Comment nous avons construit des univers parallèles pour notre (et votre) pipeline CI / CD dans Octopod

Bonjour, Habr! Je m'appelle Denis, et je vais vous dire comment il nous a été suggéré de faire une solution technique pour optimiser le processus de développement et le QA dans notre Typeable. Cela a commencé avec le sentiment général que nous faisions tout correctement, mais il serait toujours possible de progresser plus rapidement et plus efficacement - accepter de nouvelles tâches, tester, synchroniser moins. Tout cela nous a conduit à des discussions et des expérimentations, qui ont abouti à notre solution open-source, que je décrirai ci-dessous et qui est désormais à votre disposition.
Cependant, ne courons pas en avance sur la locomotive, mais commençons par le tout début et comprenons en détail de quoi je parle. Imaginons une situation assez standard - un projet avec une architecture à trois niveaux (stockage, backend, frontend). Il existe un processus de développement et un processus d'assurance qualité dans lesquels il existe plusieurs environnements (souvent appelés contours) pour les tests:
- La production est le principal environnement de travail où se rendent les utilisateurs du système.
- Pre-Production – - (, production, ; RC), production, production . Pre-production – , Production .
- Staging – , , , Production, .
Avec la pré-production, tout est assez clair: les release candidates y vont systématiquement, l'historique des sorties est le même qu'en Production . Il y a des nuances avec la mise en scène :
- ORGANISATIONNEL. Le test des pièces critiques peut nécessiter un délai dans la publication des nouvelles modifications; les changements peuvent interagir de manière imprévisible; les erreurs de traçage deviennent difficiles en raison de la grande quantité d'activité sur le serveur; il y a parfois confusion sur la version implémentée; il est parfois difficile de savoir lequel des changements accumulés a causé le problème.
- . : production , «». staging , . . : , . , QA production , .
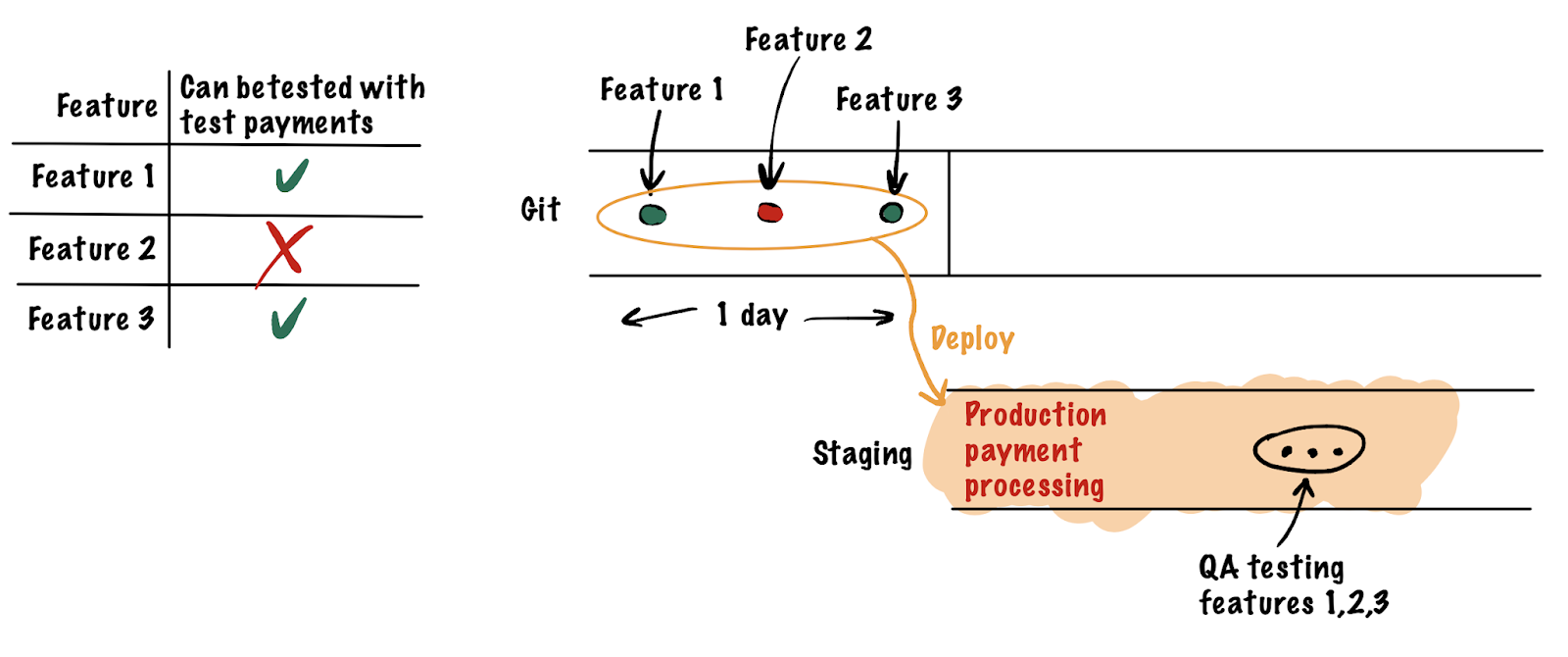
- .
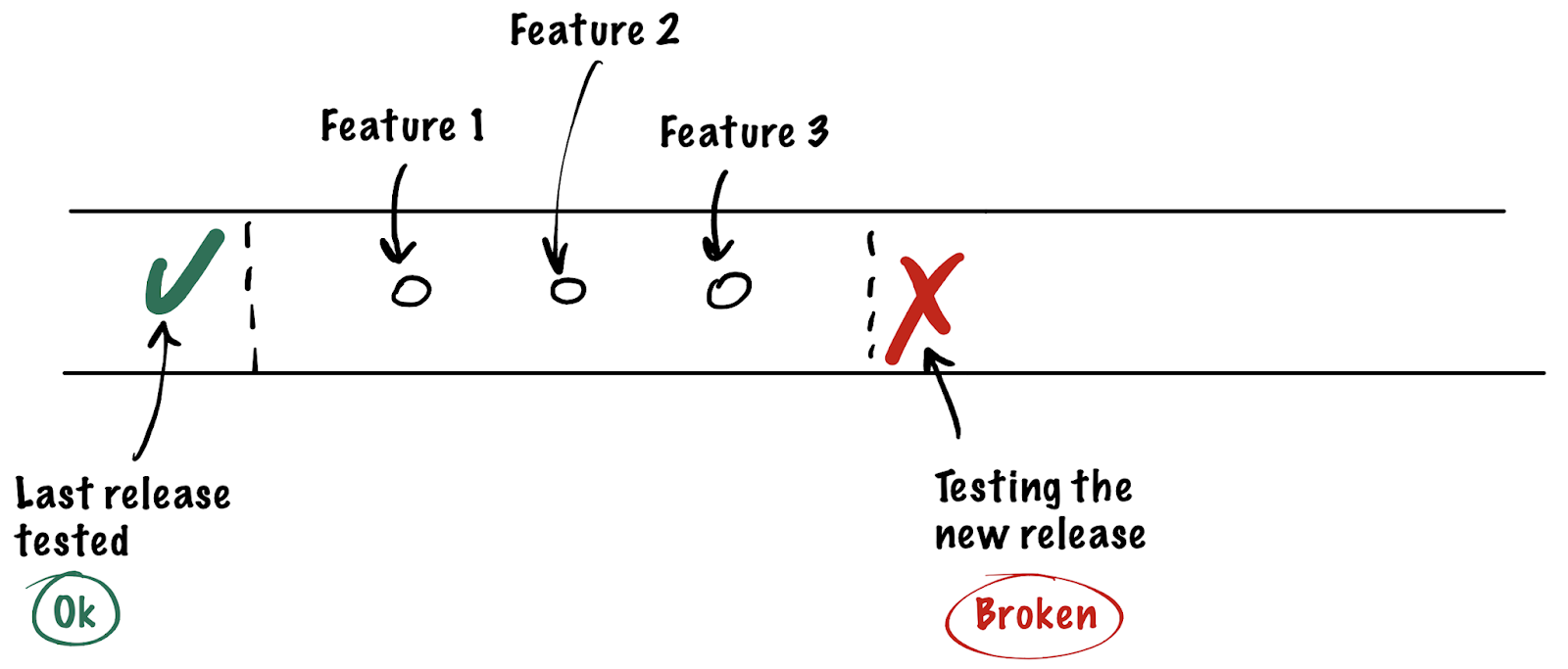
- . . -. , . , . , .
- . - , , , , . , , , . , . production , time-to-production time-to-market .
Chacun de ces points est résolu d'une manière ou d'une autre, mais tout cela a conduit à la question, sera-t-il possible de nous simplifier la vie si nous nous éloignons du concept de stand de mise en scène à leur nombre dynamique. De la même manière que nous avons des vérifications CI pour chaque branche dans git, nous pouvons obtenir des supports de contrôle qualité pour chaque branche. La seule chose qui nous empêche d'une telle démarche est le manque d'infrastructure et d'outils. En gros, pour accepter une fonctionnalité, une mise en scène distincte est créée avec un nom de domaine dédié, le contrôle qualité, l'accepte ou le renvoie pour révision. Quelque chose comme ça:

Avec cette approche, le problème des différents environnements est résolu de manière naturelle:

Fait révélateur, après la discussion, les opinions de l'équipe ont été divisées en «essayons, je veux mieux que maintenant» et «cela semble si normal, je ne vois pas de problèmes monstrueux», mais nous y reviendrons plus tard.
Notre chemin vers la solution
La première chose que nous avons essayée était un prototype construit par notre DevOps: une combinaison de docker-compose (orchestration), rundeck (gestion) et portainer (introspection), qui nous a permis de tester la direction générale de la pensée et de l'approche. Il y a eu des problèmes de commodité:
- Tout changement nécessitait un accès au code et à la vérification, que les développeurs possédaient, mais n'avaient pas, par exemple, les ingénieurs QA.
- Cela a été soulevé sur une grande machine, qui est rapidement devenue insuffisante, et pour l'étape suivante, Kubernetes ou quelque chose de similaire était déjà nécessaire.
- Portainer a donné des informations non pas sur l'état d'une étape particulière, mais sur un ensemble de conteneurs.
- Je devais constamment fusionner le fichier avec la description des étapes, les anciens stands devaient être supprimés.
Malgré tous ses inconvénients et avec quelques inconvénients de fonctionnement, l'approche est arrivée et a commencé à économiser le temps et les efforts de l'équipe de projet. L'hypothèse a été testée, et nous avons décidé de tout faire de la même manière, mais de manière serrée. Dans le but d'optimiser le processus de développement, nous avons rassemblé les exigences pour un nouveau et compris ce que nous voulions:
- Utilisez Kubernetes pour évoluer vers n'importe quel nombre d'environnements de préparation et disposez d'un ensemble standard d'outils pour les DevOps modernes.
- Une solution qui serait facile à intégrer dans l'infrastructure utilisant déjà Kubernetes.
- , Product QA-. , . – .
- , CI/CD , . , Github Actions CI.
- , DevOps .
- , , / - .
- Des informations complètes et une liste d'actions doivent être mises à la disposition des super-utilisateurs en la personne des ingénieurs DevOps et des chefs d'équipe.
Et nous avons commencé à développer Octopod . Le nom était une confusion de plusieurs réflexions sur K8S, que nous avons utilisé pour tout orchestrer sur le projet: de nombreux projets dans cet écosystème reflètent une esthétique et des thèmes marins, et nous avons imaginé une sorte de poulpe orchestrant de nombreux conteneurs sous-marins à tentacules. De plus, le Pod est l'une des entités fondatrices de Kubernetes.
Sur la pile technique, Octopod est Haskell, Rust, FRP, compilation vers JS, Nix. Mais en général, l’histoire n’est pas à ce sujet, donc je n’y reviendrai pas plus en détail.
Le nouveau modèle est devenu connu sous le nom de Multi-staging au sein de notre entreprise. Exploiter simultanément plusieurs environnements de mise en scène revient à voyager à travers des univers et des dimensions parallèles dans la science-fiction (et pas tellement). Dans ce document, les univers sont similaires les uns aux autres à l'exception d'un petit détail: quelque part différentes parties ont gagné la guerre, quelque part une révolution culturelle s'est produite, quelque part une percée technologique. La prémisse est peut-être petite, mais quels changements cela peut entraîner! Dans nos processus, cette condition préalable est le contenu de chaque branche de fonctionnalité distincte.
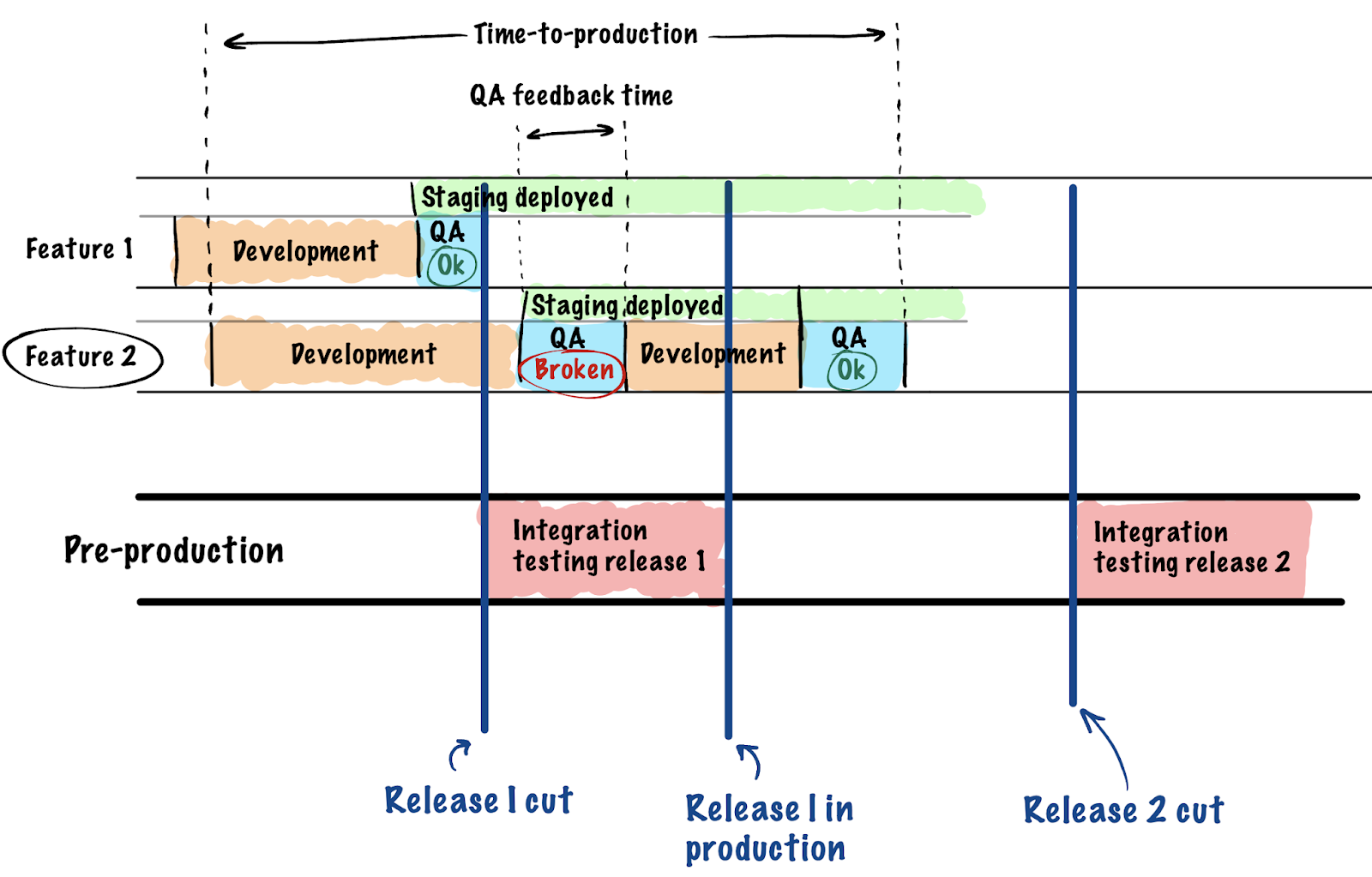
Notre implémentation s'est déroulée en plusieurs étapes et a commencé avec un seul projet. Cela inclut l'ajustement de l'orchestration du projet du côté DevOps et la réorganisation du processus de test et de communication du chef de projet.
À la suite d'un certain nombre d'itérations, certaines fonctionnalités d'Octopod lui-même ont été supprimées ou modifiées au-delà de la reconnaissance. Par exemple, dans la première version, nous avions une page avec un journal de déploiement pour chaque circuit, mais voici la malchance: toutes les équipes n'acceptent pas que les informations d'identification puissent circuler à travers ces journaux vers tous les employés impliqués dans le développement. En conséquence, nous avons décidé de nous débarrasser de cette fonctionnalité, puis de la renvoyer sous une forme différente - elle est désormais personnalisable (et donc facultative) et implémentée via l'intégration avec le tableau de bord kubernetes .
Il y a aussi d'autres points: avec la nouvelle approche, nous utilisons plus de ressources de calcul, de disques et de noms de domaine pour supporter l'infrastructure, ce qui pose la question de l'optimisation des coûts. Si vous combinez cela avec des subtilités DevOps, le matériel sera tapé dans un article séparé, voire deux, donc je ne continuerai pas à ce sujet ici.
Parallèlement à la résolution de problèmes émergents sur un projet, nous avons commencé à intégrer cette solution dans un autre, lorsque nous avons constaté l'intérêt d'une autre équipe. Cela nous a permis de nous assurer que notre solution était personnalisable et suffisamment flexible pour les besoins des différents projets. À l'heure actuelle, Octopod est largement utilisé dans notre pays depuis trois mois.
Par conséquent
En conséquence, le système et les processus sont mis en œuvre dans plusieurs projets, il y a de l'intérêt d'un autre. Il est intéressant de noter que même les collègues qui ne voyaient aucun problème avec l'ancien système ne voudraient pas y revenir. Il s'est avéré que pour certains, nous avons résolu des problèmes qu'ils ne connaissaient même pas!
Le plus difficile, comme d'habitude, a été la première mise en œuvre - la plupart des problèmes et problèmes techniques ont été pris en compte. Les retours des utilisateurs ont permis de mieux comprendre ce qui doit être amélioré en premier lieu. Dans les dernières versions, l'interface et le travail avec Octopod ressemblent à ceci:
Pour nous, Octopod est devenu une réponse à une question de procédure, et j'appellerais l'état actuel un succès sans équivoque - la flexibilité et la commodité ont clairement augmenté. Il n'y a toujours pas de problèmes entièrement résolus: nous faisons glisser l'autorisation d'Octopod lui-même dans le cluster vers Atlassian oauth pour plusieurs projets, et ce processus est retardé. Cependant, ce n'est rien de plus qu'une question de temps, techniquement le problème a déjà été résolu en première approximation.
Open source
Nous espérons qu'Octopod sera utile non seulement pour nous. Nous serons heureux de recevoir des suggestions, des pull requests et des informations sur la façon dont vous optimisez des processus similaires. Si le projet intéresse le public, nous écrirons avec nous sur les caractéristiques de l'orchestration et du fonctionnement.
Tout le code source avec des exemples de configuration et de la documentation est disponible dans le référentiel sur Github .