
Bonjour, Habr! Plus récemment, nous avons écrit sur un ensemble de données ouvert assemblé par une équipe d'étudiants diplômés en Data Science de NUST MISIS et Zavtra.Online (département universitaire de SkillFactory) dans le cadre du premier Dataton éducatif. Et aujourd'hui, nous vous présenterons jusqu'à 3 ensembles de données d'équipes qui ont également atteint la finale.
Ils sont tous différents: certains ont fait des recherches sur le marché de la musique, certains ont étudié le marché du travail des informaticiens et certains ont étudié les chats domestiques. Chacun de ces projets est pertinent dans son propre domaine et peut être utilisé pour améliorer quelque chose dans le cours habituel du travail. Un jeu de données avec des chats, par exemple, aidera les juges lors des expositions. Les ensembles de données que les étudiants devaient collecter devaient être MVP (table, json ou structure de répertoires), les données devaient être nettoyées et analysées. Voyons ce qu'ils ont fait.
Dataset 1: Glissez sur des ondes musicales avec Data Surfers
S'aligner:
- Plotnikov Kirill - chef de projet, développement, documentation.
- Dmitry Tarasov - développement, collecte de données, documentation.
- Shadrin Yaroslav - développement, collecte de données.
- Merzlikin Artyom - chef de produit, présentation.
- Ksenia Kolesnichenko - analyse des données préliminaires.
Dans le cadre de leur participation au hackathon, les membres de l'équipe ont proposé plusieurs idées intéressantes, mais nous avons décidé de nous concentrer sur la collecte de données sur les artistes de musique russes et leurs meilleurs morceaux de Spotify et MusicBrainz.
Spotify est une plate-forme musicale qui est arrivée en Russie il n'y a pas si longtemps, mais qui gagne déjà activement en popularité sur le marché. De plus, en termes d'analyse des données, Spotify fournit une API très pratique avec la possibilité d'interroger une grande quantité de données, y compris leurs propres métriques, telles que la «dansabilité» - un score de 0 à 1 qui décrit la qualité d'une piste pour danser.
MusiqueBrainzEst une encyclopédie musicale contenant les informations les plus complètes sur les groupes musicaux existants et existants. Une sorte de "wikipedia musical". Nous avions besoin des données de cette ressource pour obtenir une liste de tous les artistes de Russie.
Collecte de données sur les artistes
Nous avons compilé un tableau complet contenant 14363 entrées uniques pour divers artistes. Pour faciliter la navigation, il y a une description des champs de la table sous le spoiler.
Description des champs de table
artist – ;
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .

Exemple de
champs d' enregistrement L' artiste, musicbrainz_id et le type sont extraits de la base de données de musique Musicbrainz, car il est possible d'obtenir une liste d'artistes associés à un pays. Il existe deux façons de récupérer ces données:
- Parcourez la section Artistes sur la page avec des informations sur la Russie.
- Obtenez des données via l'API.
Documentation de l' API MusicBrainz Exemple de recherche de la
documentation de l' API MusicBrainz GET Request sur musicbrainz.org
Au cours du travail, il s'est avéré que l'API MusicBrainz ne répond pas tout à fait correctement à une demande avec le paramètre Area: Russia, nous cachant les artistes qui ont une zone spécifiée, par exemple Izhevsk ou Moskva. Par conséquent, les données de MusicBrainz ont été prises par l'analyseur directement à partir du site. Vous trouverez ci-dessous un exemple de la page à partir de laquelle les données ont été analysées.
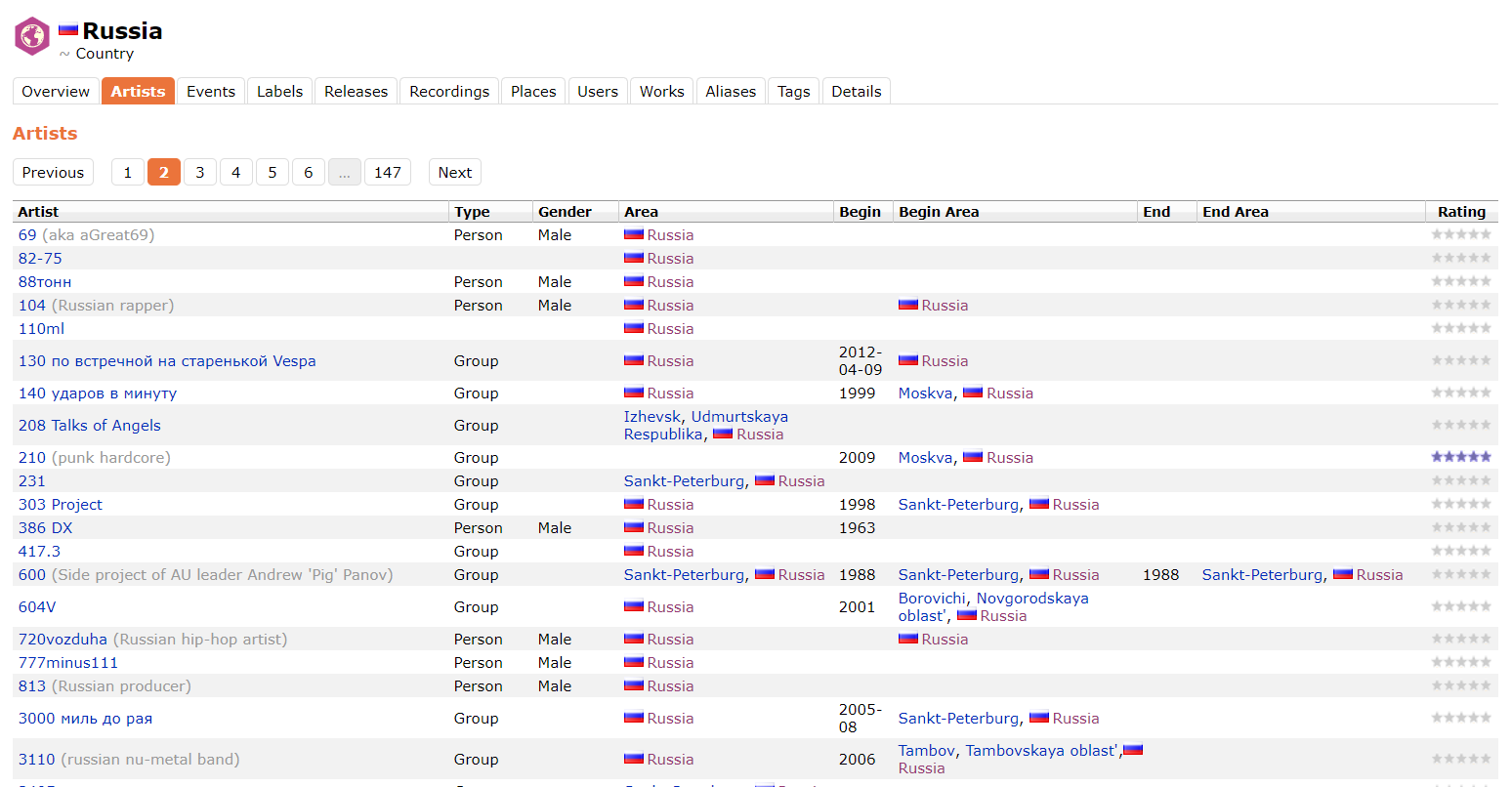
Les données obtenues sur les artistes de Musicbrainz.
Le reste des champs est obtenu à la suite de requêtes GET au point de terminaison . Lors de l'envoi d'une demande, spécifiez le nom de l'artiste dans la valeur du paramètre q et spécifiez l'artiste dans la valeur du paramètre type.
Collecte de données sur les pistes populaires
Le tableau contient 44473 enregistrements des morceaux les plus populaires d'artistes russes, présentés dans le tableau ci-dessus. Sous le spoiler, il y a une description des champs de la table.
Description des champs de table
artist – ;
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
Caractéristiques audio
key – , , 0 = C, 1 = C♯/D♭, 2 = D ..;
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
Vous pouvez en savoir plus sur chaque paramètre ici .

Un exemple d'enregistrement Les
champs nom, spotify_id, duration_ms, explicite, popularité, album_type, album_name, album_spotify_id, release_date sont obtenus à l'aide d'une requête GET pour
https://api.spotify.com/v1//v1/artists/{id}/top-tracks
, en spécifiant l'id de l'identifiant Spotify de l'artiste que nous avons reçu précédemment, et dans la valeur du paramètre de marché, nous spécifions RU. Documentation .
Le champ album_popularity peut être obtenu en effectuant une requête GET pour
https://api.spotify.com/v1/albums/{id}
, en spécifiant l'album_spotify_id obtenu précédemment comme valeur du paramètre id. Documentation .
En conséquence, nous obtenons les donnéessur les meilleures pistes d'artistes Spotify. Maintenant, le défi est d'obtenir les fonctionnalités audio. Ceci peut être fait de deux façons:
- Pour obtenir des données sur une piste, vous devez effectuer une requête GET pour
https://api.spotify.com/v1/audio-features/{id}
, en spécifiant son ID Spotify comme valeur du paramètre id. Documentation .
- Pour obtenir des données sur plusieurs pistes à la fois, vous devez envoyer une requête GET à
https://api.spotify.com/v1/audio-features
, en passant l'ID Spotify de ces pistes séparés par des virgules comme valeur du paramètre ids. Documentation .
Tous les scripts sont dans le référentiel à ce lien .
Après avoir collecté les données, nous avons effectué une analyse préliminaire, qui est visualisée ci-dessous.
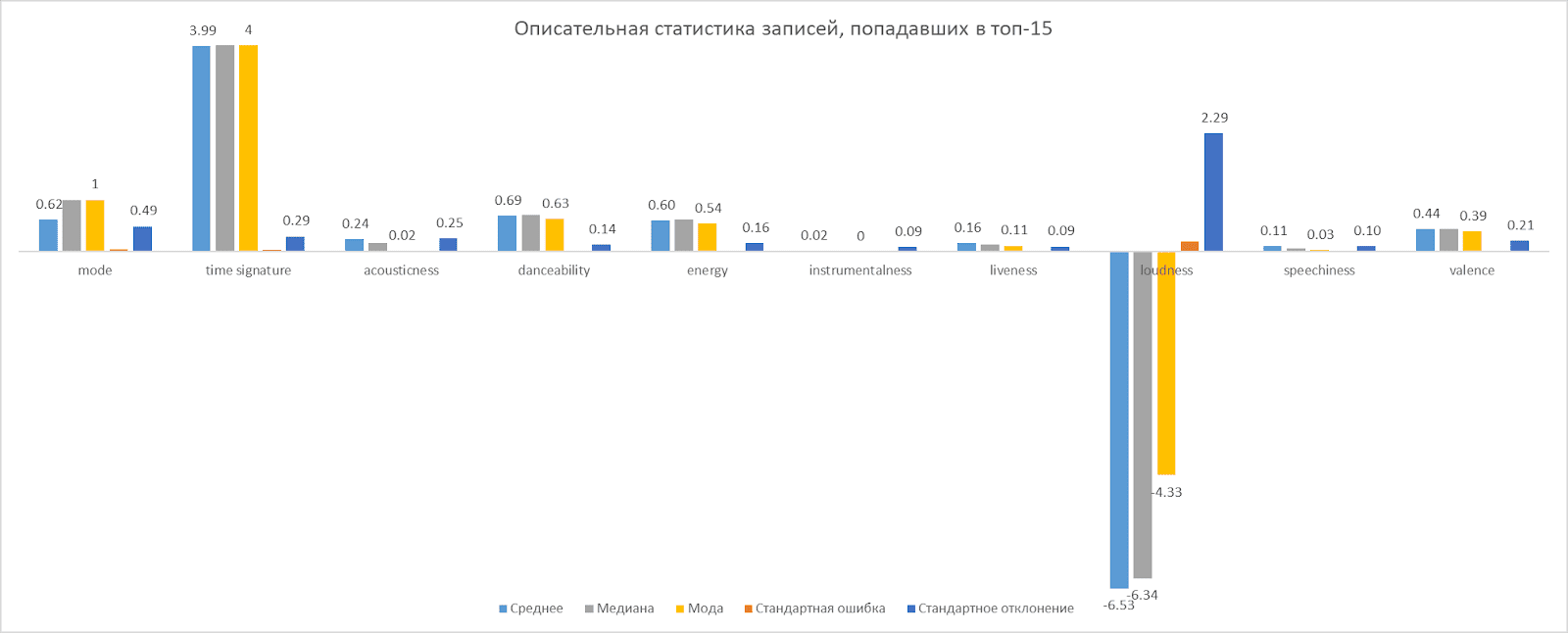
Résultat
En conséquence, nous avons réussi à collecter des données sur 14363 artistes et 44473 titres. En combinant les données de MusicBrainz et Spotify, nous avons obtenu l'ensemble de données le plus complet à ce jour de tous les artistes de musique russes représentés sur la plateforme Spotify.
Un tel jeu de données permettra de créer des produits B2B et B2C dans le domaine de la musique. Par exemple, des systèmes de recommandation d'artistes à des promoteurs dont les concerts peuvent être organisés ou des systèmes pour aider les jeunes artistes à écrire des morceaux qui sont plus susceptibles de devenir populaires. En outre, avec le réapprovisionnement régulier de l'ensemble de données avec des données fraîches, vous pouvez analyser diverses tendances de l'industrie de la musique, telles que la formation et la croissance de la popularité de certaines tendances de la musique, ou analyser les artistes interprètes individuellement. L'ensemble de données lui-même peut être consulté sur GitHub .
Dataset 2: Nous étudions le marché du travail et identifions les compétences clés avec "Hedgehog is clear"
S'aligner:
- Andrey Pshenichny - collecte et traitement des données, rédaction d'une note analytique sur l'ensemble de données.
- Pavel Kondratenok - Chef de produit, collecte de données et description de son processus, GitHub.
- Svetlana Shcherbakova - collecte et traitement des données.
- Evseeva Oksana - préparation de la présentation finale du projet.
- Elfimova Anna - Chef de projet.
Pour notre ensemble de données, nous avons choisi l'idée de collecter des données sur les postes vacants en Russie à partir de la sphère informatique et télécom à partir du site hh.ru pour octobre 2020.
Collecte de données sur les compétences
La métrique la plus importante pour toutes les catégories d'utilisateurs est les compétences clés. Cependant, lors de leur analyse, nous avons rencontré des difficultés: lors du remplissage des données de postes vacants, les RH sélectionnent les compétences clés dans la liste et peuvent également les saisir manuellement, et par conséquent, un grand nombre de compétences en double et de compétences incorrectes sont entrées dans notre ensemble de données (par exemple , nous avons rencontré le nom de la compétence clé "0,4 Ko"). Il y a une autre difficulté qui a posé des problèmes lors de l'analyse de l'ensemble de données résultant - seulement environ la moitié des postes vacants contiennent des données sur les salaires, mais nous pouvons utiliser les indicateurs de salaire moyen d'une autre ressource (par exemple, des ressources My Circle ou Habr.Career).
Nous avons commencé par l'acquisition de données et une analyse approfondie. Ensuite, nous avons échantillonné les données, c'est-à-dire que nous avons sélectionné des caractéristiques (caractéristiques ou, en d'autres termes, des prédicteurs) et des objets, en tenant compte de leur pertinence aux fins du Data Mining, de la qualité et des contraintes techniques (volume et type).
Ici, nous avons été aidés par l'analyse de la fréquence de mention des compétences dans les balises des compétences requises dans la description de poste, quelles caractéristiques de la vacance affectent la récompense proposée. Parallèlement, 8915 compétences clés ont été identifiées. Vous trouverez ci-dessous un tableau montrant les 10 principales compétences clés et la fréquence à laquelle elles sont mentionnées.
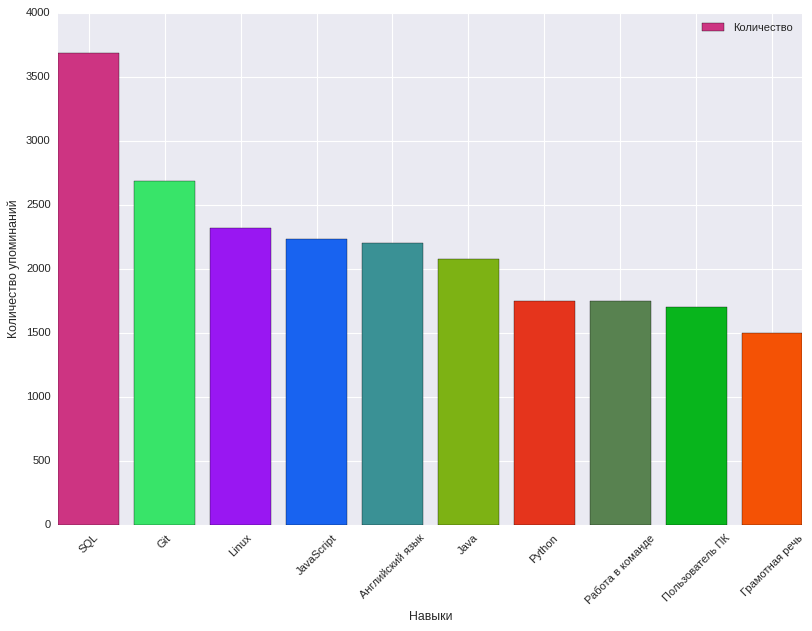
Les compétences clés les plus courantes dans les postes vacants en informatique, les
données de télécommunications, ont été obtenues à partir du site Web hh.ru à l'aide de leur API. Le code de téléchargement des données peut être trouvé ici . Nous avons sélectionné manuellement les fonctionnalités dont nous avons besoin pour l'ensemble de données. La structure et le type de données collectées peuvent être vus dans la description de la documentation de l'ensemble de données.
Après ces manipulations, nous avons obtenu un ensemble de données d'une taille de 34 513 lignes. Vous pouvez voir un échantillon des données collectées ci-dessous, ainsi que le lien .

Exemple de données collectées
Résultat
Le résultat est un ensemble de données avec lequel vous pouvez découvrir quelles compétences sont les plus demandées parmi les informaticiens dans différents domaines, et il peut être utile pour les demandeurs d'emploi (débutants et expérimentés), les employeurs, les spécialistes en ressources humaines, les organisations éducatives et les organisateurs. de conférences. Dans le processus de collecte des données, il y a également eu des difficultés: il y a trop de panneaux et ils sont rédigés dans un langage peu formalisé (description des compétences pour le candidat), la moitié des postes vacants ne disposent pas de données ouvertes sur les salaires. L'ensemble de données lui-même peut être consulté sur GitHub .
Ensemble de données 3: Profitez de la variété des chats avec l'équipe AA
S'aligner:
- Evgeny Ivanov - développement de web scraping.
- Sergey Gurylev - chef de produit, description du processus de développement, GitHub.
- Yulia Cherganova - préparation de la présentation du projet, analyse des données.
- Elena Tereshchenko - préparation des données, analyse des données.
- Yuri Kotelenko - chef de projet, documentation, présentation de projet.
Un jeu de données dédié aux chats? Pourquoi pas, avons-nous pensé. Notre ensemble de chats contient des exemples d'images de chats de différentes races.
Collecter des données sur les chats
Au départ, nous avons choisi catfishes.ru pour collecter des données , il a tous les avantages dont nous avons besoin: c'est une source gratuite avec une structure HTML simple et des images de haute qualité. Malgré les avantages de ce site, il présentait un inconvénient majeur - un petit nombre de photos en général (environ 500 pour toutes les races) et un petit nombre d'images de chaque race. Par conséquent, nous avons choisi un autre site - lapkins.ru .

En raison de la structure HTML légèrement plus complexe, le scraping du deuxième site était un peu plus difficile que le premier, mais la structure HTML était facile à comprendre. En conséquence, nous avons réussi à collecter déjà 2600 photos de toutes les races à partir du deuxième site.
Nous n'avons même pas eu besoin de filtrer les données, puisque les photos des chats sur le site sont de bonne qualité et correspondent aux races.
Pour collecter des images du site, nous avons écrit un grattoir Web. Le site contient une page lapkins.ru/cat avec une liste de toutes les races. Après avoir analysé cette page, nous avons obtenu les noms de toutes les races et des liens vers la page de chaque race. Après avoir parcouru de manière itérative chacune des roches, nous avons obtenu toutes les images et les avons placées dans les dossiers appropriés. Le code du scraper a été implémenté en Python à l'aide des bibliothèques suivantes:
- urllib : fonctions pour travailler avec des URL;
- html : fonctions de traitement XML et HTML;
- Shutil : fonctions de haut niveau pour la gestion des fichiers, des groupes de fichiers et des dossiers;
- OS : fonctions pour travailler avec le système d'exploitation.
Nous avons utilisé XPath pour travailler avec des balises.
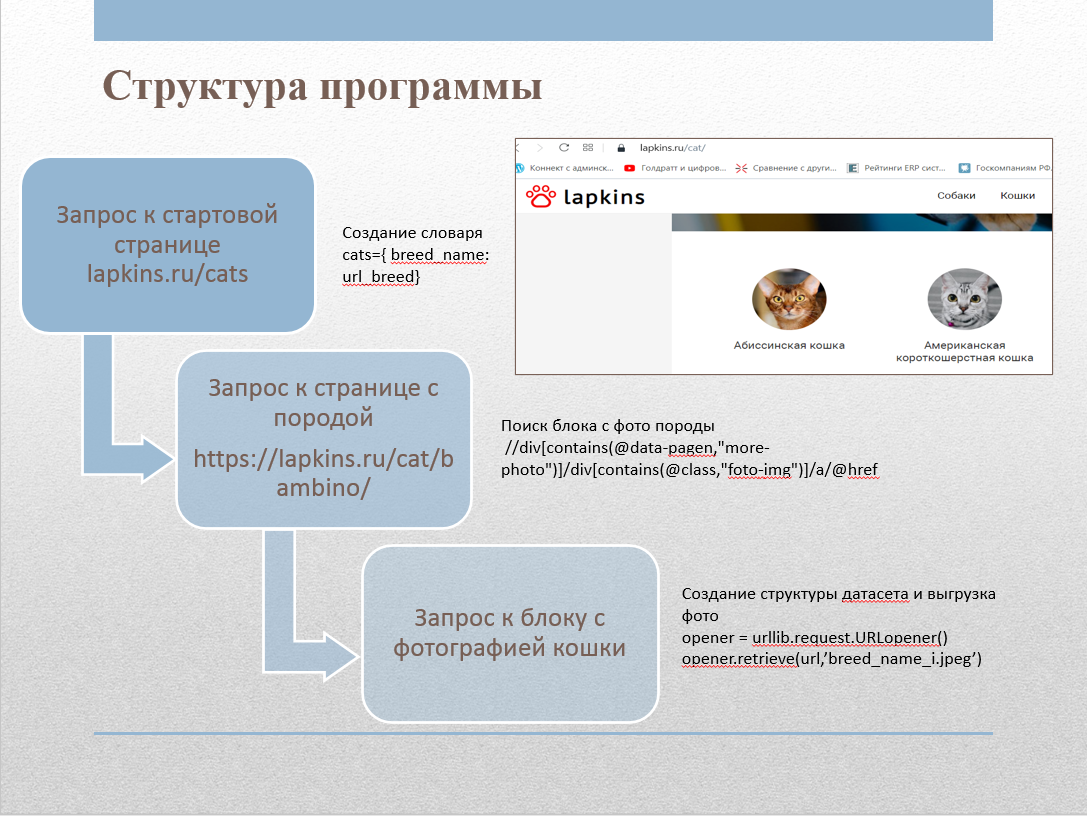
Le répertoire Cats_lapkins contient des dossiers dont les noms correspondent aux noms des races de chats. Le référentiel contient 64 répertoires pour chaque race. Au total, le jeu de données contient 2600 images. Toutes les images sont au format .jpg. Format du nom de fichier: par exemple "Abyssinian cat 2.jpg", vient d'abord le nom de la race, puis le numéro - le numéro de série de l'échantillon.

Résultat
Un tel jeu de données peut, par exemple, être utilisé pour former des modèles qui classent les chats domestiques par race. Les données collectées peuvent être utilisées aux fins suivantes: déterminer les caractéristiques de soins d'un chat, sélectionner une alimentation adaptée pour les chats de certaines races, ainsi qu'optimiser l'identification primaire de la race lors des expositions et lors du jugement. Cotoset peut également être utilisé par les entreprises - cliniques vétérinaires et fabricants d'aliments. Le cotoset lui-même est disponible gratuitement sur GitHub .
Épilogue
Sur la base des résultats de la dataton, nos étudiants ont reçu le premier cas de leur portefeuille de data scientist et des commentaires sur le travail de mentors d'entreprises telles que Huawei, Kaspersky Lab, Align Technology, Auriga, Intellivision, Wrike, Merlin AI. Dataton a également été utile dans la mesure où il a immédiatement pompé le profil des compétences techniques et non techniques dont les futurs scientifiques des données auront besoin lorsqu'ils travailleront déjà en équipes réelles. C'est aussi une bonne opportunité pour un «échange de connaissances» mutuel, puisque chaque étudiant a un parcours différent et, par conséquent, sa propre vision du problème et de sa solution possible. Nous pouvons dire avec confiance que sans un tel travail pratique, similaire à certaines tâches commerciales déjà existantes, la formation de spécialistes du monde moderne est tout simplement impensable.
Vous pouvez en savoir plus sur notre programme de maîtrise sur le site Web data.misis.ru et sur la chaîne Telegram .
Eh bien, et bien sûr pas un seul master! Si vous voulez en savoir plus sur la science des données , l' apprentissage automatique et l'apprentissage profond , jetez un œil à nos cours correspondants, ce sera difficile, mais passionnant. Et le code promo HABR vous aidera à apprendre de nouvelles choses en ajoutant 10% à la réduction sur la bannière.

Autres professions et cours