
Bonjour, Habr!
Dans cet article, nous examinerons quelques approches simples de prévision de séries chronologiques.
Le matériel présenté dans l'article, à mon avis, complète bien la première semaine du cours "Problèmes appliqués de l'analyse des données" du MIPT et de Yandex. Sur le cours indiqué, vous pouvez acquérir des connaissances théoriques suffisantes pour résoudre les problèmes de prédiction de la série de dynamiques, et comme consolidation pratique du matériau, il est proposé d'utiliser le modèle ARIMA de la bibliothèque scipy pour générer une prévision de salaire en russe Fédération pour l'année à venir. Dans l'article, nous allons également générer une prévision de salaire, mais en même temps, nous n'utiliserons pas la bibliothèque scipy , mais la bibliothèque sklearn . L'astuce est que scipy a déjà un modèle ARIMA , mais sklearn n'a pas de modèle prêt à l'emploi, nous devons donc travailler dur avec des stylos. Ainsi, pour résoudre le problème, dans un sens, nous devrons comprendre comment le modèle fonctionne de l'intérieur. De plus, en tant que matériau supplémentaire, dans l'article, le problème de prédiction est résolu en utilisant un réseau neuronal monocouche de la bibliothèque pytorch .
Tout le code est écrit en python 3 dans le notebook jupyter . De plus, le cahier est conçu de telle manière qu'au lieu des données sur les salaires, vous pouvez remplacer de nombreuses autres séries de dynamiques, par exemple des données sur les prix du sucre, modifier la période de prévision, de validation et de formation, ajouter d'autres facteurs externes et former un prévision appropriée. En d'autres termes, un simple simulateur auto-écrit est utilisé dans le travail, à l'aide duquel il est possible de prédire diverses séries de dynamiques. Le code peut être consulté ici
Aperçu de l'article
- Brève description du simulateur.
- Une solution frontale consiste à prévoir des séries chronologiques en utilisant uniquement les données «brutes» des valeurs passées des séries chronologiques.
- Ajout de variables exogènes.
- Correction de l'hétéroscédasticité par le logarithme des données initiales.
- Amener la ligne à une ligne stationnaire.
- Prévision avec un réseau neuronal monocouche.
- Comparaison des approches.
- Liens utiles
Brève description du simulateur
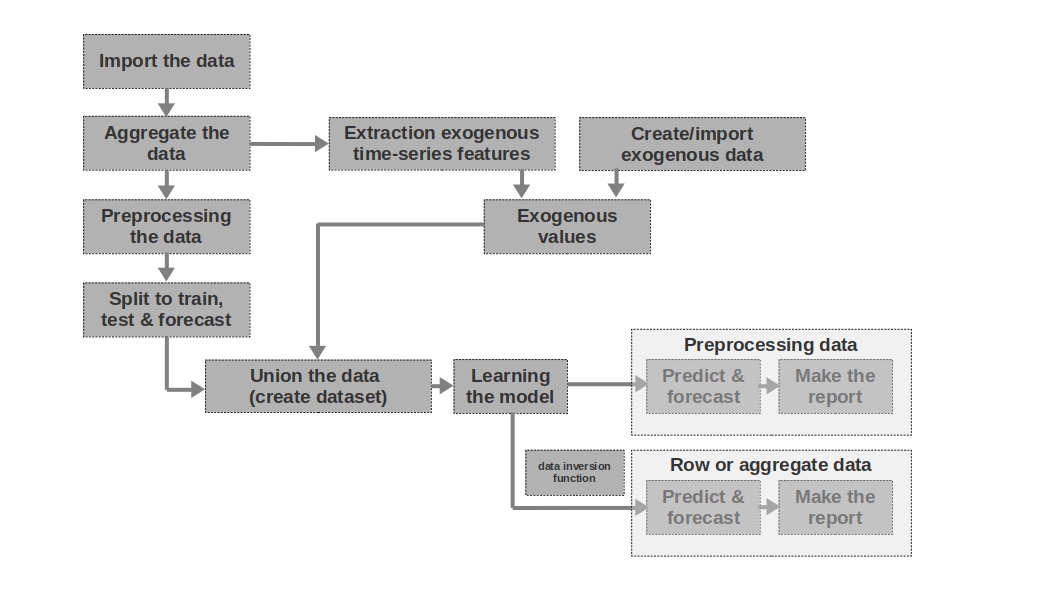
Importez les données
Ici, tout est simple - nous importons les données. Parfois, il arrive que les données brutes suffisent à former une prévision plus ou moins intelligible. Ce sont les première et deuxième prévisions de l'article qui sont modélisées sur la base de données brutes, c'est-à-dire que les données brutes sur les salaires des périodes passées sont utilisées pour prévoir les salaires.
Agréger les données
L'article n'utilise pas l'agrégation de données car elle n'est pas nécessaire. Cependant, les données peuvent souvent être présentées à des intervalles de temps inégaux. Dans ce cas, il vous suffit de les agréger. Par exemple, les données relatives aux opérations sur titres, devises et autres instruments financiers doivent être agrégées. Habituellement, la valeur moyenne de l'intervalle est prise, mais le maximum, le minimum, l'écart type et d'autres statistiques sont également possibles.
Prétraitement des données
Dans notre cas, nous parlons principalement de prétraitement des données, grâce auquel la série temporelle acquiert la propriété d'homoscédasticité (par le logarithme des données) et devient stationnaire (par la différenciation de la série).
Split pour former, tester et prévoir
Dans ce bloc de code, la série temporelle est divisée en périodes d'apprentissage, de test et de prévision en ajoutant une nouvelle colonne avec les valeurs correspondantes «train», «test», «prévision». Autrement dit, nous ne créons pas trois tableaux séparés pour chaque période, mais ajoutons simplement une colonne, sur la base de laquelle nous diviserons davantage les données.
Extraction de caractéristiques de séries chronologiques exogènes
Il peut être utile d'isoler d'autres caractéristiques externes (exogènes) d'une série chronologique. Par exemple, indiquez s'il s'agit d'un jour de congé ou non, indiquez le nombre de jours dans un mois (ou le nombre de jours ouvrables dans un mois), etc. En règle générale, ces signes sont "retirés" de la série chronologique lui-même sans aucune intervention manuelle.
Créer / importer des données exogènes
Toutes les informations ne peuvent pas être «extraites» de la série chronologique. Parfois, des données externes supplémentaires peuvent être nécessaires. Par exemple, certains événements épisodiques qui ont un fort impact sur les valeurs de la série chronologique. Ces événements peuvent être les dates du début des hostilités, l’imposition de sanctions, les catastrophes naturelles, etc. Les travaux ne tiennent pas compte de ces facteurs, mais il convient de garder à l’esprit la possibilité de les utiliser.
Valeurs exogènes
Dans ce bloc de code, nous combinons toutes les données exogènes dans une table.
Union des données (créer un jeu de données)
Dans ce bloc de code, nous combinons les valeurs de la série chronologique et des entités exogènes dans une table. En d'autres termes, nous préparons un ensemble de données sur la base duquel nous formerons le modèle, testerons la qualité et formerons une prévision.
Apprendre le modèle
Tout est clair ici - nous ne faisons que former le modèle.
Prétraitement des données: prédire et prévoir
Si nous avons utilisé des données prétraitées pour l'apprentissage du modèle (logarithmique, traitées par la fonction box-coke, série stationnaire, etc.), alors la qualité du modèle est d'abord évaluée sur les données prétraitées et uniquement puis sur les données "brutes". Si nous n'avons pas prétraité les données, cette étape est ignorée.
Données de ligne: prédire et prévoir
Cette étape est la dernière. Si le modèle était formé sur des données prétraitées, par exemple, nous les prologions, alors pour obtenir la prévision des salaires en roubles, et non le logarithme des roubles, nous devrions traduire la prévision en roubles.
Je voudrais également noter que l'article utilise une série chronologique unidimensionnelle pour prédire les salaires. Cependant, rien ne vous empêche d'utiliser une série multidimensionnelle, par exemple en ajoutant des données sur le taux de change du rouble au dollar ou à une autre série.
Décision au front
Nous supposerons que les données sur les salaires dans le passé peuvent se rapprocher des salaires dans le futur. En d'autres termes, la taille des salaires, par exemple, en janvier dépend de ce que les salaires étaient en décembre, novembre, octobre, ...
Prenons les valeurs des salaires des 12 derniers mois pour prédire les salaires du 13e mois. En d'autres termes, pour chaque valeur cible, nous aurons 12 fonctionnalités.
Les signes seront envoyés à l'entrée Ridge Regression de la bibliothèque sklearn. Nous prenons les paramètres par défaut du modèle, à l'exception du paramètre alpha, il a été mis à 0, c'est-à-dire que nous utilisons une régression régulière.
C'est une solution simple - c'est la plus simple :) Il y a des situations où vous devez donner au moins un résultat très urgent, mais il n'y a tout simplement pas de temps pour un prétraitement ou il n'y a pas assez d'expérience pour traiter ou ajouter rapidement des données. Dans de telles situations, vous pouvez utiliser des données brutes comme base de référence pour créer une prévision. Pour l'avenir, je note que la qualité du modèle s'est avérée comparable à la qualité des modèles qui utilisent le prétraitement des données.
Voyons ce que nous avons.
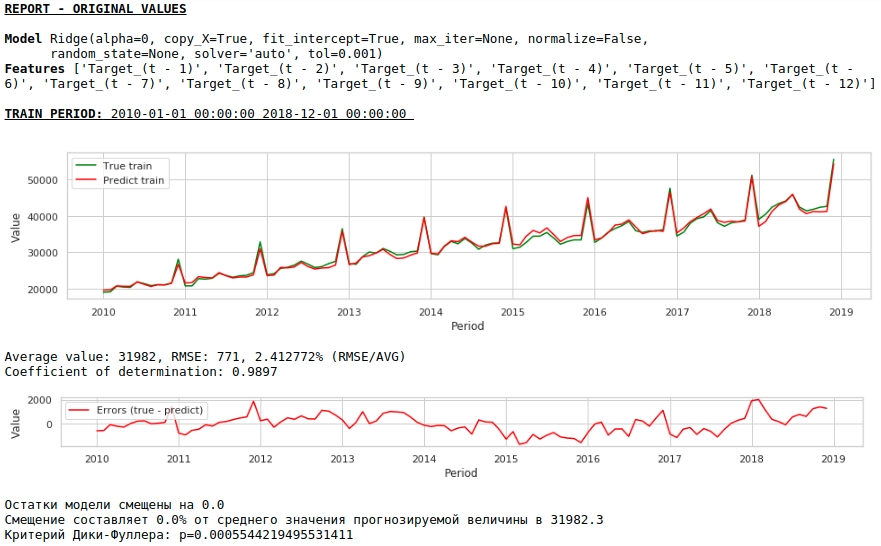
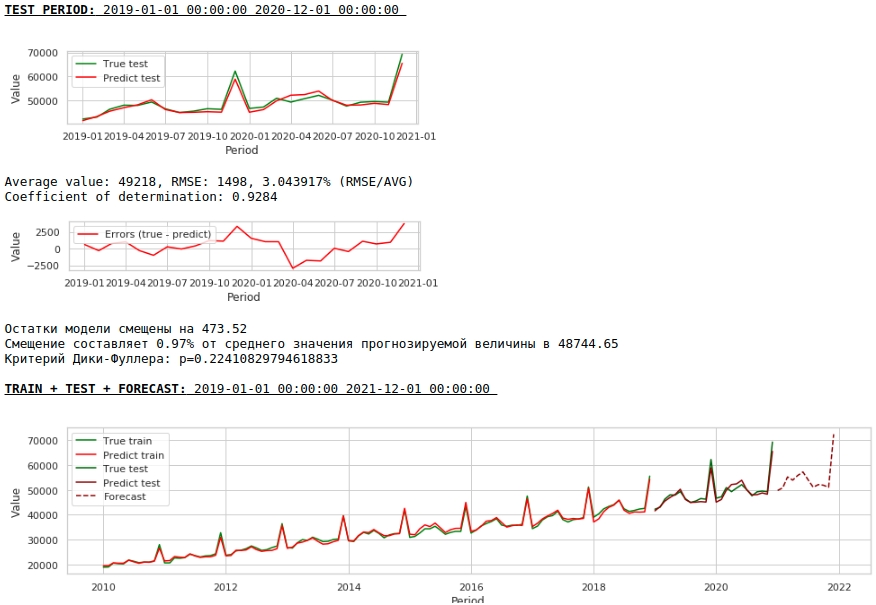
À première vue, le résultat semble, bien qu'imparfait, mais proche de la réalité.
Conformément aux valeurs des coefficients de régression, la valeur du salaire a la plus grande influence sur la prévision des salaires il y a exactement un an.
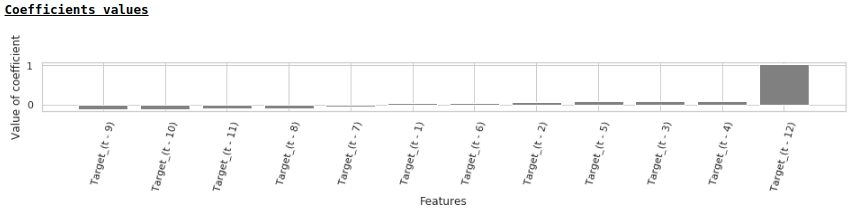
Essayons d'ajouter des variables exogènes au modèle.
Ajout de variables exogènes
Nous utiliserons 2 signes externes: le nombre de jours dans un mois et le numéro du mois (de 1 à 12). Nous binarisons l'attribut "Numéro du mois", en conséquence nous obtenons 12 colonnes pour chaque mois avec des valeurs de 0 ou 1.
Formons un nouvel ensemble de données et regardons la qualité du modèle.
Regarder les graphiques
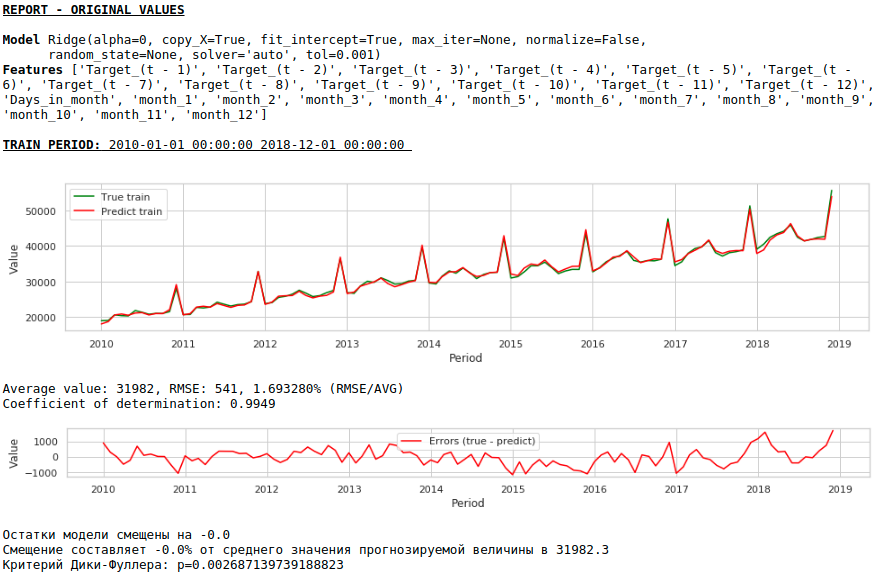
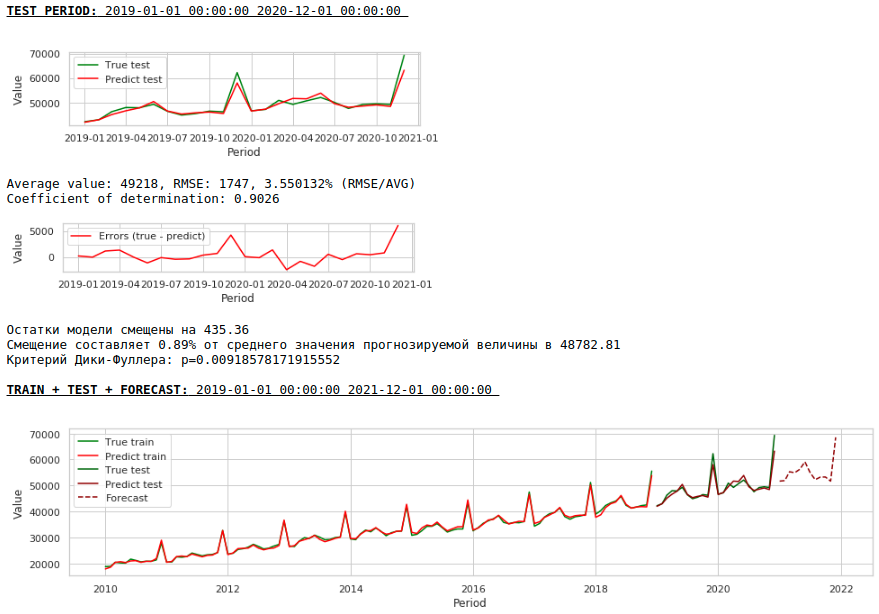
La qualité est inférieure. Visuellement, il est à noter que la prévision ne semble pas tout à fait plausible en termes de croissance des salaires en décembre.
Faisons maintenant le premier prétraitement des données.
Correction de l'hétéroscédasticité.
Si nous regardons le graphique des salaires pour la période de 2010 à 2020, nous pouvons voir que la répartition des salaires au sein de l'année entre les mois augmente chaque année.
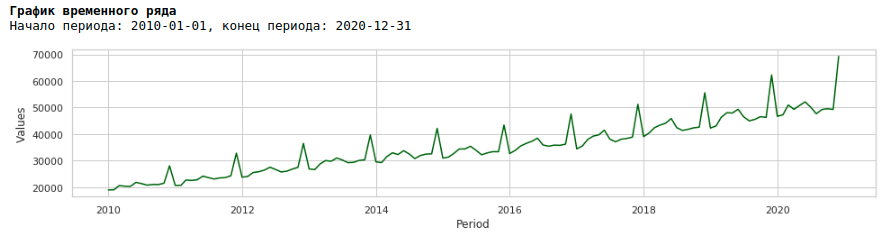
Une augmentation annuelle de la variance d'un mois à l'autre conduit à une hétéroscédasticité. Pour améliorer la qualité des prévisions, il faut se débarrasser de cette propriété des données et les amener à l'homoscédasticité.
Pour ce faire, nous utiliserons le logarithme habituel et verrons à quoi ressemble la série logarithmique.
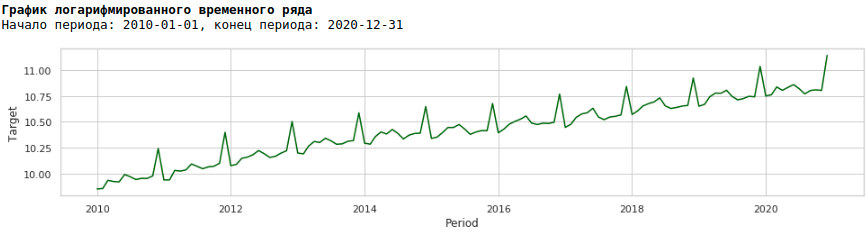
Entraînons le modèle sur la série logarithmique
Regarder les graphiques
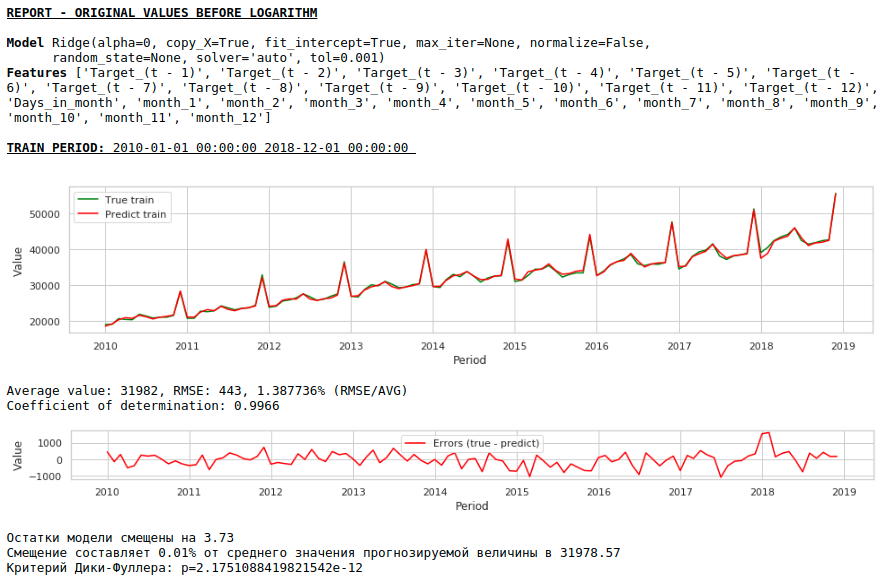
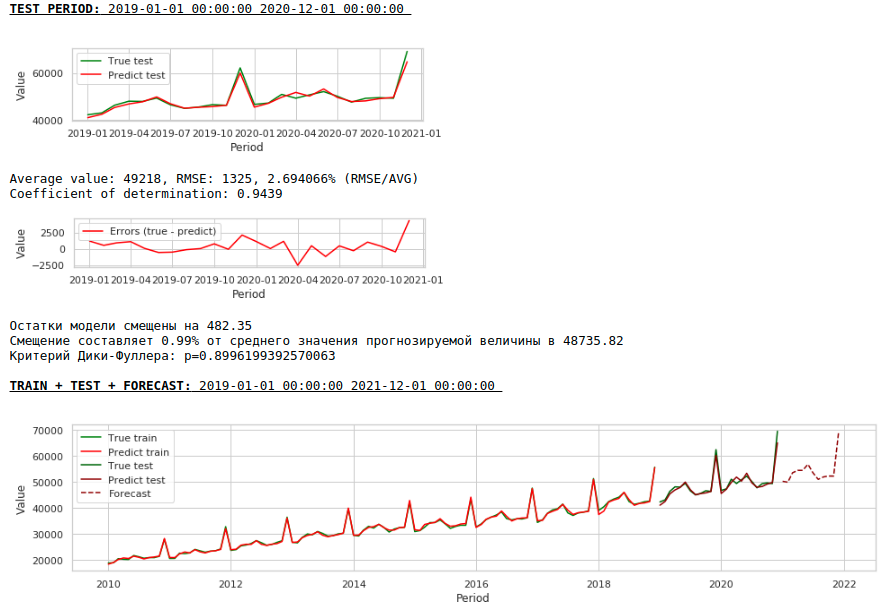
En conséquence, la qualité des prédictions sur les échantillons de formation et de test s'est améliorée, cependant, la prévision pour 2021 semble visuellement moins plausible par rapport à la prévision du premier modèle. Très probablement, l'utilisation de facteurs exogènes dégrade le modèle.
Amener une rangée à un stationnaire
Nous réduirons la série à une série stationnaire comme suit:
- Déterminez la différence entre la valeur salariale cible et la valeur il y a un an: t - (t-12) = dif_1
- Déterminez la différence entre la valeur reçue et décalée d'un mois: dif_1 - (dif_1-1) = dif_2
En conséquence, nous obtenons la série chronologique suivante.
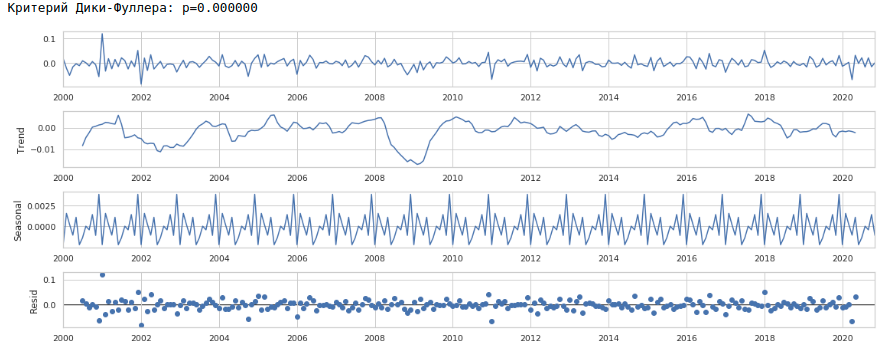
La série semble vraiment stationnaire, cela est également indiqué par la valeur du critère Dickey-Fuller.
Il n'est pas nécessaire de s'attendre à une bonne qualité de prédictions sur les échantillons d'apprentissage et de test sur les données traitées, c'est-à-dire sur une série stationnaire, car en fait, dans ce cas, le modèle doit prédire les valeurs du bruit blanc. Mais pour nous, pour prédire les salaires, il n'est pas du tout nécessaire d'utiliser la régression, car, en réduisant la série à une série stationnaire, nous avons, en termes simples, déterminé une formule d'approximation de la variable cible. Mais nous ne dévierons pas des canons et utiliserons un modèle de régression, en plus, nous avons des facteurs exogènes.
Voyons ce qui se passe.
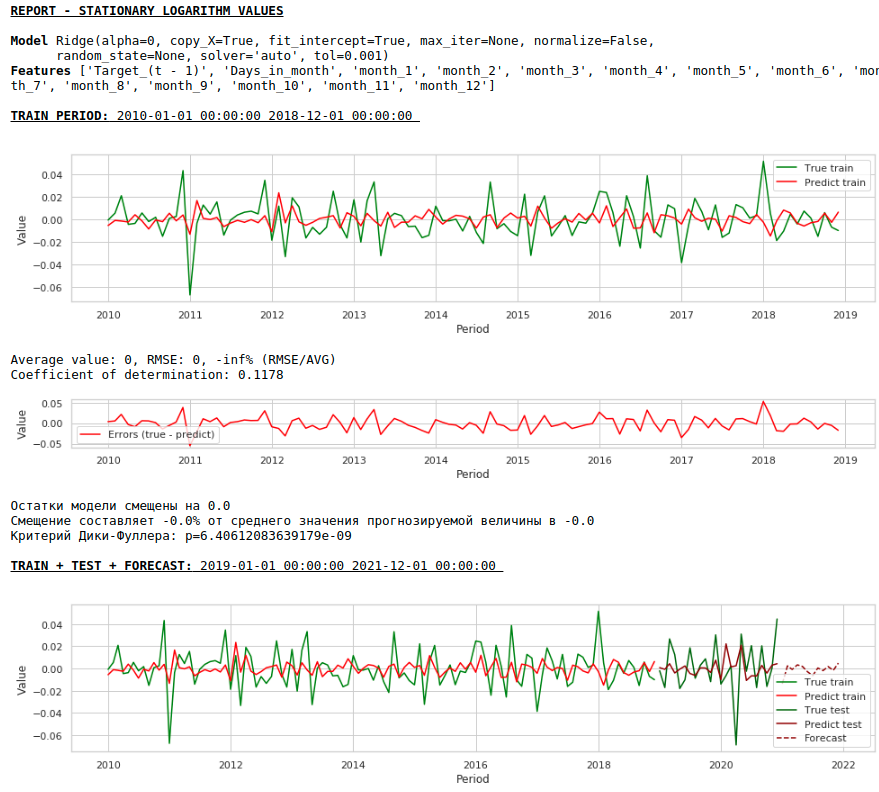
Voici à quoi ressemble la prédiction d'une série stationnaire. Comme prévu - pas très bon :)
Et voici la prédiction et la prévision des salaires.
Regarder les graphiques
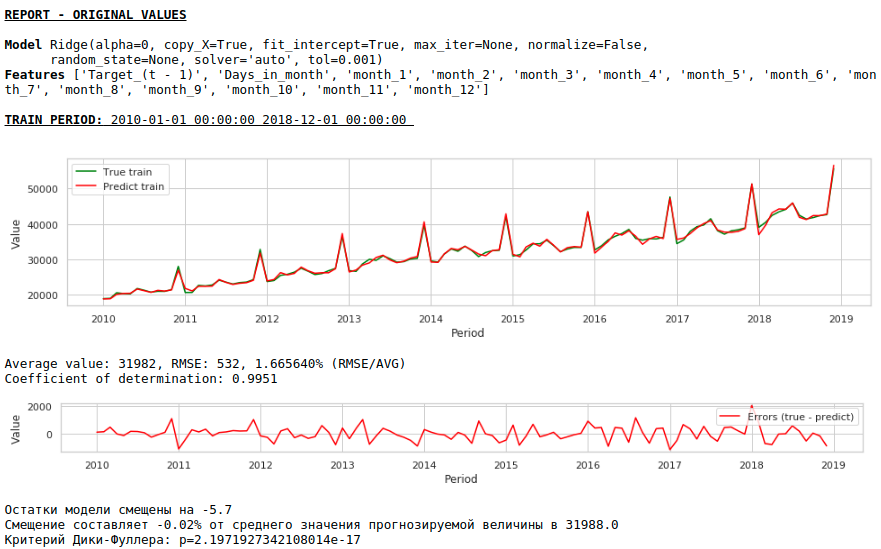
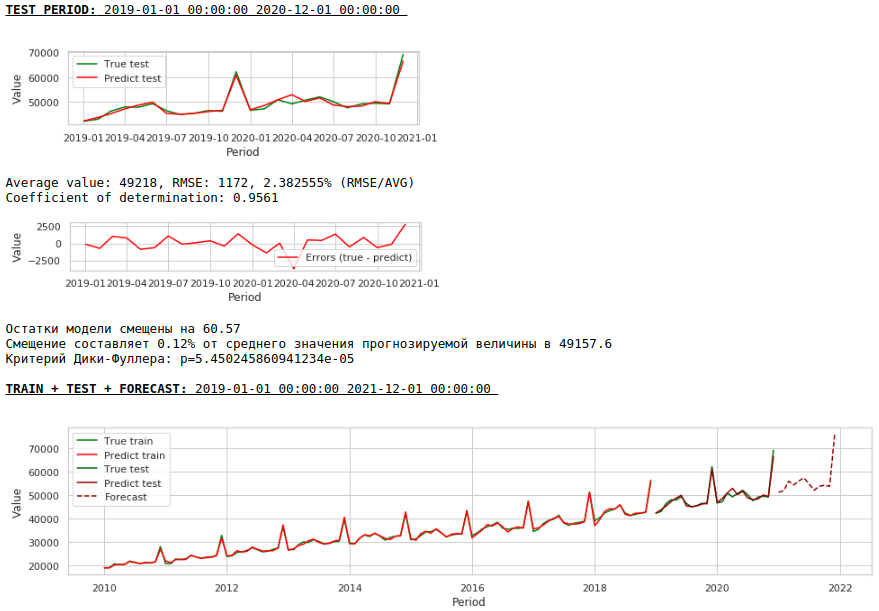
La qualité s'est nettement améliorée et les prévisions sont visuellement crédibles.
Faisons maintenant une prévision sans utiliser de variables exogènes.
Regarder les graphiques
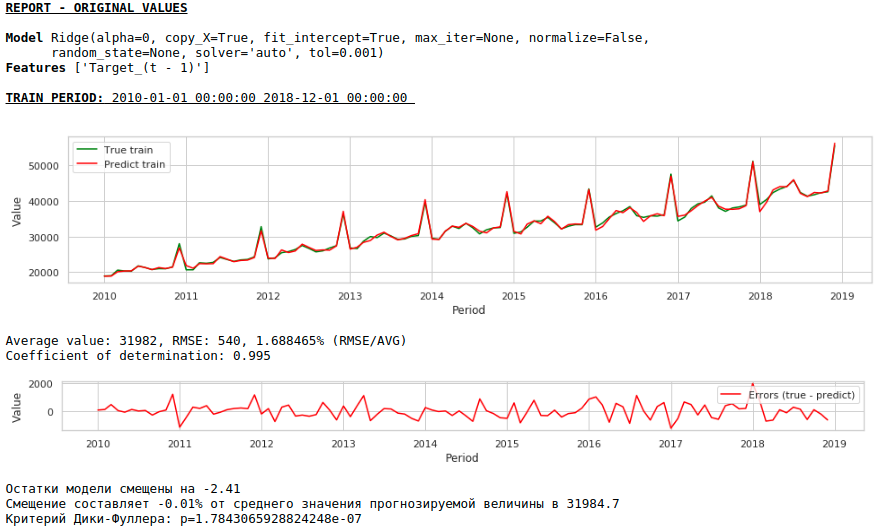
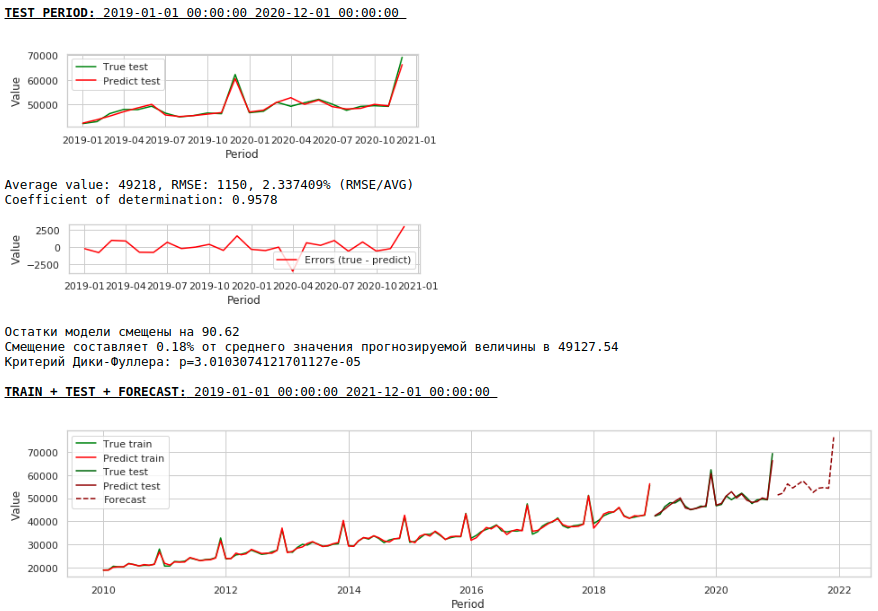
La qualité s'est encore améliorée et la plausibilité des prévisions est préservée :)
Prévision avec un réseau neuronal monocouche
Nous alimenterons les ensembles de données existants à l'entrée du réseau neuronal. Puisque notre réseau est monocouche, il s'agit en fait de la même régression linéaire avec de simples modifications et il ne faut pas s'attendre à une très grande différence dans la qualité des prédictions.
Tout d'abord, regardons le réseau lui-même.
Voir le code
class Model_1(nn.Module):
def __init__(self, input_size, output_size):
super(Model_1, self).__init__()
self.input_size = input_size
self.output_size = output_size
self.linear = nn.Linear(self.input_size, self.output_size)
def forward(self, x):
output = self.linear(x)
return output
Maintenant, quelques mots sur la façon dont nous allons la former.
- Nous fixons une graine aléatoire dans un but de reproductibilité du résultat
- Initialisation du modèle
- Réglage de la fonction de perte - MSELoss
- Sélection de l'optimiseur Adam comme optimiseur
- Nous indiquons l'étape initiale de la formation et déterminons la condition dans laquelle la marche est abaissée. Notez que le choix correct d'une étape et sa modification ultérieure (généralement une diminution) donnent de bons résultats.
- Spécifiez le nombre d'époques d'apprentissage
- Nous commençons la formation
- Nous fournissons l'ensemble de données à l'entrée du réseau, car il est très petit et cela n'a aucun sens de le diviser en lots
- Pendant l'entraînement, toutes les mille époques, nous formons des graphiques de la valeur de la fonction de perte sur les échantillons d'apprentissage et de test. Cela nous permet de contrôler le surajustement ou le non-recyclage du modèle.
Vous trouverez ci-dessous le code pour entraîner le réseau sur le premier ensemble de données. Pour chaque jeu de données, les paramètres ont légèrement changé: le nombre d'époques d'apprentissage et l'étape d'apprentissage.
Voir le code
# fix the random seed
SEED = 42
random_init(SEED)
# initialization model, loss function, optimizator
model = Model_1(len(features),1)
loss_func = nn.MSELoss()
opt = torch.optim.Adam(model.parameters(), lr=5e-2)
# set the epoch numbers, initialization list for every loss after learning on epoch
epochs = 15000
losses_train = []
losses_test = []
# initialization counter for calculation epoch numbers
counter = 0
# start the learning model
for epoch in range(epochs):
model.train()
# make prediction targets on train data
y_pred_train = model(torch.tensor(X_train.to_numpy(), dtype=torch.float))
# calculate loss
loss = loss_func(y_pred_train,
torch.reshape(torch.tensor(y_train.to_numpy(), dtype=torch.float),(-1,1)))
# bacward loss to model and calculate new parameters (coefficients) with fixed learning rate
loss.backward()
opt.step()
opt.zero_grad()
# add loss to list losses
losses_train.append(loss)
model.eval()
y_pred_test = model(torch.tensor(X_test.to_numpy(), dtype=torch.float))
loss_test = loss_func(y_pred_test,
torch.reshape(torch.tensor(y_test.to_numpy(), dtype=torch.float),(-1,1)))
losses_test.append(loss_test)
# make the mini report for every 1000 epoch
if epoch % 1000 == 0 and epoch > 0:
print ('Epoch:', epoch // 1000)
print ('Learning rate:', opt.param_groups[0]['lr'])
print ('Last loss on TRAIN data:', losses_train[-1].cpu().detach().numpy(),
' Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
# print ('Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
fig, (ax1, ax2) = plt.subplots(1, 2)
# fig.suptitle('MSE on TRAIN & TEST DATA')
fig.set_figheight(3)
fig.set_figwidth(12)
ax1.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_train][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TRAIN data")
ax2.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_test][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TEST data")
plt.show()
counter += 1000
# reduce learning rate
if epoch == 1000:
opt = torch.optim.Adam(model.parameters(), lr=7e-3)
Nous ne considérerons pas la qualité des prédictions pour chaque ensemble de données séparément (ceux qui le souhaitent peuvent voir les détails sur la gita). Comparons les résultats finaux.
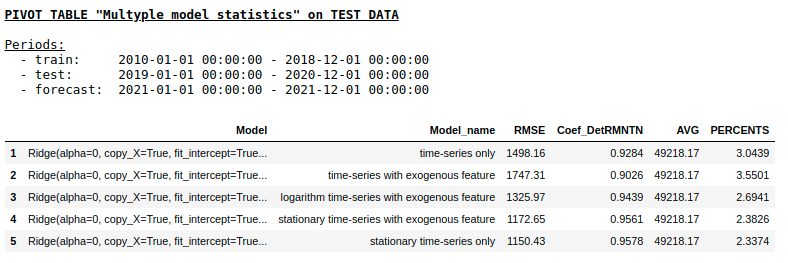
Qualité sur un échantillon de test à l'aide de la régression de crête
Qualité sur un échantillon de test à l'aide de NN monocouche
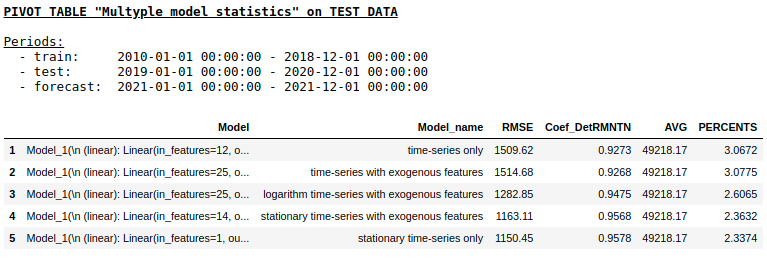
Comme nous nous y attendions, il n'y avait pas de différence fondamentale entre la régression régulière et un simple réseau neuronal monocouche. Bien sûr, les neurones offrent plus de manœuvre pour l'apprentissage: vous pouvez changer les optimiseurs, ajuster les étapes d'apprentissage, utiliser des couches cachées et des fonctions d'activation, vous pouvez aller encore plus loin et utiliser des réseaux de neurones récurrents - les RNN. À propos, personnellement, je n'ai pas pu obtenir une qualité raisonnable dans ce problème en utilisant RNN, cependant, sur Internet, vous pouvez trouver de nombreux exemples intéressants de prévisions de séries chronologiques à l'aide de LSTM.
À ce stade, l'article a pris fin. J'espère que le matériel sera utile comme une sorte de vue d'ensemble des approches de base utilisées dans la prévision des séries chronologiques et servira de bon complément pratique au cours "Problèmes appliqués de l'analyse des données" du MIPT et de Yandex.
Liens utiles
- Sources sur github
- Cours "Problèmes appliqués de l'analyse des données" du MIPT et Yandex
- Statistiques d'État "EMISS" (données sur les salaires)
- LSTM pour la prédiction de séries chronologiques
- Cours 9. Prévisions basées sur un modèle de régression. Centre d'informatique
- La photo sous le titre est prise d'ici :)