème version de PostgreSQL il n'y a rien à faire - il n'y a aucun moyen de créer une clé primaire sans verrouillage.
Si vous avez PostgreSQL 11 ou plus récent, cela peut être accompli en créant une nouvelle colonne qui remplacera celle existante. Alors, étape par étape.
Créez une nouvelle colonne qui n'est pas nulle par défaut et qui a une valeur par défaut:
ALTER TABLE my_table ADD COLUMN new_id INTEGER NOT NULL DEFAULT -1 -- PG 11
Nous mettons en place la synchronisation des données des anciennes et nouvelles colonnes à l'aide d'un déclencheur:
CREATE FUNCTION on_insert_or_update() RETURNS TRIGGER AS
$$
BEGIN
NEW.new_id = NEW.id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg BEFORE INSERT OR UPDATE ON my_table
FOR EACH ROW EXECUTE PROCEDURE on_insert_or_update();
Ensuite, vous devez mettre à jour les données des lignes qui n'ont pas été affectées par le déclencheur:
UPDATE my_table SET new_id = id WHERE new_id = -1 --
La demande avec la mise à jour ci-dessus est écrite "sur le front", sur une grande table cela ne vaut pas la peine de le faire, car il y aura un long blocage. Comme mentionné précédemment, le deuxième article examinera les approches de mise à jour de grandes tables. Pour l'instant, supposons que les données soient mises à jour et qu'il ne reste plus qu'à permuter les colonnes.
ALTER TABLE my_table RENAME COLUMN id TO old_id;
ALTER TABLE my_table RENAME COLUMN new_id TO id;
ALTER TABLE my_table RENAME COLUMN old_id TO new_id;
Dans PostgreSQL, les commandes DDL sont transactionnelles - cela signifie que vous pouvez renommer, ajouter, supprimer des colonnes, et en même temps une transaction parallèle ne verra pas cela au cours de ses opérations.
Après avoir changé les colonnes, il reste à créer un index et à "nettoyer" - supprimer le déclencheur, la fonction et l'ancienne colonne.
Une aide-mémoire rapide avec les migrations
Avant toute commande qui capture des verrous forts (presque tous
ALTER TABLE ...
), il est recommandé d'appeler:
SET LOCAL lock_timeout TO '100ms'
| Migration | Approche recommandée |
|---|---|
| Ajouter une colonne | |
| Ajout d'une colonne avec une valeur par défaut [et NOT NULL] | avec PostgreSQL 11:
avant PostgreSQL 11:
|
| Supprimer une colonne |
|
| Création d'index | En cas d'échec:
|
| Création d'un index sur une table partitionnée | Partitionnement par héritage + déclaratif en PG 10:
Partitionnement déclaratif avec PG 11:
|
| Création d'une contrainte NOT NULL |
|
| Créer une clé étrangère |
|
| Créer une contrainte unique |
|
| Créer une clé primaire | Si la colonne est IS NOT NULL:
Si la colonne EST NULL avec PG 11:
|
Dans le prochain article, nous examinerons les approches de mise à jour de grandes tables.
Migrations faciles à tous!