En quelque sorte, cet article est une suite de notre article sur le dimensionnement sur Habré . Mais des exemples réels sont apparus ici, donc s'il y a un besoin d'une sorte de continuité, commencez par cet article, puis revenez ici. Tous les détails sont sous la coupe.
Cet article est basé sur l' analyse comparative et le dimensionnement de votre cluster Elasticsearch pour les journaux et les métriques sur le blog Elastic. Nous l'avons légèrement modifié et avons supprimé les exemples avec Elastic basé sur le cloud.
Ressources matérielles du cluster Elasticsearch
Les performances d'un cluster Elasticsearch dépendent principalement de la façon dont vous l'utilisez et de ce qui s'exécute en dessous (au sens du matériel). Le matériel se caractérise par les éléments suivants:
Sauter
Le fournisseur recommande d'utiliser des disques SSD dans la mesure du possible. Mais, évidemment, cela peut ne pas être le cas partout, donc l'architecture chaud-chaud-froid et l'Index Lifecycle Management (ILM) sont à votre service.
Elasticsearch ne nécessite pas de stockage redondant (vous pouvez vous passer de RAID 1/5/10), les scénarios de stockage de journaux ou de métriques ont généralement au moins une réplique pour une tolérance de panne minimale.
Mémoire
La mémoire sur le serveur est divisée en:
JVM Heap. Stocke les métadonnées sur le cluster, les index, les segments, les segments et les données de champ de document. Idéalement, vous devriez allouer 50% de la RAM disponible à cela.
Cache du système d'exploitation. Elasticsearch utilisera la mémoire disponible restante pour mettre en cache les données, ce qui améliorera considérablement les performances en empêchant les lectures de disque pendant les recherches de texte intégral, les agrégations de valeurs de documents et le tri. Et n'oubliez pas de désactiver le swap (fichier d'échange) pour éviter de vider le contenu de la RAM sur le disque puis de le lire (c'est lent!).
CPU
Les nœuds Elasticsearch ont ce que l'on appelle. pools de threads et files d'attente de threads qui utilisent les ressources informatiques disponibles. Le nombre et les performances des cœurs de processeur déterminent la vitesse moyenne et le débit maximal des opérations de données dans Elasticsearch. Le plus souvent, il s'agit de 8 à 16 cœurs.
Réseau
Performances du réseau - la bande passante et la latence peuvent affecter considérablement la communication entre les nœuds Elasticsearch et la communication entre les clusters Elasticsearch. Veuillez noter que par défaut, une vérification de la disponibilité des nœuds est effectuée toutes les secondes et si un nœud ne ping pas dans les 30 secondes, il est marqué comme indisponible et est arrêté à partir du cluster.
Dimensionnement d'un cluster Elasticsearch par volume de stockage
Le stockage des journaux et des métriques nécessite généralement une quantité importante d'espace disque, il est donc utile d'utiliser la quantité de ces données pour déterminer initialement la taille de notre cluster Elasticsearch. Voici quelques questions pour comprendre la structure de données qui doit être gérée dans un cluster:
- Combien de données brutes (Go) allons-nous indexer par jour?
- Combien de jours conserverons-nous les données?
- Combien de jours y a-t-il dans la zone chaude?
- Combien de jours y a-t-il dans la zone chaude?
- Combien de répliques seront utilisées?
Il est conseillé de mettre 5% ou 10% au-dessus et pour que 15% de l'espace disque total reste toujours en stock. Essayons maintenant de compter ce cas.
Taille totale des données (Go) = Nombre de données brutes par jour (Go) * Nombre de jours de stockage * (Nombre de réplicas + 1).
Stockage total (Go) = Total des données (Go) * (1 + 0,15 espace de stockage + 0,1 stockage supplémentaire).
Nombre total de nœuds de données = OKRVVERH (taille totale des données (Go) / taille de la mémoire par nœud de données / mémoire: ratio de données). Dans le cas d'une grande installation, il est préférable de conserver un nœud supplémentaire supplémentaire en stock.
Elastic recommande les ratios de mémoire suivants: données pour différents types de nœuds: chaud → 1:30 (30 Go d'espace disque par gigaoctet de mémoire), chaud → 1: 160, froid → 1: 500). OKRVVERKH - entoure à l'entier supérieur le plus proche.
Exemple de calcul de petit cluster
Supposons que ~ 1 Go de données arrive chaque jour, qui doit être stocké pendant 9 mois.
Total des données (Go) = 1 Go x (9 mois x 30 jours) x 2 = 540 Go
Stockage total (Go) = 540 Go x (1 + 0,15 + 0,1) = 675 Go
Nombre total de nœuds de données = 675 Go / 8 Go de RAM / 30 = 3 nœuds.
Exemple de calcul d'un grand cluster
Vous obtenez 100 Go par jour et vous stockerez ces données pendant 30 jours dans la zone chaude et 12 mois dans la zone chaude. Vous disposez de 64 Go de mémoire par nœud, dont 30 Go sont alloués au tas JVM et le reste au cache du système d'exploitation. Le rapport mémoire / données recommandé pour la zone chaude est de 1:30, pour la zone chaude - 1: 160.
Ainsi, si vous obtenez 100 Go par jour et que vous devez stocker ces données pendant 30 jours, nous obtenons:
Quantité totale de données (Go) dans la zone chaude = (100 Go x 30 jours * 2) = 6000 Go de stockage
total de la zone chaude (Go) = 6000 Go x (1 + 0,15 + 0,1) = 7500 Go
Total des nœuds de données de la zone chaude = OK 7500 / 64/30) + 1 = 5 nœuds
Données totales (Go) dans la zone chaude= (100 Go x 365 jours * 2) = 73000 Go
Stockage total (Go) dans la zone chaude = 73000 Go x (1 + 0,15 + 0,1) = 91250 Go
Nombre total de nœuds de données dans la zone chaude = OKRVVERKH (91250 / 64/160) + 1 = 10 nœuds
Ainsi, nous avons obtenu 5 nœuds pour la zone chaude et 10 nœuds pour le fruit chaud. Pour la zone froide, calculs similaires, mais le ratio mémoire: les données seront déjà de 1: 500.
Des tests de performance
Une fois que la taille du cluster a été déterminée, il faut confirmer que les mathématiques fonctionnent dans la vraie vie.
Ce test utilise le même outil que les ingénieurs d'Elasticsearch, Rally . Il est facile à déployer et à exécuter et est entièrement personnalisable, de sorte que plusieurs scénarios (pistes) peuvent être testés.
Pour faciliter l'analyse des résultats, le test est divisé en deux sections: l'indexation et les requêtes de recherche. Les tests utiliseront les données des pistes Metricbeat et des journaux du serveur Web .
Indexage
Les tests répondent aux questions suivantes:
- Quel est le débit maximal pour l'indexation des clusters?
- Combien de données peuvent être indexées par jour?
- Le cluster est-il plus grand ou plus petit que la taille appropriée?
Ce test utilise un cluster à 3 nœuds avec la configuration suivante pour chaque nœud:
- 8 vCPU;
- HDD;
- 32 Go / 16 tas.
Test d'indexation n ° 1
L'ensemble de données utilisé pour le test est constitué de données Metricbeat avec les caractéristiques suivantes:
- 1 079 600 documents;
- Volume de données: 1,2 Go;
- Taille moyenne des documents: 1,17 Ko.
Ensuite, il y aura plusieurs tests pour déterminer la taille optimale des paquets et le nombre optimal de threads.
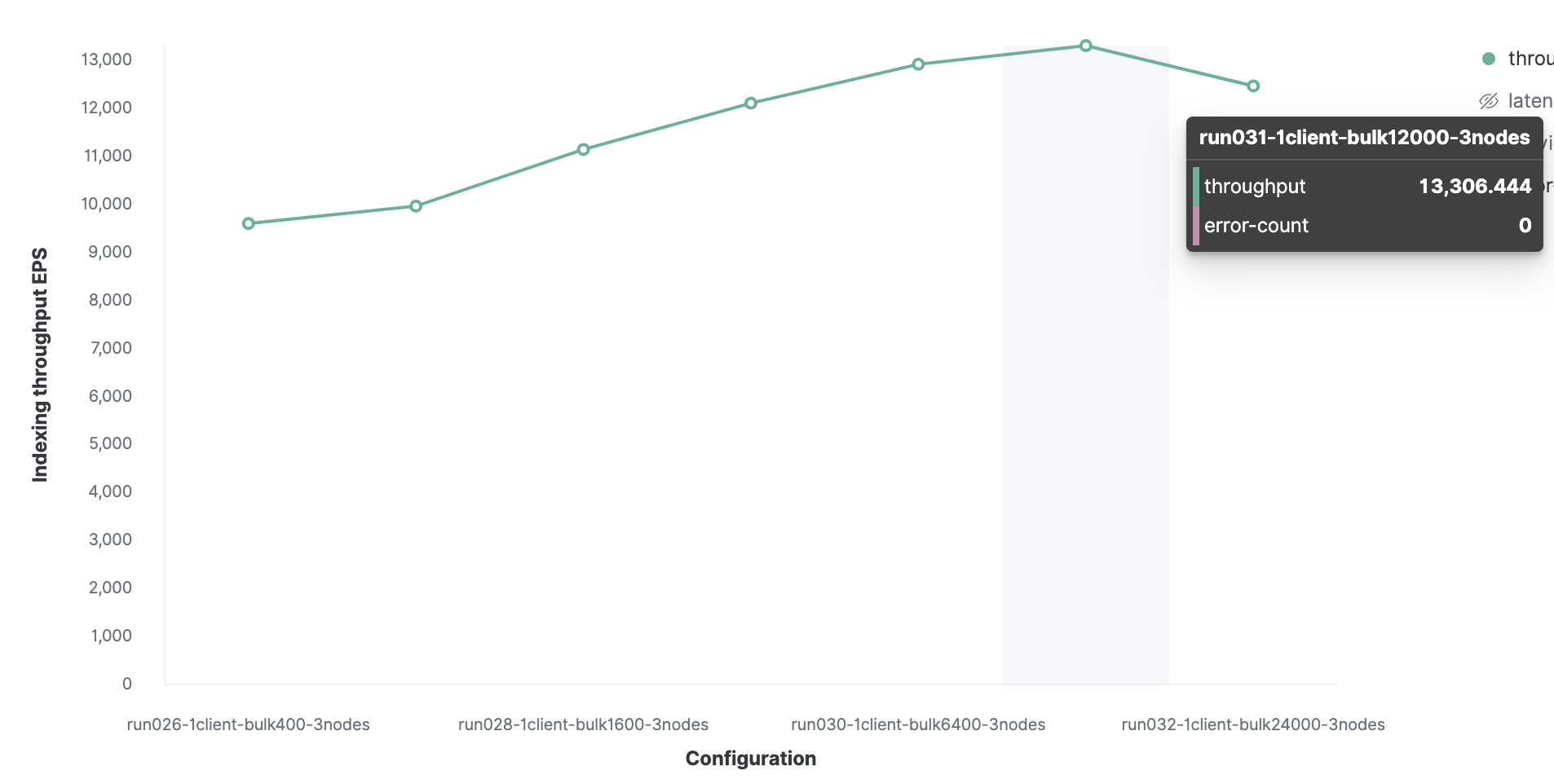
Tout commence avec 1 client Rally pour trouver la taille de paquet optimale. Au départ, 100 documents sont chargés, puis leur nombre double lors des lancements suivants. Le résultat sera une taille de lot optimale de 12 000 documents (soit environ 13,7 Mo). À mesure que la taille des paquets augmente, les performances commencent à baisser.
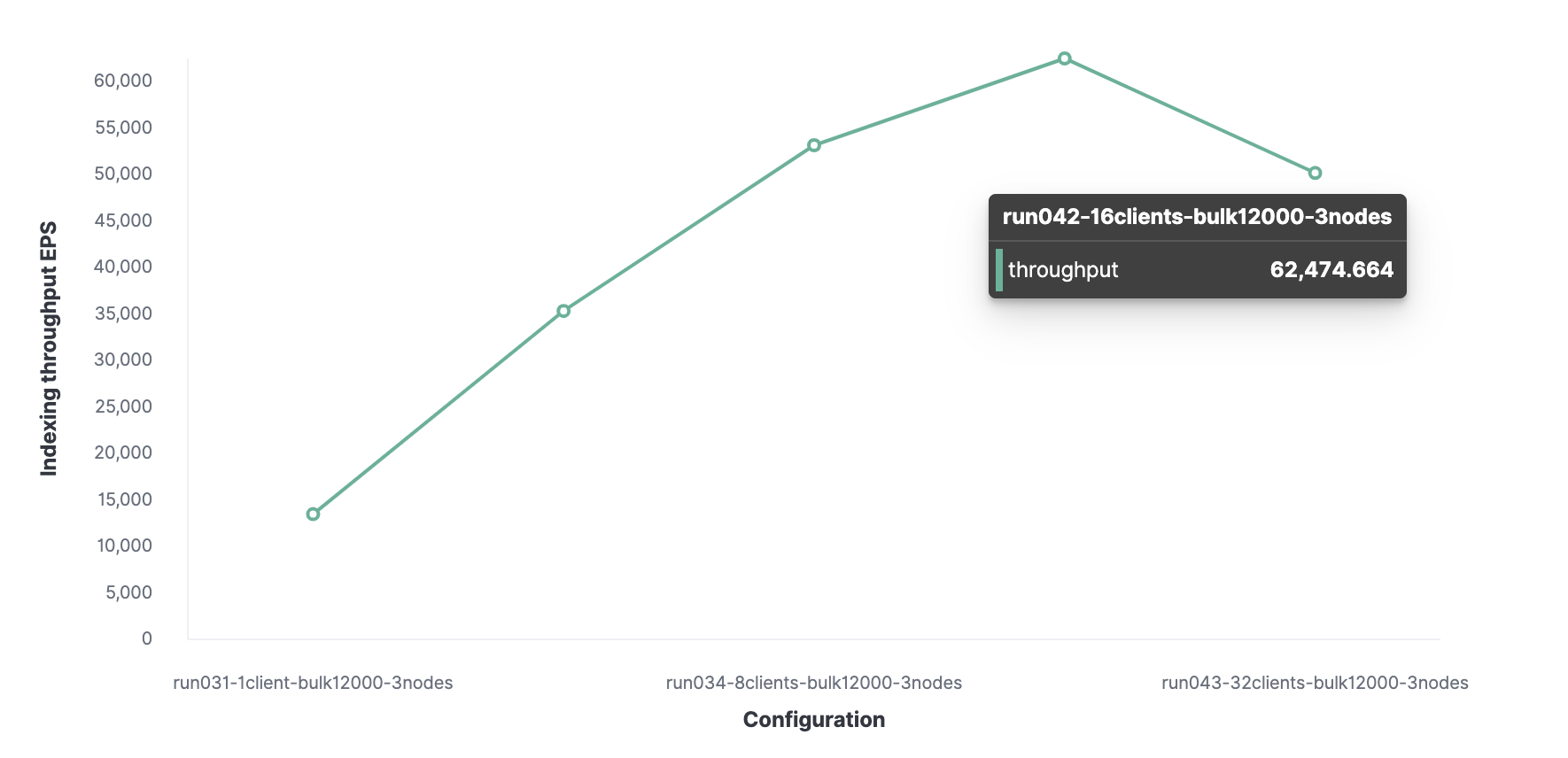
Ensuite, en utilisant une méthode similaire, 16 est le nombre optimal de clients pour atteindre 62 000 événements indexés par seconde.
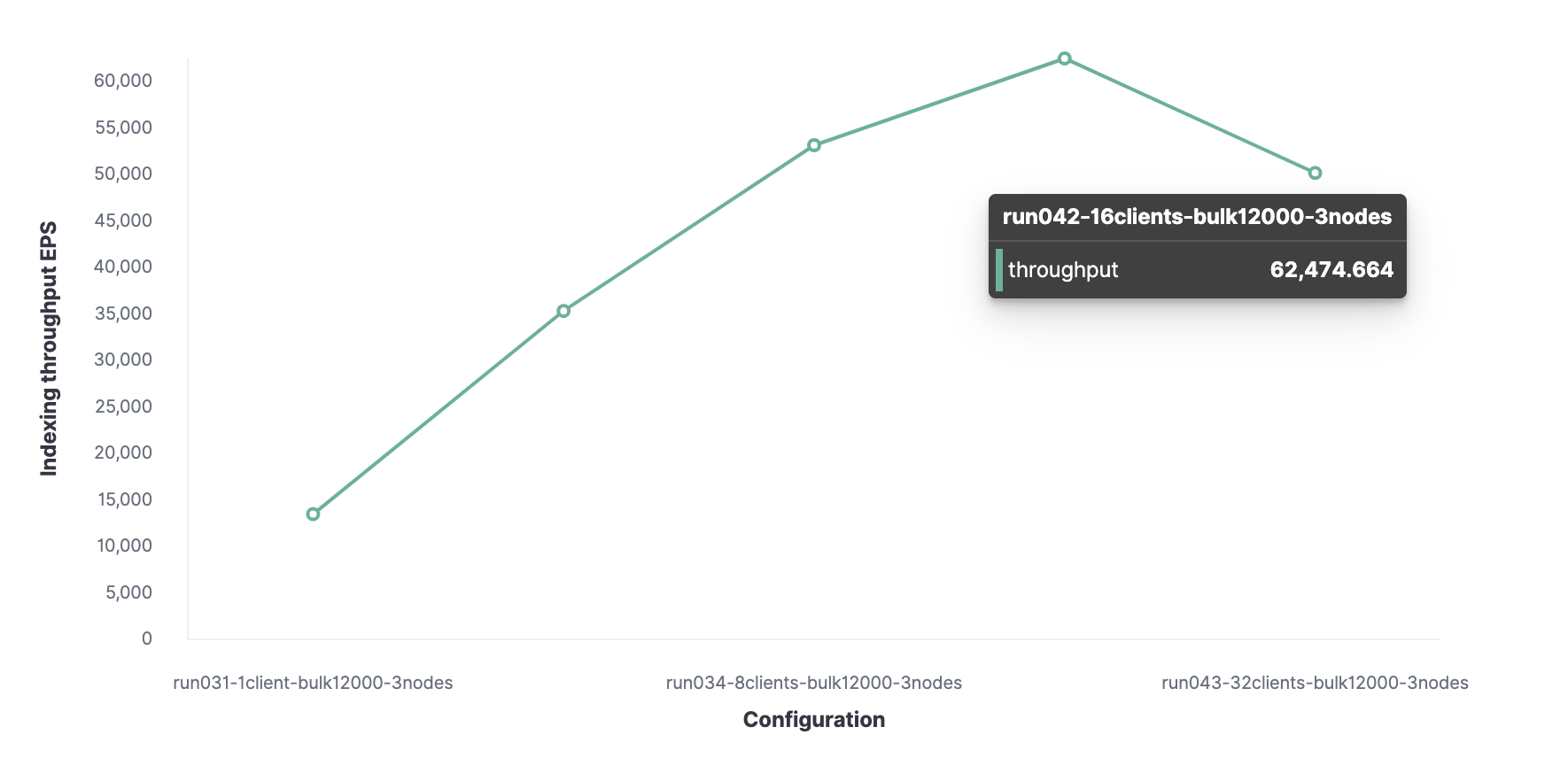
Au total, le cluster peut traiter un maximum de 62 000 événements par seconde sans sacrifier les performances. Pour augmenter ce nombre, vous devrez ajouter un nouveau nœud.
Ci-dessous, le même test avec un paquet de 12 000 événements, mais à titre de comparaison, les données de bande passante sont données pour 1 nœud, 2 et 3 nœuds.
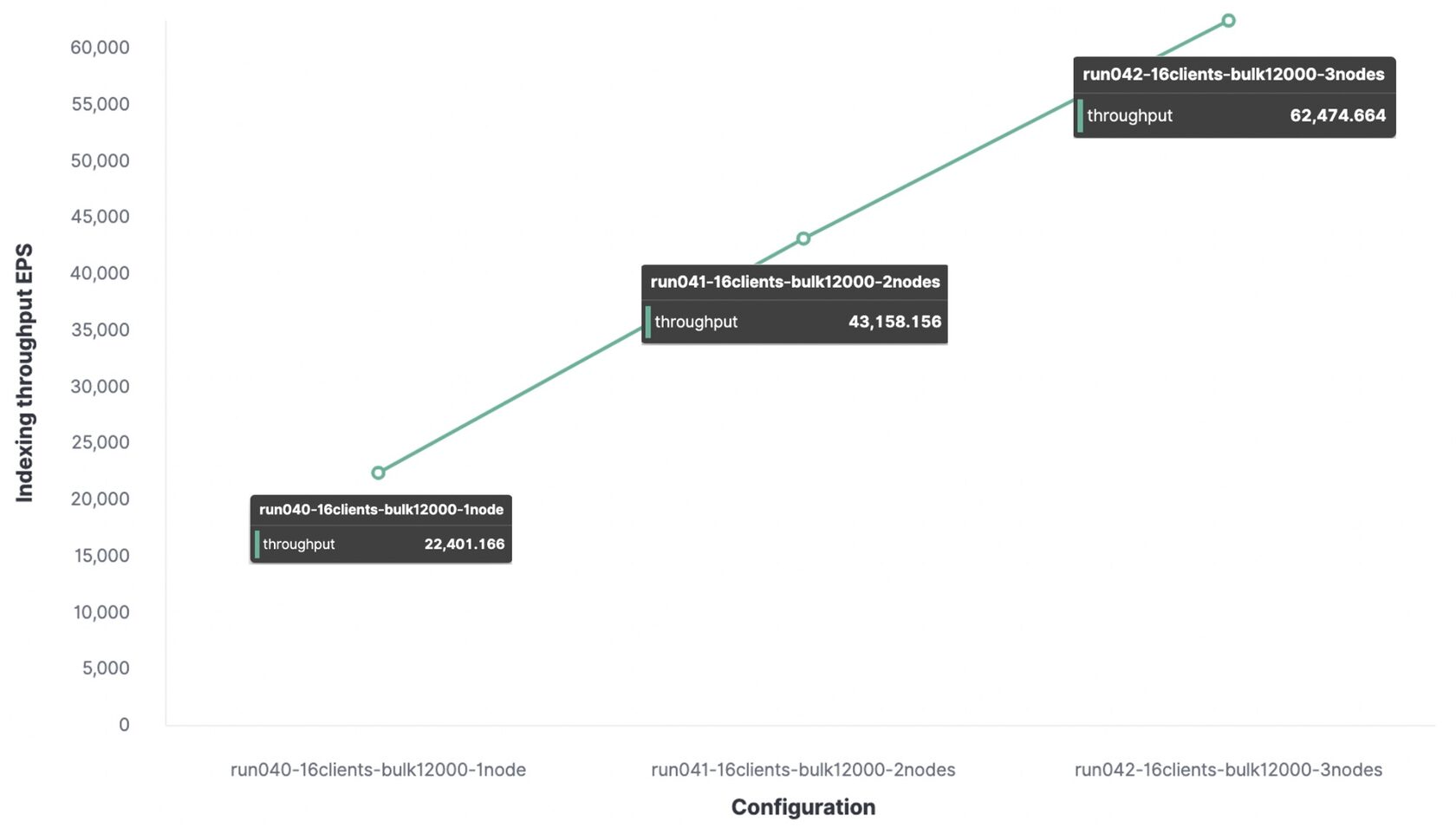
Pour un environnement de test, le débit d'indexation maximal sera:
- Avec 1 nœud et 1 fragment, 22 000 événements par seconde ont été indexés;
- Avec 2 nœuds et 2 fragments, 43 000 événements par seconde ont été indexés;
- Avec 3 nœuds et 3 fragments, 62 000 événements par seconde ont été indexés.
Toute demande d'index supplémentaire sera mise en file d'attente et lorsqu'elle sera pleine, le nœud répondra en rejetant la demande d'index.
Veuillez noter que l'ensemble de données affecte les performances du cluster, il est donc important d'exécuter des pistes de rallye avec vos propres données.
Test d'indexation n ° 2
Pour l'étape suivante, les pistes de données du journal du serveur HTTP avec la configuration suivante seront utilisées:
- 247 249 096 documents;
- Volume de données: 31,1 Go;
- Taille moyenne des documents: 0,8 Ko.
La taille optimale de l'emballage est de 16 000 documents.
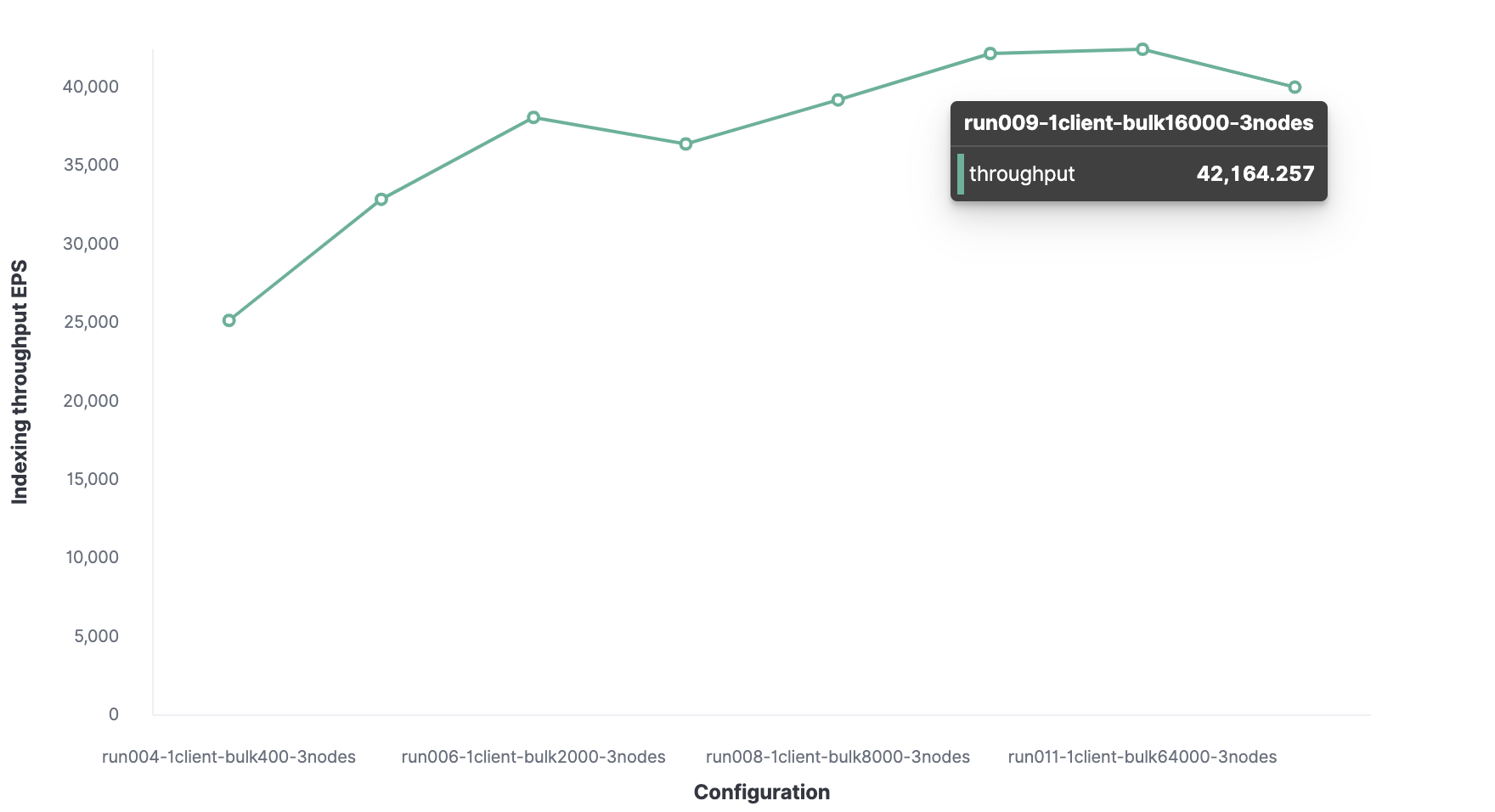
Le nombre optimal de clients est de 32. Par
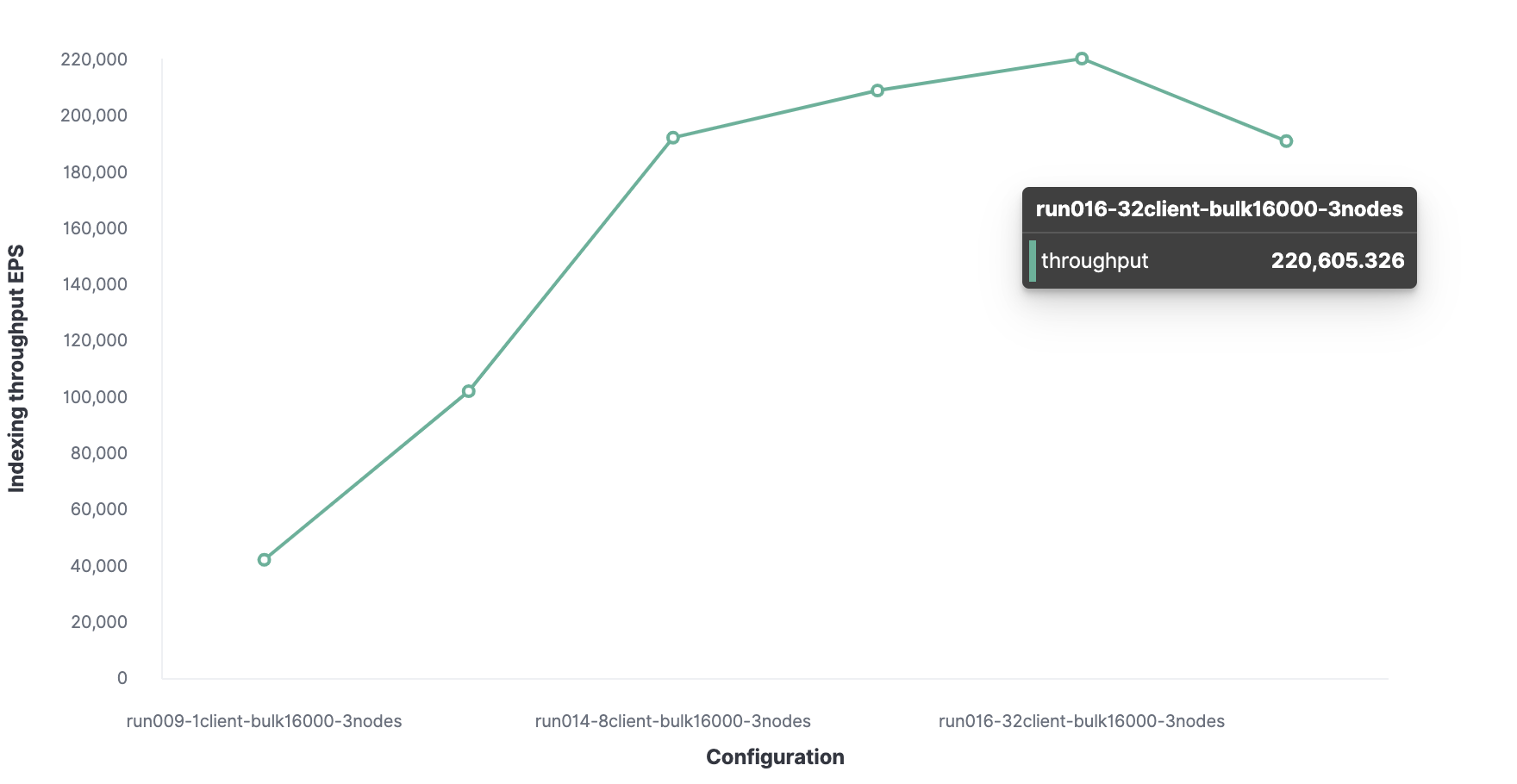
conséquent, le débit d'indexation maximal dans Elasticsearch est de 220 000 événements par seconde.
Chercher
Le débit de recherche sera estimé sur la base de 20 clients et de 1 000 opérations par seconde. Trois tests seront effectués pour la recherche.
Test de recherche n ° 1
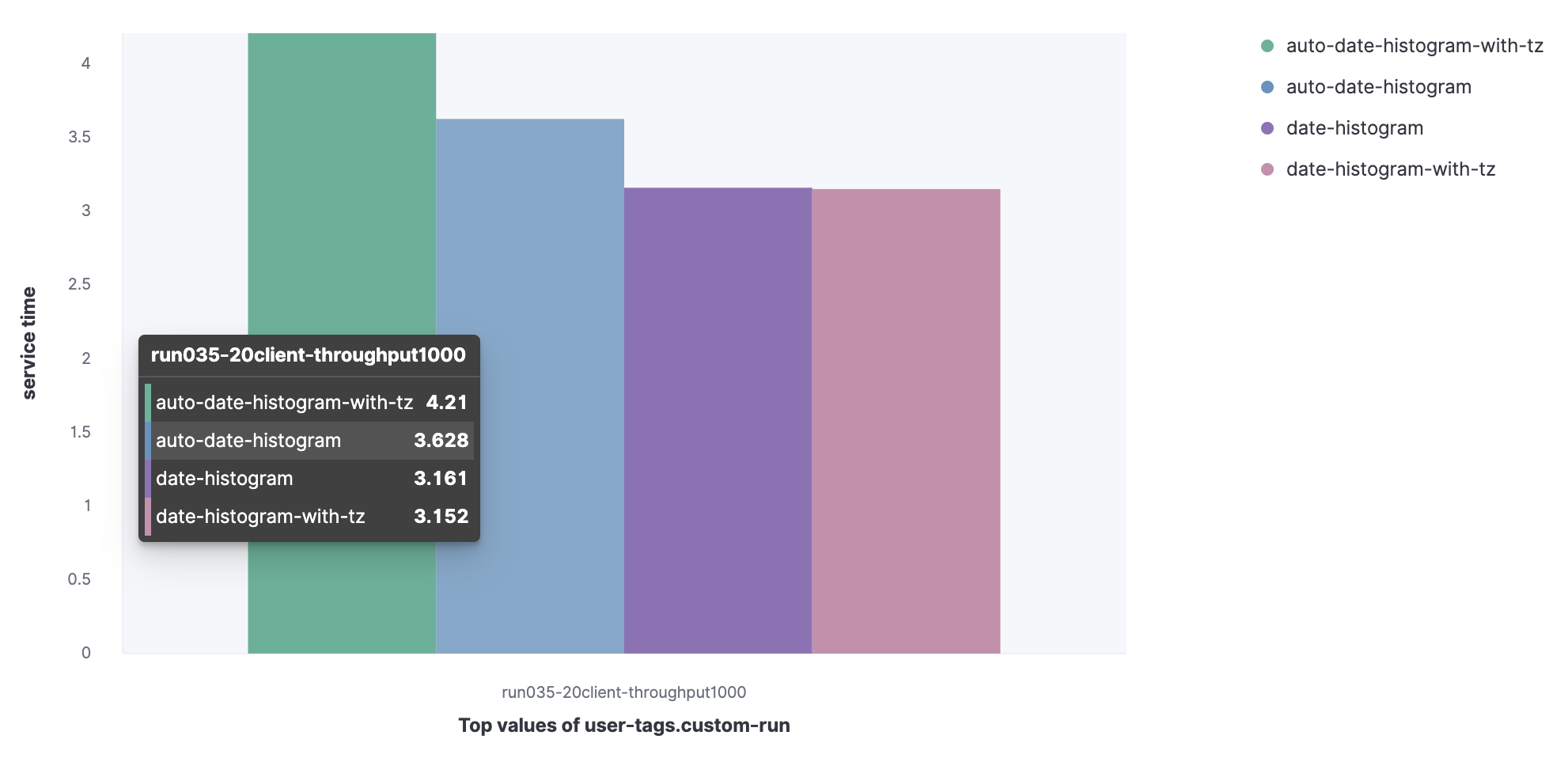
Compare le temps de service (ou plutôt le 90e centile) pour un ensemble de requêtes.
Ensemble de données de Metricbeat:
- Histogramme de date agrégé avec intervalle automatique (auto-date-historgram);
- Histogramme de date agrégé avec fuseau horaire avec intervalle automatique (auto-date-histogram-with-tz);
- Histogramme de date agrégé (histogramme de date);
- Histogramme de date agrégé avec fuseau horaire (date-histogram-with-tz).
Vous pouvez voir que la requête auto-date-histogram-with-tz a la durée de service la plus longue du cluster.
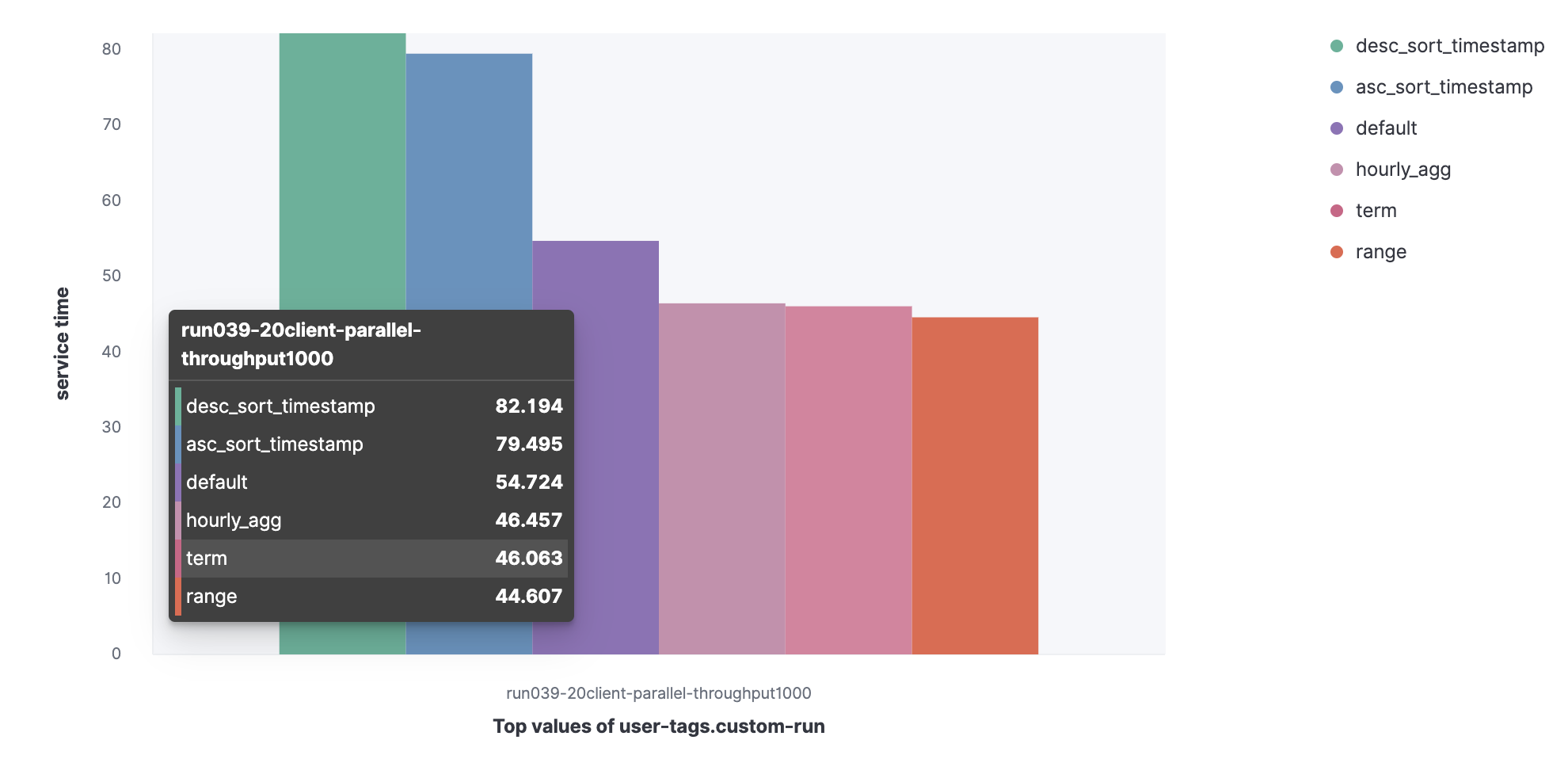
Ensemble de données du journal du serveur HTTP:
- Défaut;
- Terme;
- Varier;
- Hourly_agg;
- Desc_sort_timestamp;
- Asc_sort_timestamp.
Vous pouvez voir que les requêtes desc_sort_timestamp et desc_sort_timestamp ont une durée de vie plus longue.

Test de recherche n ° 2 Regardons
maintenant les requêtes parallèles. Voyons comment le temps de service du 90e centile augmente si les requêtes sont exécutées en parallèle.
Test de recherche n ° 3
Tenez compte de la vitesse d'indexation et du temps de service des requêtes de recherche en présence d'une indexation parallèle.
Exécutons une tâche d'indexation et de recherche parallèle pour voir la vitesse d'indexation et la durée du service de requête.

Voyons comment le temps de service de requête du 90e centile a augmenté lors de l'exécution de recherches en parallèle avec des opérations d'indexation.

Au total, avec 32 clients pour l'indexation et 20 utilisateurs pour la recherche:
- Le débit d'indexation est de 173 000 événements par seconde, ce qui est inférieur à 220 000 lors des expériences précédentes;
- La bande passante de recherche est de 1 000 événements par seconde.
Rally est un outil d'analyse comparative puissant, mais vous ne devez l'utiliser qu'avec des données qui seront également mises en production à l'avenir.
Quelques annonces:
Nous avons développé une formation sur les bases du travail avec Elastic Stack , qui est adaptée aux besoins spécifiques du client. Programme de formation détaillé sur demande.
Nous vous invitons à vous inscrire à l'Elastic Day en Russie et à la CIS 2021, qui se tiendra en ligne le 3 mars de 10 h à 13 h.
Lisez nos autres articles:
- Dimensionnement d'Elasticsearch
- Comment les licences Elastic Stack (Elasticsearch) sont-elles concédées et différentes?
- Comprendre l'apprentissage automatique dans la pile élastique (alias Elasticsearch, alias ELK)
- Élastique sous le verrou: activation des options de sécurité pour le cluster Elasticsearch pour un accès de l'intérieur et de l'extérieur
Si vous êtes intéressé par les services d'administration et de support pour votre installation Elasticsearch, vous pouvez laisser une demande dans le formulaire de commentaires sur une page spéciale.
Abonnez-vous à notre groupe Facebook et à notre chaîne Youtube .