
Lorsque nous parlons de CI&CD, nous approfondissons souvent les outils de base pour automatiser la construction, les tests et la livraison des applications - en nous concentrant sur les outils, mais en oubliant de couvrir les processus qui se produisent pendant la coupe et la stabilisation des versions. Cependant, tous les outils prêts à l'emploi ne sont pas également utiles et certains processus personnalisés ne rentrent pas dans leur champ d'application. Vous devez rechercher les processus et trouver des moyens de les automatiser pour les optimiser.
Dans notre entreprise, les ingénieurs QA utilisent Zephyr pour suivre la progression de la régression, car nous ne pouvons pas remplacer les tests manuels et exploratoires par des tests automatiques. Mais malgré cela, les autotests sont souvent poursuivis ici et en grande quantité, je veux donc pouvoir omettre certaines vérifications banales qui ont été automatisées et permettre aux testeurs de faire un travail plus productif et utile.
Nous avons des courses de nuit où des suites de tests complètes sont recherchées. Mais à l'aube même de la maîtrise de Zephyr, lors de la régression, nos testeurs ont dû télécharger xcresult, ou même plus tôt plist, ou junit xml, puis déposer les correspondances des tests verts et rouges dans les guimauves avec leurs mains. Il s'agit d'une opération plutôt courante et il faut beaucoup de temps pour passer 500 à 600 tests à la main. Vous voulez laisser de telles choses à la merci d'une machine sans âme. C'est ainsi que ZERG est né.
Zerg est né
Zephyr Enterprise Report Generator est un petit utilitaire qui, au départ, savait seulement comment rechercher des correspondances dans le rapport de test et envoyer leurs statuts actuels à Zephyr. Plus tard, l'utilitaire a reçu de nouvelles fonctions, mais aujourd'hui, nous nous concentrerons sur la recherche et l'envoi de rapports.
Dans Zephyr, il nous est demandé d'opérer avec des versions, des boucles et des exécutions de cas de test. Chaque version contient un nombre arbitraire de cycles et chaque cycle contient des passages de cas. Ces passes contiennent des informations sur la tâche (zephyr s'intègre parfaitement à jira et le cas de test est, en fait, une tâche dans jira), l'auteur, le statut du cas, ainsi que qui est engagé dans ce cas et d'autres détails nécessaires .
Pour automatiser le problème que nous avons décrit ci-dessus, il est important pour nous de comprendre comment définir le statut du cas.
Travailler avec du code
Mais comment corréler le test de code et le test de guimauve? Ici, nous avons adopté une approche assez simple et directe: pour chaque test, nous ajoutons des liens vers des tâches dans jira dans la section commentaires.
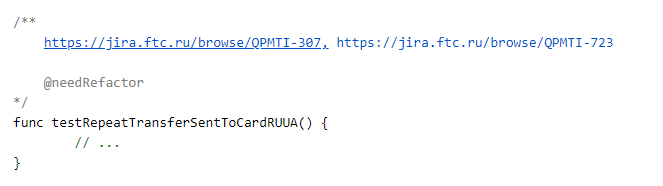
Des paramètres supplémentaires peuvent également être placés dans les commentaires, mais nous en parlerons plus tard.
Ainsi, un test dans le code peut couvrir plusieurs tâches. Mais la logique inverse fonctionne également. Plusieurs tests peuvent être écrits en code pour une tâche. Leurs statuts seront pris en compte lors de la rédaction du rapport.
Nous devons parcourir le code source, extraire toutes les classes de test et les tests, lier les tâches aux méthodes et corréler cela avec le rapport de réussite des tests (xcresult ou junit).
Vous pouvez travailler avec le code lui-même de différentes manières:
- il suffit de lire des fichiers et de récupérer des informations via des expressions régulières
- d'utiliser SourceKit
Quoi qu'il en soit, même en utilisant SourceKit, nous ne pouvons pas nous passer d'expressions régulières pour extraire les ID de tâches des liens dans les commentaires.
À ce stade, nous ne sommes pas intéressés par les détails, nous allons donc nous en isoler avec un protocole:

nous devons faire des tests. Pour ce faire, nous décrivons les structures:
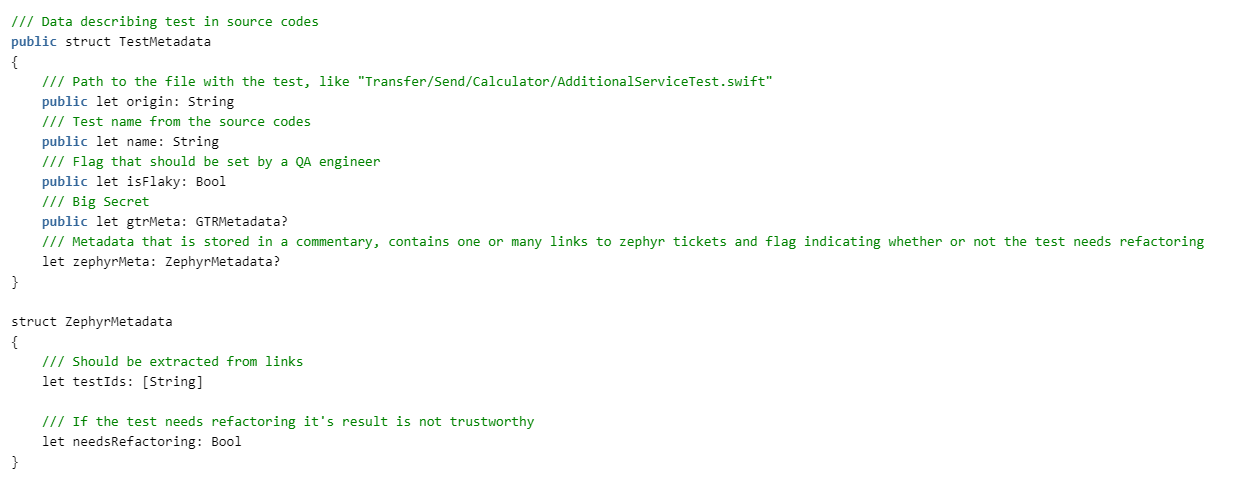
Ensuite, nous devons lire le rapport sur la réussite des tests. ZERG est né avant de passer à xcresult, et peut donc analyser plist et junit. Nous ne sommes toujours pas intéressés par les détails de cet article, ils seront joints dans le code. Par conséquent, nous clôturerons les protocoles

Il ne reste plus qu'à lier les tests dans le code avec les résultats des tests des rapports.
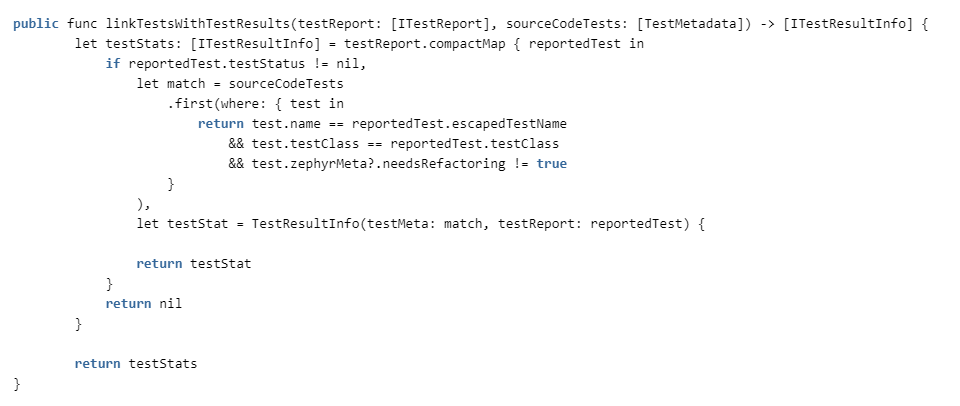
Nous vérifions la correspondance par nom de classe et nom de test (différentes classes peuvent avoir des méthodes avec le même nom) et si un refactoring est nécessaire pour le test. Si vous en avez besoin, nous considérons qu'il n'est pas fiable et nous le rejetons des statistiques.
Nous travaillons avec des guimauves
Maintenant que nous avons lu les rapports de test, nous devons les traduire dans le contexte zephyr. Pour ce faire, vous devez obtenir une liste des versions du projet, corréler avec la version de l'application (pour que cela fonctionne comme ça, il est nécessaire que la version dans la guimauve coïncide avec la version dans l'Info.plist de votre application , par exemple, 2.56), téléchargez des boucles et des passes. Et puis corréler les passes avec nos rapports existants.
Pour ce faire, nous devons implémenter les méthodes suivantes dans ZephyrAPI: La
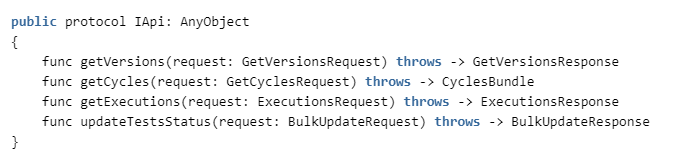
spécification peut être vue ici: getzephyr.docs.apiary.io , et l'implémentation du client est dans notre référentiel.
L'algorithme général est assez simple:
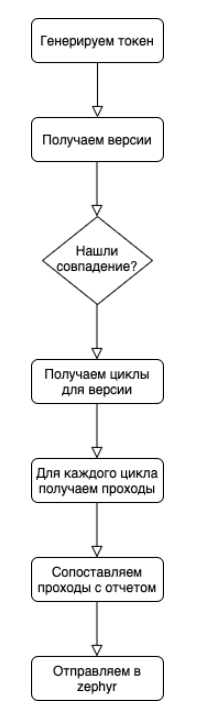
Au stade de la mise en correspondance des passes avec les rapports, il y a un point subtil qui doit être pris en compte: dans l'api zephyr, il est plus pratique d'envoyer la mise à jour de l'exécution par lots, où l'état général et une liste des ID de passe sont transmis . Nous devons élargir nos rapports de tickets et prendre en compte le ratio nm. Pour un cas de guimauve, il peut y avoir plusieurs tests dans le code. Un test dans le code peut couvrir plusieurs cas. Si pour un cas il y a n tests dans le code et que l'un d'eux est rouge, alors pour un tel cas, l'état général est rouge, mais si l'un de ces tests couvre m cas et qu'il est vert, alors le reste des cas devrait pas devenir rouge.
Par conséquent, nous opérons avec des ensembles et recherchons l'intersection du rouge et du vert. Tout ce qui tombe dans l'intersection, nous soustrayons les résultats verts et envoyons les informations modifiées à zéphyr.

Il convient également de noter ici qu'au sein de l'équipe, nous avons convenu que zerg ne changera pas le statut de la passe si:
1. Le statut actuel est bloqué ou échoué (nous avions l'habitude de changer le statut d'échec, mais maintenant nous avons abandonné pratique, car nous voulons que les testeurs fassent attention aux autotests rouges lors de la régression).
2. Si l'état actuel est pass et qu'il a été défini par une personne, pas par zerg.
3. Si le test est marqué comme clignotant.
Intérêts de l'API Zephyr
Lors de la demande de boucles, nous recevons json, qui à première vue ne peut pas être systématisé pour la désérialisation. Le fait est qu'une demande pour obtenir des boucles pour une version, bien qu'elle doive renvoyer un tableau de boucles, renvoie en fait un objet, où chaque champ est unique et est appelé l'identificateur de boucle, qui réside dans la valeur. Pour gérer cela, nous utilisons de simples hacks:

les statuts de réussite des tests sont fournis dans l'une des requêtes à côté de l'objet de requête. Mais ils peuvent être déplacés à l'avance vers enum:

lors de la demande de boucles, vous devez transmettre la version et l'identifiant entier du projet aux paramètres de la requête. Mais dans la demande de passes pour la boucle, le même identifiant de projet doit être passé au format chaîne.

Au lieu d'une conclusion
S'il y a beaucoup de travail de routine, il est fort probable que quelque chose puisse être automatisé. La synchronisation du passage des autotests avec le système de gestion des tests est l'un de ces cas.
Ainsi, chaque nuit, nous avons un test complet, et pendant la régression, le rapport est envoyé aux ingénieurs QA. Cela réduit le temps de régression et laisse du temps pour les tests exploratoires.
Si vous implémentez correctement l'analyseur de source Android, il peut être appliqué avec le même succès pour la deuxième plate-forme.
Notre Zerg, en plus de comparer les tests, est également capable d'analyser l'impact initial, mais plus à ce sujet, peut-être la prochaine fois.