Cependant, écrire des programmes entièrement en langage assembleur n'est pas seulement long, morne et difficile, mais aussi quelque peu idiot - car des abstractions de haut niveau ont été inventées à cette fin, pour réduire le temps de développement et simplifier le processus de programmation. Par conséquent, le plus souvent, les fonctions bien optimisées prises séparément sont écrites en langage d'assemblage, qui sont ensuite appelées à partir de langages de niveau supérieur tels que C ++ et C #.
Sur cette base, l'environnement de programmation le plus pratique sera Visual Studio, qui inclut déjà MASM. Vous pouvez le connecter à un projet C / C ++ via le menu contextuel du projet Build Dependencies - Build Customizations ..., en cochant la case à côté de masm, et les programmes assembleurs eux-mêmes seront situés dans des fichiers avec le .asm extension (dans les propriétés dont le type d'élément doit être défini sur Microsoft Macro Assembler). Cela permettra non seulement de compiler et d'appeler des programmes en langage assembleur sans gestes inutiles - mais aussi d'effectuer un débogage de bout en bout, "tomber" dans la source assembleur directement à partir de c ++ ou c # (y compris le point d'arrêt à l'intérieur de la liste de l'assembly) , ainsi que le suivi de l'état des registres avec les variables habituelles dans la fenêtre de surveillance.
Mise en évidence de la syntaxe
Visual Studio n'a pas de coloration syntaxique intégrée pour l'assembleur et d'autres réalisations de la structure IDE moderne; mais il peut être fourni avec des extensions tierces.
AsmHighlighter est historiquement le premier avec des fonctionnalités minimales et un jeu de commandes incomplet - non seulement AVX manque, mais aussi certains des standards, en particulier fsqrt. Ce fait m'a incité à écrire ma propre extension -
ASM Advanced Editor . En plus de mettre en évidence et de réduire les sections de code (en utilisant les commentaires "; [", "; [+" et ";]"), il lie les indices aux registres qui apparaissent en survolant le code (également via des commentaires). Cela ressemble à ceci:
;rdx=
ou comme ça:
mov rcx, 8;=
Des conseils pour les commandes sont également présents, mais plutôt sous une forme expérimentale - il s'est avéré qu'il faudra plus de temps pour les remplir complètement que pour écrire l'extension elle-même.
Il s'est également avéré soudain que les boutons habituels pour annoter / commenter la section en surbrillance du code ont cessé de fonctionner. Par conséquent, j'ai dû écrire une autre extension dans laquelle cette fonctionnalité était accrochée au même bouton, et la nécessité de telle ou telle action est automatiquement sélectionnée.
Asm mec- est venu un peu plus tard. Dans ce document, l'auteur est allé dans l'autre sens et a concentré ses efforts sur la référence de commande intégrée et l'auto-complétion, y compris les balises de suivi. Le pliage de code y est également présent (selon "#region / #end region"), mais il ne semble pas encore y avoir de liaison des commentaires aux registres.
32 contre 64
Depuis l'apparition de la plate-forme 64 bits, il est devenu la norme d'écrire 2 versions d'applications. Il est temps d'arrêter ça! Combien d'héritage pouvez-vous tirer. Il en va de même pour les extensions - vous ne pouvez trouver un processeur sans SSE2 que dans un musée - d'ailleurs, sans SSE2, les applications 64 bits ne fonctionneront pas. Il n'y aura aucun plaisir de programmation si vous écrivez 4 variantes de fonctions optimisées pour chaque plateforme.
L'avantage de la plate-forme 64 bits n'est pas du tout dans les registres «larges» - mais dans le fait que le nombre de ces registres a doublé - 16 pièces chacun, à la fois polyvalents et XMM / YMM. Cela simplifie non seulement la programmation, mais réduit également considérablement les accès à la mémoire.
FPU
Si auparavant il n'y avait nulle part sans FPU, tk. les fonctions avec des nombres réels ont laissé le résultat en haut de la pile, puis sur une plate-forme 64 bits l'échange a lieu sans sa participation en utilisant les registres xmm de l'extension SSE2. Intel recommande également activement d'abandonner les FPU au profit de SSE2 dans ses directives. Cependant, il y a une mise en garde: FPU vous permet d'effectuer des calculs avec une précision de 80 bits - ce qui dans certains cas peut être critique. Par conséquent, le support FPU n'est allé nulle part et cela ne vaut certainement pas la peine de le considérer comme une technologie obsolète. Par exemple, le calcul de l'hypoténuse peut se faire "de front" sans crainte de débordement,
à savoir
fld x fmul st(0), st(0) fld y fmul st(0), st(0) faddp st(1), st(0) fsqrt fstp hypot
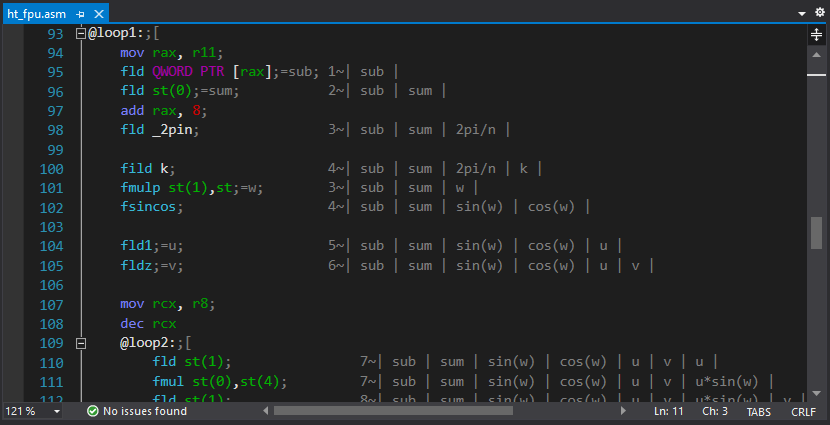
La principale difficulté dans la programmation de FPU est son organisation de pile. Pour simplifier, un petit utilitaire a été écrit qui génère automatiquement des commentaires avec l'état actuel de la pile (il était prévu d'ajouter des fonctionnalités similaires directement à l'extension principale pour la coloration syntaxique - mais nous n'y sommes jamais parvenus)
Exemple d'optimisation: transformée de Hartley
Les compilateurs C ++ modernes sont suffisamment intelligents pour vectoriser automatiquement le code pour des tâches simples telles que la somme de nombres dans un tableau ou la rotation de vecteurs, en reconnaissant les modèles correspondants dans le code. Par conséquent, obtenir un gain de performances significatif sur les tâches primitives n'est pas quelque chose qui ne fonctionnera pas - au contraire, il se peut que votre programme super optimisé s'exécute plus lentement que ce que le compilateur a généré. Mais vous ne devriez pas non plus en tirer des conclusions profondes - dès que les algorithmes deviennent un peu plus compliqués et pas évidents pour l'optimisation, toute la magie de l'optimisation des compilateurs disparaît. Il est toujours possible d'obtenir une performance décuplée grâce à l'optimisation manuelle en 2021.
Donc, comme tâche, nous prenons l'algorithme (lent) Hartley transforme :
le code
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (Math.Cos(w) + Math.Sin(w));
}
result[i] = sum / Math.Sqrt(n);
}
}
C'est aussi assez trivial pour la vectorisation automatique (nous verrons plus tard), mais cela laisse un peu plus de place à l'optimisation. Eh bien, notre version optimisée ressemblera à ceci:
code (commentaires supprimés)
ht_asm PROC local sqrtn:REAL10 local _2pin:REAL10 local k:DWORD local n:DWORD and r8, 0ffffffffh mov n, r8d mov r11, rcx xor rcx, rcx mov r9, r8 dec r9 shr r9, 1 mov r10, r8 sub r10, 2 shl r10, 3 finit fld _2pi fild n fdivp st(1), st fstp _2pin fld1 fild n fsqrt fdivp st(1), st ; mov rax, r11 mov rcx, r8 fldz @loop0: fadd QWORD PTR [rax] add rax, 8 loop @loop0 fmul st, st(1) fstp QWORD PTR [rdx] fstp sqrtn add rdx, 8 mov k, 1 @loop1: mov rax, r11 fld QWORD PTR [rax] fld st(0) add rax, 8 fld _2pin fild k fmulp st(1),st fsincos fld1;=u fldz;=v mov rcx, r8 dec rcx @loop2: fld st(1) fmul st(0),st(4) fld st(1) fmul st,st(4) faddp st(1),st fxch st(1) fmul st, st(4) fxch st(2) fmul st,st(3) fsubrp st(2),st fld st(0) fadd st, st(2) fmul QWORD PTR [rax] faddp st(5), st fld st(0) fsubr st, st(2) fmul QWORD PTR [rax] faddp st(6), st add rax, 8 loop @loop2 fcompp fcompp fld sqrtn fmul st(1), st fxch st(1) fstp QWORD PTR [rdx] fmulp st(1), st fstp QWORD PTR [rdx+r10] add rdx,8 sub r10, 16 inc k dec r9 jnz @loop1 test r10, r10 jnz @exit mov rax, r11 fldz mov rcx, r8 shr rcx, 1 @loop3:;[ fadd QWORD PTR [rax] fsub QWORD PTR [rax+8] add rax, 16 loop @loop3;] fld sqrtn fmulp st(1), st fstp QWORD PTR [rdx] @exit: ret ht_asm ENDP
Attention: il n'y a pas de déroulement de boucle, pas de SSE / AVX, pas de tables cosinus, pas de réduction de complexité grâce à l'algorithme de transformation "rapide". La seule optimisation explicite est le calcul itératif sinus / cosinus dans la boucle interne de l'algorithme directement dans les registres FPU.
Puisque nous parlons d'une transformation intégrale, en plus de la vitesse, nous nous intéressons également à la précision du calcul et au niveau d'erreurs accumulées. Dans ce cas, il est très simple de le calculer - en faisant deux transformations d'affilée, nous devrions obtenir (en théorie) les données initiales. En pratique, ils seront légèrement différents, et il sera possible de calculer l'erreur à travers l'écart type du résultat obtenu par rapport au résultat analytique.
Les résultats de l'auto-optimisation d'un programme C ++ peuvent également dépendre grandement des réglages des paramètres du compilateur et du choix d'un jeu d'instructions étendu valide (SSE / AVX / etc). Cependant, il y a deux nuances:
- Les compilateurs modernes ont tendance à calculer tout ce qui est possible au stade de la compilation - par conséquent, il est tout à fait possible dans le code compilé, au lieu de l'algorithme, de voir une valeur précalculée, qui, lors de la mesure des performances, donnera au compilateur un avantage de 100500 fois. Pour éviter cela, mes mesures utilisent la fonction externe zero (), qui ajoute de l'ambiguïté aux paramètres d'entrée.
- « AVX» — , AVX. . – , AVX .
Le paramètre d'optimisation le plus intéressant est le modèle à virgule flottante, qui prend des valeurs Precise | Strict | Fast. Dans le cas de Fast, le compilateur est autorisé à faire toutes les transformations mathématiques à sa discrétion (y compris les calculs itératifs) - en fait, c'est seulement dans ce mode que la vectorisation automatique se produit.
Donc, compilateur Visual Studio 2019, framework cible AVX2, modèle à virgule flottante = précis. Pour le rendre encore plus intéressant, il mesurera à partir d'un projet c # sur un tableau de 10000 éléments:
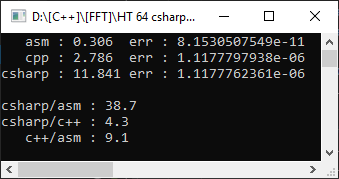
C #, comme prévu, s'est avéré plus lent que C ++, et la fonction assembleur s'est avérée 9 fois plus rapide! Cependant, il est trop tôt pour se réjouir - définissons le modèle à virgule flottante = Rapide:

Comme vous pouvez le voir, cela a contribué à accélérer considérablement le code et le décalage par rapport à l'optimisation manuelle n'a été que de 1,8 fois. Mais ce qui n'a pas changé, c'est l'erreur. Que l'autre option a donné une erreur de 4 chiffres significatifs - et c'est important dans les calculs mathématiques.
Dans ce cas, notre version s'est avérée à la fois plus rapide et plus précise. Mais ce n'est pas toujours le cas - et en choisissant FPU pour stocker les résultats, nous perdrons inévitablement dans la possibilité d'une optimisation par vectorisation. De plus, personne n'interdit de combiner FPU et SSE2 dans les cas où cela a du sens (en particulier, j'ai utilisé cette approche dans la mise en œuvre de l' arithmétique double-double , ayant reçu une accélération de 10 fois lors de la multiplication).
Une optimisation supplémentaire de la transformée de Hartley se situe dans un plan différent et (pour une taille arbitraire) nécessite l'algorithme Bluestein, qui est également essentiel à la précision des calculs intermédiaires. Eh bien, ce projet peut être téléchargé sur GitHub , et en prime, il existe également quelques fonctions pour sommer / mettre à l'échelle des tableaux pour FPU / SSE2 / AVX (à des fins éducatives).
Que lire
Littérature sur l'assembleur en vrac. Mais il existe plusieurs sources clés:
1. Documentation officielle d'Intel . Rien de superflu, la probabilité de fautes de frappe est minime (qui sont omniprésentes dans la littérature imprimée).
2. Annuaire en ligne , extrait de la documentation officielle.
3. Site d'Agner Fogh , expert en optimisation reconnu. Contient également des exemples de code C ++ optimisé utilisant des éléments intrinsèques.
4. SIMPLEMENT FPU .
5.40 Pratiques de base dans la programmation en langage d'assemblage .
6. Tout ce que vous devez savoir pour commencer à programmer pour les versions 64 bits de Windows .
Annexe: Pourquoi ne pas simplement utiliser Intrinsics?
Texte masqué
, , , - — , SIMD- . — .
:
:
- . DOS , – .
- . – .
- . , , (FPU). . , //etc.
- - – , , . , , .
- , C++ , - SIMD-. 32- XMM8 XMM0 / XMM7 – . — , , , . – , C++.
- , . , – Microsoft , C++.