
J'ai décidé d'écrire un article pour tous ceux qui essaient de trouver des questions et des réponses d'entrevue Amazon pertinentes. J'ai répondu à quelques questions d'entrevue qui ont été posées ces derniers mois et j'ai essayé de leur fournir des réponses concises et claires. Il y a des questions difficiles, il y en a des simples, mais dans tous les cas, les deux peuvent être utiles.
Q: Le couple a deux enfants et le couple sait que l'un des enfants est un garçon. Quelle est la probabilité que l'autre enfant soit un garçon?
Il n'y a pas de piège ici. La probabilité qu'un enfant soit un garçon est indépendante de l'autre, elle est donc de 50%. Vous pouvez être confus par la question de Leonard Mlodinov , où la réponse est d'un tiers, mais c'est une question complètement différente, sans rapport avec la nôtre.
Q: Expliquez ce qu'est une valeur p.
Si vous recherchez sur google ce qu'est une valeur p, vous obtiendrez la réponse suivante: "C'est la probabilité d'obtenir pour un modèle probabiliste donné de la distribution des valeurs d'une variable aléatoire la même valeur ou une valeur plus extrême des statistiques ( moyenne, médiane, etc.), par rapport à l’observation précédente, à condition que l’hypothèse nulle soit correcte. »
Réponse verbeuse, parce que p a un sens très spécifique et est souvent mal compris.
Une définition plus simple d'une valeur p est: "C'est la probabilité que la statistique observée se produise par hasard, étant donné la distribution de l'échantillon."
Alpha définit la norme sur la façon dont les valeurs extrêmes doivent être avant que l'hypothèse nulle puisse être rejetée. La valeur p indique l'extrême des données.
Q: Il y a 4 boules rouges et 2 bleues, quelle est la probabilité qu'elles soient identiques à deux élections?
La réponse est la probabilité que les deux soient rouges, plus la probabilité que les deux soient bleus. Supposons que cette question soit sans remplacement.
- Probabilité de 2 rouges = (4/6) * (3/6) = 1/3 ou 33%
- Probabilité de 2 bleus = (2/6) * (1/6) = 1/18 ou 5,6%
Par conséquent, la probabilité que les balles soient les mêmes est d'environ 38,6%.
Q: Décrivez l'arbre, le SVM et la forêt aléatoire. Parlez-nous de leurs avantages et inconvénients.
Arbres de décision: un modèle d'arbre utilisé pour modéliser des décisions basées sur une ou plusieurs conditions.
Avantages: Facile à mettre en œuvre, intuitif, gère les valeurs manquantes.
Inconvénients: variance élevée, imprécis
Avantages: précision dimensionnelle élevée
Inconvénients: tendance au surajustement, n'évalue pas directement la probabilité
Avantages: Peut atteindre une plus grande précision, gérer les valeurs manquantes, aucune mise à l'échelle de fonction requise, peut déterminer l'importance de la fonction.
Inconvénients: boîte noire, intensif en calcul.
La réduction de dimensionnalité est le processus de réduction du nombre d'entités dans un jeu de données. Ceci est principalement important lorsque vous souhaitez réduire la variance de votre modèle (sur-ajustement).
Wikipédia énonce quatre avantages de la réduction de la dimensionnalité:
- Réduit le temps et l'espace de stockage requis.
- La suppression de la multicolinéarité améliore l'interprétation des paramètres du modèle d'apprentissage automatique.
- Il devient plus facile de visualiser les données lorsqu'elles sont réduites à de très petites dimensions telles que 2D ou 3D.
- Évite la malédiction de la dimension.
Nous devons faire certaines hypothèses sur cette question avant de pouvoir y répondre. Supposons qu'il existe deux emplacements possibles pour acheter un article particulier sur Amazon, et que la probabilité de le trouver à l'emplacement A est de 0,6 et B est de 0,8. La probabilité de trouver un produit sur Amazon peut être expliquée comme suit:
Nous pouvons reformuler ce qui précède comme P (A) = 0,6 et P (B) = 0,8. Supposons également qu'il s'agisse d'événements indépendants, ce qui signifie que la probabilité d'un événement ne dépend pas d'un autre. On peut alors utiliser la formule ...
P (A ou B) = P (A) + P (B) - P (A et B)
P (A ou B) = 0,6 + 0,8 - (0,6 * 0, 8)
P (A ou B) = 0,92
Q: S'il y a 8 balles de poids égal et 1 balle qui pèse un peu plus (9 balles au total), combien de pesées sont nécessaires pour déterminer quelle balle est la plus lourde?

Deux pesées sont requises (voir les parties A et B ci-dessus):
Vous devez diviser les neuf balles en trois groupes de trois et peser deux groupes. Si les échelles sont équilibrées (option 1), vous savez que la balle lourde appartient au troisième groupe de balles. Sinon, vous prendrez un groupe avec un poids important (option 2).
Ensuite, vous suivez la même étape, mais vous aurez trois groupes d'un ballon au lieu de trois groupes de trois.
Q: Qu'est-ce que le «recyclage»?
Le surajustement est une erreur lorsqu'un modèle «s'adapte» trop bien aux données, ce qui donne un modèle avec une variance élevée et un biais faible. En conséquence, le modèle de surajustement prédira de manière inexacte les nouveaux points de données, même s'il présente une haute fidélité dans les données d'apprentissage.
Q: Nous avons deux modèles, l'un avec une précision de 85%, l'autre avec une précision de 82%. Lequel allez-vous choisir?
Si nous ne nous soucions que de la précision du modèle, la réponse est 85%. Mais si l'enquêteur a posé la question à ce sujet, il vaut probablement la peine de savoir dans quel contexte la question est posée, c'est-à-dire ce que le modèle essaie de prédire. Cela nous donnera une meilleure idée de savoir si la métrique de notation doit vraiment être la précision ou une autre métrique comme le rappel ou le score f1.
Q: Qu'est-ce qu'un algorithme bayésien naïf?
Le classificateur bayésien naïf est un classificateur populaire utilisé en science des données. L'idée sous-jacente est basée sur le théorème de Bayes:

en termes simples, cette équation est utilisée pour répondre à la question suivante. «Quelle est la probabilité de y (ma variable de sortie) avec X (mes variables d'entrée)? Et à cause de l'hypothèse naïve que les variables sont indépendantes pour une classe donnée, on peut dire que:

De plus, en supprimant le dénominateur, on peut dire que P (y | X) est proportionnel au côté droit.
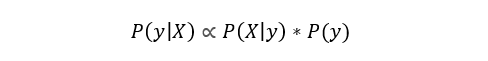
Par conséquent, le but est de trouver la classe avec la probabilité proportionnelle la plus élevée.
Q: Comment la modification de la cotisation de base affectera-t-elle le marché?
Je ne suis pas sûr à 100% de la réponse à cette question, mais je ferai de mon mieux!
Prenons un exemple d'augmentation de la cotisation de base - il y a deux parties impliquées: les acheteurs et les vendeurs.
Pour les acheteurs, l'impact d'une augmentation de la cotisation de base dépend en fin de compte de l'élasticité-prix de la demande pour les acheteurs. Si l'élasticité-prix est élevée, une augmentation de prix donnée entraînera une baisse significative de la demande et vice-versa. Les acheteurs qui continuent d'acheter des cotisations sont probablement les clients les plus fidèles et les plus actifs d'Amazon - ils accorderont probablement plus d'attention aux produits haut de gamme.
Les vendeurs en souffriront car le coût d'achat d'un panier de produits Amazon est désormais plus élevé. Cela rendra certains aliments plus affectés alors que d'autres ne le seront pas. Il est probable que les produits haut de gamme achetés par les clients les plus fidèles d'Amazon ne seront pas aussi durement touchés que l'électronique.
Merci de votre attention!
Ce que j'aime dans ces entretiens et les problèmes qu'ils traitent, ce sont deux choses:
- Ils vous aident à apprendre de nouveaux concepts que vous n'étiez pas familiers auparavant.
- Ils ouvrent des concepts que vous connaissez sous un nouvel angle.
J'espère que tout cela vous aidera à préparer votre voyage dans le monde de la science des données!
, Data Science AR- Banuba - Skillbox.
, -: , , . «» .
« ». . , , , .
:
1) , ?
2) ?
3) ?
4) , , -?
5) , ?
, .