
Comment faire en sorte que tout développeur puisse rapidement apporter une solution à son problème et garantir sa livraison en production? Le déploiement de l'application est simple. En faire un produit à part entière pour qu'une dizaine d'équipes l'utilisent sur une centaine d'instances est plus difficile. Et si nous parlons d'un système maître pour plusieurs téraoctets, le niveau d'anxiété augmente, les mains transpirent et la base éclate (peut-être).
Je souhaite partager un moyen de déployer sans temps d'arrêt et sans déni de service. Pipeline Jenkins, zéro intermédiaire, 500 instances dans un environnement de production en 60 minutes. Tout cela est en open source. Pour plus de détails je vous invite sous chat.
Je m'appelle Roman Proskin, je crée et supporte des systèmes à forte charge basés sur Tarantool chez Mail.ru Group. Je vais vous dire comment notre équipe a construit un déploiement d'application Tarantool, qui met à jour le code dans un environnement de production sans temps d'arrêt ni déni de service. Je décrirai les problèmes que nous avons rencontrés au cours du processus et les solutions que nous avons choisies à la fin. J'espère que notre expérience vous sera utile pour construire votre déploiement.
Le déploiement d'une application est simple. Tarantool a un utilitaire cartouche-cli ( github). Avec lui, l'application en cluster sera déployée quelque part dans Docker dans quelques minutes. Il est beaucoup plus difficile de transformer une solution du genou en un produit à part entière. Il devrait facilement gérer des centaines d'instances. En même temps, vous devez être sollicité dans des dizaines d'équipes de différents niveaux de formation.
L'idée derrière notre déploiement est très simple:
- Vous prenez deux serveurs en fer.
- Sur chacun, vous lancez une instance.
- Combinez-les en un seul ensemble de répliques.
- Vous mettez à jour un par un.
Mais quand il s'agit d'un système maître avec plusieurs téraoctets de données, le niveau d'anxiété augmente, les mains transpirent et la base éclate (peut-être).
Définition des conditions initiales
Le système a un SLA strict: il est nécessaire d'assurer une disponibilité de 99%, en tenant compte des travaux prévus. Cela signifie qu'il y a un total de 87 heures par an pendant lesquelles nous pouvons nous permettre de ne pas répondre aux demandes de renseignements. Il semble que 87 heures, c'est beaucoup, mais ...
Le projet est conçu pour un volume de données d'environ 1,8 To. Seul le redémarrage prendra 40 minutes! La mise à jour elle-même, si les modifications sont effectuées manuellement, en ajoutera plus par le haut. Nous faisons trois mises à jour par semaine: un total de 40 * 3 * 52/60 = 104 heures - SLA est violé . Et ce ne sont que des travaux planifiés sans tenir compte des accidents qui se produiront certainement.
L'application a été développée pour une charge utilisateur élevée, ce qui signifie qu'elle devait répondre aux exigences de stabilité. Afin de ne pas perdre de données en cas de défaillance d'un nœud, nous avons décidé de diviser géographiquement notre cluster en deux centres de données. Nous avons donc décidé d'un mécanisme de déploiement qui ne violerait pas le SLA. Laissez les instances être mises à jour non pas immédiatement, mais par lots dans les centres de données.
La charge peut être transférée vers le deuxième centre de données, puis le cluster sera disponible pour l'enregistrement pendant toute la mise à jour. Il s'agit d'un déploiement d'épaule classique et de l'une des pratiques de reprise après sinistre standard .
La possibilité de mettre à jour entre les centres de données est l'un des éléments clés d'un déploiement sans temps d'arrêt. Je vous en dirai plus sur le processus à la fin de l'article, mais pour l'instant je m'attarderai sur les caractéristiques de notre déploiement inhumain et les difficultés que nous avons rencontrées.
Problèmes
Nous transférons le trafic sur la route
Il existe plusieurs centres de données et les demandes peuvent être adressées à n'importe lequel d'entre eux. Un déplacement vers un centre de données à proximité pour les données augmentera le temps de réponse de 1 à 100 ms. Pour éviter le trafic croisé, nous avons attribué à nos centres de données des balises actives et en veille . L'équilibreur (nginx) est configuré de sorte que le trafic circule toujours vers le centre de données actif. Si Tarantool plante ou devient indisponible dans le centre de données actif, il bascule automatiquement vers la réserve.
Chaque demande d'utilisateur est importante, vous avez donc besoin d'un moyen de vous assurer que les connexions sont maintenues. Pour cela, nous avons écrit un playbook ansible distinct qui permute le trafic entre les centres de données. La commutation est implémentée à l'aide d'une directive
backup
dans la description
upstream
pour le serveur. Les amont sont sélectionnés par la limite, qui deviendra active. Le reste est prescrit
backup
: nginx ne laissera le trafic sur eux que si tous les actifs ne sont pas disponibles. Lors de la modification de la configuration, les connexions ouvertes ne sont pas fermées et les nouvelles demandes iront aux routeurs qui ne sont pas soumis au redémarrage.
Que peut-on faire si l'infrastructure ne dispose pas d'un équilibreur de charge externe? Écrivez votre propre mini-équilibreur en Java qui surveillera la disponibilité des instances Tarantool. Mais ce sous-système séparé nécessitera également son propre déploiement. Une autre option consiste à créer un mécanisme de commutation à l'intérieur des routeurs. Une chose reste inchangée: le trafic HTTP doit être contrôlé.
Nous l'avons réglé avec nginx, mais les problèmes ne se sont pas arrêtés là. La commutation doit également être effectuée pour les maîtres dans les jeux de répliques. Comme je l'ai mentionné, les données doivent être conservées à proximité des routeurs pour éviter des trajets réseau inutiles. De plus, lorsque le maître actuel (c'est-à-dire une instance de stockage avec accès en écriture) tombe en panne, le mécanisme de basculement ne fonctionne pas immédiatement. Alors que le cluster prend une décision générale concernant l'indisponibilité de l'instance, toutes les demandes pour l'élément de données affecté seront erronées. Pour résoudre ce problème, nous avons également dû compiler un playbook, dans lequel nous avons utilisé des requêtes GraphQL pour l'API du cluster.
Les mécanismes de modification des assistants et de changement de trafic utilisateur sont les derniers éléments clés d'un déploiement sans temps d'arrêt. Un équilibreur de charge contrôlé évite la perte de connexions et les erreurs dans le traitement des demandes des utilisateurs et la modification des maîtres - erreurs d'accès aux données. Avec la mise à jour sur les épaules de ces trois piliers, un déploiement tolérant aux pannes est obtenu, que nous avons encore automatisé.
Combattre l'héritage
Le client disposait déjà d'un mécanisme de déploiement prêt à l'emploi: des rôles qui déployaient et configuraient les instances étape par étape. Ensuite, nous sommes venus avec la cartouche magique ansible ( github) qui résoudra tous les problèmes. Nous n'avons pas seulement pris en compte le fait que la cartouche ansible elle-même est un monolithe - un rôle important, dont les différentes étapes sont séparées par des étiquettes et des tâches séparées. Pour l'utiliser pleinement, il était nécessaire de changer le processus de livraison de l'artefact, de réviser la structure des répertoires sur les machines cibles, de changer l'orchestrateur, et bien plus encore. J'ai passé un mois à affiner le déploiement à l'aide d'ansible-cartouche. Le rôle monolithique ne cadrait tout simplement pas avec les playbooks finis. Cela n'a pas fonctionné sous cette forme, et j'ai été arrêté par une question juste d'un collègue: "En avons-nous besoin?"
Nous n'avons pas abandonné - nous avons séparé la configuration du cluster d'une seule pièce, à savoir:
- combiner les instances de stockage en jeux de réplicas;
- bootstrap vshard (mécanisme de partitionnement des données de cluster);
- mise en place du basculement (commutation automatique des maîtres en cas de chute).
Ce sont les dernières étapes du déploiement, lorsque toutes les instances sont opérationnelles. Malheureusement, toutes les autres étapes ont dû être laissées telles quelles.
Choisir un orchestrateur
Le code sur les serveurs est inutile s'il ne peut pas être exécuté. Nous avons besoin d'un utilitaire pour démarrer et arrêter les instances Tarantool. La cartouche ansible inclut des tâches pour créer des fichiers de service systemctl et travailler avec des packages rpm. Mais la spécificité de notre tâche était la présence d'un circuit fermé chez le client et l'absence de privilèges sudo. Cela signifie que nous n'avons pas pu utiliser systemctl.
Bientôt, nous avons trouvé un orchestrateur qui ne nécessite pas de privilèges root permanents - Supervisord... Je devais d'abord l'installer sur tous les serveurs, et également résoudre les problèmes locaux d'accès au fichier socket. Un nouveau rôle ansible est apparu pour fonctionner avec supervisord: il comprend des tâches de création de fichiers de configuration, de mise à jour de la configuration, de démarrage et d'arrêt des instances. C'était suffisant pour le mettre en production.
Pour des raisons d'expérimentation, nous avons ajouté la possibilité d'exécuter l'application à l'aide de supervisord dans ansible-cartouche. Cette méthode s'est avérée moins flexible et est toujours en attente de finalisation dans une branche distincte.
Réduire les temps de chargement
Quel que soit l'orchestrateur que nous utilisons, nous ne pouvons pas attendre une heure le lancement de l'instance. Le seuil est de 20 minutes. Si l'instance est indisponible plus longtemps que ce seuil, une panne automatique sera déclenchée et enregistrée dans le système comptable. Les accidents fréquents affectent les performances clés des équipes et peuvent saper les plans de développement du système. Je ne veux pas du tout perdre la prime à cause du déploiement banalement nécessaire. Par tous les moyens, vous devez conserver dans les 20 minutes.
Fait: le temps de téléchargement dépend directement de la quantité de données. Plus vous devez passer des journaux à la RAM, plus l'instance démarre longtemps après la mise à jour. Vous devez également prendre en compte le fait que les instances de stockage sur la même machine seront en concurrence pour les ressources: Tarantool utilise tous les cœurs de processeur pour créer des index.
D'après nos observations, la taille
memtx_memory
par instance ne doit pas dépasser 40 Go. Cette valeur est optimale, par exemple, la récupération prend moins de 20 minutes. Le nombre d'instances sur un serveur est calculé séparément et est étroitement lié à l'infrastructure du projet.
Nous connectons la surveillance
Tout système doit être surveillé et Tarantool ne fait pas exception. Notre surveillance n'est pas apparue immédiatement. Un bloc entier a été consacré à l'obtention de l'accès, à l'approbation et à la mise en place de l'environnement nécessaires.
Dans le processus de développement de l'application et d'écriture de playbooks, nous avons légèrement modifié le module de métriques ( github ). Vous pouvez maintenant diviser les métriques par le nom de l'instance à partir de laquelle elles ont volé - créé des étiquettes globales. À la suite de l'intégration avec les systèmes de surveillance, tout un rôle est apparu pour les applications de cluster. Le nouveau type de métrique quantile est également né de la généralisation des exigences de notre système.
Nous voyons maintenant le nombre actuel de requêtes adressées au système, la taille de la mémoire utilisée, le retard de réplication et de nombreuses autres mesures clés. De plus, ils sont configurés avec des notifications dans les chats. Les problèmes les plus critiques relèvent du système général des accidents de voiture et ont un SLA clair pour l'élimination.
Un peu sur les outils. Une description détaillée de l'endroit, de quoi et comment obtenir est recueillie dans etcd , d'où l'agent telegraf reçoit ses instructions. Les métriques au format JSON sont stockées dans InfluxDB . Nous avons utilisé Grafana comme visualiseur , pour lequel nous avons même écrit un modèle de tableau de bord . Et enfin, les alertes sont configurées via kapacitor .
Bien entendu, c'est loin d'être la seule option pour mettre en œuvre la surveillance. Vous pouvez utiliser Prometheus , et les métriques savent simplement comment donner des valeurs au format requis. Pour les alertes, zabbix peut également être utile , par exemple.
Mon collègue m'en a dit plus sur la mise en place du monitoring pour Tarantool dans l'article " Monitoring Tarantool: Logs, Metrics and their Processing ".
Configuration de la journalisation
Vous ne pouvez pas vous limiter à la surveillance. Pour obtenir une image complète de ce qui se passe avec le système, tous les diagnostics doivent être collectés, et cela inclut également les journaux. De plus, plus le niveau de journalisation est élevé, plus il y a d'informations de débogage et plus les fichiers journaux sont volumineux.
L'espace disque n'est pas infini. Notre application peut générer jusqu'à 1 To de journaux par jour en cas de charge maximale. Dans une telle situation, vous pouvez ajouter des disques, mais tôt ou tard, l'espace libre ou le budget du projet s'épuisera. Mais vous ne voulez pas non plus perdre les informations de débogage sans laisser de trace! Que faire?
L'une des étapes du déploiement, nous avons ajouté le paramètre logrotate: conservez quelques fichiers de 100 Mo bruts et compressez-en quelques autres. En fonctionnement normal, cela suffit pour trouver un problème local dans les 24 heures. Les journaux sont stockés dans un répertoire strictement défini au format JSON. Tous les serveurs exécutent le démon filebeat , qui collecte les journaux des applications et les envoie pour un stockage à long terme à ElasticSearch . Cette approche vous évite les erreurs de débordement de disque et vous permet d'analyser les performances du système en cas de problèmes à long terme. Et cette approche s'intègre bien dans le déploiement.
Nous adaptons la solution
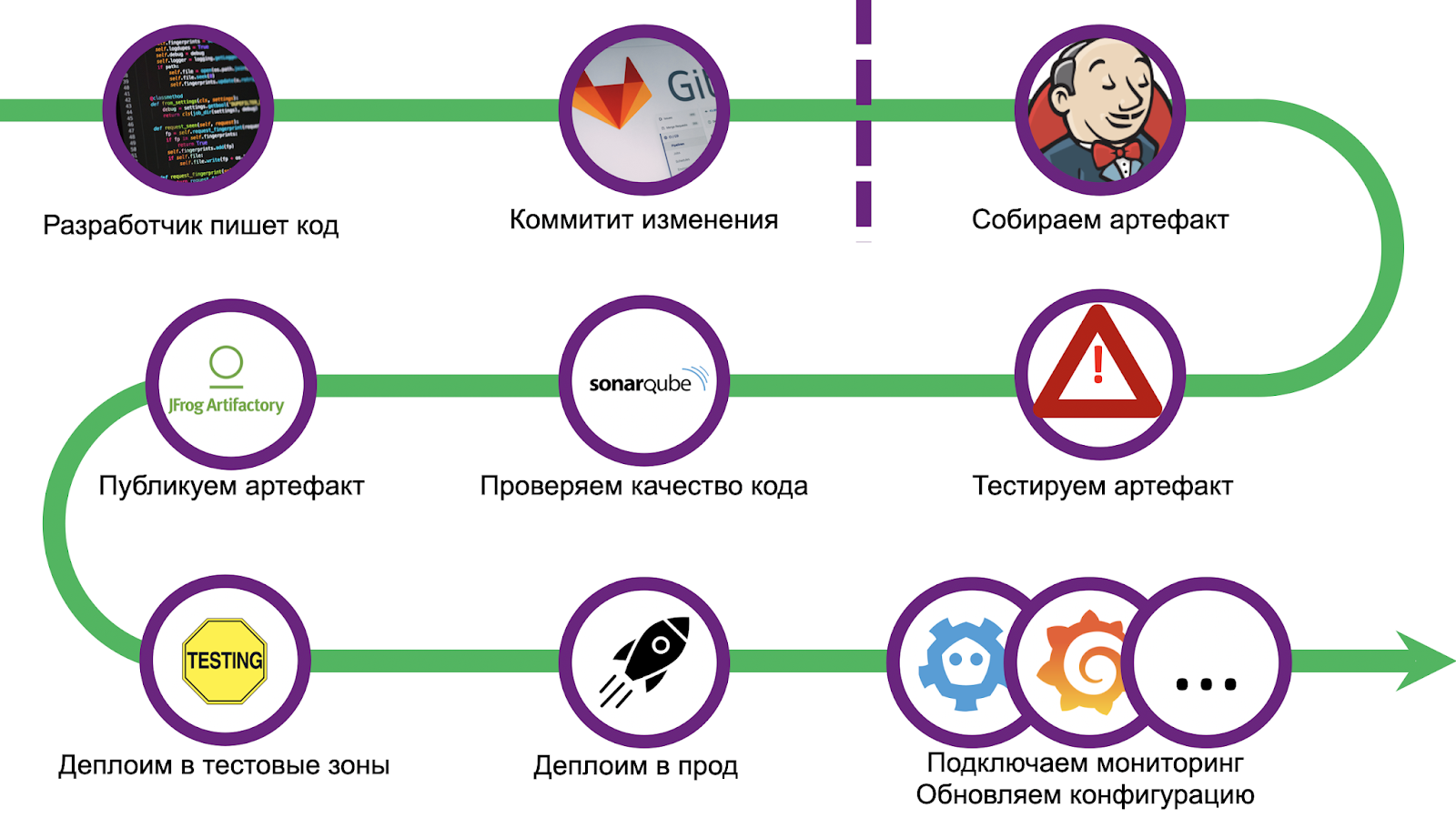
Le chemin était long et épineux, nous avons eu une bonne quantité de cônes. Afin de ne pas répéter les erreurs, nous avons standardisé le déploiement et utilisé le bundle CI / CD - Gitlab + Jenkins. La mise à l'échelle a également causé un certain nombre de problèmes, le débogage de la solution prenant plus d'un mois. Mais nous avons fait face et nous sommes maintenant prêts à partager notre expérience avec vous. Passons en revue les étapes.
Comment faire en sorte que tout développeur puisse rapidement apporter une solution à son problème et garantir sa livraison en production? Enlevez-lui Jenkinsfile! Il est nécessaire de tracer des frontières audacieuses, au-delà de ce qui signifie l'impossibilité de déploiement, et d'orienter le développeur sur cette voie.
Nous avons réalisé un exemple d'application à part entière, qui a été déployé de la même manière et qui constitue un point de départ exhaustif. Mais nous sommes allés encore plus loin avec le client: nous avons écrit un utilitaire pour créer automatiquement un modèle qui met en place un référentiel git et des tâches Jenkins. Le développeur aura besoin de moins d'une heure pour tout sur tout, et le projet sera en production.
Le pipeline commence par une vérification de code standard et une configuration d'environnement. De plus, nous mettons un inventaire pour un déploiement ultérieur dans plusieurs zones de test fonctionnel et prod. Vient ensuite la phase de test unitaire.
Le framework de test standard de Tarantool luatest ( github). Vous pouvez y écrire des tests unitaires et d'intégration, il existe des modules auxiliaires pour exécuter et configurer Tarantool Cartridge . Dans les versions récentes, vous pouvez également activer la couverture . Nous commençons avec une simple commande:
.rocks/bin/luatest --coverage
A l'issue des tests, les statistiques collectées sont envoyées à SonarQube - logiciel d'évaluation de la qualité et de la sécurité du code. À l'intérieur, nous avons déjà configuré le Quality Gate. Tout code de l'application, quel que soit le langage (Lua, Python, SQL, etc.), est validé. Cependant, il n'y a pas de gestionnaire intégré pour Lua, donc pour représenter la couverture au format générique, nous avons des plugins qui sont installés avant le début des tests.
tarantoolctl rocks install luacov 0.13.0-1 # coverage
tarantoolctl rocks install luacov-reporters 0.1.0-1 #
Une version console simple peut être vue comme ceci:
.rocks/bin/luacov -r summary . && cat ./luacov.report.out
Le rapport pour SonarQube est généré par la commande:
.rocks/bin/luacov -r sonar
Après la couverture vient l'étape du linter. Nous utilisons luacheck ( github ), qui est également l'un des plugins Tarantool.
tarantoolctl rocks install luacheck 0.26.0-1
Les résultats du linter sont également envoyés à SonarQube:
.rocks/bin/luacheck --config .luacheckrc --formatter sonar *.lua
Les statistiques de couverture du code et les linters sont comptés ensemble. Pour passer le Quality Gate, toutes les conditions doivent être remplies:
- la couverture du code par les tests doit être d'au moins 80%;
- les changements ne doivent pas introduire de nouvelles odeurs;
- le nombre total de problèmes critiques est de 0;
- le nombre total de stocks non critiques est inférieur à 5.
Après avoir passé la porte de qualité, vous devez cuire l'artefact. Puisque nous avons décidé que toutes les applications utiliseraient Tarantool Cartridge, nous utilisons cartouche-cli ( github ) pour la construction . Il s'agit d'un petit utilitaire pour exécuter (en fait, développer) des applications Tarantool en cluster localement. Elle sait également créer des images et des archives Docker avec le code d'application, à la fois localement et dans Docker (par exemple, si vous devez créer un artefact pour une architecture différente). L'assemblage
tar.gz
est effectué par la commande:
cartridge pack tgz --name <nme> --version <vrsion>
L'archive résultante est ensuite téléchargée vers n'importe quel référentiel, par exemple vers Artifactory ou Mail.ru Cloud Storage .
Déployez sans temps d'arrêt
Et la dernière étape du pipeline est le déploiement lui-même. En fonction de l'état des modifications, le laminage est effectué dans différentes zones de test. Une zone est allouée pour tout éternuement: chaque poussée vers le référentiel lance l'ensemble du pipeline. Il y a aussi plusieurs domaines fonctionnels où vous pouvez tester l' interaction avec les systèmes externes, pour cela , vous devez créer une demande de fusion dans le maître branche du référentiel. Mais en production, le laminage n'est lancé qu'après acceptation des modifications et appui sur le bouton de fusion.
Permettez-moi de vous rappeler les éléments clés de notre déploiement sans temps d'arrêt:
- mise à jour pour les centres de données;
- changer de maître dans des répliques;
- la configuration de l'équilibreur pour un centre de données actif.
Lors de la mise à niveau, vous devez surveiller la compatibilité des versions et du schéma de données. La mise à jour s'arrêtera si une erreur se produit à l'une des étapes.
La mise à jour peut être représentée schématiquement comme suit:
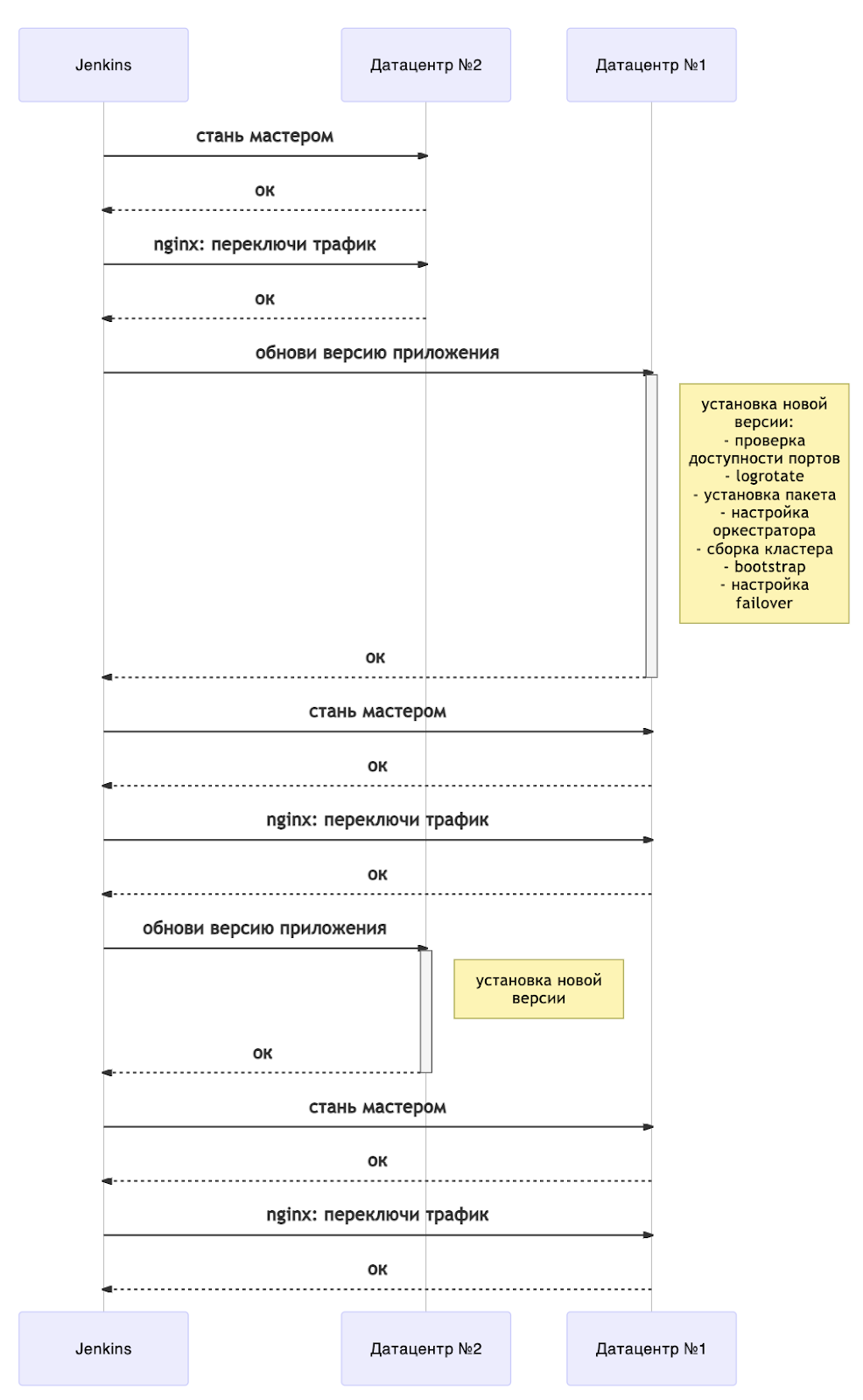
Désormais, toute mise à jour est accompagnée d'un redémarrage du serveur. Pour comprendre quand vous pouvez continuer le déploiement, nous avons un playbook séparé sur l'attente de l'état des instances. Tarantool Cartridge a une machine d'état, et nous attendons l'état RolesConfigured , ce qui signifie que l'instance est entièrement configurée (et pour nous, elle est prête à accepter les requêtes). Si l'application est déployée pour la première fois, vous devez attendre l'état Non configuré .
Dans l'ensemble, le diagramme présente une vue d'ensemble d'un déploiement sans temps d'arrêt. Il est facilement extensible à plus de centres de données. En fonction de vos besoins, vous pouvez mettre à jour tous les "bras" de sauvegarde immédiatement après avoir changé les maîtres (c'est-à-dire avec le centre de données n ° 1) ou un par un.
Bien sûr, nous n'avons pas pu nous empêcher d'apporter nos développements à l'open source. Jusqu'à présent, ils sont disponibles dans ma fourchette ansible-cartouche ( opomuc / ansible-cartouche ), mais il est prévu de la déplacer vers la branche principale du référentiel principal.
Un exemple peut être trouvé ici ( exemple ). Pour que cela fonctionne correctement, le serveur doit être configuré
supervisord
pour l'utilisateur
tarantool
. Les commandes de configuration peuvent être trouvées ici . L'archive avec l'application doit également contenir un binaire
tarantool
.
La séquence de commandes pour démarrer le déploiement de l'épaule:
# ( )
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.0.0-0.tar.gz' \
--extra-vars 'app_version=1.0.0' \
--tags supervisor
# 1.2.0
# dc2
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc2
# — dc1
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc1
# dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
# — dc2
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc2
# , dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
Le paramètre
base_dir
indique le chemin vers le répertoire "home" du projet. Après le déploiement, des sous-répertoires seront créés:
<base_dir>/run
- pour les sockets de contrôle et les fichiers pid;<base_dir>/data
- pour les fichiers .snap et .xlog, ainsi que la configuration de la cartouche Tarantool;<base_dir>/conf
- pour les paramètres d'application et les instances spécifiques;<base_dir>/releases
- pour la gestion des versions et le code source;<base_dir>/instances
- pour les liens vers la version actuelle de chaque instance de l'application.
Le paramètre
cartridge_package_path
parle de lui-même, mais il y a une particularité:
- si le chemin commence par
http://
ouhttps://
, alors l'artefact sera préchargé à partir du réseau (par exemple, à partir de l'artefact généré à côté). - dans d'autres cas, le fichier est recherché localement
Le paramètre
app_version
sera utilisé pour la gestion des versions dans le dossier
<base_dir>/releases
. La valeur par défaut est
latest
.
La balise
supervisor
signifie qu'elle sera utilisée comme orchestrateur
supervisord
.
Il existe de nombreuses options pour démarrer un déploiement, mais la plus fiable est la bonne ancienne
Makefile
. La commande conditionnelle
make deploy
peut être incluse dans n'importe quel CI \ CD et tout fonctionnera exactement de la même manière.
Résultat
C'est tout! Nous avons maintenant un pipeline prêt à l'emploi sur Jenkins, nous nous sommes débarrassés des intermédiaires et la rapidité de livraison des changements est devenue folle. Le nombre d'utilisateurs augmente, dans l'environnement de production, il y a déjà 500 instances déployées exclusivement à l'aide de notre solution. Nous avons de la place pour grandir.
Et bien que le processus de déploiement lui-même soit loin d'être idéal, il fournit une base solide pour le développement ultérieur des processus DevOps. Vous pouvez prendre notre implémentation en toute sécurité afin de livrer rapidement le système à la production et ne pas avoir peur de faire des modifications fréquentes.
Et ce sera aussi une leçon pour nous qu'il est impossible d'amener un monolithe et d'espérer son utilisation généralisée: nous avons besoin d'une décomposition des playbooks, de l'attribution des rôles à chaque étape de l'installation, d'une manière flexible de présenter l'inventaire. Un jour, nos développements seront inclus dans master, et tout sera encore mieux!
Liens
- Un guide étape par étape pour ansible-cartouche:
- Vous pouvez en savoir plus sur Tarantool Cartridge ici .
- À propos du déploiement sur Kubernetes:
- Surveillance Tarantool: logs, métriques et leur traitement .
- Pour obtenir de l'aide, contactez le chat Telegram .