
Daniel Lemire - professeur à l'Université par correspondance du Québec (TÉLUQ), qui a inventé un moyen d'analyser le double très rapidement - avec l'ingénieur John Kaiser de Microsoft a publié une autre découverte: le validateur UTF-8, surpassant la bibliothèque UTF-8 CPP (2006) à 48..77 fois, DFA de Björn Hörmann (2009) - 20..45 fois, et Google Fuchsia (2020) - 13..35 fois. L'actualité de cette publication a déjà été postée sur Habré , mais sans détails techniques; nous compensons donc cette lacune.
Exigences UTF-8
Pour commencer, rappelez-vous que Unicode autorise les points de code de U + 0000 à U + 10FFFF, qui sont codés en UTF-8 sous forme de séquences de 1 à 4 octets:
| Le nombre d'octets dans l'encodage | Le nombre de bits dans le point de code | Valeur minimum | Valeur maximum |
|---|---|---|---|
| une | 1..7 | U + 0000 = 0 0000000 | U + 007F = 0 1111111 |
| 2 | 8..11 | U + 0080 = 110 00010 10 000 000 | U + 07FF = 110 11111 10 111111 |
| 3 | 12..16 | U + 0800 = 1110 0000 10 100000 10 000000 | U + FFFF = 1110 1111 10 111111 10 111111 |
| quatre | 17..21 | U + 010000 = 11110 000 10 010000 10 000000 10 000000 | U + 10FFFF = 11110 100 10 001111 10 111111 10 111111 |
Selon les règles de codage, les bits les plus significatifs du premier octet de la séquence déterminent le nombre total d'octets de la séquence; Le bit le plus significatif zéro ne peut être que des caractères à un octet (ASCII), les deux bits les plus significatifs uniques désignent un caractère multi - octets, 1 et zéro désignent un octet de continuation> caractère multi-octets.
Quel genre d'erreurs pourrait-il y avoir dans une chaîne encodée de cette façon?
- Séquence incomplète : un octet de début ou un caractère ASCII a été rencontré à l'endroit où un octet de continuation était attendu;
- Séquence non boutonnée : un octet de début ou un caractère ASCII était attendu à l'endroit où un octet de continuation a été rencontré;
- Séquence trop longue : l'octet de tête
11111xxx
correspond à une séquence de cinq octets ou plus qui n'est pas autorisée en UTF-8; - Dépasser les limites Unicode : après décodage de la séquence de quatre octets, le point de code est supérieur à U + 10FFFF.
Si la ligne ne contient aucune de ces quatre erreurs, elle peut être décodée en une séquence de points de code corrects. UTF-8, cependant, nécessite plus - que chaque séquence de points de code corrects soit codée de manière unique. Cela ajoute deux autres types d'erreurs possibles:
- : code point ;
- : code points U+D800 U+DFFF UTF-16, code point U+FFFF. UTF-8 , code points , .
Dans le codage CESU-8 rarement utilisé, la dernière exigence est annulée (et dans MUTF-8, c'est aussi l'avant-dernière), en raison de laquelle la longueur de la séquence est limitée à trois octets, mais le décryptage et la validation des chaînes sont compliqués. Par exemple, l'émoticône U + 1F600 GRINNING FACE est représentée dans UTF-16 comme une paire de substituts
0xD83D 0xDE00
, et CESU-8 / MUTF-8 la traduit en une paire de séquences de trois octets
0xED 0xA0 0xBD 0xED 0xB8 0x80
; mais en UTF-8, ce smiley est codé dans une séquence de quatre octets
0xF0 0x9F 0x98 0x80
.
Pour chaque type d'erreur, voici les séquences de bits qui y conduisent:
| Séquence inachevée | 2e octet manquant | 11xxxxxx 0xxxxxxx
|
11xxxxxx 11xxxxxx
|
||
| 3e octet manquant | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| 4ème octet manquant | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Séquence non récupérée | 2e octet supplémentaire | 0xxxxxxx 10xxxxxx
|
| 3e octet supplémentaire | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| 4e octet supplémentaire | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| 5e octet supplémentaire | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Séquence trop longue | 11111xxx
|
|
| Dépasser les frontières Unicode | U + 110000..U + 13FFFF | 11110100 1001xxxx
|
11110100 101xxxxx
|
||
| ≥ U + 140 000 | 11110101
|
|
1111011x
|
||
| Cohérence non minimale | 2 octets | 1100000x
|
| 3 octets | 11100000 100xxxxx
|
|
| 4 octets | 11110000 1000xxxx
|
|
| Substituts | 11101101 101xxxxx
|
|
Valider UTF-8
Avec l'approche naïve utilisée dans la bibliothèque UTF-8 CPP du serbe Nemanja Trifunovic, la validation est effectuée dans une cascade de branches imbriquées:
const octet_difference_type length = utf8::internal::sequence_length(it);
// Get trail octets and calculate the code point
utf_error err = UTF8_OK;
switch (length) {
case 0:
return INVALID_LEAD;
case 1:
err = utf8::internal::get_sequence_1(it, end, cp);
break;
case 2:
err = utf8::internal::get_sequence_2(it, end, cp);
break;
case 3:
err = utf8::internal::get_sequence_3(it, end, cp);
break;
case 4:
err = utf8::internal::get_sequence_4(it, end, cp);
break;
}
if (err == UTF8_OK) {
// Decoding succeeded. Now, security checks...
if (utf8::internal::is_code_point_valid(cp)) {
if (!utf8::internal::is_overlong_sequence(cp, length)){
// Passed! Return here.
À l'intérieur
sequence_length()
et
is_overlong_sequence()
aussi en ramification en fonction de la longueur de la séquence. Si des séquences de différentes longueurs sont imbriquées de manière imprévisible dans la chaîne d'entrée, alors le prédicteur de branchement ne peut pas éviter de vider le pipeline plusieurs fois sur chaque caractère traité.
Une approche plus efficace de la validation UTF-8 consiste à utiliser une machine à états de 9 états: (l'état d'erreur n'est pas montré dans le diagramme)
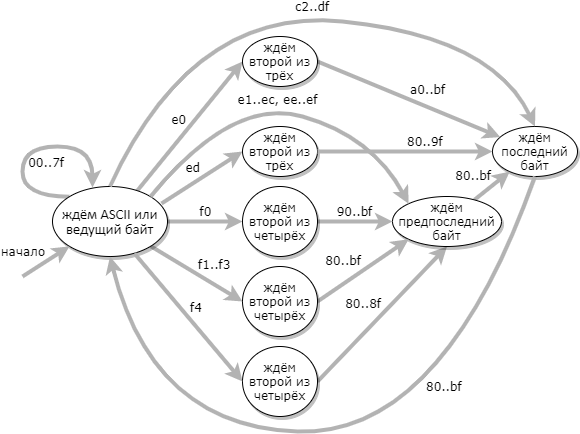
Lorsque la table de transition d'automate est construite, le code du validateur est très simple:
uint32_t type = utf8d[byte];
*codep = (*state != UTF8_ACCEPT) ?
(byte & 0x3fu) | (*codep << 6) :
(0xff >> type) & (byte);
*state = utf8d[256 + *state + type];
Ici, pour chaque caractère traité, les mêmes actions sont répétées, sans transitions conditionnelles - par conséquent, aucune réinitialisation de canal n'est requise; par contre, à chaque itération, un accès mémoire supplémentaire (à la table de saut
utf8d
) est effectué en plus de la lecture du caractère d'entrée.
Lemir et Kaiser ont utilisé le même DFA comme base de leur validateur et ont décuplé une accélération grâce à l'application de trois améliorations:
- La table de sauts a été réduite de 364 octets à 48, de sorte qu'elle tient entièrement dans trois registres vectoriels (128 bits chacun), et les accès à la mémoire ne sont nécessaires que pour lire les caractères d'entrée;
- Les blocs de 16 octets adjacents sont traités en parallèle;
- Si un bloc de 16 octets se compose entièrement de caractères ASCII, alors il est connu pour être correct et il n'est pas nécessaire de procéder à une vérification plus approfondie. Cette "tranche de chemin" accélère de deux à trois fois le traitement de textes "réalistes" contenant des phrases entières en alphabet latin; mais sur des textes aléatoires, où l'alphabet latin, les hiéroglyphes et les émoticônes sont uniformément mélangés, cela ne s'accélère pas.
Il y a des subtilités subtiles dans la mise en œuvre de chacune de ces améliorations, elles méritent donc d'être examinées en détail.
Réduire la table de saut
La première amélioration repose sur le constat que pour détecter la plupart des erreurs (12 séquences de bits invalides sur les 19 listées dans le tableau ci-dessus), il suffit de vérifier les 12 premiers bits de la séquence:
| Séquence inachevée | 2e octet manquant | 11xxxxxx 0xxxxxxx
|
0x02
|
11xxxxxx 11xxxxxx
|
|||
| Séquence non récupérée | 2e octet supplémentaire | 0xxxxxxx 10xxxxxx
|
0x01
|
| Séquence trop longue | 11111xxx 1000xxxx
|
0x20
|
|
11111xxx 1001xxxx
|
0x40
|
||
11111xxx 101xxxxx
|
|||
| Dépasser les frontières Unicode | U + 1 [1235679ABDEF] xxxx | 111101xx 1001xxxx
|
|
111101xx 101xxxxx
|
|||
| U + 1 [48C] xxxx | 11110101 1000xxxx
|
0x20
|
|
1111011x 1000xxxx
|
|||
| Cohérence non minimale | 2 octets | 1100000x
|
0x04
|
| 3 octets | 11100000 100xxxxx
|
0x10
|
|
| 4 octets | 11110000 1000xxxx
|
0x20
|
|
| Substituts | 11101101 101xxxxx
|
0x08
|
|
Pour chacune de ces erreurs potentielles, les chercheurs ont attribué l'un des sept bits, comme indiqué dans la colonne la plus à droite. (Les bits attribués sont différents entre leur article publié et leur code GitHub ; voici les valeurs de l'article.) Pour se débrouiller avec sept bits, les deux sous-cas Unicode hors limites ont dû être repartitionnés afin que le second est concaténé avec une séquence non minimale de 4 octets; et le cas de séquence trop longue est divisé en trois sous-cas et combiné avec les sous-cas Unicode hors limites.
Ainsi, les modifications suivantes ont été apportées au Hörmann DKA:
- L'entrée ne vient pas par octet, mais par tétrade (quartet);
- L'automate est utilisé comme non déterministe - le traitement de chaque tétrade transfère l'automate entre des sous-ensembles de tous les états possibles;
- Huit états corrects sont combinés en un seul, mais un état erroné est divisé en sept;
- Trois tétrades adjacentes sont traitées non pas séquentiellement, mais indépendamment les unes des autres, et le résultat est obtenu comme l'intersection de trois ensembles d'états finaux.
Grâce à ces changements, trois tableaux de 16 octets suffisent pour décrire toutes les transitions possibles: chaque élément du tableau est utilisé comme un champ de bits listant tous les états finaux possibles. Trois de ces éléments sont associés par ET, et s'il y a des bits différents de zéro dans le résultat, alors une erreur a été détectée.
| Tetrad | Valeur | Erreurs possibles | Le code |
|---|---|---|---|
| Haut dans le premier octet | 0-7 | 2- | 0x01
|
| 8–11 | () | 0x00
|
|
| 12 | 2- ; 2- | 0x06
|
|
| 13 | 2- | 0x02
|
|
| 14 | 2- ; 2- ; | 0x0E
|
|
| 15 | 2- ; ; Unicode; 4- | 0x62
|
|
| 0 | 2- ; 2- ; | 0x37
|
|
| 1 | 2- ; 2- ; 2- | 0x07
|
|
| 2–3 | 2- ; 2- | 0x03
|
|
| 4 | 2- ; 2- ; Unicode | 0x43
|
|
| 5–7 | 0x63
|
||
| 8–10, 12–15 | 2- ; 2- ; | ||
| 11 | 2- ; 2- ; ; | 0x6B
|
|
| 0–7, 12–15 | Le 2ème octet est manquant; séquence trop longue; Séquence non minimale de 2 octets | 0x06
|
|
| 8 | 2e octet supplémentaire; séquence trop longue; aller au-delà des frontières Unicode; cohérence non minimale | 0x35
|
|
| neuf | 0x55
|
||
| 10-11 | 2e octet supplémentaire; séquence trop longue; aller au-delà des frontières Unicode; Séquence non minimale de 2 octets; substituts | 0x4D
|
Il y a 7 autres séquences de bits non valides non traitées:
| Séquence inachevée | 3e octet manquant | 111xxxxx 10xxxxxx 0xxxxxxx
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| 4ème octet manquant | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Séquence non récupérée | 3e octet supplémentaire | 110xxxxx 10xxxxxx 10xxxxxx
|
| 4e octet supplémentaire | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| 5e octet supplémentaire | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
Et ici, le bit le plus significatif est pratique, prudemment laissé inutilisé dans les tables de transition: il correspondra à une séquence de bits
10xxxxxx 10xxxxxx
, c'est-à-dire deux octets consécutifs. Maintenant, la vérification de trois ordinateurs portables peut soit détecter une erreur, soit donner un résultat
0x00
ou
0x80
. Et ce résultat du premier contrôle - avec le premier cahier - nous suffit:
| 3e octet manquant | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| 4ème octet manquant | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| 3e octet supplémentaire | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| 4e octet supplémentaire | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| 5e octet supplémentaire | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Combinaisons autorisées |
|
|
|
||
Cela signifie que pour terminer la vérification, il suffit de s'assurer que chaque résultat
0x80
correspond à l'une des deux combinaisons valides.
Vectorisation
Comment traiter des blocs de 16 octets adjacents en parallèle? L'idée centrale est d'utiliser l'instruction
pshufb
comme 16 substitutions simultanées selon une table de 16 octets. Pour la deuxième vérification, vous devez trouver dans le bloc tous les octets du formulaire
111xxxxx
et
1111xxxx
; comme il n'y a pas de comparaison vectorielle non signée sur Intel, elle est remplacée par la soustraction de saturation (
psubusb
).
Les sources simdjson sont difficiles à lire en raison du fait que tout le code est divisé en fonctions sur une seule ligne. L'ensemble du pseudocode du validateur ressemble à ceci:
prev = vector(0)
while !input_exhausted:
input = vector(...)
prev1 = prev<<120 | input>>8
prev2 = prev<<112 | input>>16
prev3 = prev<<104 | input>>24
#
nibble1 = prev1.shr(4).lookup(table1)
nibble2 = prev1.and(15).lookup(table2)
nibble3 = input.shr(4).lookup(table3)
result1 = nibble1 & nibble2 & nibble3
#
test1 = prev2.saturating_sub(0xDF) # 111xxxxx => >0
test2 = prev3.saturating_sub(0xEF) # 1111xxxx => >0
result2 = (test1 | test2).gt(0) & vector(0x80)
# result1 0x80 , result2,
#
if result1 != result2:
return false
prev = input
return true
Si une séquence incorrecte se trouve sur le bord droit du tout dernier bloc, elle ne sera pas détectée par ce code. Afin de ne pas vous déranger, vous pouvez compléter la chaîne d'entrée avec zéro octet afin qu'à la fin, vous obteniez un bloc complètement nul. Au lieu de cela, simdjson a choisi d'implémenter une vérification spéciale pour les derniers octets: pour qu'une chaîne soit correcte, le tout dernier octet doit être strictement inférieur
0xC0
, l'avant-dernier octet strictement inférieur
0xE0
et le troisième à partir de la fin strictement inférieur
0xF0
.
La dernière des améliorations apportées par Lemierre et Kaiser est la coupure ASCII. Déterminer qu'il n'y a que des caractères ASCII dans le bloc actuel est très simple:
input & vector(0x80) == vector(0)
... Dans ce cas, il suffit de s'assurer qu'il n'y a pas de séquences incorrectes sur la frontière
prev
et
input
, - et vous pouvez passer au bloc suivant. Ce contrôle est effectué de la même manière qu'à la fin de la chaîne d'entrée; la comparaison vectorielle non signée avec
[..., 0x0, 0xE0, 0xC0]
, qui n'est pas disponible sur Intel, est remplacée par le calcul du vecteur maximum (
pmaxub
) et sa comparaison avec le même vecteur.
La vérification de l'ASCII s'avère être la seule branche à l'intérieur de l'itération du validateur, et pour réussir à prédire cette branche, il suffit que la chaîne d'entrée n'entrelace pas entièrement les blocs ASCII avec des blocs contenant des caractères non ASCII. Les chercheurs ont découvert que des résultats encore meilleurs sur des textes réels peuvent être obtenus en vérifiant la concaténation OU de quatre blocs adjacents pour l'ASCII et en sautant les quatre blocs dans le cas de l'ASCII. En effet, on peut s'attendre à ce que si l'auteur du texte, en principe, utilise des caractères non-ASCII, alors ils se produiront au moins une fois tous les 64 caractères, ce qui est suffisant pour prédire la transition.
