
Chez ForePaaS, nous expérimentons le DevOps depuis un certain temps maintenant - d'abord en équipe, et maintenant dans toute l'entreprise. La raison est simple: l'organisation grandit. Auparavant, nous n'avions qu'une seule équipe pour toutes les occasions. Elle était impliquée dans l'architecture, la conception et la sécurité des produits et était rapide à répondre à tout problème. Désormais, nous sommes divisés en plusieurs équipes par spécialisation: front-end, back-end, développement, opération ...
Nous nous sommes rendu compte que nos méthodes précédentes ne seraient pas si efficaces et nous devons changer quelque chose, tout en maintenant la vitesse sans sacrifier la qualité et le vice versa.
Auparavant, nous appelions l'équipe devops, qui, en fait, faisait Ops et était également responsable du développement sur le backend. Une fois par semaine, d'autres développeurs ont expliqué à l'équipe DevOps quels nouveaux services devaient être déployés en production. Cela a parfois conduit à des problèmes. D'une part, l'équipe DevOps n'a pas vraiment compris ce qui se passait avec les développeurs, d'autre part, les développeurs ne se sentaient pas responsables de leurs services.
Récemment, les gars de DevOps ont essayé de réveiller cette responsabilité chez les développeurs - pour la disponibilité, la fiabilité et la qualité du code de service. Pour commencer, il fallait rassurer les développeurs, alarmés par la charge qui leur était tombée dessus. Ils avaient besoin de plus d'informations pour diagnostiquer les problèmes émergents, nous avons donc décidé de mettre en place une surveillance du système.
Dans cet article, nous parlerons de ce qu'est la surveillance et de ce avec quoi elle est consommée, nous en apprendrons davantage sur les soi-disant quatre signaux dorés, et nous discuterons de la manière d'utiliser les métriques et d'explorer les problèmes actuels.
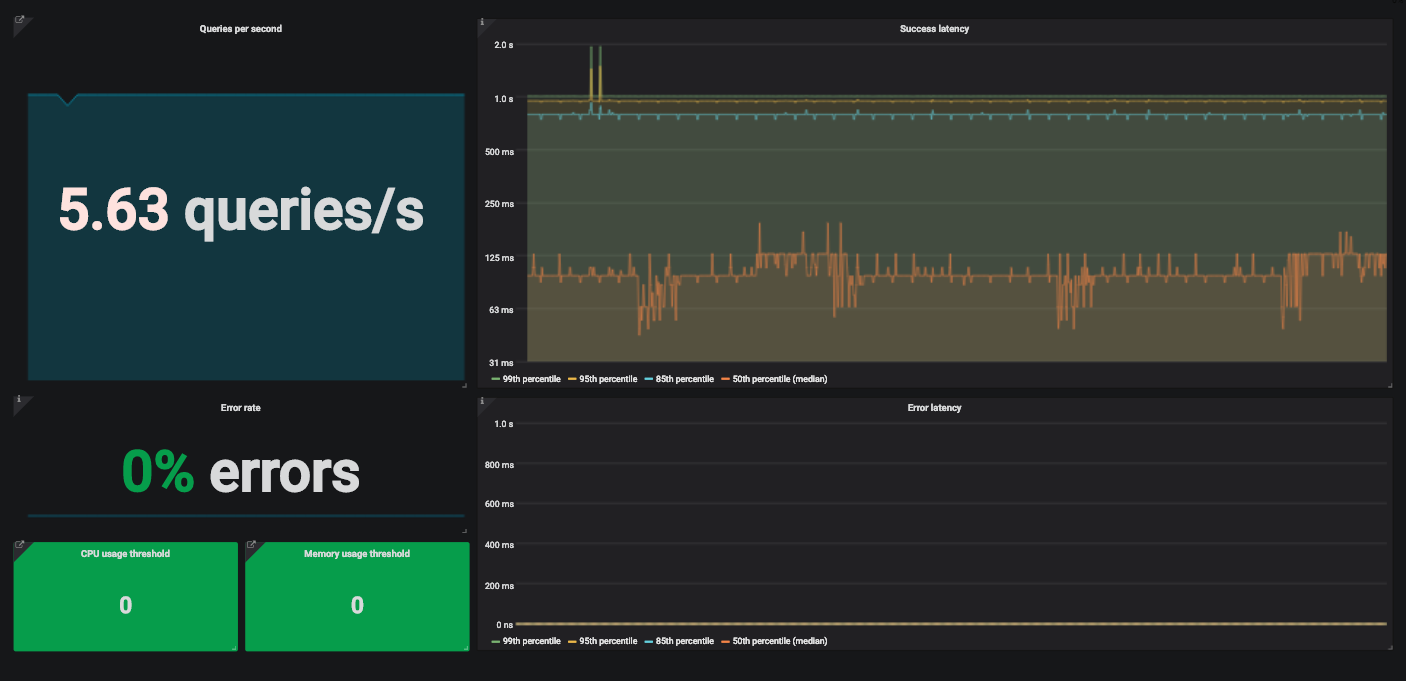
Un exemple de tableau de bord Grafana avec quatre signaux d'or pour surveiller un service.
Qu'est-ce que la surveillance?
La surveillance est la création, la collecte, l'agrégation et l'utilisation de mesures qui fournissent un aperçu de la santé d'un système.
Pour surveiller un système, nous avons besoin d'informations sur ses composants logiciels et matériels. Ces informations peuvent être obtenues grâce à des métriques collectées à l'aide d'un programme spécial ou d'une instrumentation de code.
L'instrumentation change votre code afin que vous puissiez mesurer ses performances. Nous ajoutons du code qui n'affecte pas la fonctionnalité du produit lui-même, mais calcule simplement et fournit des métriques. Disons que nous voulons mesurer la latence d'une requête. Ajoutez un code qui calculera le temps nécessaire au service pour traiter la demande reçue.
La métrique ainsi créée doit encore être collectée et combinée avec d'autres. Cela se fait généralement avec Metricbeat pour la collecte et Logstash pour l'indexation des métriques dans Elasticsearch . Ensuite, ces métriques peuvent être utilisées à vos propres fins. En règle générale, cette pile est complétée par Kibana , qui restitue les données indexées dans Elasticsearch.
Pourquoi surveiller?
Vous devez surveiller le système pour diverses raisons. Par exemple, nous surveillons l'état actuel du système et ses variations afin de générer des alertes et de peupler les tableaux de bord. Lorsque nous recevons une alerte, nous recherchons les raisons de l'échec sur le tableau de bord. Parfois, la surveillance est utilisée pour comparer deux versions d'un service ou analyser les tendances à long terme.
Que surveiller?
L'ingénierie de fiabilité du site a un chapitre utile sur la surveillance des systèmes distribués qui décrit l'approche de Google pour suivre les quatre signaux d'or.

Beyer, B., Jones C., Murphy, N. & Petoff, J. (2016) Ingénierie de la fiabilité du site. Comment Google gère les systèmes de production. O'Reilly. Version gratuite en ligne: https://landing.google.com/sre/sre-book/toc/index.html
- — . . — , .
- — . API . , .
- . (, 500- ) . — , .
- , , . ? . . , , .
?
Prenons l'exemple de la pile technologique. Nous choisissons généralement des outils standard populaires au lieu de solutions personnalisées. Sauf lorsque les fonctionnalités disponibles ne nous suffisent pas. Nous déployons la plupart des services dans les environnements Kubernetes et instrumentons le code pour obtenir des métriques sur chaque service personnalisé. Pour collecter ces métriques et les préparer pour Prometheus, nous utilisons l' une des bibliothèques clientes Prometheus . Il existe des bibliothèques clientes pour presque toutes les langues courantes. Dans la documentation, vous trouverez tout ce dont vous avez besoin pour écrire votre propre bibliothèque.
S'il s'agit d'un service open source tiers, nous prenons généralement les exportateurs suggérés par la communauté. Les exportateurs sont le code qui collecte les métriques du service et les formate pour Prometheus. Ils sont généralement utilisés avec des services qui ne génèrent pas de métriques Prometheus.
Nous envoyons des métriques dans le pipeline et les stockons dans Prometheus sous forme de séries chronologiques. De plus, nous utilisons des métriques d'état kube dans Kubernetes pour collecter et soumettre des métriques à Prometheus. Nous pouvons ensuite créer des tableaux de bord et des alertes dans Grafana à l' aide des requêtes Prometheus. Nous n'entrerons pas dans les détails techniques ici, expérimentez vous-même ces outils. Ils ont une documentation détaillée, vous pouvez facilement la comprendre.
Par exemple, regardons une API simple qui reçoit du trafic et traite les demandes reçues à l'aide d'autres services.
Retard
La latence est le temps nécessaire pour traiter une demande. Nous mesurons la latence séparément pour les demandes réussies et pour les erreurs. Nous ne voulons pas que ces statistiques se mélangent.
La latence globale est généralement prise en compte, mais ce n'est pas toujours un bon choix. Mieux vaut suivre la distribution de la latence car elle est plus conforme aux exigences de disponibilité. La proportion de demandes traitées plus rapidement qu'un seuil donné est un indicateur de niveau de service (SLI) commun. Voici un exemple d'objectif de niveau de service (SLO) pour ce SLI:
"Dans les 24 heures, 99% des demandes devraient être traitées en moins d'une seconde."
Le moyen le plus visuel de représenter les métriques de latence consiste à utiliser un graphique de série chronologique. Nous mettons les métriques dans des seaux et les exportateurs les collectent toutes les minutes. De cette manière, n-quantiles pour les latences de service peuvent être calculés.
Si 0 <n <1 et que le graphique contient q valeurs, le n-quantile de ce graphique est égal à une valeur qui ne dépasse pas n * q sur q valeurs. Autrement dit, la médiane, 0,5 quantile d'un graphique avec x enregistrements est égale à une valeur qui ne dépasse pas la moitié de x enregistrements.
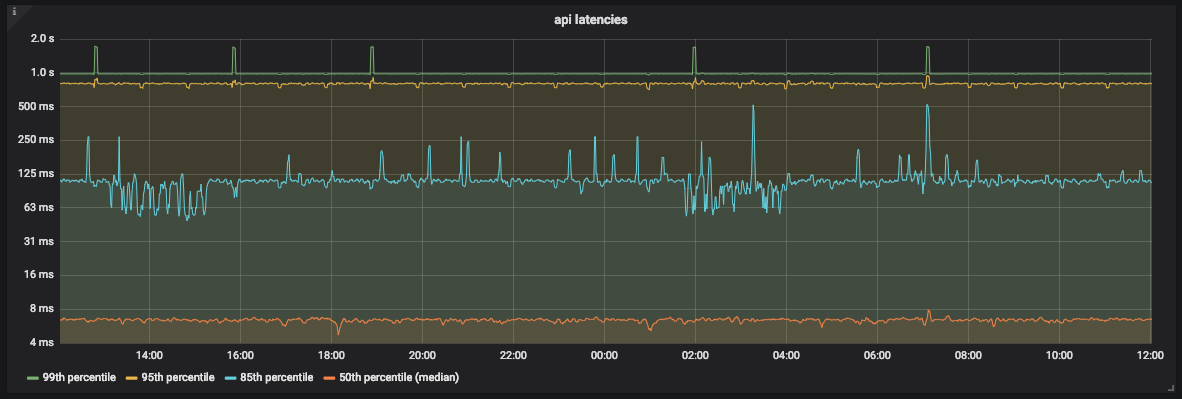
Graphique de latence de l'API
Comme vous pouvez le voir sur le graphique, l'API traite la plupart du temps 99% des requêtes en moins d'une seconde. Cependant, il y a aussi des pics d'environ 2 secondes qui ne correspondent pas à notre SLO.
Puisque nous utilisons Prometheus, nous devons être très prudents lors du choix de la taille du godet. Prometheus permet des tailles de godets linéaires et exponentielles. Peu importe ce que nous choisissons, tant que les erreurs d'estimation sont prises en compte .
Prometheus ne fournit pas de valeur exacte pour le quantile. Il détermine dans quel compartiment se trouve le quantile, puis utilise une interpolation linéaire et calcule une valeur approximative.
Circulation
Pour mesurer le trafic d'une API, vous devez compter le nombre de requêtes qu'elle reçoit chaque seconde. Étant donné que nous collectons des métriques une fois par minute, nous n'obtiendrons pas la valeur exacte pendant une seconde spécifique. Mais nous pouvons calculer le nombre moyen de requêtes par seconde en utilisant les fonctions de débit et de colère de Prometheus.
Pour afficher ces informations, nous utilisons le panneau Grafana SingleStat. Il affiche les demandes moyennes actuelles par seconde et les tendances.

Un exemple de panneau Grafana SingleStat avec le nombre de requêtes que notre API reçoit par seconde
Si le nombre de requêtes par seconde change soudainement, nous le verrons. Si le trafic est divisé par deux en quelques minutes, nous comprendrons qu'il y a un problème.
les erreurs
Il est facile de calculer le pourcentage d'erreurs évidentes - divisez les réponses HTTP 500 par le nombre total de requêtes. Comme pour le trafic, nous utilisons ici une moyenne.
L'intervalle doit être le même que pour le trafic. Cela facilitera le suivi du trafic avec des erreurs sur un panneau.
Disons que le taux d'erreur est de 10% au cours des cinq dernières minutes et que l'API traite 200 requêtes par seconde. Il est facile de calculer qu'en moyenne, il y avait 20 erreurs par seconde.
Saturation
Pour surveiller la saturation, vous devez définir des limites de service. Pour notre API, nous avons commencé par mesurer les ressources du processeur et de la mémoire, car nous ne savions pas ce qui affecte le plus. Kubernetes et kube-state-metrics fournissent ces métriques pour les conteneurs.
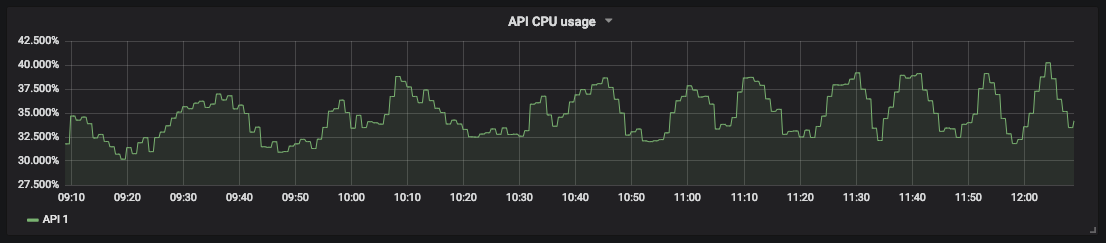
Un graphique de l'utilisation du processeur pour notre
mesure de saturation API vous permet de prévoir les temps d'arrêt et de planifier les ressources. Par exemple, pour le stockage de base de données, vous pouvez mesurer l'espace disque libre et la vitesse à laquelle il se remplit pour comprendre quand agir.
Tableaux de bord détaillés pour surveiller les services distribués
Jetons un coup d'œil à un autre service. Par exemple, une API distribuée qui agit comme un proxy pour d'autres services. Cette API a plusieurs instances dans différentes régions et plusieurs points de terminaison. Chacun d'eux dépend de son propre ensemble de services. Il devient rapidement assez difficile de lire des graphiques avec des dizaines de lignes. Nous avons besoin de la capacité de surveiller l'ensemble du système et, si nécessaire, de détecter les pannes individuelles.
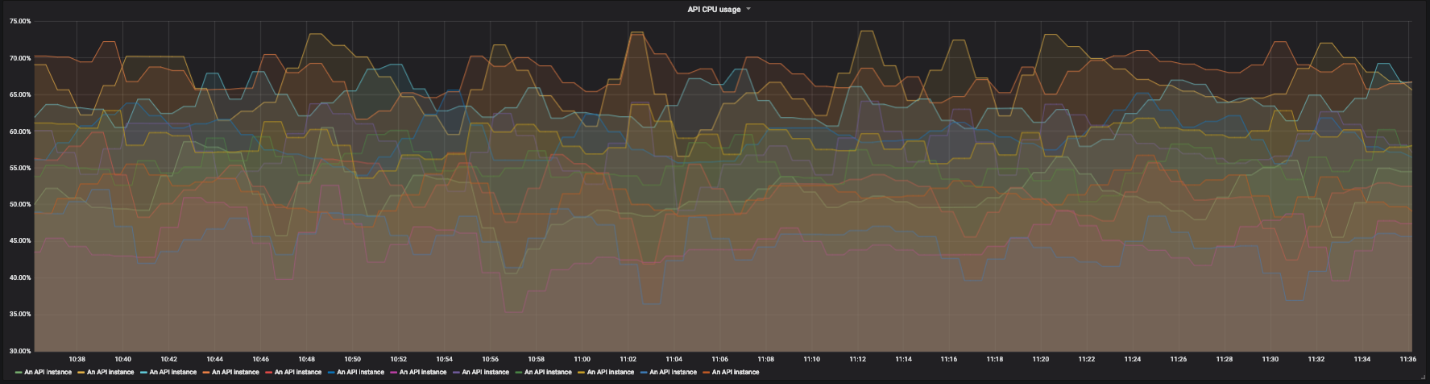
Graphique d'utilisation du processeur pour 12 instances de notre API
Pour cela, nous utilisons des tableaux de bord détaillés. Sur chaque écran d'un panneau, nous voyons une vue globale du système et pouvons cliquer sur des éléments individuels pour examiner les détails. Pour la saturation, nous n'utilisons pas de graphiques, mais simplement des rectangles colorés montrant l'utilisation des ressources processeur et mémoire. Si l'utilisation des ressources dépasse le seuil spécifié, le rectangle devient orange.

Indicateurs d'utilisation du processeur et de la mémoire pour les
instances d' API Cliquez sur le rectangle, accédez aux détails et voyez plusieurs rectangles colorés représentant différentes instances d'API.

Indicateurs d'utilisation du processeur pour les instances d'API
Si une seule instance a un problème, nous pouvons cliquer sur le rectangle et trouver plus de détails. Ici, nous voyons la région de l'instance, les demandes reçues, etc.

Une vue granulaire de l'état d'une instance d'API. De gauche à droite, de haut en bas: région du fournisseur, nom d'hôte de l'instance, date du dernier redémarrage, requêtes par seconde, utilisation du processeur, utilisation de la mémoire, nombre total de requêtes par chemin et pourcentage d'erreur total par chemin.
Nous faisons de même avec le pourcentage d'erreurs - nous cliquons et regardons le pourcentage d'erreurs pour chaque point de terminaison de l'API afin de comprendre où se situe le problème - dans l'API elle-même ou les services auxquels elle est associée.
Nous avons fait de même pour les retards et les erreurs de demande réussis, bien qu'il y ait des nuances ici. L'objectif principal est de s'assurer que le service est correct à l'échelle mondiale. Le problème est que l'API a de nombreux points de terminaison différents, dont chacun dépend de plusieurs services. Chaque point de terminaison a ses propres retards et trafic.
Il est difficile de configurer des SLO (et SLA) distincts pour chaque point de terminaison de service. Certains points de terminaison auront une latence nominale plus élevée que d'autres. Dans ce cas, une refactorisation peut être nécessaire. Si des SLO distincts sont nécessaires, vous devez diviser l'ensemble du service en services plus petits. Peut-être verrons-nous que la couverture de notre service était trop large.
Nous avons décidé qu'il serait préférable de surveiller la latence globale. La granularité permet simplement d'étudier le problème lorsque les écarts de latence sont suffisamment importants pour attirer l'attention.
Conclusion
Nous utilisons ces méthodes pour surveiller les systèmes depuis un certain temps maintenant et avons remarqué que le temps nécessaire pour trouver des problèmes et le temps moyen de récupération (MTTR) ont diminué. Les détails nous permettent de trouver la cause réelle d'un problème global, et pour nous cette capacité a beaucoup changé.
D'autres équipes de développement ont également commencé à utiliser ces méthodes et n'y voient que des avantages. Désormais, ils ne sont pas seulement responsables du fonctionnement de leurs services. Ils vont encore plus loin et peuvent déterminer comment les modifications apportées au code affectent le comportement des services.
Les quatre signaux en or ne résolvent pas du tout tous les problèmes, mais ils sont très utiles pour les plus courants. Avec presque aucun effort, nous avons pu améliorer considérablement la surveillance et réduire le MTTR. Ajoutez autant de métriques que nécessaire, tant qu'il y a quatre signaux en or parmi eux.