Réseau neuronal haute performance profond pour les données tabulaires TabNet
introduction
Les réseaux de neurones profonds (GNN) sont devenus l'un des outils les plus attractifs pour créer des systèmes d'intelligence artificielle (SRI), par exemple la reconnaissance vocale, la communication naturelle, la vision par ordinateur [2-3], etc. En particulier, grâce à la sélection automatique de GNS importants, caractéristiques de définition, connexions à partir de données. Des architectures de réseaux neuronaux (néocognitroniques, convolutifs, deep trust, etc.), des modèles et des algorithmes d'apprentissage GNS (autoencodeurs, machines Boltzmann, récurrents contrôlés, etc.) se développent. Les GNS sont difficiles à entraîner, principalement en raison de problèmes de gradient qui disparaissent.
L'article traite de la nouvelle architecture canonique de GNS pour les données tabulaires (TabNet), conçue pour afficher un «arbre de décision». Le but est d'hériter des avantages des méthodes hiérarchiques (interprétabilité, sélection de fonctionnalités éparse) et des méthodes basées sur GNS (apprentissage étape par étape et de bout en bout). Plus précisément, TabNet répond à deux besoins clés: hautes performances et interprétabilité. Les performances élevées ne suffisent souvent pas - GNS doit interpréter, remplacer les méthodes arborescentes.
TabNet est un réseau neuronal de couches entièrement connectées avec un mécanisme d'attention séquentielle qui:
utilise une sélection restreinte d'objets par instances, obtenue à partir du jeu de données d'apprentissage;
crée une architecture séquentielle à plusieurs étages dans laquelle chaque étape de décision peut contribuer à la partie de la décision qui est basée sur les fonctions sélectionnées;
améliore la capacité d'apprentissage grâce à des transformations non linéaires de fonctions sélectionnées;
simule un ensemble, impliquant des mesures plus précises et plus d'étapes d'amélioration.
Chaque couche d'une architecture donnée (Fig. 1) est une étape de solution contenant un bloc avec des couches entièrement connectées pour transformer les caractéristiques - un transformateur de caractéristiques et un mécanisme d'attention pour déterminer l'importance des caractéristiques d'origine d'entrée.

1. Convertisseur de fonctions
1.1. Normalisation par lots
- . . , (, ), , . (covariate shift).
. , — . ( ) , . , , , .
. , — , . , , ( , – ) . . - (batch normalization), 2015 [4].
- .
1. d: x = (x1, . . . , xd). k- x ( ):

2. . , . , , (

[−1, 1] ).
, :

γ, β .
3. , , -,


4. .
-:
, , ;
, ;
, ;
.
1.2. GLU
[5] Gated Linear Unit, , , LSTM-.
GLU
, , , . H = [h0 ,..., hN] w0, ... ,wN, P (wi |hi). f H hi = f(hi - 1 , wi - 1) , i ( , ).
f H = f * w , , , , , . . , , [5] , , .
. 2 . , D |V| x e, |V| - ( ), e - . w0, … , wN, E = [Dw0, … , DwN]. h0 , …hL

m, n – , , k - , X ∈ R N×m - hl ( , ),
, σ - ⊗ .
, hi . , . , k-1, , - , , k - .

X * W + b, σ(X * V + c). LSTM, X * W + b , . (GLU). E H = hL◦. . .◦h0 (E).
(GLU) , .
3.3 LSTM
LSTM (long short-term memory, – ) — , . LSTM , , [5].
LSTM . — , !
. , , tanh.
LSTM
LSTM .
LSTM , . , « ». h x 0 1 C. 1 « », 0 — « ».
. , . , . , .
, . . , « », , . tanh - C, . .
, .
C. , .
f, , . i*C. , , .
, .
, , . . , , . tanh ( [-1, 1]) .
, , , . , , ( ) .
TabNet

3.4. Split:
Feature Transformer , . , , Attentive Transformer , . (backpropagation) , «» , ( ). , . , Attentive Transformer . , "" , , .
SPLIT
: (. . 1) .
, , ( ), , .
. 3 . FC BN (GLU) , . √0.5 , , . . BN, , , BN BV mB. , , BN. , , . 3,
:
. softmax ( argmax ).
4.
. (), ( ) Softmax, , , : , - , — .
, , ht, t=1 …m, d , .
C d di−1 .
s — hi « ».
, s softmax. e=softmax(s)
softmax :
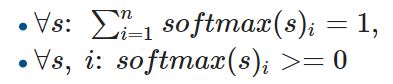
:

cc , hi ei.
. , , , , , . Softmax, Sparsemax. , , - , Softmax , . «» «» , - .
5. SPARSEMAX
, z z, . :

τ(z) S(z), p. softmax , , , softmax .
, . softmax , sparsemax :
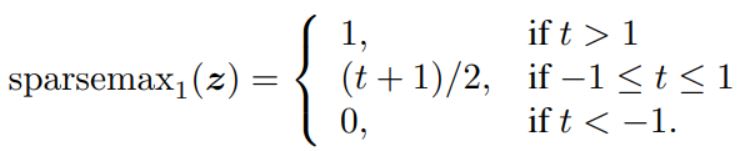
, :

, sparsemax , , :

|S(z)| - S(z).
, , , , Sparsemax.
,
6.
, , , , - . . , , . ( ), () , , , .
:
. , , , , . : M[i] · f. (. . 1) , , a[i − 1]:
Sparsemax [6] , .
,
h[i] - , . 4., FC, BN, P[i] - , , :

γ - : γ = 1, γ, . P[0] ,
- . ( ), P[0] , . :
ϵ - . λ, , .
, , . , , , - . , [5] , .
TabNet - . TabNet . , () , .
, , , .
.. // . : . 2017. .6, №3. .28–59. DOI: 10.14529/cmse170303
LeCun Y., Bengio Y., Hinton G. Deep Learning // Nature. 2015. Vol.521. Pp.436–444. DOI: 10.1038/nature14539.
Rav`ı D., Wong Ch., Deligianni F., et al. Deep Learning for Health Informatics // IEEE Journal of Biomedical and Health Informatics. 2017. Vol.21, No.1. PP.4–21. DOI: 10.1109/JBHI.2016.2636665.
Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal // Proceedings of The 32nd International Conference on Machine Learning (2015), pp.448-456.
Sercan O. Arik, Tomas Pfister. TabNet: Attentive Interpretable Tabular Learning // ICLR 2020 Conference Blind Submission 25 Sept 2019 (modified: 24 Dec 2019). URL:https://drive.google.com/file/d/1oLQRgKygAEVRRmqCZTPwno7gyTq22wbb/view?usp=sharing
Andre F. T. Martins and Ram´on Fern´andez Astudillo. 2016. From Softmax´ to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. arXiv:1602.02068.