L'article s'adresse aux débutants comme moi.
Début
Examinons d'abord le problème. J'ai pris un site d'information peu connu sur Israël, puisque je vis moi-même dans ce pays, et je veux lire des nouvelles sans publicité et sans nouvelles intéressantes. Et donc, il y a un site où des nouvelles sont publiées: il y a des nouvelles marquées en rouge, et il y en a des ordinaires. Ceux qui sont ordinaires n'ont rien d'intéressant, et ceux marqués en rouge sont le jus même. Considérez notre site.
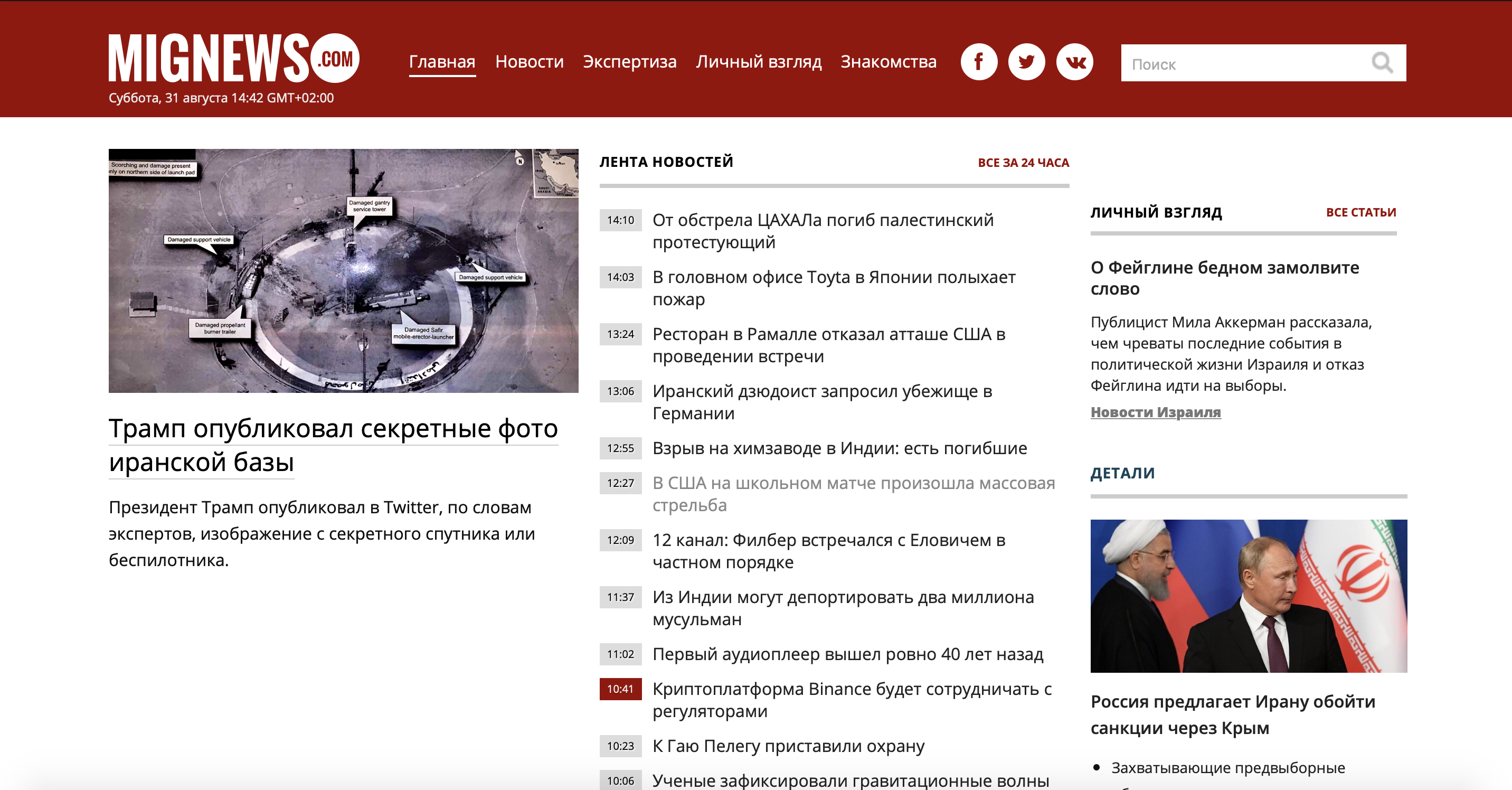
Comme vous pouvez le voir, le site est assez grand et il y a beaucoup d'informations inutiles, mais nous n'avons besoin que du conteneur de news. Utilisons la version mobile du site
pour nous épargner le même temps et les mêmes efforts.

Comme vous pouvez le voir, le serveur nous a donné un beau conteneur de nouvelles (qui, soit dit en passant, est plus que sur le site principal, ce qui est en notre faveur) sans publicités et déchets.
Jetons un coup d'œil au code source pour comprendre ce à quoi nous avons affaire.

Comme vous pouvez le voir, chaque actualité se trouve séparément dans la balise «a» et a la classe «lenta». Si nous ouvrons la balise 'a', nous remarquerons qu'à l'intérieur il y a une balise 'span', qui contient la classe 'time2' ou 'time2 time3', ainsi que l'heure de publication, et après avoir fermé la balise, nous voyons le texte des nouvelles lui-même.
Qu'est-ce qui sépare les nouvelles importantes des nouvelles sans importance? La même classe «time2» ou «time2 time3». Les nouvelles marquées «time2 time3» sont nos nouvelles rouges. Puisque l'essence de la tâche est claire, passons à la pratique.
S'entraîner
Pour travailler avec des analyseurs, des gens intelligents ont créé la bibliothèque "BeautifulSoup4", qui a beaucoup plus de fonctions intéressantes et utiles, mais plus à ce sujet la prochaine fois. Nous avons également besoin de la bibliothèque Requests qui nous permet d'envoyer diverses requêtes http. Nous allons les télécharger.
(assurez-vous d'avoir la dernière version de pip)
pip install beautifulsoup4
pip install requests
Allez dans l'éditeur de code et importez nos bibliothèques:
from bs4 import BeautifulSoup
import requests
Tout d'abord, sauvegardons notre URL dans une variable:
url = 'http://mignews.com/mobile'
Maintenant, envoyons une requête GET () au site et sauvegardons les données reçues dans la variable 'page':
page = requests.get(url)
Vérifions la connexion:
print(page.status_code)
Le code nous a renvoyé le code d'état «200», ce qui signifie que nous sommes connectés avec succès et que tout est en ordre.
Créons maintenant deux listes (je vous expliquerai à quoi elles servent plus tard):
new_news = [] news = []
Il est temps d'utiliser BeautifulSoup4 et de le nourrir de notre page, en indiquant entre guillemets comment cela nous aidera 'html.parcer':
soup = BeautifulSoup(page.text, "html.parser")
Si vous lui demandez de montrer ce qu'il a sauvé là-bas:
print(soup)
Nous allons sortir tout le code html de notre page.
Utilisons maintenant la fonction de recherche dans BeautifulSoup4:
news = soup.findAll('a', class_='lenta')
Regardons de plus près ce que nous avons écrit ici.
Dans la liste 'news' créée précédemment (à laquelle j'ai promis de revenir), enregistrez tout avec la balise 'a' et la classe 'news'. Si nous demandons de sortir sur la console tout ce qu'il a trouvé, cela nous montrera toutes les nouvelles qui étaient sur la page:

Comme vous pouvez le voir, avec le texte des nouvelles, les balises 'a', 'span', les classes ' lenta 'et' time2 ', et aussi' time2 time3 ', en général, tout ce qu'il a trouvé selon nos souhaits.
Nous allons continuer:
for i in range(len(news)):
if news[i].find('span', class_='time2 time3') is not None:
new_news.append(news[i].text)
Ici, dans une boucle for, nous parcourons toute notre liste d'actualités. Si dans les news sous l'index [i] nous trouvons la balise 'span' et la classe 'time2 time3', alors nous sauvegardons le texte de cette news dans la nouvelle liste 'new_news'.
Notez que nous utilisons «.text» pour reformater les lignes de notre liste à partir du «bs4.element.ResultSet» que BeautifulSoup utilise pour ses recherches en texte brut.
Une fois que je suis resté coincé sur ce problème pendant une longue période en raison d'un malentendu sur le fonctionnement des formats de données et de ne pas savoir comment utiliser le débogage, soyez prudent. Ainsi, nous pouvons maintenant enregistrer ces données dans une nouvelle liste et utiliser toutes les méthodes des listes, car maintenant c'est du texte ordinaire et, en général, en faire ce que nous voulons.
Affichons nos données:
for i in range(len(new_news)):
print(new_news[i])
Voici ce que nous obtenons:

nous obtenons l'heure de publication et seulement des nouvelles intéressantes.
Ensuite, vous pouvez créer un bot dans le panier et y télécharger ces nouvelles, ou créer un widget sur votre bureau avec les nouvelles actuelles. En général, vous pouvez trouver un moyen pratique de vous renseigner sur les actualités.
Espérons que cet article aidera les débutants à comprendre ce qui peut être fait avec les analyseurs et les aidera à progresser un peu dans leur apprentissage.
Merci pour votre attention, j'étais heureux de partager mon expérience.