Bonjour à tous. Nous continuons cette série d'articles sur ce que la science des données peut fournir pour prédire le COVID-19. Le premier article est ici . Aujourd'hui, nous allons parler de la deuxième classe de modèles pour prédire la dynamique de la propagation du COVID-19. Ils reposent sur des hypothèses d'augmentation de l'incidence et décrivent la situation à moyen et long terme. Nous parlons avec Nikolay Kobalo, ingénieur principal des données CFT.
Rappelons les conditions que nous avons:
Étant donné: des capacités colossales en science des données, trois spécialistes talentueux.
Trouvez: des moyens de prédire la propagation du COVID-19 une semaine à l'avance.
Passons à la deuxième solution.
- Kolya, bonjour. Dites-nous quel modèle vous avez utilisé pour résoudre ce problème.
- J'ai pris l'un des modèles qui, à mon avis, convient le mieux à l'occasion. Le modèle est présenté sous la forme d'une équation différentielle et comprend quatre fonctions:
1. Le nombre de personnes susceptibles d'être infectées par cette infection;
2. Le nombre de porteurs, c'est-à-dire de personnes déjà infectées, mais qui ne le savent pas encore;
3. Le nombre de malades qui infectent les autres;
4. Le nombre de récupérés.
Comme vous pouvez le voir, ce modèle ne prend pas en compte la mortalité par covid. Vous pouvez voir les détails du modèle sur mon github: https://github.com/rerf2010rerf/COVID-19-forecast/blob/master/public.ipynb
Le modèle s'appelle SEIR et appartient à une famille de modèles compartimentaux qui décrivent la propagation d'une épidémie. Les modèles de cette famille permettent de décrire différents types d'infections. Par exemple, ceux pour lesquels l'immunité est développée (ou, au contraire, n'est pas développée). Ou ceux qui ont (ou n'ont pas) une période d'incubation. Dans le cas du COVID-19, j'ai utilisé un modèle avec une période d'incubation et l'immunité qui a été produite chez les personnes qui avaient été malades.
Tous les modèles polygames sont des systèmes d'équations différentielles du premier ordre. Pour SEIR, ils ressemblent à ceci:

Ici:
S (t) - (Susceptible) - le nombre de personnes sensibles à l'infection.
E (t) - (Exposed) - le nombre de porteurs, c'est-à-dire les personnes infectées chez lesquelles la maladie ne s'est pas encore manifestée en raison de la période d'incubation.
I (t) - (infectieux) - infecté.
R (t) - (récupéré) - récupéré.
N = S + E + I + R - taille de la population. Il reste constant, c'est-à-dire on suppose que personne ne meurt de la maladie.
μ est le taux de mortalité naturelle.
α est l'inverse de la période d'incubation de la maladie.
γ est l'inverse du temps de récupération moyen.
β est le coefficient d'intensité des contacts menant à l'infection.
Le cycle de vie d'un individu dans le modèle SEIR ressemble à ceci:

Une personne en bonne santé, mais pas encore malade (sensible) peut être infectée par une personne infectée (infectieuse). La probabilité qu'une personne en bonne santé devienne infectée est décrite par le paramètre β.
Une personne infectée entre dans un état de porteur d'infection (exposée). Les porteurs sont des personnes chez qui la maladie ne s'est pas encore manifestée, c'est-à-dire qu'ils ont une période d'incubation. Les porteurs ne peuvent infecter personne. La transition des personnes sensibles à la maladie vers l'état de porteuses est décrite par les deux premières équations du modèle (en utilisant le terme β (I / N)).
Après 1 / α jours (période d'incubation) après l'infection, le porteur entre dans l'état infecté (infectieux).
Après 1 / γ jours (temps de récupération), la personne infectée entre dans l'état Récupéré. La personne rétablie développe une immunité et ne peut plus contracter cette infection.
Le modèle prévoit également la mortalité naturelle de la population dans la population. La mortalité dans le modèle SEIR est équilibrée par la fécondité, de sorte que la population totale ne change pas. Dans le même temps, le nombre de personnes rétablies dans la population diminuera, car les nouveau-nés n'auront pas d'immunité. En conséquence, le nombre de personnes qui se sont rétablies dans la population diminue avec le temps. Le taux de mortalité est décrit par le paramètre μ.
- Vous avez des coefficients dans le modèle. Alors, avez-vous fait des hypothèses?
- L'une de mes hypothèses était que la mortalité naturelle de la population peut être négligée, c'est-à-dire μ = 0. Cette hypothèse semble valable, puisque nous voulons prédire la propagation de l'infection sur une courte période de temps, seulement quelques mois.
De plus, le modèle choisi suppose que ceux qui se sont rétablis deviennent immunisés contre l'infection, c'est-à-dire qu'ils ne peuvent plus être infectés.
- Et c'est ainsi, au fait?
- Il semble que oui. Plusieurs réinfections ont déjà été enregistrées, mais le plus souvent cela ne se produit pas. Par conséquent, nous pouvons dire qu'il en est ainsi.
- Et quel est votre «facteur d'intensité de contact»?
«J'entends ici l'intensité avec laquelle les gens entrent en contact les uns avec les autres et sont infectés. En gros, c'est la probabilité que lorsque deux personnes se rencontrent, où l'une est infectée et l'autre non, la seconde finit par tomber malade.
- Combien ça coûte? Près d'un?
- Non, j'ai sélectionné ce paramètre en fonction des données. Cela dépend du niveau d'auto-isolement. Par exemple, si une grande partie de la population n'entre pas en contact avec d'autres personnes, le coefficient devient plus bas et si la population communique activement entre elles, elle augmente.
- D'accord. Avez-vous aussi un temps de récupération? Alpha et gamma?
- J'ai pris l'alpha égal à 1 / 5,1, c'était un paramètre connu du COVID-19 (le paramètre inverse de la période d'incubation en jours). Et j'ai sélectionné la gamme en fonction des données. C'est le "temps de convalescence". Soit dit en passant, «l'intensité des contacts» est également basée sur les données.
- Tant pis. Là encore, pouvez-vous nous dire quelles hypothèses sont formulées par les modèles? Que signifie chaque équation?
- La première équation décrit l'évolution du nombre de sujets sensibles à l'infection. En particulier, le troisième terme dit que plus les contacts entre les infectés et les sensibles sont intenses, plus le nombre de sensibles diminue rapidement. De plus, si quelqu'un a été infecté, puis est devenu infecté, il n'est plus inclus dans ce nombre. Au début de l'épidémie, il est égal au nombre de personnes dans la population.
Ensuite, le nombre de porteurs est déterminé parmi ceux susceptibles d'être infectés, c'est-à-dire qu'une personne communique avec une personne infectée, devient infectée et devient porteuse de l'infection. Ceci est décrit dans la deuxième équation. Il dit que le taux de croissance des porteurs est d'autant plus élevé que les contacts entre les sujets sensibles et les infectés sont intenses et, au contraire, moins il en reste pour le moment.
La troisième équation dit que le taux de croissance des personnes infectées est plus élevé, plus il y a de porteurs (qui se transforment en infectés), et moins, plus il y a déjà d'infectés.
La quatrième équation décrit le taux de croissance de ceux qui se sont rétablis, qui est le plus élevé, le plus infecté (qui peut guérir), et le moins, plus il y en a déjà.
- Cela ressemble à une description de l'évolution de la situation.
- En fait, il existe différents modèles. C'est le modèle SEIR, et il y a SIR, dans lequel il n'y a pas de risque d'infection. Il existe des modèles avec plus de paramètres. Il existe un modèle qui prévoit la mortalité par infection, mais je ne l'ai pas utilisé.
- Où avez-vous trouvé ce modèle?
- Googlé. Il y a un article sur Wikipedia. J'ai trouvé des articles supplémentaires.
- Vous avez également présenté les graphiques.
- Ce graphique est un exemple. Ce n'est pas basé sur des données réelles. Cela montre simplement comment le modèle se comporte. Elle prédit que tout le monde finira par tomber malade et se rétablira.

- D'accord, alors tu as tout pris, et puis quoi?
- J'ai pris les données disponibles par pays. Il a supposé que le taux de mortalité était nul. Réécriture des difours sous forme de différences finies:

En tant qu'opérateur de différences finies dans cette solution, une différence bilatérale est utilisée.
Le nombre de personnes R récupérées par jour est dans les données initiales, et le nombre de I infectés est égal au nombre de cas confirmés moins le nombre de guéris. Ainsi, à partir de la dernière équation, nous pouvons trouver γ en optimisant la fonction objectif MALE (ΔR-γI).
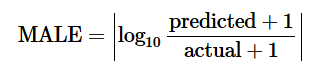
Afin de suivre comment les mesures de quarantaine affectent le développement de l'épidémie, j'ai un peu compliqué ma tâche et remplacé le coefficient β par la fonction β (t) - après tout, à mesure que la quarantaine est introduite dans le pays, le taux d'infection devrait diminuer, ce qui signifie que dans notre cas, β ne sera pas constant. Puisque nous avons déjà toutes les conditions initiales pour résoudre le difur, nous pouvons utiliser l'optimisation pour trouver la fonction β (t).
- C'est un jour de différence?
- Jour moins le jour précédent. J'ai branché les données et calculé les coefficients inconnus.
- Bêta et gamma?
- J'ai pris Alpha 5.1 jours. En conséquence, il était nécessaire de trouver bêta et gamma - l'intensité des contacts et le temps de récupération.
- Et que vous est-il arrivé?
- Il y a des graphiques. Chaque région et chaque pays se sont révélés différents. J'ai décidé pour chaque pays séparément. Sur la gauche se trouve un graphique de données (noir - c'était réel, rouge - infecté et récupéré, prédit par le modèle). Infecté + récupéré - il s'avère que E + R. Sur la droite se trouve le graphique du coefficient bêta. La bêta, au fait, est censée dépendre du temps. Ici, le plus grand saut de β coïncide avec l'heure de la quarantaine le 30 mars.
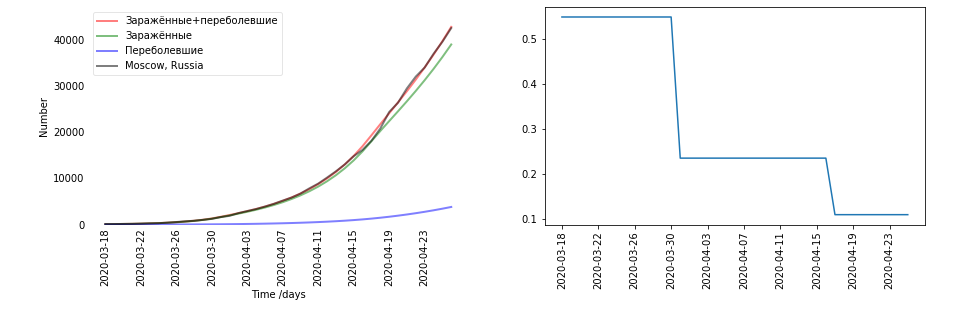
- Et vous l'avez compté selon les données ou supposé ainsi?
- Ceci est déjà calculé en fonction des données. C'est exactement le résultat de la formation à Moscou.
- Avez-vous défini vous-même les seuils de temps?
- Je pensais que la fonction avait une forme en deux étapes. Et optimisé. Je viens d'ajuster les données et de trouver les fonctions optimales qui correspondent le mieux. J'ai également essayé d'utiliser des fonctions avec un nombre d'échelons différent, mais celles en deux étapes ont donné de meilleurs résultats.
- Jetons un coup d'œil aux pays, par exemple, l'Italie. Eh bien, ici vous avez une image différente ...

- En Italie, la quarantaine, apparemment, fonctionnait mieux. Et il y a plus de gens qui ont été malades. Le modèle a confirmé que la quarantaine a été introduite le 9 mars.
- Qu'avez-vous choisi pour les prévisions finales?
- Pour la prévision finale, j'ai choisi une intensité constante de contacts et construit un modèle en utilisant les deux derniers points. Autrement dit, nous connaissons toute l'histoire précédente, mais nous ne prenons que les derniers points.
- C'est pour la prédiction de la semaine?
- Oui. Et ce qui s'est passé auparavant était de voir comment le modèle se comporte. Et puis j'ai déjà regardé quelle fonction est préférable de prendre et combien de points à étudier.
- Probablement, si vous vouliez faire des prévisions jusqu'à maintenant, vous auriez reçu une décision différente. Avez-vous quelque chose qui montrera comment la situation peut évoluer davantage?
- Oui. Mais ce n'est pas très intéressant là-bas. Elle a prédit que tout le monde à Moscou serait malade en septembre.
- Lors de l'une des rencontres, vous avez dit que selon vos prévisions, le pic aurait dû être en juillet. En fait, tout s'est passé un peu plus tôt. Que pensez-vous que le modèle n'a pas pris en compte?
- Probablement bêta. Peut-être que la quarantaine s'est intensifiée. Il est possible que l'intensité des contacts ait diminué en raison du fait que les personnes ont été malades, ne s'infectent pas et ne sont pas infectées. La bêta devrait en dépendre d'une manière ou d'une autre. Et ici, il n'est pas pris en compte.
- Eh bien, c'est-à-dire que vous dites que nous pouvons tout réguler avec une seule beta?
- Selon les données connues - oui, nous pouvons, avec bêta et gamma ajuster.
- Votre modèle prédit-il la prochaine vague?
- Non, tout est stable: ça pousse, ça pousse, ça pousse et tout le monde tombera malade. Bien qu'il y ait aussi un facteur de saisonnalité. Périodes d'automne, par exemple (lorsque la grippe, etc., le système immunitaire est affaibli). Mais le modèle ne tient pas compte de tout cela.
- Quels sont les avantages et les inconvénients de votre modèle?
- Au moment de la compilation du modèle, il y avait peu de données connues. Maintenant, la période de récupération et la période d'incubation sont déjà connues (alors 5.1 l'était, maintenant elle est mesurée avec plus de précision). Des pros: il montre le processus lui-même, comment il se déroule. Et si nous enquêtons plus en profondeur sur l'exemple d'autres pays, par exemple, l'Italie, l'Allemagne, comment ces bêtas ont influencé, alors il nous serait possible d'affiner ce modèle et de construire une prévision à long terme plus précise.
, data science – .
, , . - – , , , , .
, , . .Il a fait le modèle le plus cool;)