Notre traduction aujourd'hui concerne la science des données. Un analyste de données de Dublin a expliqué comment il cherchait un logement sur un marché à forte demande et à faible offre.
J'ai toujours envié les professionnels qui peuvent appliquer leurs compétences professionnelles à leur vie quotidienne . Prenez un plombier, un dentiste ou un chef, par exemple: leurs compétences ne sont pas seulement utiles au travail.
Pour l'analyste de données et l'ingénieur logiciel, ces avantages sont généralement moins tangibles. Bien sûr, je suis féru de technologie, mais au travail, je travaille principalement avec le secteur des affaires, il est donc difficile de trouver des cas d'utilisation intéressants pour mes compétences pour résoudre des problèmes familiaux.
Lorsque ma femme et moi avons décidé d'acheter une nouvelle maison à Dublin, j'ai immédiatement vu une opportunité d'utiliser ces connaissances!
Le contenu de l'article:
- Demande élevée, offre faible
- Recherche de données
- De l'idée à l'outil
- Donnee de base
- Améliorer la qualité des données
- Google Data Studio
- Quelques détails de mise en œuvre (puis passer à la partie amusante)
- Géocodage des adresses
- Calcul du temps pendant lequel la propriété est sur le marché
- Analyse
- résultats
- Conclusion
Les données ci-dessous n'ont pas été récupérées mais générées avec ce script .
Demande élevée, offre faible
Pour comprendre comment tout a commencé, vous pouvez lire mon expérience personnelle d'achat de biens immobiliers à Dublin. Je dois admettre que cela n'a pas été facile: le marché est très demandé (grâce aux excellentes performances économiques de l'Irlande ces dernières années), et le logement est extrêmement cher. L'Irlande affichait les coûts de logement les plus élevés par rapport à l'UE en 2019, selon un rapport d'Eurostat (77% au-dessus de la moyenne de l'UE).

Que signifie ce diagramme?
1. Il y a très peu de maisons qui correspondent à notre budget , et dans les zones de la ville à forte demande, il y en a encore moins (avec des infrastructures de transport plus ou moins normales).
2. L' état des logements secondaires est parfois très mauvais, car il n'est pas rentable pour les propriétaires d'investir dans les réparations avant de vendre. Les maisons à vendre ont souvent une faible efficacité énergétique, une plomberie et un équipement électrique médiocres, ce qui signifie que les acheteurs devront ajouter des coûts de rénovation à un prix déjà élevé.
3. Les ventes sont basées sur un système d'enchères et dans la plupart des cas, les offres des acheteurs dépassent le prix de départ. Pour autant que je sache, cela ne s'applique pas aux nouveaux bâtiments, mais ils dépassaient largement notre budget, nous n'avons donc pas du tout considéré ce segment.
Je pense que de nombreuses personnes dans le monde connaissent cette situation, car, très probablement, les choses sont les mêmes dans les grandes villes.
Comme tout le monde dans notre recherche de propriété, nous voulions trouver la maison parfaite dans le quartier parfait à un prix abordable. Voyons comment l'analyse de données nous a aidés à y parvenir!
Recherche de données
Dans tout projet de Data Science, il y a une étape de collecte de données, et pour ce cas particulier, je cherchais une source contenant des informations sur tous les logements disponibles sur le marché. En Irlande, il existe deux types de sites:
- sites Internet d'agences immobilières,
- agrégateurs.
Les deux options sont très utiles et facilitent grandement la vie des vendeurs et des acheteurs. Malheureusement, l'interface utilisateur et les filtres suggérés ne fournissent pas toujours le moyen le plus efficace d'extraire les informations requises et de comparer différentes propriétés. Voici quelques questions auxquelles il est difficile de répondre avec les moteurs de recherche comme Google:
1. Combien de temps faut-il pour se mettre au travail?
2. Combien de propriétés y a-t-il dans une zone ou une autre? Il est possible de comparer les quartiers des villes sur des sites Web classiques, mais ils couvrent généralement plusieurs kilomètres carrés. Ce n'est pas assez de détails pour comprendre, par exemple, qu'une phrase trop haute dans une rue particulière indique une sorte de truc. La plupart des sites spécialisés ont des cartes, mais elles ne sont pas aussi informatives que nous le souhaiterions.
3. Quelles installations y a-t-il à proximité de la maison?
4. Quel est le prix moyen demandé pour un groupe de propriétés?
5. Depuis combien de temps la propriété est-elle en vente? Même si ces informations sont disponibles, elles ne sont pas toujours fiables, car l'agent immobilier pourrait supprimer l'annonce et la placer à nouveau.
La refonte de l'interface utilisateur pour la convivialité et l'amélioration de la qualité des données ont rendu la recherche d'un logement beaucoup plus facile et nous ont permis de tirer des idées très intéressantes.
De l'idée à l'outil
Donnee de base
La première étape a été d'écrire un grattoir pour collecter des informations de base:
- adresse brute de la propriété,
- prix vendeur actuel,
- lien vers la page avec la propriété,
- les caractéristiques de base telles que le nombre de pièces, le nombre de salles de bain, la cote d'efficacité énergétique,
- nombre de vues d'annonces (si disponible),
- type de bien (maison, appartement, immeuble neuf).
Ce sont, en fait, toutes les données que j'ai pu trouver sur Internet. Pour une analyse plus approfondie, j'avais besoin d'améliorer cet ensemble de données.
Améliorer la qualité des données
Lors du choix d'une maison, mon principal argument en faveur de l'achat est une route pratique pour me rendre au travail, pour moi, ce n'est pas plus de 50 minutes pour tout le trajet de porte à porte. Pour ces calculs, j'ai décidé d'utiliser la plate-forme Google Cloud:
1. À l'aide de l'API Geocoding, j'ai obtenu les coordonnées de latitude et de longitude en utilisant l'adresse de la propriété.
2. À l'aide de l'API Directions, j'ai calculé le temps qu'il faut pour aller de la maison au travail à pied et en transports en commun. Remarque: le vélo est environ 3 fois plus rapide que la marche.
3. Utilisation des sièges d'API (API Places)J'ai reçu des informations sur les équipements autour de chaque propriété. En particulier, nous nous sommes intéressés aux pharmacies, aux supermarchés et aux restaurants. Remarque: les API Places sont très coûteuses: avec une base de données de 4 000 propriétés, vous devrez exécuter 12 000 requêtes pour trouver des informations sur trois types d'équipements. Par conséquent, j'ai exclu ces données du tableau de bord final.
Outre la situation géographique, une autre question m'intéressait: depuis combien de temps la propriété est-elle sur le marché? Si la propriété n'a pas été vendue depuis trop longtemps, c'est un réveil: peut-être que quelque chose ne va pas avec le quartier ou la maison elle-même, ou le prix demandé est trop élevé.
A l'inverse, si le bien vient d'être mis en vente, il faut garder à l'esprit que les propriétaires n'accepteront pas la première offre reçue. Malheureusement, ces informations sont assez faciles à cacher. À l'aide de l'apprentissage automatique de base, j'ai estimé cet aspect à l'aide du nombre de vues des annonces et de quelques autres statistiques.
Enfin, j'ai amélioré le jeu de données avec quelques champs de service pour faciliter le filtrage (par exemple en ajoutant une colonne avec une fourchette de prix).
Google Data Studio
Avec un jeu de données amélioré qui me convenait, j'allais créer un tableau de bord puissant . J'ai choisi Google Data Studio comme outil de visualisation de données pour cette tâche. Ce service présente certains inconvénients (ses capacités sont très, très limitées), mais il y a aussi des avantages: il est gratuit, a une version Web et peut lire les données de Google Sheets. Voici un diagramme décrivant l'ensemble du flux de travail.

Quelques détails d'implémentation
Pour être honnête, la mise en œuvre était assez simple et il n'y a rien de nouveau ou de spécial ici: juste un tas de scripts pour collecter des données et quelques transformations de base de Pandas. Sauf qu'il vaut la peine de noter l'interaction avec l'API Google et le calcul du temps pendant lequel le bien était sur le marché.
Les données ci-dessous n'ont pas été récupérées mais générées avec ce script .
Jetons un coup d'œil aux données brutes.
Comme je m'y attendais, le fichier contient les colonnes suivantes:
id
: ID d'annonce._address
: Adresse de la propriété._d_code
: . D<>. <> , (, ), — ._link
: , ._price
: .type
: (, , )._bedrooms
: ()._bathrooms
: ._ber_code
: , : «», ._views
: ( )._latest_update
: ( ).days_listed
: — , ,_last_update
.
Le but est d'apporter tout cela à la carte et de tirer parti de la puissance des données géolocalisées. Pour ce faire, voyons comment obtenir la latitude et la longitude à l'aide de l'API Google.
Pour ce faire, vous avez besoin d'un compte avec Google Cloud Platform, puis vous pouvez suivre le tutoriel sur le lien pour obtenir une clé API et activer l'API correspondante. Comme je l'ai écrit plus tôt, pour ce projet, j'ai utilisé l'API de géocodage, l'API Directions et l'API Places (vous devrez donc activer ces API spécifiques lors de la création de la clé API). Vous trouverez ci-dessous un extrait de code pour interagir avec Google Cloud Platform.
# The Google Maps library
import googlemaps
# Date time for easy computations between dates
from datetime import datetime
# JSON handling
import json
# Pandas
import pandas as pd
# Regular expressions
import re
# TQDM for fancy loading bars
from tqdm import tqdm
import time
import random
# !!! Define the main access point to the Google APIs.
# !!! This object will contain all the functions needed
geolocator = googlemaps.Client(key="<YOUR API KEY>")
WORK_LAT_LNG = (<LATITUDE>, <LONGITUDE>)
# You can set this parameter to decide the time from which
# Google needs to calculate the directions
# Different times affect public transport
DEPARTURE_TIME = datetime.now
# Load the source data
data = pd.read_csv("/path/to/raw/data/data.csv")
# Define the columns that we want in the geocoded dataframe
geo_columns = [
"_link",
"lat",
"lng",
"_time_to_work_seconds_transit",
"_time_to_work_seconds_walking"
]
# Create an array where we'll store the geocoded data
geo_data = []
# For each element of the raw dataframe, start the geocoding
for index,
in tqdm(data.iterrows()):
# Google Geo coding
_location = ""
_location_json = ""
try:
# Try to retrieve the base location,
# i.e. the Latitude and Longitude given the address
_location = geolocator.geocode(row._address)
_location_json = json.dumps(_location[0])
except:
pass
_time_to_work_seconds_transit = 0
_directions_json = ""
_lat_lon = {"lat": 0, "lng": 0}
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the distance with PUBLIC TRANSPORT (`mode=transit`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG,
(_lat_lon["lat"], _lat_lon["lng"]), mode="transit")
_time_to_work_seconds_transit = _directions[0]["legs"][0]["duration"]["value"]
_directions_json = json.dumps(_directions[0])
except:
pass
_time_to_work_seconds_walking = 0
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the WALKING distance (`mode=walking`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG, (_lat_lon["lat"], _lat_lon["lng"]), mode="walking")
_time_to_work_seconds_walking = _directions[0]["legs"][0]["duration"]["value"]
except:
pass
# This block retrieves the number of SUPERMARKETS arount the property
'''
_supermarket_nr = 0
_supermarket = ""
try:
# _supermarket = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="supermarket")
_supermarket_nr = len(_supermarket["results"])
except:
pass
'''
# This block retrieves the number of PHARMACIES arount the property
'''
_pharmacy_nr = 0
_pharmacy = ""
try:
# _pharmacy = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="pharmacy")
_pharmacy_nr = len(_pharmacy["results"])
except:
pass
'''
# This block retrieves the number of RESTAURANTS arount the property
'''
_restaurant_nr = 0
_restaurant = ""
try:
# _restaurant = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="restaurant")
_restaurant_nr = len(_restaurant["results"])
except:
pass
'''
geo_data.append([row._link, _lat_lon["lat"], _lat_lon["lng"], _time_to_work_seconds_transit,
_time_to_work_seconds_walking])
geo_data_df = pd.DataFrame(geo_data)
geo_data_df.columns = geo_columns
geo_data_df.to_csv("geo_data_houses.csv", index=False)
Calcul du temps pendant lequel la propriété est sur le marché
Examinons de plus près les données :
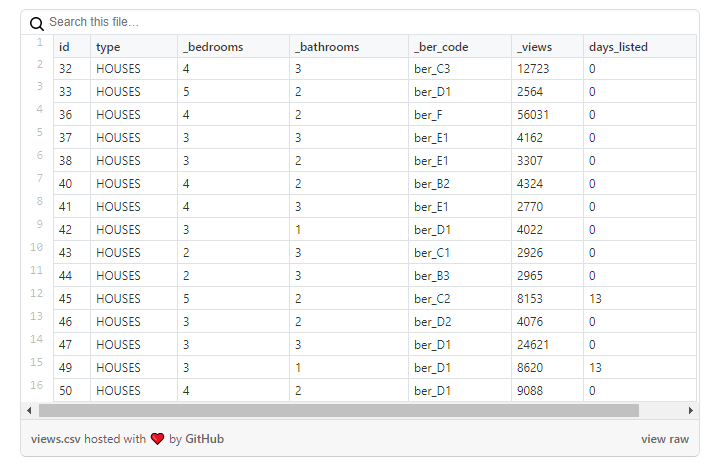
comme vous pouvez le voir dans cet exemple, le nombre de vues de propriétés ne se reflète pas dans le nombre de jours pendant lesquels l'annonce était active: par exemple, une maison avec un id = 47 a ~ 25 mille vues, mais il est apparu ce jour-là, lorsque j'ai chargé des données.
Cependant, ce problème n'est pas courant pour toutes les propriétés. Dans l'exemple ci - dessous , le nombre de vues est plus comparable au nombre de jours pendant lesquels l'annonce était active:

Comment pouvons-nous utiliser les informations ci-dessus? Facilement! Nous pouvons utiliser le deuxième ensemble de données comme ensemble d'apprentissage pour le modèle, que nous pouvons ensuite appliquer au premier ensemble de données.
J'ai testé deux approches:
1. Prenez un ensemble de données «comparable» et calculez le nombre moyen de vues par jour, puis appliquez cette valeur au premier ensemble de données. Cette approche n'est pas dénuée de bon sens, mais elle pose le problème suivant: toutes les propriétés sont regroupées en un seul groupe, et il est probable qu'une annonce pour la vente d'une maison d'une valeur de 10 millions d'euros recevra moins de vues par jour, puisqu'une telle le budget est disponible pour un groupe restreint de personnes.
2. Entraînez le modèle Random Forest sur le deuxième jeu de données, puis appliquez-le au premier jeu de données.
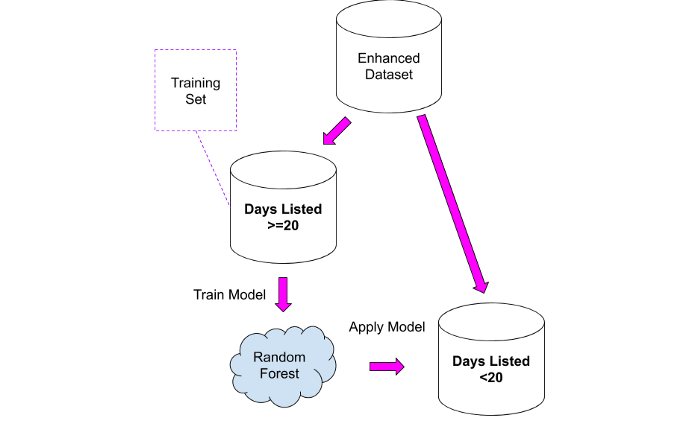
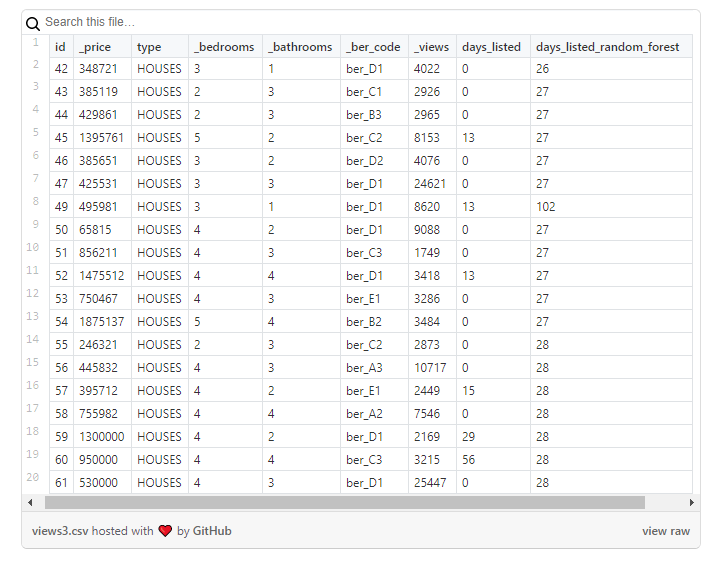
Les résultats doivent être examinés très attentivement, en gardant à l'esprit que la nouvelle colonne ne contiendra que des valeurs approximatives: je les ai utilisées comme point de départ pour analyser plus en détail les propriétés là où quelque chose semblait étrange.
Analyse
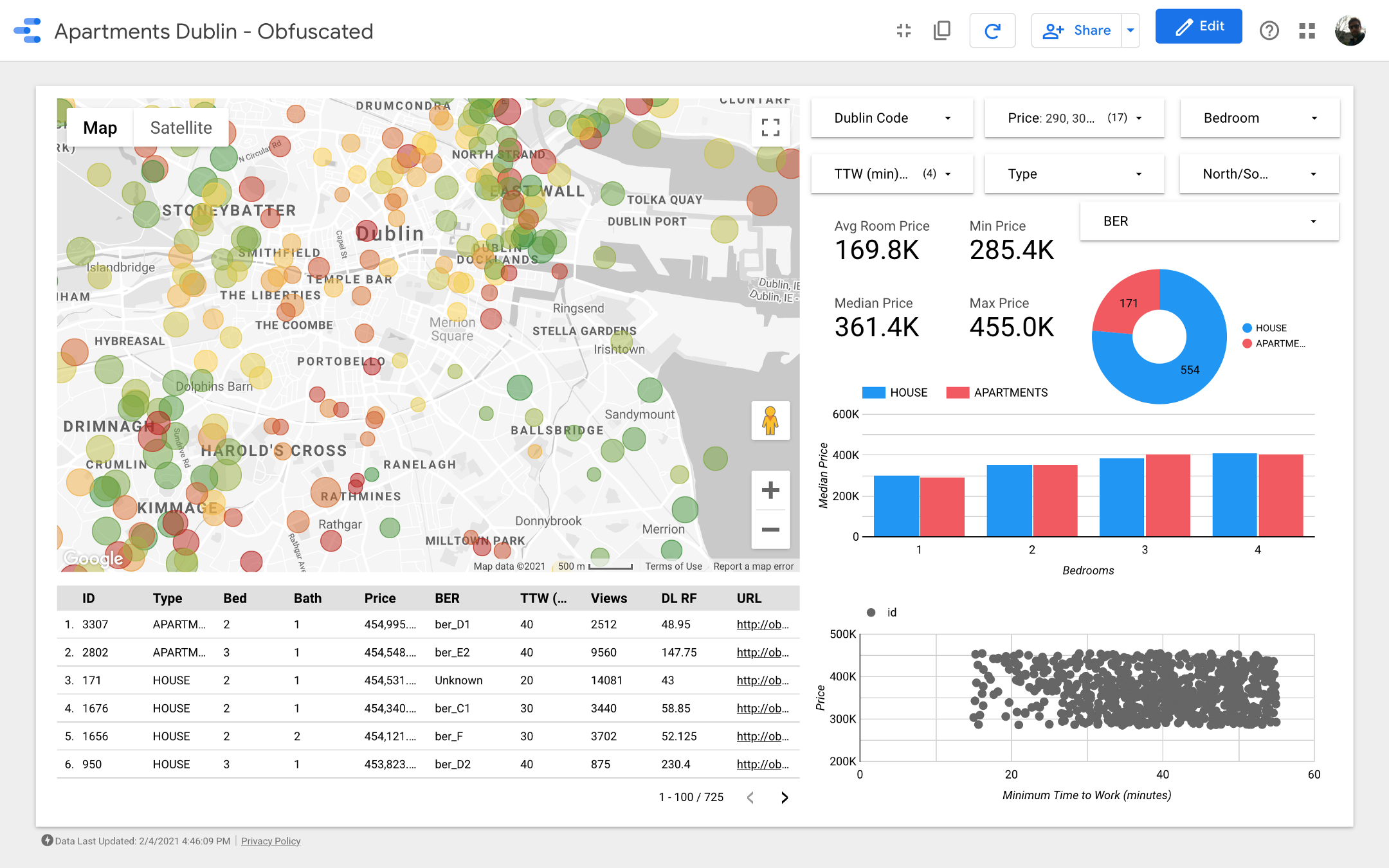
Mesdames et messieurs, je présente à votre attention le tableau de bord final . Si vous voulez y creuser, suivez le lien .
Remarque: Malheureusement, le module Google Maps ne fonctionne pas lorsqu'il est intégré dans un article, j'ai donc dû utiliser des captures d'écran.
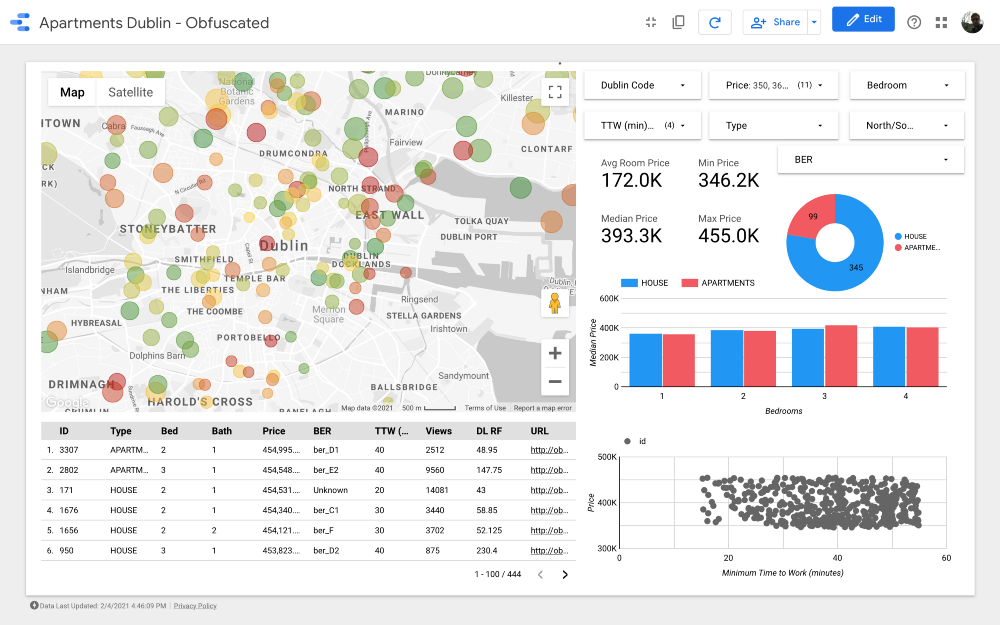
https://datastudio.google.com/s/qKDxt8i2ezE La
carte est la partie la plus importante du tableau de bord. La couleur des bulles dépend du prix de la maison / appartement, et la coloration ne prend en compte que les propriétés disponibles (correspondant aux paramètres de filtre dans le coin supérieur droit); la taille des bulles indique la distance à parcourir: plus elle est petite, plus la route est courte.
Les graphiques vous permettent d'analyser comment le prix demandé change en fonction de certaines caractéristiques (par exemple, le type de bâtiment ou le nombre de pièces), et le nuage de points compare la distance au travail et le prix demandé.
Enfin, le tableau de données brutes (
DL RF
correspond à Days Listed Random Forest et indique le nombre de jours pendant lesquels l'annonce a été active, le modèle Random Forest).
résultats
Plongeons dans l'analyse et voyons quelles conclusions nous pouvons tirer du tableau de bord.
L'ensemble de données comprend environ 4000 maisons et appartements: bien sûr, nous ne pouvons pas tous les visualiser, notre tâche est donc d' identifier un sous-ensemble d'enregistrements contenant une ou plusieurs propriétés que nous sommes prêts à envisager d'acheter.
Tout d'abord, nous devons clarifier les critères de recherche. Par exemple, disons que nous recherchons une propriété qui répond aux caractéristiques suivantes:
1. Type de propriété: Maison.
2. Nombre de pièces (chambres): 3.
3. Distance du travail: moins de 60 minutes.
4. Classe d'efficacité énergétique: A, B, C ou D.
5. Prix: de 250 à 540 milliers d'euros.
Appliquons tous les filtres sauf le prix et regardons la carte (en ne filtrant que ceux qui sont plus chers que 1 million et moins de 200 milliers d'euros).
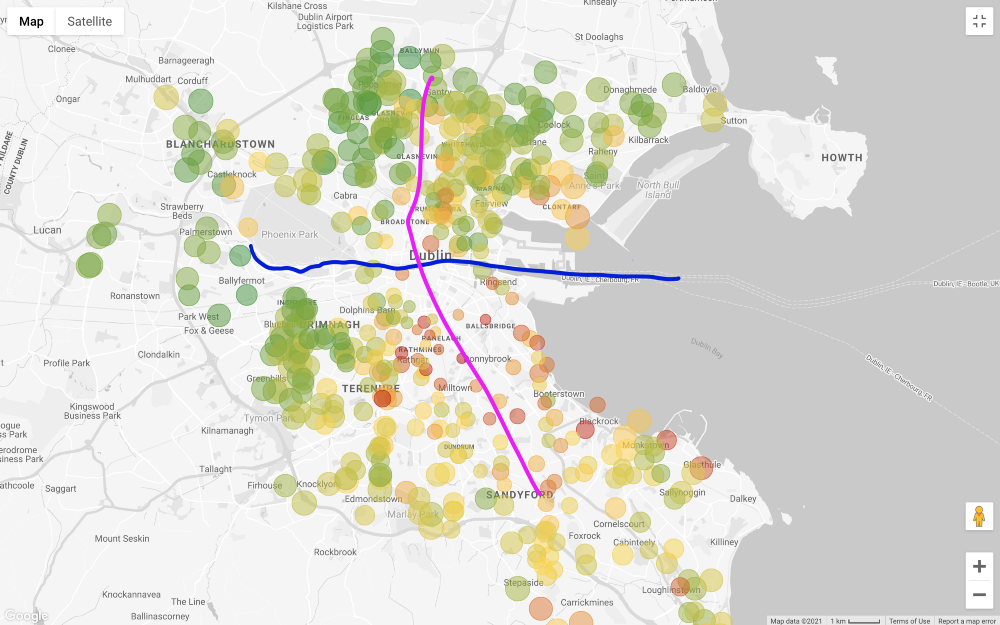
En général, le prix demandé pour les propriétés dans le sud de Liffey est beaucoup plus élevé que dans le nord, à quelques exceptions près dans le sud-ouest de la ville. Même les «zones extérieures» du nord, c'est-à-dire du nord-est et du nord-ouest, semblent moins chères que le nord du centre-ville. L'une des raisons de ce prix est que la ligne principale de tramway de Dublin (LUAS) traverse la ville du nord au sud en ligne droite (il existe une autre ligne qui va d'ouest en est, mais elle ne traverse pas tous les quartiers d'affaires).
Veuillez noter que je fais ces considérations uniquement sur la base d'une inspection visuelle. Une approche plus approfondie nécessite de tester la corrélation entre le prix d'une maison et sa distance par rapport aux transports en commun, mais cela ne nous intéresse pas de prouver ce lien.
La situation devient encore plus intéressante, si vous définissez les prix du filtre en ligne avec notre budget (n'oubliez pas que sur la carte ci-dessus montre la maison avec 3 chambres, et mettez-vous au travail en moins de 60 minutes, et sur la carte ci-dessous ajoutée seulement filtrer par prix):
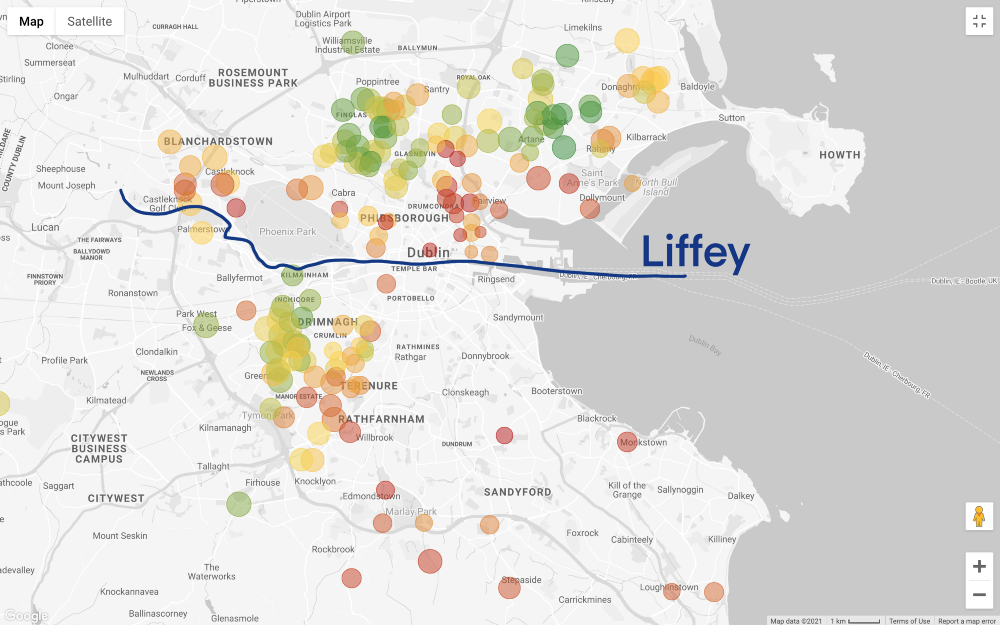
Prenons du recul. Nous avons une idée générale des domaines que nous pouvons nous permettre, mais maintenant le plus difficile est à venir - la recherche de compromis! Voulons-nous trouver une option plus économique? Ou considérons-nous la meilleure maison que nos économies durement gagnées peuvent acheter? Malheureusement, l'analyse des données ne peut pas répondre à ces questions, il s'agit d'une décision commerciale (et très personnelle).
Supposons que nous choisissions la deuxième option: nous privilégions la qualité de la maison ou de la zone au prix le plus bas.
Dans ce cas, nous devons considérer les options suivantes:
1. Zones avec une faible concentration de propositions - une maison isolée sur la carte peut indiquer qu'il n'y a pas beaucoup d'offres dans la région, ce qui signifie que les propriétaires ne sont pas pressés de se séparer de leur maison dans un si bon quartier ...
2. Une maison située dans un groupe de propriétés chères - si toutes les autres propriétés à proximité d'une maison particulière sont chères, cela peut signifier que la région est en forte demande. Ce n'est qu'une note supplémentaire, mais nous pourrions quantifier ce phénomène en utilisant l'autocorrélation spatiale (par exemple, en calculant le I de Moran ).
Même si la première option semble attrayante, il faut garder à l'esprit que le prix très bas de l'immobilier par rapport à d'autres offres dans le même quartier peut impliquer une sorte de prise dans la maison elle-même (par exemple, de petites pièces ou des coûts de rénovation très élevés ). Pour cette raison, nous poursuivrons notre analyse en nous concentrant sur la deuxième option, qui, à mon avis, est la plus prometteuse compte tenu de notre objectif.
Examinons de plus près les propositions dans ce domaine:

nous avons déjà réduit nos options de 4 000 à moins de 200, et maintenant nous devons mieux casser les points et comparer les clusters.
L'automatisation de la recherche de cluster n'ajoutera pas grand-chose à cette analyse, mais appliquons quand même l' algorithme DBSCAN.... Nous utilisons DBSCAN car certains des groupes peuvent être non globulaires (par exemple, k-means ne fonctionnera pas correctement sur cette base de données). En théorie, nous devons calculer la distance géographique entre les points, mais nous utiliserons le système euclidien, car il donne une bonne approximation:
import pandas as pd
from sklearn.cluster import DBSCAN
data = pd.read_csv("data.csv")
data["labels"] = DBSCAN(eps=0.01, min_samples=3).fit(data[["lat","lng"]].values).labels_
print(data["labels"].unique())
data.to_csv("out.csv")

L'algorithme a donné un assez bon résultat, mais je réviserais les clusters comme suit (en tenant compte de la connaissance des quartiers d'affaires de Dublin):

Nous refusons les zones à prix plus bas, car nous privilégions la qualité maximale du logement et une route confortable pour travailler à l'intérieur. notre budget afin d'exclure les clusters 2, 3, 4, 6 et 9. Notez que les clusters 2, 3 et 4 sont situés dans certaines des zones les plus économiques du nord de Dublin (probablement en raison d'une infrastructure de transport public moins développée). Le cluster 11 présente des options coûteuses situées loin du travail, nous pouvons donc également l'exclure.
En ce qui concerne les grappes les plus chères, le numéro 7 est l'un des meilleurs en termes de distance au travail. il Drumcondra , un beau quartier résidentiel au nord de Dublin; malgré le fait qu'il ne soit pas très bien situé par rapport à la ligne de tramway, des lignes de bus le longent; dans le groupe 8, les prix des logements et la distance au travail sont les mêmes qu'à Drumkondra. Un autre groupe qui mérite d'être analysé est le numéro 10: il semble se trouver dans une zone où l'offre est plus faible, ce qui signifie que les gens ici vendent probablement rarement des logements, et la zone est également assez bien située pour les routes publiques. densité de population).
Enfin, les groupes 1 et 5, situés à côté du parc Phoenix, le plus grand parc public clôturé .
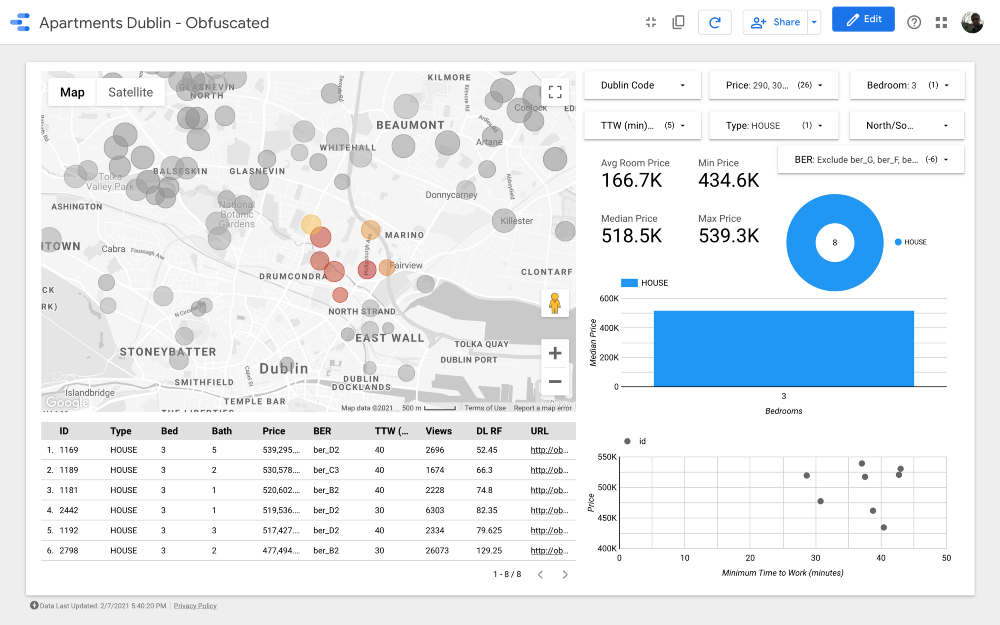
Groupe 7

Cluster 8
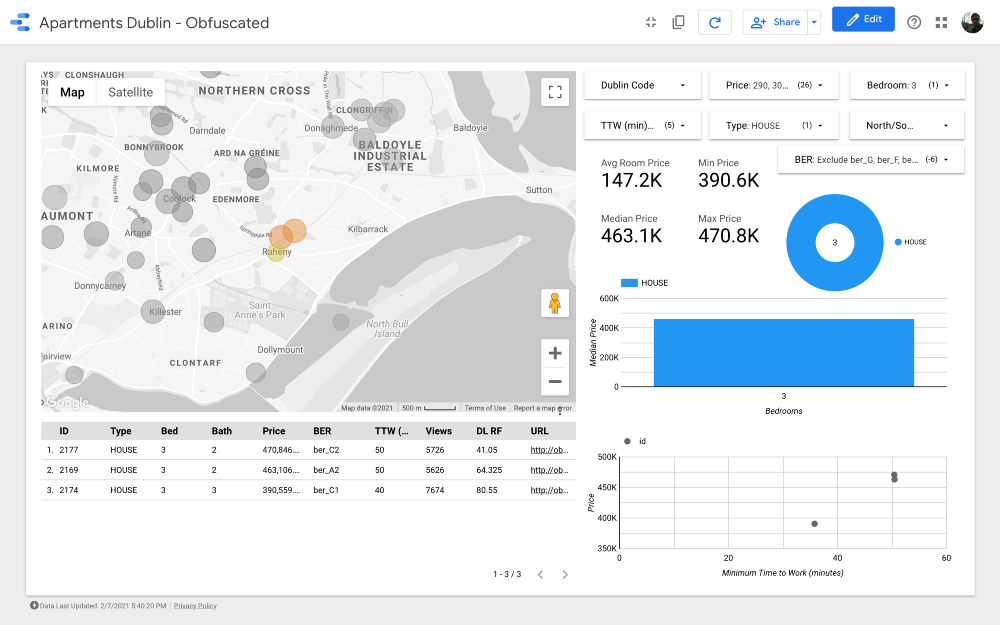
Cluster 10
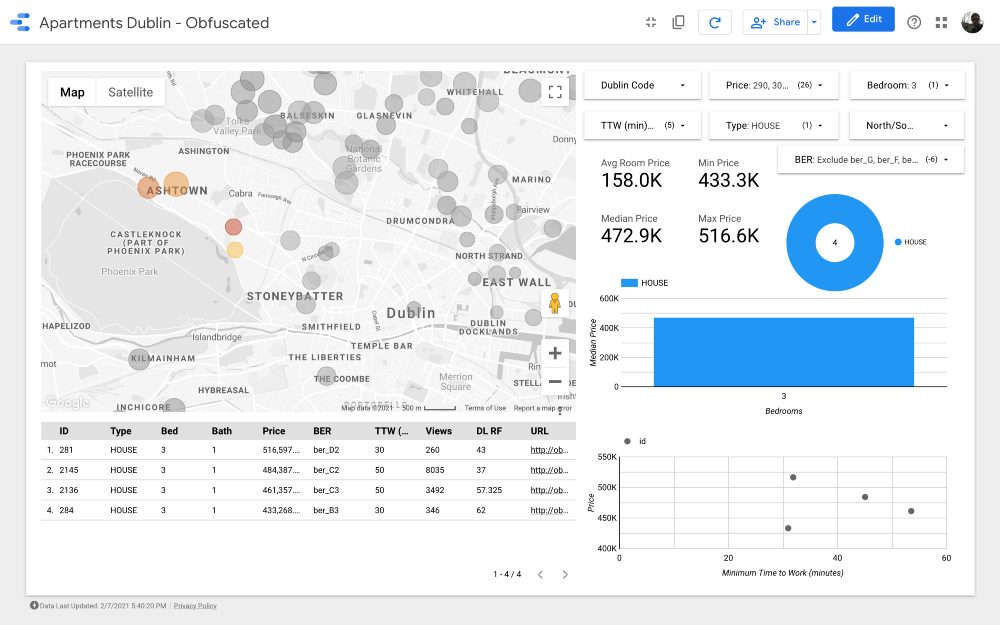
Cluster 1

Cluster 5
Génial! Nous avons trouvé 26 propriétés qui valent le détour. Maintenant, nous pouvons analyser soigneusement chaque offre et, finalement, organiser une visite avec un agent immobilier!
Conclusion
Nous avons commencé notre recherche, ne sachant pratiquement rien sur Dublin, et nous avons finalement bien compris les quartiers de la ville qui sont particulièrement demandés lors de l'achat d'une maison.
Attention, nous n'avons même pas regardé les photos de ces maisons et n'avons rien lu à leur sujet! Juste en regardant un tableau de bord bien organisé, nous sommes arrivés à des conclusions utiles auxquelles nous n'aurions pas pu arriver au début!
Ces données ne sont plus utiles et certaines intégrations peuvent être effectuées pour améliorer l'analyse. Quelques réflexions:
1. Nous n'avons pas intégré l'ensemble de données sur les commodités (celui que nous avons compilé à l'aide de l'API Places) dans l'étude. Avec un budget plus important pour les services cloud, nous pourrions facilement ajouter ces informations au tableau de bord.
2. En Irlande, de nombreuses données intéressantes sont publiées sur le site Internet de l'office statistique : par exemple, vous pouvez trouver des informations sur le nombre d'appels à chaque poste de police par quartier et par type de délit. Ainsi, nous pourrions savoir dans quels domaines il y a le plus de vols. Puisqu'il est possible d'obtenir des données de recensement pour chaque bureau de vote, nous pourrions également calculer le taux de criminalité par habitant. Veuillez noter que pour de telles fonctionnalités avancées, nous avons besoin d'un système d'information géographique approprié (par exemple QGIS ) ou d'une base de données capable de gérer des données géographiques (par exemple PostGIS ).
3. L'Irlande dispose d'une base de données des prix des logements antérieurs appelée Registre des propriétés résidentielles . Leur site Web contient des informations sur chaque propriété résidentielle achetée en Irlande depuis le 1er janvier 2010, y compris la date de vente, le prix et l'adresse. En comparant les prix actuels des maisons aux prix passés, vous pouvez voir comment la demande a évolué au fil du temps.
4. Les prix de l'assurance habitation dépendent dans une large mesure de l'emplacement de la maison. Avec un peu d'effort, nous pourrions supprimer les sites des compagnies d'assurance pour intégrer leur «modèle de facteur de risque» dans notre tableau de bord.
Dans un marché comme Dublin, trouver une nouvelle maison peut être une tâche ardue, en particulier pour quelqu'un qui vient de s'installer en ville et qui ne la connaît pas très bien.
Grâce à cet outil, ma femme et moi avons gagné du temps (ainsi qu'à l'agent immobilier): nous sommes allés regarder 4 fois, avons offert leur prix à 3 vendeurs, et l'un d'eux a accepté notre offre.