Il n'est généralement pas habituel de parler de telles erreurs, car seuls les célestes sans péché travaillent dans tous les intégrateurs. Comme vous le savez, au niveau de l'ADN, il n'y a aucune possibilité de se tromper ou de se tromper.
Mais je vais le risquer. J'espère que mon expérience sera utile à quelqu'un. Nous avons un client majeur, la vente au détail en ligne, pour lequel nous soutenons pleinement l'usine Cisco ACI. L'entreprise ne dispose pas de son propre administrateur compétent pour ce système. Une structure de réseau est un groupe de commutateurs qui ont un seul centre de contrôle. De plus, il existe de nombreuses fonctionnalités utiles dont le fabricant est très fier, mais au final, pour tout supprimer, vous avez besoin d'un administrateur, pas de dizaines. Et un centre de contrôle, pas des dizaines de consoles.
L'histoire commence ainsi: le client souhaite transférer le cœur de l'ensemble du réseau vers ce groupe de commutateurs. Cette décision est due au fait que l'architecture ACI, dans laquelle ce groupe de commutateurs est "collecté", est très tolérante aux pannes. Bien que ce ne soit pas typique et en général, une usine dans un centre de données n'est pas utilisée comme réseau de transit pour d'autres réseaux et sert uniquement à connecter la charge finale (réseau de tronçon). Mais une telle approche est tout à fait possible, donc le client veut - nous le faisons.
Puis une chose banale s'est produite - j'ai confondu deux boutons: supprimer la politique et supprimer la configuration d'un fragment du réseau:
Eh bien, alors, selon les classiques, il était nécessaire de réassembler une partie du réseau effondré.
En ordre
La demande du client ressemblait à ceci: il était nécessaire de construire des groupes de ports séparés pour le transfert des équipements directement vers cette usine.
Chers collègues, veuillez transférer les paramètres des ports Leaf 1-1 101 et Leaf 1-2 102, ports 43 et 44, vers Leaf 1-3 103 et leaf 1-4 104, ports 43 et 44. Vers les ports 43 et 44 sur Leaf 1- 1 et 1-2, la pile 3650 est connectée, elle n'a pas encore été mise en service, vous pouvez transférer les paramètres de port à tout moment.
Autrement dit, ils voulaient transférer le cluster de serveurs. Il était nécessaire de configurer un nouveau groupe de ports virtuels pour l'environnement serveur. En fait, il s'agit d'une tâche de routine; il n'y a généralement aucun temps d'arrêt de service pour une telle tâche. En substance, un groupe de ports dans la terminologie APIC est un VPC qui est assemblé à partir de ports physiquement situés sur différents commutateurs.
Le problème est qu'en usine, les paramètres de ces groupes de ports sont liés à une entité distincte (ce qui est dû au fait que l'usine est contrôlée à partir du contrôleur). Cet objet est appelé une stratégie de port. Autrement dit, au groupe de ports que nous ajoutons, nous devons également appliquer une politique générale d'en haut en tant qu'entité qui gérera ces ports.
Autrement dit, il était nécessaire d'analyser quels EPG sont utilisés sur les ports 43 et 44 sur les nœuds 101 et 102 afin d'assembler une configuration similaire sur les nœuds 103-104. Après avoir analysé les changements nécessaires, j'ai commencé à configurer les nœuds 103-104. Pour configurer un nouveau VPC dans la stratégie d'interface existante pour les nœuds 103 et 104, il était nécessaire de créer une stratégie dans laquelle les interfaces 43 et 44 seraient introduites.
Et il y a une nuance dans l'interface graphique. J'ai créé cette politique et réalisé que pendant le processus de configuration, j'ai fait une erreur mineure - je l'ai nommée différemment de la coutume du client. Ce n'est pas critique - car la politique est nouvelle et n'affecte rien. Et j'ai dû supprimer cette politique, car des modifications ne peuvent plus y être apportées (le nom ne change pas) - vous ne pouvez que supprimer et recréer la politique.
Le problème est que l'interface graphique a des icônes de suppression qui font référence aux stratégies d'interface, et il y a des icônes qui font référence aux stratégies de commutation. Visuellement, ils sont presque identiques. Et au lieu de supprimer la stratégie que j'ai créée, j'ai supprimé toute la configuration des interfaces sur les commutateurs 103-104: au
lieu de supprimer un groupe, j'ai en fait supprimé tous les VPC des paramètres de nœud, utilisé supprimer au lieu de poubelle.
Ces liens avaient des VLAN sensibles à l'entreprise. En fait, après avoir supprimé la config, j'ai désactivé une partie de la grille. De plus, cela n'a pas été immédiatement perceptible, car l'usine n'est pas contrôlée via le noyau, mais elle dispose d'une interface de gestion distincte. Je n'ai pas été expulsé tout de suite, il n'y a pas eu d'erreur dans l'usine car l'action a été prise par l'administrateur. Et l'interface pense - eh bien, si vous avez dit de supprimer, alors il devrait en être ainsi. Il n'y avait aucune indication d'erreurs. Le logiciel a décidé qu'une sorte de reconfiguration était en cours. Si l'administrateur supprime le profil feuille, alors pour l'usine, il cesse d'exister et il n'écrit pas d'erreur indiquant que cela ne fonctionne pas. Cela ne fonctionne pas - car il a été délibérément supprimé. Cela ne devrait pas fonctionner pour les logiciels.
Le logiciel a donc décidé que j'étais Chuck Norris et que je savais exactement ce que je faisais. Tout est sous contrôle. L'administrateur ne peut pas se tromper, et même lorsqu'il se tire une balle dans le pied, cela fait partie d'un plan rusé.
Mais après environ dix minutes, j'ai été expulsé du VPN, que je n'avais initialement pas associé à la configuration APIC. Mais c'est au moins suspect, et j'ai contacté le client pour clarifier ce qui se passait. Et pendant les minutes qui ont suivi, j'ai pensé que le problème était un travail technique, une pelle soudaine ou une panne de courant, mais pas la configuration d'usine.
Le réseau du client est complexe. Nous ne voyons qu'une partie de l'environnement par notre accès. Lors de la restauration d'événements, tout semble que le rééquilibrage du trafic a commencé, après quoi, après quelques secondes, le routage dynamique des systèmes restants n'a tout simplement pas été supprimé.
Le VPN que j'utilisais était le VPN administrateur. Les employés ordinaires se sont assis l'un sur l'autre, tout a continué à travailler pour eux.
En général, il a fallu quelques minutes de plus de négociations pour comprendre que le problème est toujours dans ma config. La première action dans une bataille dans une telle situation est de revenir aux configurations précédentes, puis de lire les journaux uniquement, car il s'agit de prod.
Restauration d'usine
Il a fallu 30 minutes pour restaurer l'usine - y compris tous les appels et rassembler toutes les personnes impliquées.
Nous avons trouvé un autre VPN que vous pouvez utiliser (cela nécessitait un accord avec les gardes de sécurité), et j'ai annulé la configuration d'usine - dans Cisco ACI, cela se fait en deux clics. Il n'y a rien de compliqué. Le point de restauration est simplement sélectionné. Cela prend 10 à 15 secondes. Autrement dit, la récupération elle-même a pris 15 secondes. Le reste du temps a été consacré à trouver comment obtenir la télécommande.
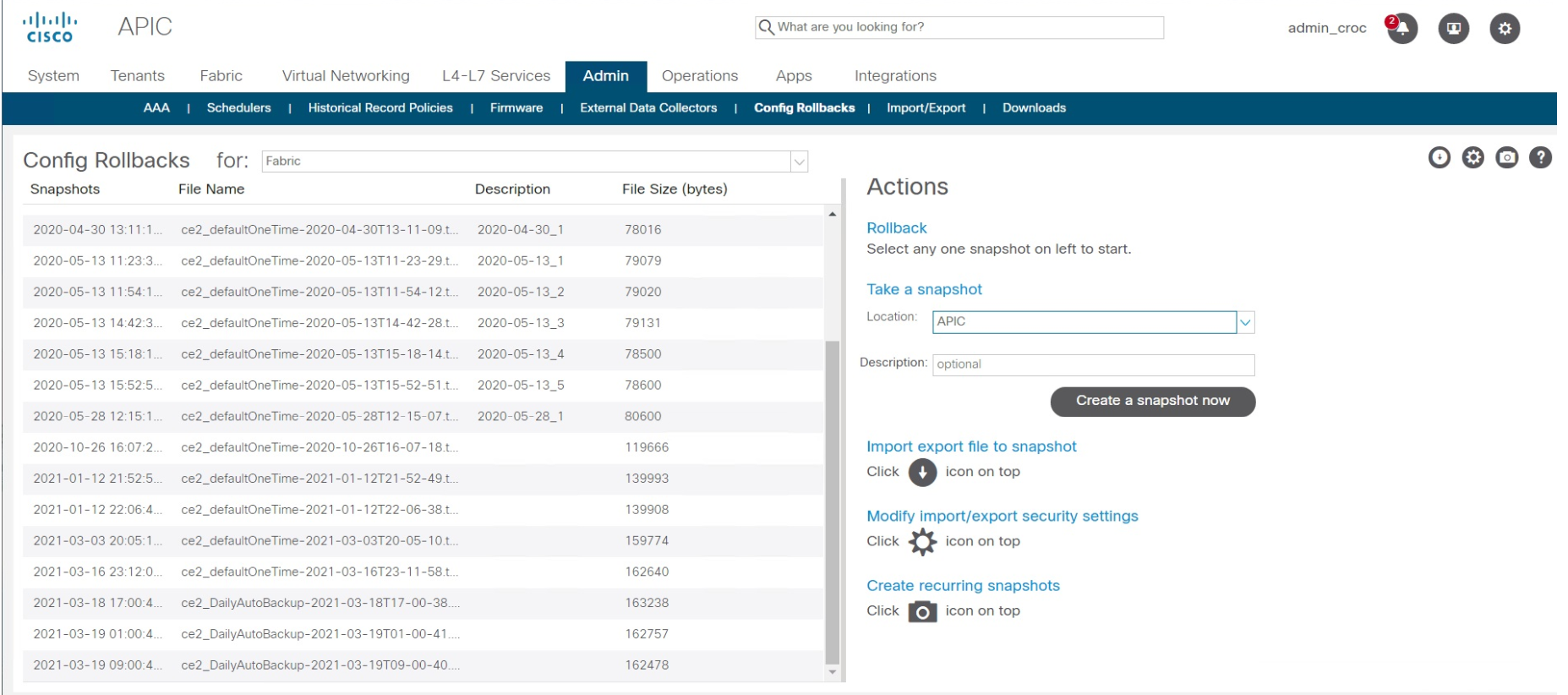
Après l'incident
Un autre jour, nous avons analysé les journaux et restauré la chaîne des événements. Ensuite, ils ont passé un appel avec le client, énoncé calmement l'essence et les causes de l'incident, proposé un certain nombre de mesures pour minimiser les risques de telles situations et le facteur humain.
Nous avons convenu de ne toucher aux configs de l'usine que pendant les heures creuses: la nuit et le soir. Nous travaillons avec une connexion à distance dupliquée (il y a des canaux VPN fonctionnels, il y en a de secours). Le client reçoit un avertissement de notre part et surveille à ce moment les services.
L'ingénieur (c'est-à-dire moi) est resté le même sur le projet. Je peux dire que le sentiment de confiance en moi est devenu encore plus grand qu'avant l'incident - je pense, précisément parce que nous avons rapidement travaillé sur la situation et n'avons pas laissé une vague de panique couvrir le client. L'essentiel est qu'ils n'ont pas essayé de cacher le joint. De la pratique, je sais que dans cette situation, il est plus facile d'essayer de passer au fournisseur.
Nous avons appliqué des politiques de mise en réseau similaires à d’autres clients externalisés: c’est plus difficile pour les clients (canaux VPN supplémentaires, changements d’administrateur supplémentaires pendant les heures creuses), mais beaucoup ont compris pourquoi cela était nécessaire.
Nous avons également approfondi le logiciel Cisco Network Assurance Engine (NAE), où nous avons trouvé l'opportunité de faire deux choses simples mais très importantes à l'usine ACI:
- Premièrement, le NAE nous permet d'analyser le changement prévu, avant même de le déployer dans l'usine et de tout filmer pour nous-mêmes, en prédisant comment le changement affectera positivement ou négativement la configuration existante;
- deuxièmement, le NAE, après le changement, vous permet de mesurer la température globale de l'usine et de voir comment ce changement a finalement affecté son état de santé.
Si vous êtes intéressé par plus de détails - demain, nous aurons un webinaire sur la cuisine interne du support technique, nous vous dirons comment tout fonctionne avec nous et avec les fournisseurs. Nous analyserons également les erreurs)