Bonjour à tous. Nous entrons dans la dernière ligne droite: aujourd'hui est le dernier article sur ce que la science des données peut fournir pour prédire le COVID-19.
Le premier article est ici . Le second est là .
Aujourd'hui, nous discutons avec Alexander Zhelubenkov de ses décisions de prédire la propagation du COVID-19.
Nos conditions sont les suivantes:
Étant donné : des capacités colossales en science des données, trois spécialistes talentueux.
Trouvez : des moyens de prédire la propagation du COVID-19 une semaine à l'avance.
Et voici la décision d'Alexandre Zhelubenkov
- Alexandre, bonjour. Tout d'abord, parlez-nous un peu de vous et de votre travail.
- Je travaille chez Lamoda en tant que responsable du groupe d'analyse de données et d'apprentissage automatique. Nous sommes engagés dans un moteur de recherche et des algorithmes pour classer les produits dans le catalogue. La science des données m'a intéressé lorsque j'étudiais à l'Université d'État de Moscou à la Faculté de mathématiques computationnelles et de cybernétique.
- Les connaissances et les compétences ont été utiles. Vous avez réalisé un modèle de qualité: assez simple pour ne pas être suréquipé. Comment avez-vous réussi à y parvenir?
- Le problème de la prévision des séries chronologiques est bien étudié et les approches qui peuvent lui être appliquées sont compréhensibles. Dans notre tâche, les échantillons sont assez petits par rapport aux normes de l'apprentissage automatique - plusieurs milliers d'observations dans les données d'entraînement et seulement 560 prédictions doivent être faites pour chaque semaine (prévisions pour 80 régions pour chaque jour de la semaine prochaine). Dans de tels cas, des modèles plus grossiers sont utilisés qui fonctionnent bien dans la pratique. En fait, je me suis retrouvé avec une base de référence soignée.
En tant que modèle, j'ai utilisé le boosting de gradient sur les arbres. Vous remarquerez peut-être que les modèles en bois prêts à l'emploi ne savent pas comment prédire les tendances, mais si nous passons à des cibles incrémentielles, il sera alors possible de prédire la tendance. Il s'avère que vous devez apprendre au modèle à prédire dans quelle mesure le nombre de cas augmentera par rapport au jour en cours au cours des X prochains jours, où X de 1 à 7 est l'horizon de prévision.
Une autre caractéristique était que la qualité des prédictions du modèle était évaluée sur une échelle logarithmique, c'est-à-dire que la pénalité n'était pas le fait que vous vous trompiez, mais le nombre de fois où les prédictions du modèle se sont révélées inexactes. Et cela a eu l'effet suivant: la qualité finale des prévisions pour toutes les régions était fortement influencée par l'exactitude des prévisions dans les petites régions.
Les délais pour chaque région étaient connus: le nombre de cas dans chacun des jours du passé et littéralement quelques caractéristiques qualitatives, telles que la population et la proportion de résidents urbains. En gros, c'est tout. Il est difficile de recycler de telles données s'il est normal de faire la validation et de déterminer où il vaut la peine de s'arrêter dans la formation du boosting.
- Quelle bibliothèque d'amplification de dégradé avez-vous utilisée?
- Je suis à l'ancienne - XGBoost. Je connais LightGBM et CatBoost, mais pour une telle tâche, il me semble que le choix n'est pas si important.
- D'accord. Mais toujours la cible. Qu'as-tu pris pour la cible? Est-ce le logarithme de la relation de deux jours ou le logarithme de la valeur absolue?
- Comme cible, j'ai pris la différence dans les logarithmes du nombre de cas. Par exemple, si aujourd'hui il y avait 100 cas, et demain il y en a 200, alors lors de la prévision un jour à l'avance, vous devez apprendre à prédire le logarithme d'une croissance double.
En général, on sait que les premières semaines, il y a une augmentation exponentielle de la propagation du virus. Cela signifie que si nous utilisons des incréments sur une échelle logarithmique comme cibles, il sera en fait possible de prédire une constante multipliée par l'horizon de prévision chaque jour. L'amplification de dégradés est un modèle polyvalent et s'adapte bien à de telles tâches.
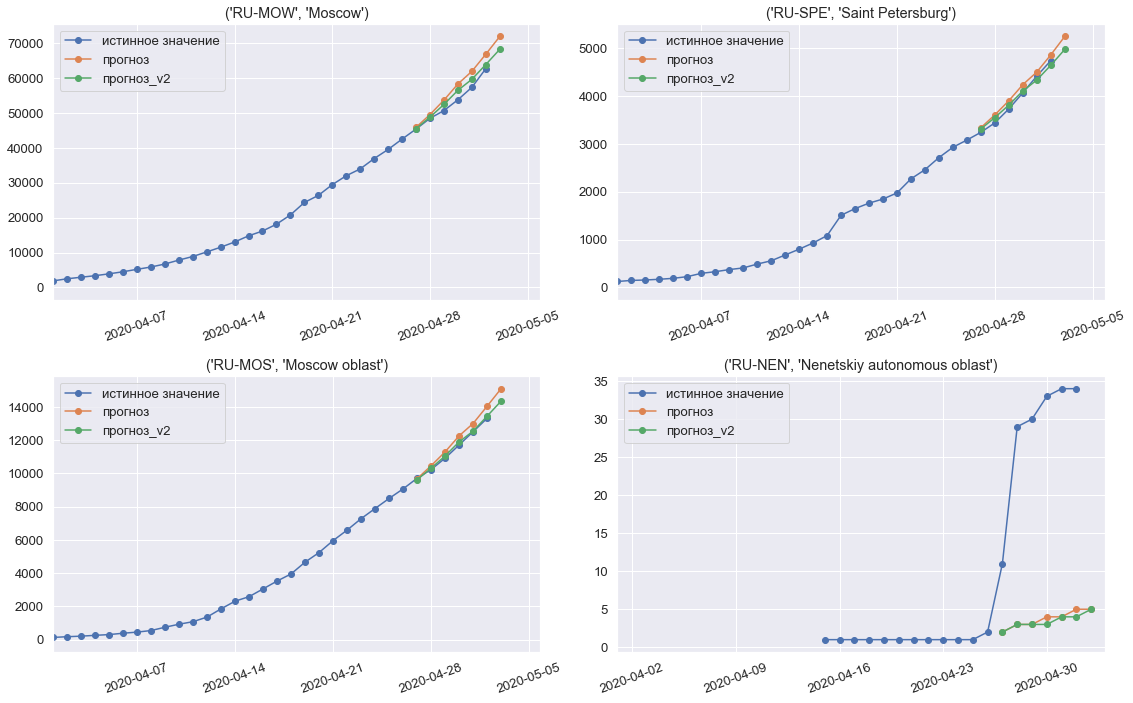
Prédictions de modèle pour la troisième et dernière semaine de la compétition
- Quel échantillon d'entraînement avez-vous pris?
- Pour prédire les régions, j'ai pris des informations sur la répartition par pays. Il semble que cela ait aidé, car quelque part déjà la forte croissance ralentissait, et les pays ont commencé à entrer sur le plateau. Dans les régions de Russie, j'ai coupé la période initiale, quand il y avait des cas isolés. Pour la formation, j'ai utilisé les données de février.
- Comment êtes-vous validé?
- Validé dans le temps, comme pour les séries chronologiques et il est d'usage de le faire. J'ai utilisé les deux dernières semaines pour le test. Si nous prédisons la semaine dernière, alors pour l'entraînement, nous utilisons toutes les données qui la précèdent. Si nous prédisons l'avant-dernière, nous utilisons toutes les données, sans les deux dernières semaines.
- Avez-vous utilisé autre chose? Certains jours, 10e ou 20e jour, c'est-à-dire à partir de là?
- Les principaux facteurs importants étaient des statistiques différentes: moyennes, médianes, augmentations au cours des N derniers jours. Pour chaque région, il peut être calculé séparément. Vous pouvez également ajouter les mêmes facteurs ensemble séparément, calculés uniquement pour toutes les régions à la fois.
- Question sur la validation. Cherchez-vous davantage la stabilité ou la précision? Quel était le critère?
- J'ai regardé la qualité moyenne du modèle, qui a été obtenue au cours des deux dernières semaines sélectionnées pour validation. Lors de l'ajout de certains facteurs, nous avons obtenu une image telle qu'avec une configuration d'amplification fixe et ne faisant varier que le paramètre de départ aléatoire, la qualité des prédictions pouvait beaucoup sauter - c'est-à-dire qu'une grande variance était obtenue. Afin de ne pas me recycler et d'obtenir un modèle plus stable, je n'ai finalement pas utilisé de facteurs aussi douteux dans le modèle final.
- De quoi tu te rappelles? Surpris? Une fonctionnalité qui a fonctionné, ou une sorte de truc de boost?
- J'ai appris deux leçons. Premièrement, lorsque j'ai décidé de mélanger deux modèles: linéaire et boosting, et en même temps, pour chaque région, les coefficients avec lesquels ces deux modèles ont été pris (ils se sont avérés différents) ont simplement été mis en place la semaine dernière - c'est-à-dire pendant sept jours. En fait, j'ai mis en place 1 à 2 coefficients pour chaque région pendant 7 jours. Mais la découverte était la suivante: les prévisions se sont avérées bien pires par rapport à si je n'avais pas fait ces réglages. Dans certaines régions, le modèle a été fortement recyclé et, par conséquent, les prévisions s'y sont révélées mauvaises. Lors de la troisième étape du concours, j'ai décidé de ne pas le faire.
Et le deuxième point: il semble que le nombre de jours depuis le début devrait être utile en tant que caractéristique: du premier malade, du dixième malade. J'ai essayé de les ajouter, mais lors de la validation, cela a aggravé la situation. Je l'ai expliqué de cette façon: la distribution des valeurs dans les échantillons change avec le temps. Si vous étudiez le 20e jour à compter du début de la propagation du virus, alors lors de la prédiction de la distribution des valeurs de cette fonctionnalité, il y aura sept jours à l'avance, et peut-être que cela ne permet pas d'utiliser de tels facteurs avec avantage.
- Vous avez dit que la proportion de la population urbaine jouait un certain rôle. Et quoi d'autre?
- Oui, la part de la population urbaine pour les pays et les régions de la Russie a toujours été utilisée. Ce facteur a constamment donné un petit coup de pouce à la qualité des prévisions. En conséquence, à part la série chronologique elle-même, je n'ai rien pris d'autre dans le modèle final. J'ai essayé d'ajouter divers mais n'a pas fonctionné.
- Quelle est votre opinion: SARIMA c'est le siècle dernier?
- Les modèles d'autorégressivité - moyenne mobile - sont plus difficiles à mettre en place, et il est plus coûteux d'y ajouter des facteurs supplémentaires, même si je suis sûr qu'avec les modèles (S) ARIMA (X) il serait possible de faire de bonnes prédictions, mais pas aussi bon que le boosting.
- Et pour une période plus longue qu'une semaine, vous pouvez faire des prédictions, qu'en pensez-vous?
- Ce serait intéressant. Au départ, les organisateurs ont eu l'idée de collecter des prévisions à long terme. Le mois semble être un tournant où vous pouvez encore essayer les approches que j'ai faites.
- Que penses tu qu'il va advenir par la suite?
- Nous devons reconstruire le modèle, regardez. À propos, ma solution peut être trouvée ici:
github.com/Topspin26/sberbank-covid19-challenge Pour les
dernières nouvelles de la science des données COVID de la communauté internationale, visitez https://www.kaggle.com/tags/covid19 . Et bien sûr, nous vous invitons sur le canal #coronavirus sur opendatascience.slack.com (invité par ods.ai ).