L'infrastructure technologique du Groupe M.Video-Eldorado est aujourd'hui bien plus qu'une gigantesque chaîne de caisses enregistreuses dans plus de 1000 magasins à travers le pays. Sous le capot, nous avons une plate-forme en ligne qui fournit une interaction avec les clients, l'apprentissage automatique, des algorithmes de recherche intelligents, des robots de discussion, un système de recommandation, l'automatisation des processus commerciaux clés et le flux de documents électroniques. Sous la coupe, il y a une histoire détaillée sur ce qui nous a poussé à briser le monolithe en microservices.
Légendes de l'antiquité profonde
Pour que tout cela fonctionne comme une horloge, nous devons suivre l'évolution des technologies et répondre rapidement aux demandes des entreprises. Malheureusement, la fonctionnalité de base des systèmes ERP mondiaux est loin d'être toujours capable de répondre rapidement aux besoins émergents des clients internes. En 2016, c'est devenu l'un des arguments en faveur de notre transition vers une architecture de microservices.
L'entreprise était confrontée à une tâche assez difficile, celle de mettre en œuvre une logique métier unifiée de travail avec différents mécanismes promotionnels dans le processus de passation des commandes par les clients dans tous les canaux de vente et points de contact (à l'époque: site web, application mobile, caisses et terminaux dans les magasins et opérateurs dans les centres d'appels).
Dans le même temps, dans le paysage informatique, nous avions de grands systèmes monolithiques tels que la plate-forme de commerce électronique Oracle ATG, SAP CRM et autres. La répétition de la logique dans chacun d'eux ou la mise en œuvre dans l'une et la réutilisation dans une autre des fonctionnalités nécessaires, selon nos calculs, ont abouti à des années et à des dizaines de millions d'investissements.
Par conséquent, nous avons réuni une petite équipe de développeurs et de personnes techniquement compétentes qui étaient à notre disposition à ce moment-là, et avons réfléchi à la façon dont nous pourrions créer un service distinct pour nos besoins. Au cours du processus d'élaboration, nous avons réalisé que nous avions besoin en fait non pas d'un, mais de trois ou quatre outils de travail. C'est ainsi que nous arrivons pour la première fois au concept d'architecture de microservices.
Nous avons décidé de coder en Java, car nous avions l'expérience nécessaire dans ce domaine. Nous avons choisi Spring version 3.2. En conséquence, nous avons obtenu une sorte de micromonolithe distribué en trois ou quatre services, étroitement interconnectés les uns avec les autres. Malgré le fait qu'ils aient été développés de manière indépendante, seul tout le monde pouvait travailler ensemble.
Cependant, il s'agissait d'un grand pas en avant en termes de développement de sa propre technologie. Nous sommes passés de Java 6 à Java 8, avons commencé à maîtriser Spring 3, en passant progressivement à Spring 4. Bien sûr, c'était un certain essai.
Nous avons réussi à réduire le délai de mise en œuvre du projet, passant d'obscurs «mois de développement», après avoir mis en œuvre la logique commerciale cross-canal requise en près de deux mois.
Évolution technologique
En 2017-2018, nous avons commencé une refactorisation globale du micromonolithe. Le concept de développement de microservices était apprécié à la fois par les informaticiens et les entreprises. Le flux des tâches de travail a commencé à croître. De plus, nous avons continué à isoler les blocs fonctionnels nécessaires à différents consommateurs du paysage informatique de l'entreprise et à les traduire sur les rails des microservices.
Nous avons essayé de suivre le rythme et de passer à Java 9, mais cela n'a pas été couronné de succès. Malheureusement, nous n'avons pas tiré d'avantages tangibles de cet exercice, nous sommes donc restés sur Java 8. Il y
avait de plus en plus de services, il fallait les gérer de manière centralisée et les normaliser. C'est là que nous avons essayé la conteneurisation pour la première fois. Les conteneurs Docker étaient alors volumineux et lourds, de plusieurs centaines de mégaoctets chacun.
Plus tard, nous avons dû résoudre des problèmes d'équilibrage du trafic et de la charge sur les services. Nous avons choisi Consul pour les clients externes et Eureka pour les clients internes comme solutions. Nous avons essayé différents outils de communication interservices gRPC, RMI. Nous avons vécu comme ça pendant près d'un an et il nous a semblé que nous avions appris à réussir à créer des microservices et à construire une architecture de microservices.
Attachez vos ceintures de sécurité, nous nous noyons!
En 2019, le nombre de nos microservices a considérablement augmenté, dépassant la barre des 100+. Nous avons appliqué de nouvelles solutions pour la communication interservices, dans la mesure du possible, essayé de mettre en œuvre des approches basées sur les événements.
Pendant ce temps, les problèmes d'orchestration et de gestion des dépendances devenaient de plus en plus aigus. Mais le plus grand changement qui nous a déjà touchés début 2019 est lié au changement de politique de l'entreprise concernant l'utilisation de Java.
Nous avions le choix de ce qu'il fallait faire ensuite: rester avec Oracle et leur payer beaucoup d'argent, investir dans notre propre version d'Open JDK ou essayer de trouver de vraies alternatives.
Nous avons choisi la troisième option et avec BellSoft, qui est l'un des cinq leaders mondiaux impliqués dans le développement du projet OpenJDK, après une série de réunions et de discussions, nous avons élaboré un plan pour la transition et le pilotage de la nouvelle version de Java. , et combiné avec la transition directe vers Java 11. Le processus était difficile, mais sur tous les tests, nous n'avons pas ressenti de problèmes graves et insolubles.
La prochaine étape pour nous a été la mise en œuvre de la gestion des conteneurs pour Kubernetes. Grâce à cela, depuis un certain temps, il nous a semblé que tout allait bien et nous avons obtenu de sérieux succès. Mais ensuite, les problèmes suivants avec l'infrastructure sont apparus. Elle ne pouvait tout simplement pas faire face à l'augmentation constante de la charge.
Nous n'avons tout simplement pas eu le temps de passer à l'échelle. La nécessité des prochaines transformations techniques cardinales est devenue évidente. Nous avons donc commencé à nous tourner vers les technologies cloud et à nous efforcer de les essayer par nous-mêmes.
Élevez-vous au-dessus des nuages
Le début de 2020 nous a promis une grande étape dans le développement de nos technologies internes, la compréhension et l'amélioration de notre architecture de microservices. Il y avait un grand pas en avant dans les nuages. Hélas, les plans ont dû être corrigés, comme on dit, au cours de la pièce.
En raison de la pandémie COVID-19, au lieu de migrer progressivement et d'explorer les possibilités des services cloud, nous avons demandé à toute l'entreprise de rechercher de nouveaux outils pour répondre aux besoins changeants de nos clients en raison de la pandémie. Nous avons en fait écrit les prochains microservices, introduisant simultanément de nouvelles technologies et continuant de passer à l'infrastructure cloud.
Pour nous, la taille des conteneurs est devenue critique pour deux raisons simples: c'est de l'argent pour la puissance de cloud computing consommée et le temps que le développeur, et donc toute l'entreprise, consacre à lever les conteneurs, à les synchroniser et à les configurer, à exécuter des autotests, etc. Et ici, nous avons pleinement ressenti l'avantage et l'utilité de nos conteneurs compacts avec le runtime Liberica JDK.
Malgré le pic de la pandémie, en quelques mois, nous avons mis en place et lancé avec succès une opération productive de deux douzaines de microservices, entièrement basés sur l'infrastructure cloud.
Fin 2020, nous nous sommes concentrés sur les processus: nous avons investi beaucoup de temps et d'efforts dans la construction d'une approche produit, dans le développement de microservices, dans la sélection et la formation d'équipes séparées avec leurs propres métriques et KPI autour de divers domaines de business units. .
Scier le monolithe en microservices à l'aide de l'exemple du service de calcul de commande
Afin de ne pas mettre votre patience à l'épreuve, j'aimerais vous présenter des exemples spécifiques et une logique de travail avec une infrastructure de microservices. Prenons un calcul de commande typique dans un environnement informatique standard.
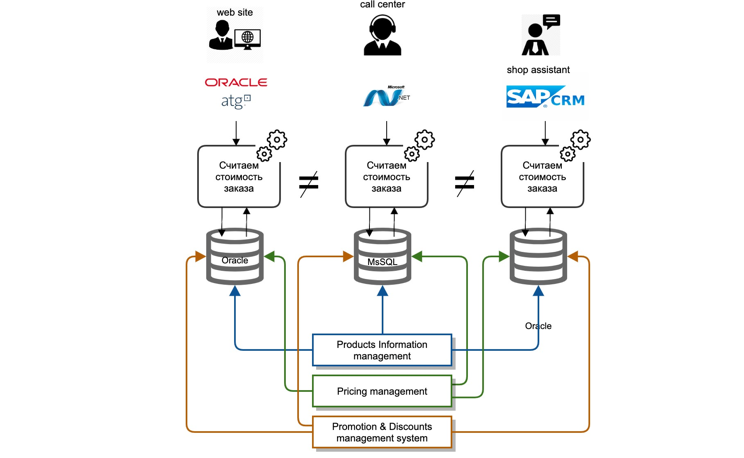
Nous avons été confrontés à toute une série de défis. Nos données de base étaient profondément ancrées dans les systèmes du back-office. Chaque système informatique est un monolithe classique: base de données, serveur d'applications. L'intégration des systèmes maîtres avec d'autres acteurs du paysage informatique a été réalisée en «point à point», c'est-à-dire que chaque système informatique s'est intégré, à sa manière et à chaque fois de nouveau.
Les intégrations étaient principalement de deux types: réplication au niveau de la base de données, transfert de fichiers. La logique de calcul a été répétée dans chaque système informatique séparément, à savoir dans différents langages de développement, il n'y a aucun moyen de réutiliser même le code d'une équipe voisine.
Il était extrêmement coûteux et presque impossible de synchroniser la logique de calcul simultanément dans tous les systèmes, en raison des différentes feuilles de route et des coûts de ressources des différents systèmes informatiques.
De plus, lors du traitement des plaintes des clients, il nous a été extrêmement difficile de déterminer pourquoi le prix correct ou l'une ou l'autre remise n'était pas fournie.
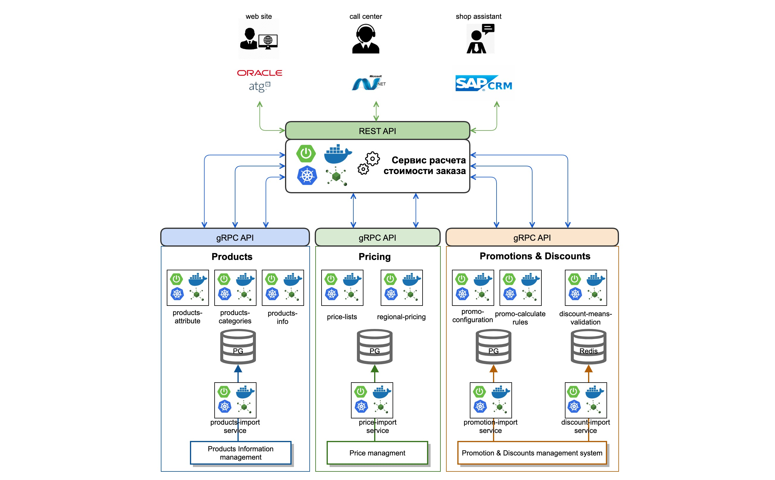
Qu'avons-nous fait? Nous avons analysé et déterminé le contexte nécessaire au calcul correct de la valeur de la commande. Ensuite, nous avons sélectionné des domaines d'activité et les avons divisés en interne en microservices distincts. Ainsi, par exemple, nous avons mis en évidence des données sur les marchandises qui devaient être prises en compte dans le processus de calcul du coût d'une commande.
Nous avons implémenté un service d'importation de données à partir de systèmes maîtres en ligne à l'aide de files d'attente (Kafka). En plus des données, nous avons implémenté des microservices atomiques qui fonctionnent avec des catégories de produits et leurs attributs (produits-attribut-service, produits-catégories-service). Nous avons fait la même chose avec les domaines dans le contexte du prix et de la promotion.
Par ailleurs, nous avons déplacé la logique et la procédure de calcul des prix de commande dans un moteur de calcul de commande séparé, mettant en œuvre une logique unifiée unique pour le calcul des prix et des coûts, en utilisant des fonds de réduction et des cartes promotionnelles.
Nous avons également mis en place une API REST standardisée pour tous les clients qui implémentent la logique de règlement des commandes. Pour la communication interservices, nous avons choisi le protocole gRPC avec une description sur protobuf3.
En conséquence, un microservice standard ressemble aujourd'hui à quelque chose comme ceci: il s'agit d'une application de démarrage à ressort, qui est collectée dans un conteneur docker à l'aide de GitLab CI et déployée dans le cluster Kubernetes.
Quelle est la ligne du bas?
Sur la voie de notre évolution technique, dans un premier temps, nous avons revu l'approche du processus de développement des services eux-mêmes et de constitution des équipes. Nous nous sommes concentrés sur une approche produit, recruté des équipes basées sur les principes maximum d'autonomie.
Dans le même temps, pour que les équipes correspondent à des domaines et domaines d'activité spécifiques et puissent, en conséquence, participer avec les responsables des fonctions métiers au développement d'un domaine d'activité particulier.
En termes de développement technique, nous avons choisi la connectivité asynchrone utilisant Kafka, y compris les flux Kafka, comme l'un des outils de communication interservices. Cela a permis aux équipes de devenir pratiquement indépendantes des autres. Nous utilisons et pratiquons également activement des pratiques de développement réactif, par exemple le projet de réacteur. Nous voulons toujours vraiment essayer le projet Loom.
Pour accélérer le développement, nous nous sommes concentrés sur le développement de plusieurs facteurs techniques et organisationnels qui nous ont permis d'influencer significativement le timing.
L'aspect technologique est le passage aux technologies cloud, qui a assuré la vitesse optimale d'automatisation des processus CI \ CD. La vitesse et la durée de la régression complète et du déploiement d'un microservice particulier sont ici essentielles.
Par exemple, aujourd'hui, une exécution complète (avec tous les types de tests unitaires, contractuels, d'intégration) CI \ CD Pipeline pour une application commerciale productive et fonctionnelle - et cela représente environ 12 à 15 microservices interconnectés) dure environ 31 minutes, soit 7-8 minutes de moins que les indicateurs début 2020.
Ainsi, nous passons environ 17 à 18% de temps en moins à attendre le résultat. Ces économies nous permettent de nous attaquer à d'autres tâches d'épicerie. Cela est en grande partie dû au fait que nous utilisons des conteneurs compacts basés sur Alpine Linux, qui deviennent de plus en plus rapides et légers chaque heure.
Nous sommes devenus plus efficaces en termes de développement de microservices en général. Et cela a un effet positif sur l'expérience utilisateur de nos clients. La vitesse est désormais l'une des mesures clés de nos produits en ligne (site Web et applications mobiles), et Liberica JDK nous permet également d'atteindre ce gain, qui en termes de performances, nous convertissons en une expérience positive pour nos clients.
De plus, la bonne approche du développement de microservices nous a permis d'accélérer considérablement le temps de lancement de notre produit sur le marché. Nous avons appris à mettre en production des services individuels, en utilisant diverses stratégies de déploiement A \ B, conserverie et autres selon les besoins. Cela permet de recevoir rapidement un retour d'expérience sur le travail des microservices.
En deux mois, nous avons développé et implémenté quelques nouveaux services dans l'expérience d'achat. Nous parlons de la soi-disant livraison rapide des marchandises dans les 2 heures (nous utilisons divers agrégateurs de taxi et de livraison) et de l'émission de nos commandes dans les endroits les plus inattendus (dans les magasins Pyaterochka ou les bureaux de poste russes, même dans les parkings de grande taille). centres d'affaires).
Grâce à nos microservices, certains clients du Groupe M.Video-Eldorado ont la possibilité de prendre un taxi avec leurs marchandises directement à la maison depuis le magasin.
Plans créatifs
Nos plans pour 2021 incluent le développement actif de l'infrastructure cloud et la transition entièrement vers le concept d'infrastructure en tant que code («Infrastructure as a code»).
Nous prévoyons d'accorder une grande attention à la construction de solutions transparentes pour le contrôle et l'interaction des microservices sous la forme d'une solution Service Mesh basée sur Istio et Admiral. Nous avons beaucoup de travail à faire pour peaufiner et améliorer l'ensemble de la pile Observability, surveiller le suivi des demandes et la journalisation des messages.
Nous prévoyons également d'essayer d'utiliser des technologies sans serveur, y compris une volonté de l'essayer en java. De plus, il existe une idée si lointaine mais pas irréaliste de créer une infrastructure et un écosystème multi-cloud.
Si vous souhaitez toucher notre pile technologique avec vos mains, n'hésitez pas, il y a assez de travail pour tout le monde. L'inscription des volontaires se fait 24h / 24 et 7j / 7: ici . Vous êtes les bienvenus .
Avantages, astuces de vie, expérience personnelle

Dmitry Chuiko , BellSoft Senior Performance Architect, sur les secrets des petits conteneurs Docker pour les microservices Java:
─ . , . Docker-. , : , .
Linux , . JDK. , , .
1.
CentOS CentOS slim. ? Debian. Alpine musl. BellSoft Alpine Linux, — Linux. Liberica JDK 11.0.10 + 11.0.10 Linux.
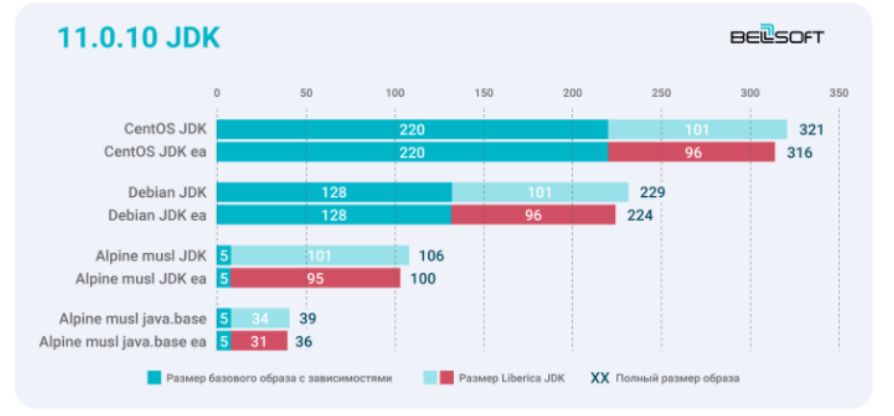
Liberica EA 3–6 14,7 % Alpine musl java.base. 7,6 %. Docker-, JRE java.base. Liberica JRE EA — 16 %.
Liberica Lite . , , — . - Java SE JVM, Standart, JIT- (C1, C2, Graal JIT Compiler), (Serial, Parallel, CMS, G1, Shenandoah, ZGC) serviceability, .
2. JDK
— jdeps JLINK. . Java (JDeps). - Java, . . JAR, , . JDeps JDK, Java-. , , .

jdeps , java.base. jlink. , BellSoft Docker- java.base. DockerHub, .
docker run –rm bellsoft/liberica – openjdk -demos- asciiduke.
CLI-like java.base. Liberica JDK Lite Alpine Linux musl 40,4 .
.
Enjoy!