
La manipulation des doublons est l'un des sujets les plus douloureux du travail d'un analyste. Dans notre plateforme, nous essayons d'automatiser ce processus autant que possible afin de réduire la charge sur les experts NSI et d'augmenter la productivité des collègues avec le traitement des données. Aujourd'hui, nous allons voir comment la plate-forme contribue à former un seul record d'or en utilisant l'exemple de l'un des livres de référence les plus courants et les plus élémentaires - l'annuaire des «contreparties».
Considérons l'un des scénarios typiques. Supposons qu'un grand distributeur B2B reçoive des marchandises de différents fournisseurs et les vende à des clients - entité juridique. des personnes. Si dans la pratique tout est plus ou moins bon avec la maintenance par le fournisseur, alors le traitement de la clientèle nécessite parfois toute une équipe d'experts dédiée. Cela est dû au fait que les entreprises utilisent généralement plusieurs systèmes-sources de données clients: ERP, CRM, open sources, etc. Le travail est particulièrement difficile lorsqu'il y a plusieurs départements dans l'entreprise, chacun entretenant sa propre clientèle au sein de l'entreprise. le même territoire ... Dans ce cas, une partie des données client est dupliquée dans la redistribution d'une base, et se recoupe également implicitement entre différentes bases clients. Dans un système ERP, un traitement sérieux des enregistrements en double est nécessaire pour obtenir un enregistrement dit maître,avec lequel vous pouvez travailler à l'avenir. La plate-forme Unidata dispose d'un mécanisme spécial pour rechercher et traiter les enregistrements en double, qui gère avec succès ces tâches.
Commençons
La plateforme est basée sur le métamodèle du domaine utilisé. Le domaine est un ensemble structuré de registres, d'annuaires. leurs attributs et les relations entre eux, qui décrivent ensemble la structure des données du domaine. Nous parlerons du métamodèle lui-même plus tard, mais nous verrons maintenant comment la plate-forme vous permet de travailler avec des enregistrements en double dans un modèle de données existant. Dans notre exemple, il existe un registre des «contreparties», dont les principaux attributs sont: le nom de la contrepartie (généralement court et complet), TIN, KPP, adresses légale et réelle, adresse d'enregistrement de la personne morale, etc.
La plate-forme utilise un mécanisme de consolidation pour gérer les doublons. L'essence de la consolidation est que nous mettons en place certaines règles pour trouver les doublons, définissons les sources de données et pour chaque source de données, nous définissons des pondérations spéciales qui sont responsables du niveau de confiance des informations reçues du système source, puis des doublons trouvés par le système sont fusionnés en un seul enregistrement de référence. Dans ce cas, les enregistrements en double disparaissent des résultats de la recherche, mais restent dans l'historique de l'enregistrement de référence. Tous les paramètres sont définis dans l'interface administrateur de la plate-forme et ne nécessitent aucune programmation. Si la fusion d'enregistrements est effectuée par erreur, il est toujours possible d'annuler la fusion. Ainsi, la plupart du travail avec les doublons est pris en charge par le système lui-même, l'utilisateur ne peut contrôler que ce processus.Considérons l'application du mécanisme de consolidation sur les cas de l'exemple indiqué.
Disons que la plateforme Unidata a été introduite dans le bus d'intégration de l'entreprise, qui reçoit des données sur les contreparties du système CRM, du système ERP et du système de vente mobile. La plateforme supprime les doublons, enrichit et harmonise les données, puis transfère les enregistrements de référence vers les systèmes récepteurs.
Cas 1. Correspondance TIN et KPP
Le moyen le plus simple de trouver des contreparties en double est de les comparer par TIN et KPP, dans la plupart des cas, même un TIN suffit. Pour implémenter une telle règle de recherche d'enregistrements en double, il suffit de définir une règle de correspondance exacte pour les attributs INN et KPP.
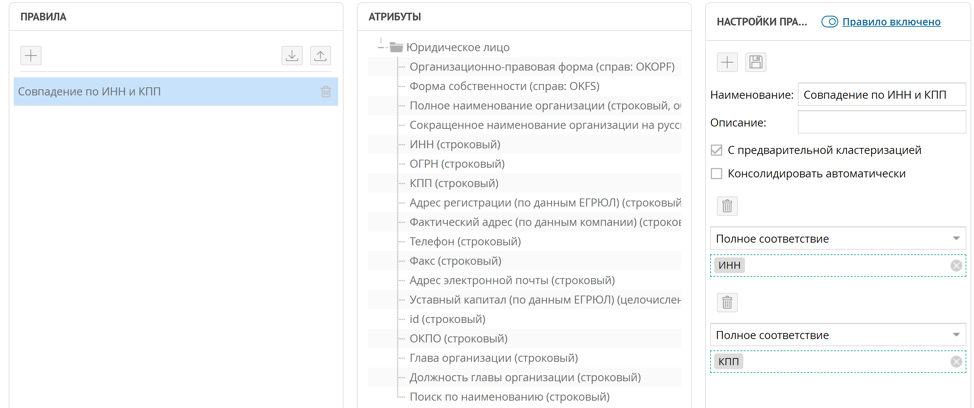
Selon cette règle, lorsqu'un nouvel enregistrement arrive sur la plateforme, la règle de recherche de doublons configurée est automatiquement lancée si la règle est définie sur "pré-clustering". Tous les tuples d'enregistrements trouvés par coïncidence de DCI et KPP sont collectés dans des grappes en double. Dans la fenêtre de cluster en double, Unidata vous permet de créer un enregistrement maître à partir d'enregistrements en double.
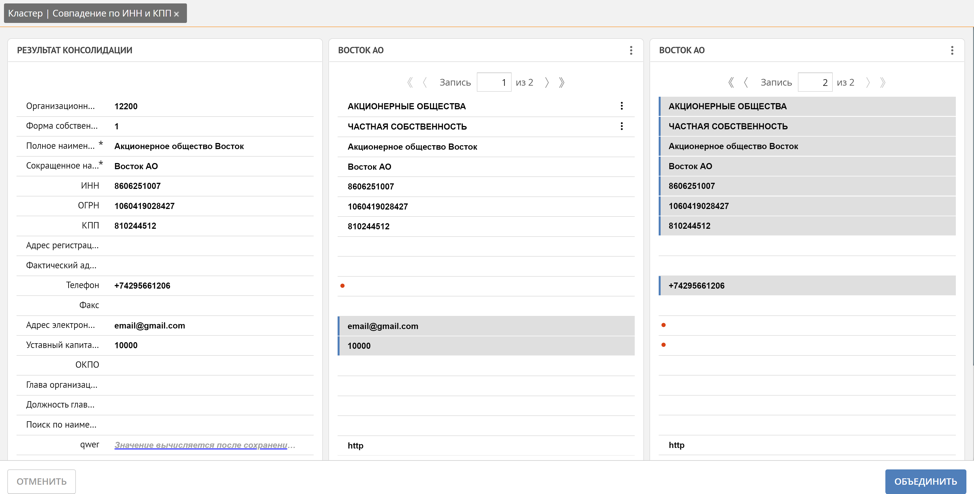
Ici, l'utilisateur peut suivre manuellement quel enregistrement devient automatiquement une référence et, si nécessaire, le corriger en marquant manuellement les valeurs des attributs des enregistrements en double qui doivent être inclus dans l'enregistrement de référence, ou en marquant l'enregistrement entier. De plus, Unidata prend en charge un mécanisme d'enrichissement des valeurs manquantes basé sur des enregistrements similaires. Par exemple, le téléphone, le courrier et le capital-actions ont été automatiquement obtenus à partir de 2 enregistrements en double différents.
Comme nous l'avons déjà noté, la plate-forme, lors de la formation d'un cluster de doublons, détermine automatiquement comment l'enregistrement de référence sera formé. Cela est dû aux poids de confiance mentionnés précédemment des systèmes source. Plus le poids du système d'où provient l'enregistrement est élevé, plus les valeurs de ses attributs sont importantes pour l'enregistrement de référence. Mais souvent, il y a des situations où les valeurs de certains attributs pour un certain système source doivent prévaloir sur tous les autres, par exemple, nous faisons surtout confiance à l'adresse de livraison réelle du client à l'agent qui négocie directement sur le territoire du client et connaît l'adresse exactement, ce qui signifie dans notre exemple de système de vente mobile. Pour résoudre ces problèmes, la plate-forme a la possibilité de définir des pondérations non seulement pour les sources de données, mais également pour les attributs d'enregistrement dans le contexte de chaque source de données.Cette combinaison de poids vous permet de configurer de manière flexible les règles de génération d'un enregistrement de référence.

Cas 2. Correspondance floue par le nom de la personne morale
Bien que le TIN soit un attribut obligatoire, supposons que les informations sur le client n'ont pas été mises à jour depuis longtemps, il a changé sa forme organisationnelle et juridique. Dans ce cas, une entrée avec un TIN différent arrivera déjà sur la plate-forme et la correspondance TIN ne fonctionnera pas. Dans ce cas, la plateforme vous permet de former une règle de correspondance floue par la valeur des attributs, dans ce cas par le nom de l'entité légale.

La recherche floue n'a pas de clustering préliminaire, car cette opération est assez gourmande en ressources, ce qui signifie que cette règle ne fonctionnera pas immédiatement lorsqu'un nouvel enregistrement est ajouté. Pour lancer des règles de recherche floue, une opération spéciale de recherche de doublons est utilisée, qui est lancée manuellement par l'administrateur ou par le système selon un calendrier. Une fois les doublons trouvés, les groupes formés peuvent être visualisés dans une section spéciale de l'interface opérateur de données.
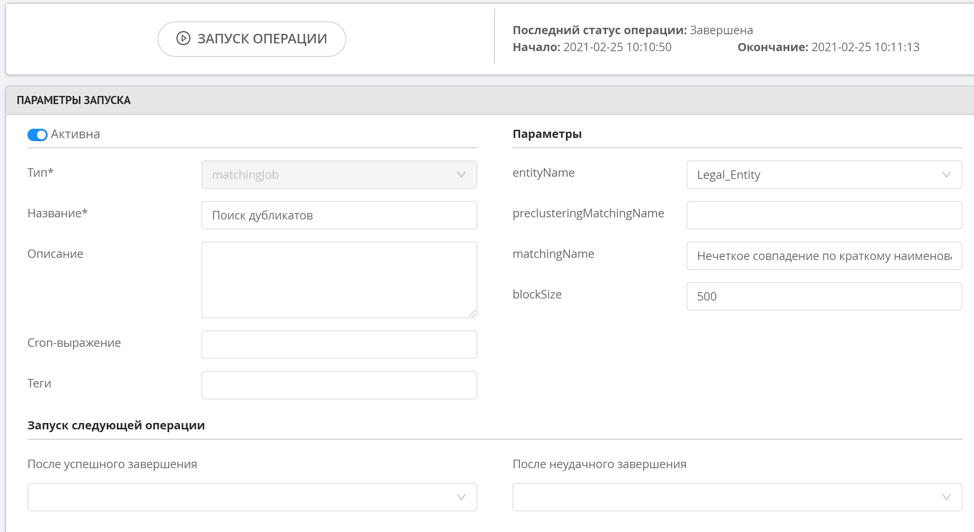

La recherche floue en double fonctionne de telle manière que nous déterminons des valeurs de chaîne similaires qui diffèrent de 1 à 2 caractères ou ne nécessitent pas plus de deux permutations (distance de Levenshtein), il existe également la possibilité de rechercher par n-grammes. Cette approche vous permet de trouver des enregistrements similaires avec une grande précision, tout en ne chargeant pas les ressources pour calculer toutes les manipulations de chaîne possibles si les chaînes sont très différentes les unes des autres.
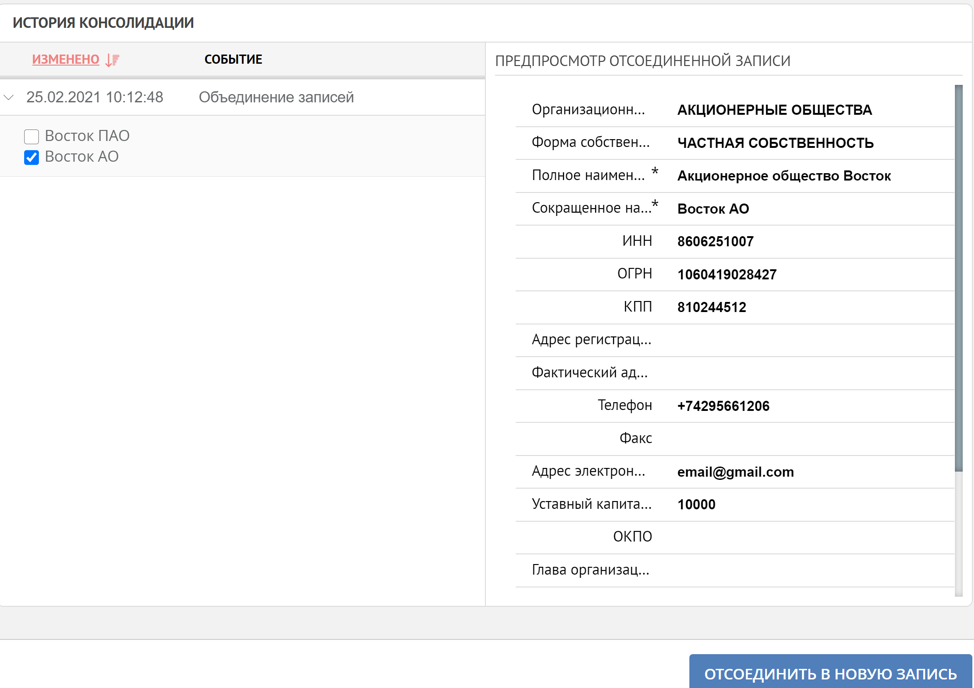
Ainsi, nous avons démontré dans des cas typiques simples les principes de la plate-forme lorsque l'on travaille avec des enregistrements en double. Le traitement en double peut être effectué soit complètement sous le contrôle de l'utilisateur, soit automatiquement. Si la consolidation des données a eu lieu par erreur, comme mentionné au début, le système a toujours la possibilité de visualiser l'historique de la formation de l'enregistrement de référence et, si nécessaire, de démarrer le processus inverse.
Nous ne nous arrêtons pas là, nous recherchons de nouveaux algorithmes et approches lorsque nous travaillons avec des doublons, nous nous efforçons d'assurer la qualité maximale des données dans une variété de systèmes d'entreprise.