
Les problèmes que le machine learning résout aujourd'hui sont souvent complexes et incluent un grand nombre de fonctionnalités (fonctionnalités). En raison de la complexité et de la diversité des données initiales, l'utilisation de modèles d'apprentissage automatique simples ne permet souvent pas d'obtenir les résultats nécessaires.Par conséquent, des modèles complexes et non linéaires sont utilisés dans des cas commerciaux réels. De tels modèles présentent un inconvénient majeur: en raison de leur complexité, il est presque impossible de voir la logique selon laquelle le modèle a affecté cette classe particulière à l'opération de compte. L'interprétabilité du modèle est particulièrement importante lorsque les résultats de son travail doivent être présentés au client - il voudra probablement savoir sur la base de quels critères les décisions sont prises pour son entreprise.
, sklearn, xgboost, lightGBM (). , . , , ? ? , . SHAP. SHAP . , .
. , . 213 , .
kaggle .
:
%%time
# LOAD TRAIN
X_train=pd.read_csv('train_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols+['isFraud'])
train_id= pd.read_csv('train_identity.csv',index_col='TransactionID', dtype=dtypes)
X_train = X_train.merge(train_id, how='left', left_index=True, right_index=True)
# LOAD TEST
X_test=pd.read_csv('test_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols)
test_id = pd.read_csv('test_identity.csv',index_col='TransactionID', dtype=dtypes)
fix = {o:n for o, n in zip(test_id.columns, train_id.columns)}
test_id.rename(columns=fix, inplace=True)
X_test = X_test.merge(test_id, how='left', left_index=True, right_index=True)
# TARGET
y_train = X_train['isFraud'].copy()
del train_id, test_id, X_train['isFraud']; x = gc.collect()
# PRINT STATUS
print('Train shape',X_train.shape,'test shape',X_test.shape)
X_train.head()

, , , , .
, () , , . , , , .
.
:
if BUILD95:
feature_imp=pd.DataFrame(sorted(zip(clf.feature_importances_,cols)), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False).iloc[:50])
plt.title('XGB95 Most Important Features')
plt.tight_layout()
plt.show()
del clf, h; x=gc.collect()

, , . : ? . , , . , , SHAP. , , : 20 . 50 .
:
import shap
shap.initjs()
shap_test = shap.TreeExplainer(h).shap_values(X_train.loc[idxT,cols])
shap.summary_plot(shap_test, X_train.loc[idxT,cols],
max_display=25, auto_size_plot=True)
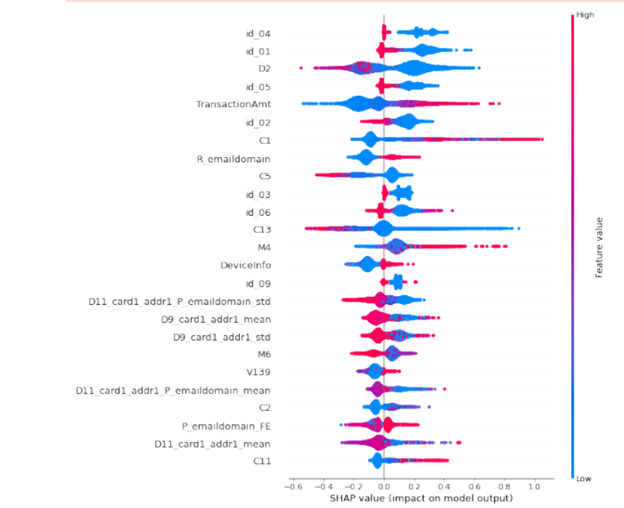
, . 2 . «0», «1». , . , . , , , : , , . , email.
Sur la base des données obtenues, il est possible d'alléger le modèle, c'est-à-dire de ne laisser que les paramètres qui ont un impact significatif sur les résultats de prédiction de notre modèle. De plus, il devient possible d'évaluer l'importance des fonctionnalités pour certains sous-groupes de données, par exemple, des clients de différentes régions, des transactions à différents moments de la journée, etc. De plus, cet outil peut être utilisé pour analyser des cas individuels, pour exemple, pour analyser les «valeurs aberrantes» et les valeurs extrêmes. SHAP peut également aider à trouver des zones de chute lors de la classification des phénomènes négatifs. Cet outil, en combinaison avec d'autres approches, rendra les modèles plus légers, de meilleure qualité et les résultats interprétables.