Nos lecteurs n'ont pas pu s'empêcher de remarquer notre intérêt croissant pour la langue Go. En plus du livre du post précédent , nous avons beaucoup de choses intéressantes sur ce sujet . Aujourd'hui, nous voulons vous proposer une traduction du matériel "pour les pros", qui démontre des aspects intéressants de la gestion manuelle de la mémoire dans Go, ainsi que l'exécution simultanée des opérations mémoire en Go et C ++.
En langage Dgraph Labs Go utilisé depuis sa création en 2015. Après cinq ans ou 200 000 lignes de code sur le Go, prêt à annoncer avec bonheur qu'il n'a pas tort de Go. Ce langage n'est pas seulement un outil pour créer de nouveaux systèmes, mais encourage même l'écriture de scripts en Go qui étaient traditionnellement écrits en Bash ou Python. Il s'avère que Go vous permet de créer une base de code propre, lisible et maintenable qui - surtout - est efficace et facile à gérer simultanément.
Cependant, il y a un problème avec Go, qui se manifeste déjà dans les premières étapes du travail: la gestion de la mémoire... Nous n'avons pas eu de plaintes à propos du ramasse-miettes Go, mais, en plus, à quel point il simplifie la vie des développeurs, il a les mêmes problèmes que les autres ramasse-miettes: il ne peut tout simplement pas rivaliser d'efficacité avec la gestion manuelle de la mémoire .
La gestion manuelle de la mémoire entraîne une utilisation moindre de la mémoire, une utilisation prévisible de la mémoire et évite les pics d'utilisation de la mémoire lorsqu'un grand nouveau bloc de mémoire est alloué fortement. Tous les problèmes ci-dessus avec la gestion automatique de la mémoire ont été remarqués lors de l'utilisation de la mémoire dans Go.
Des langages comme Rust peuvent prendre pied en partie parce qu'ils fournissent une gestion manuelle sûre de la mémoire. C'est bienvenu.
D'après mon expérience, l'allocation manuelle de mémoire et le suivi des fuites de mémoire potentielles sont plus faciles que d'essayer d'optimiser l'utilisation de la mémoire avec des outils de récupération de place. Le garbage collection manuel vaut bien la peine de créer des bases de données offrant une évolutivité pratiquement illimitée.
Pour l'amour de Go et la nécessité d'éviter le garbage collection en utilisant le Go GC, nous avons dû trouver des moyens innovants de gérer manuellement la mémoire dans Go. Bien sûr, la plupart des utilisateurs de Go n'auront jamais besoin de gérer manuellement la mémoire, et nous vous recommandons d'éviter de le faire à moins que vous n'en ayez vraiment besoin. Et quand vous en avez besoin , vous devez savoir comment le faire .
Construire la mémoire avec Cgo
Cette section est calquée sur l'article du wiki Cgo sur la conversion de tableaux C en segments Go. Nous pourrions utiliser malloc pour allouer de la mémoire en C et utiliser unsafe pour la transmettre à Go, sans nécessiter aucune intervention du garbage collector Go.
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]
Cependant, ce qui précède est possible avec la mise en garde indiquée sur golang.org/cmd/cgo.
: . Go nil C ( Go) C, , C Go. , C Go, Go . C, Go.
Par conséquent, au lieu de malloc, nous utiliserons son homologue
calloc
légèrement plus lourd.
calloc
fonctionne exactement comme ceci
malloc
, avec la mise en garde qu'il réinitialise la mémoire à zéro avant de la renvoyer à l'appelant.
Pour commencer, nous venons d'implémenter dans leur forme la plus simple les fonctions Calloc et Free qui allouent et libèrent des segments d'octets pour Go via Cgo. Pour tester ces fonctionnalités, un test continu d'utilisation de la mémoire a été développé et testé. ... Ce test, sous la forme d'une boucle sans fin, a répété un cycle d'allocation / libération de mémoire, dans lequel les premiers fragments de mémoire de taille aléatoire ont été alloués jusqu'à ce que la mémoire totale allouée atteigne 16 Go, puis ces fragments ont été progressivement libérés jusqu'à ce que seulement 1 Go de mémoire soit alloué. .
Le programme équivalent C a fonctionné comme prévu. Nous avons
htop
vu comment la quantité de mémoire allouée au processus (RSS) atteint d'abord 16 Go, puis passe à 1 Go, puis augmente à nouveau jusqu'à 16 Go, et ainsi de suite. Cependant, un programme Go utilisant
Calloc
et
Free
utilisait de plus en plus de mémoire après chaque boucle (voir schéma ci-dessous).
Il a été suggéré que cela est dû à la fragmentation de la mémoire due au manque de "conscience de thread" dans les appels
C.calloc
par défaut. Pour éviter cela, il a été décidé d'essayer
jemalloc
.
jemalloc
jemalloc
Est une implémentation génériquemalloc
qui se concentre sur la prévention de la fragmentation et le maintien de la concurrence évolutive.jemalloc
a été utilisé pour la première fois dans FreeBSD en 2005 en tant qu'allocateurlibc
et a depuis trouvé une utilisation dans de nombreuses applications en raison de son comportement prévisible. - jemalloc.net
Nous avons changé nos API pour les utiliser
jemalloc
avec les appels
calloc
et
free
. De plus, cette option a parfaitement fonctionné: elle
jemalloc
prend en charge nativement les flux sans presque aucune fragmentation de la mémoire. Le test de mémoire, qui a testé les cycles d'allocation de mémoire et de désallocation, est resté dans les limites du raisonnable, mis à part la petite surcharge qu'implique l'exécution du test.
Juste pour souligner que nous utilisons jemalloc et éviter les conflits de noms, nous ajoutons un préfixe lors de l'installation
je_
afin que nos API appellent maintenant
je_calloc
et
je_free
, pas
calloc
et
free
.
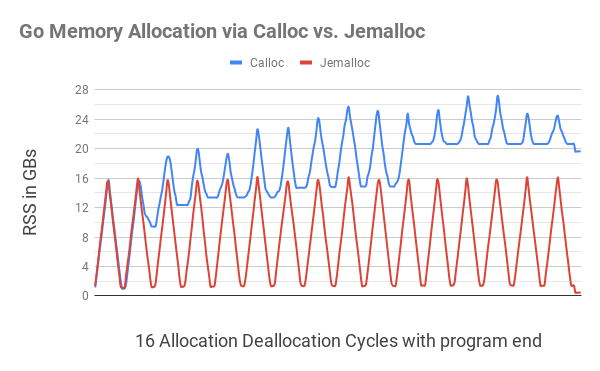
Cette illustration montre que l'allocation de mémoire Go avec
C.calloc
conduit à une grave fragmentation de la mémoire, ce qui oblige le programme à consommer jusqu'à 20 Go de mémoire au 11e cycle. Le code équivalent
jemalloc
n'a donné aucune fragmentation notable, s'adaptant à chaque cycle à près de 1 Go.
Plus près de la fin du programme (une petite ondulation sur le bord droit), une fois que toute la mémoire allouée a été libérée, le programme a
C.calloc
encore consommé un peu moins de 20 Go de mémoire, alors qu'il
jemalloc
ne coûtait que 400 Mo de mémoire.
Pour installer jemalloc, téléchargez-le à partir d'ici, puis exécutez les commandes suivantes:
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto' make sudo make install
L'ensemble du code
Calloc
ressemble à ceci:
ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw panic, ,
// . , – , Go,
// .
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// C Go, .
return (*[MaxArrayLen]byte)(uptr)[:n:n]
Ce code est inclus dans le package Ristretto . Une balise d'assembly a été ajoutée pour permettre au code résultant de passer à jemalloc pour l'allocation de blocs d'octets
jemalloc
. Pour simplifier davantage les opérations de déploiement, la bibliothèque a été liée statiquement
jemalloc
à tout binaire Go résultant en définissant les indicateurs LDFLAGS appropriés.
Décomposition des structures Go en segments d'octets
Nous avons maintenant un moyen d'allouer et de libérer un segment d'octet, puis nous l'utiliserons pour mettre en page nos structures dans Go. Vous pouvez commencer par l'exemple le plus simple (code complet).
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}
Dans l'exemple ci-dessus, nous avons présenté la structure Go sur la mémoire allouée en C en utilisant
newNode
. Nous avons créé une fonction appropriée
freeNode
qui nous permet de libérer de la mémoire dès que nous en avons terminé avec la structure. La structure en langage Go contient le type de données le plus simple
int
et un pointeur vers la structure du nœud suivant, tout cela peut être défini dans le programme, puis ces entités sont accessibles. Nous avons sélectionné des objets de nœud 2M et créé une liste chaînée à partir d'eux pour démontrer que jemalloc fonctionne comme prévu.
Avec l'allocation de mémoire par défaut de Go, vous pouvez voir que 31 Mio du tas sont alloués à une liste liée avec 2 Mo d'objets, mais rien n'est alloué via
jemalloc
.
$ go run . Allocated memory: 0 Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 31 MiB
En utilisant la balise d'assembly
jemalloc
, nous voyons que 30 Mio octets de mémoire sont alloués dans through
jemalloc
, et après la publication de la liste liée, cette valeur tombe à zéro. Go n'alloue que 399 Kio de mémoire, ce qui est probablement dû à la surcharge liée à l'exécution du programme.
$ go run -tags=jemalloc . Allocated memory: 30 MiB Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 399 KiB
Amortissement des coûts Calloc avec Allocator
Le code ci-dessus fait un excellent travail d'allocation de mémoire dans Go. Mais cela se fait au détriment de la dégradation des performances . Après avoir conduit les deux copies avec
time
, nous voyons que sans le
jemalloc
programme fait face en 1,15 secondes. Depuis
jemalloc
qu'elle a fait 5 fois plus lentement, avec plus de 5,29.
$ time go run . go run . 1.15s user 0.25s system 162% cpu 0.861 total $ time go run -tags=jemalloc . go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 total
Ce ralentissement peut être attribué au fait que des appels Cgo ont été effectués pour chaque allocation de mémoire, et chaque appel Cgo entraîne une surcharge. Pour gérer ces problèmes, la bibliothèque Allocator a été écrite , également incluse dans le paquetage ristretto / z . Cette bibliothèque alloue des segments de mémoire plus grands en un seul appel, chacun pouvant accueillir de nombreux petits objets, ce qui élimine le besoin d'appels Cgo coûteux .
L'allocateur démarre avec un tampon et, dès qu'il est épuisé, crée un nouveau tampon deux fois plus grand que le premier. Il maintient une liste interne de tous les tampons alloués. Enfin, lorsque l'utilisateur a terminé avec les données, nous pouvons appeler Release pour libérer tous ces tampons d'un seul coup. Remarque: Allocator ne déplace pas du tout la mémoire. Cela garantit que tous les pointeurs que nous avons vers la structure continuent de fonctionner.
Bien qu'une telle gestion de la mémoire peut apparaître maladroit et par rapport à la façon de fonctionner
tcmalloc
et
jemalloc
, cette approche est beaucoup plus simple. Une fois que vous avez alloué de la mémoire, vous ne pouvez plus libérer une seule structure. Vous ne pouvez libérer que toute la mémoire utilisée par l'allocateur à la fois.
Ce à quoi Allocator est vraiment doué, c'est d'allouer des millions de structures à bas prix et de les libérer ensuite lorsque le travail est fait sans avoir à impliquer un tas de Go pour faire le travail . L'exécution du programme ci-dessus avec la nouvelle balise de construction d'allocateur s'exécutera encore plus rapidement que la version de mémoire Go.
$ time go run -tags="jemalloc,allocator" . go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 total
Dans Go 1.14 et versions ultérieures, l'indicateur
-race
active les contrôles d'alignement des structures en mémoire. Allocator a une méthode
AllocateAligned
qui renvoie de la mémoire et le pointeur doit être correctement aligné pour réussir ces vérifications. Si la structure est volumineuse, une partie de la mémoire peut être perdue, mais les instructions du processeur commencent à fonctionner plus efficacement en raison de la délimitation correcte des mots.
Un autre problème est survenu avec la gestion de la mémoire. Il se trouve que la mémoire est allouée à un endroit et libérée dans un endroit complètement différent. Toute communication entre ces deux points peut être effectuée à travers des structures, et ils ne peuvent être distingués qu'en transférant un objet spécifique
Allocator
. Pour faire face à cela, nous attribuons un identifiant unique à chaque objet.
Allocator
que ces objets stockent dans la référence
uint64
. Chaque nouvel objet
Allocator
est stocké dans le dictionnaire global en référence à une référence à lui-même. Les objets d'allocateur peuvent ensuite être rappelés à l'aide de cette référence et libérés lorsque les données ne sont plus nécessaires.
Organisez les liens avec compétence
NE référencez PAS la mémoire allouée par Go à partir de la mémoire allouée manuellement.
Lors de l'allocation manuelle d'une structure comme indiqué ci-dessus, il est important de s'assurer qu'il n'y a aucune référence à la mémoire allouée par Go dans cette structure. Modifions un peu la structure ci-dessus:
type node struct {
val int
next *node
buf []byte
}
Utilisons la fonction
root := newNode(val)
définie ci-dessus pour sélectionner manuellement un nœud. Si nous installons ensuite
root.next = &node{val: val}
, allouant ainsi tous les autres nœuds de la liste liée via la mémoire Go, nous obtenons inévitablement l'erreur de partitionnement suivante:
$ go run -race -tags="jemalloc" . Allocated memory: 16 B Objects: 2000001 unexpected fault address 0x1cccb0 fatal error: fault [signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]
La mémoire allouée par Go est soumise au garbage collection car aucune structure Go valide ne pointe vers elle. Les références proviennent uniquement de la mémoire allouée en C et le tas Go ne contient aucune référence appropriée, ce qui provoque l'erreur ci-dessus. Ainsi, si vous créez une structure et que vous lui allouez manuellement de la mémoire, il est important de vous assurer que tous les champs accessibles de manière récursive sont également alloués manuellement.
Par exemple, si la structure ci-dessus utilisait un segment d'octets, nous allouions ce segment à l'aide d'un Allocator et évitions également de mélanger la mémoire Go avec la mémoire C.
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // 16
rand.Read(n.buf)
Comment gérer des gigaoctets de mémoire dédiée
Allocator
bon pour sélectionner manuellement des millions de structures. Mais il y a aussi des cas où vous devez créer des milliards de petits objets et les trier. Pour ce faire dans Go, même avec de l'aide
Allocator
, vous devez écrire un code comme celui-ci:
var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// .
Tous ces nœuds 1B sont alloués manuellement
Allocator
, ce qui coûte cher. Vous devez également dépenser de l'argent sur chaque segment de mémoire dans Go, ce qui est assez cher en soi, car nous avons besoin de 8 Go de mémoire (8 octets par pointeur de nœud).
Pour faire face à ces situations pratiques, un
z.Buffer
fichier mappé en mémoire a été créé, permettant ainsi à Linux d'échanger et de vider les pages mémoire selon les besoins du système. Il met en œuvre
io.Writer
et nous permet de ne pas dépendre
bytes.Buffer
.
Plus important encore, il
z.Buffer
offre une nouvelle façon de mettre en évidence des segments de données plus petits. Lorsque vous appelez
SliceAllocate(n)
,
z.Buffer
enregistrera la longueur du segment à sélectionner
(n)
, puis sélectionnera ce segment. Cela
z.Buffer
facilite la compréhension des limites des segments et l'itération correcte des segments avec
SliceIterate
.
Tri des données de longueur variable
Pour le tri, nous avons d'abord essayé d'obtenir des décalages de segment
z.Buffer
, de se référer aux segments pour comparaison, mais de ne trier que les décalages. Ayant reçu l'offset, il
z.Buffer
peut le lire, trouver la longueur du segment et renvoyer ce segment. Ainsi, un tel système permet de restituer les segments sous une forme triée sans recourir à un brassage mémoire. Aussi innovant soit-il, ce mécanisme met une pression importante sur la mémoire, car nous devons encore payer une pénalité de 8 Go de mémoire juste pour pousser les décalages intéressants vers la mémoire Go.
Le facteur le plus important limitant notre travail était que les tailles n'étaient pas les mêmes pour tous les segments. De plus, nous ne pouvions accéder à ces segments que dans un ordre séquentiel, et non en sens inverse ou aléatoire, ne pouvant pas calculer et stocker les décalages à l'avance. La plupart des algorithmes de tri sur place supposent que toutes les valeurs sont de la même taille, peuvent être consultées dans n'importe quel ordre, et rien n'empêche leur échange.
sort.Slice
in Go fonctionne de manière similaire, et était donc mal adapté pour
z.Buffer
.
Compte tenu de ces limitations, il a été conclu que l'algorithme de tri par fusion est le mieux adapté à la tâche à accomplir. Avec le tri par fusion, vous pouvez travailler dans une mémoire tampon, en effectuant des opérations dans un ordre séquentiel, la surcharge de mémoire supplémentaire ne représentant que la moitié de la taille de la mémoire tampon. Cela s'est avéré non seulement moins coûteux que de déplacer l'indentation en mémoire, mais cela améliore également considérablement la prévisibilité en termes de surcharge mémoire (la moitié de la taille du tampon). Mieux encore, la surcharge requise pour effectuer le tri par fusion est elle-même mappée en mémoire.
Il y a un autre effet très positif de l'utilisation du tri par fusion. Le tri des décalages doit garder les décalages en mémoire pendant que nous les parcourons et traitons le tampon, ce qui ne fait qu'augmenter la pression sur la mémoire. Avec le tri par fusion, toute la mémoire supplémentaire dont nous avions besoin est libérée au moment où l'énumération démarre, ce qui signifie que nous aurons plus de mémoire pour traiter le tampon.
z.Buffer prend également en charge l'allocation de mémoire via
Calloc
, ainsi que le mappage automatique de la mémoire après avoir dépassé une certaine limite spécifiée par l'utilisateur. Par conséquent, l'outil fonctionne bien avec des données de toute taille.
buffer := z.NewBuffer(256<<20) // 256MB Calloc.
buffer.AutoMmapAfter(1<<30) // mmap 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// .
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})
Attraper les fuites de mémoire
Toute cette discussion serait incomplète sans aborder le sujet des fuites de mémoire. Après tout, si nous allouons de la mémoire manuellement, les fuites de mémoire seront inévitables dans tous ces cas lorsque nous oublions de libérer de la mémoire. Comment pouvez-vous les attraper?
Nous avons longtemps utilisé une solution simple - nous avons utilisé un compteur atomique qui garde la trace du nombre d'octets alloués lors de tels appels. Dans ce cas, vous pouvez connaître rapidement la quantité de mémoire que nous avons allouée manuellement dans le programme en utilisant
z.NumAllocBytes()
. Si à la fin du test de mémoire nous avions encore de la mémoire supplémentaire, cela signifiait une fuite.
Lorsque nous avons réussi à trouver une fuite, nous avons d'abord essayé d'utiliser le profileur de mémoire jemalloc. Mais il est vite devenu clair que cela n'a pas aidé - il n'a pas vu toute la pile d'appels, car il se heurtait à la frontière Cgo. Tout ce que le profileur voit est l'allocation de mémoire et les actes de libération des mêmes appels
z.Calloc
et
z.Free
.
Grâce au runtime Go, nous avons rapidement pu créer un système simple pour intercepter les appelants
z.Calloc
et les mapper aux appels
z.Free
. Ce système nécessite des verrous mutex, nous avons donc décidé de ne pas l'activer par défaut. Au lieu de cela, nous avons utilisé l'indicateur de construction
leak
pour activer les messages de débogage pour les fuites dans les assemblys de développeur. Ainsi, les fuites sont automatiquement détectées et affichées sur la console exactement d'où elles proviennent.
// .
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// , , .
// ,
// , .
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91
Production
Avec l'aide des techniques décrites, un moyen d'or est atteint. Nous pouvons allouer manuellement de la mémoire dans des chemins de code critiques qui dépendent fortement de la mémoire disponible. Dans le même temps, nous pouvons tirer parti du ramasse-miettes automatique de manière moins critique. Même si vous n'êtes pas très doué pour gérer Cgo ou jemalloc, vous pouvez utiliser ces techniques avec des morceaux de mémoire relativement importants dans Go - l'effet sera comparable.
Toutes les bibliothèques mentionnées ci-dessus sont disponibles sous la licence Apache 2.0 dans le package Ristretto / z . Le test de mémoire et le code de démonstration se trouvent dans le dossier contrib .