Aujourd'hui, je vais vous dire pourquoi la livraison externalisée n'est pas toujours bonne, pourquoi vous avez besoin de transparence des processus et comment nous avons écrit une plate-forme en un an et demi qui aide nos coursiers à livrer les commandes. Je partagerai également trois histoires du monde du développement.

Sur la photo, l'équipe de la plate-forme de messagerie il y a dix mois. À cette époque, elle était placée dans une pièce. Maintenant, nous sommes 5 fois plus nombreux.
Pourquoi avons-nous fait tout cela
Lors du développement de la plate-forme de messagerie, nous voulions mettre à niveau trois éléments principaux.
Le premier est la qualité . Lorsque nous travaillons avec des services de livraison externes, la qualité ne peut être contrôlée. L'entreprise contractante promet qu'il y aura telle ou telle délivrabilité, mais un certain nombre de commandes peuvent ne pas être livrées. Et nous voulions réduire au minimum le pourcentage de retards, afin que presque toutes les commandes soient livrées à temps.
La deuxième est la transparence... Quand quelque chose ne va pas (il y a des transferts, des délais), alors nous ne savons pas pourquoi ils se sont produits. Nous ne pouvons pas aller dire: "Les gars, faisons-le comme ça." Nous ne voyons pas nous-mêmes et nous ne pouvons pas montrer d'autres choses au client. Par exemple, que la commande n'arrivera pas à huit heures, mais dans les 15 minutes. C'est parce qu'il n'y a pas un tel niveau de transparence dans le processus.
Le troisième est l'argent... Lorsque nous travaillons avec un entrepreneur, il existe un contrat qui précise les montants. Et nous pouvons changer ces chiffres dans le cadre du contrat. Et lorsque nous sommes responsables de l'ensemble du processus de a à z, vous pouvez voir quelles parties du système sont conçues économiquement non rentables. Et vous pouvez, par exemple, modifier le fournisseur SMS ou le format du flux de documents. Ou vous remarquerez peut-être que les coursiers ont un kilométrage trop élevé. Et si vous construisez des itinéraires de plus près, vous pourrez finalement livrer plus de commandes. Grâce à cela, vous pouvez également économiser de l'argent - la livraison deviendra plus efficace.
Ce sont les trois objectifs que nous nous sommes fixés à la tête de tout.
À quoi ressemble la plateforme
Voyons ce que nous avons.
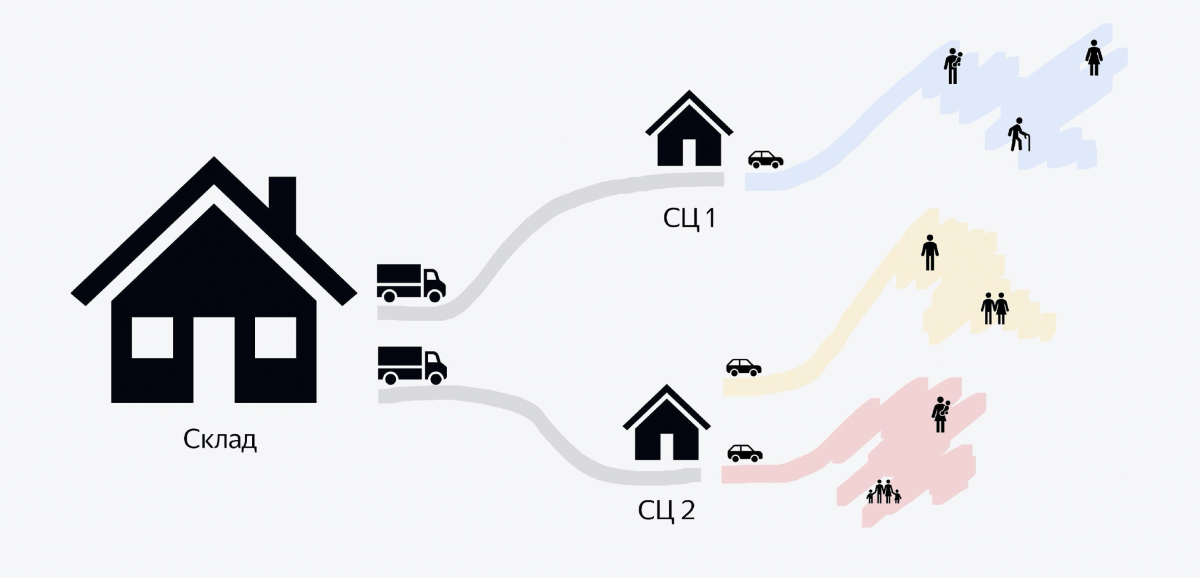
L'image montre un diagramme du processus. Nous avons de grands entrepôts qui contiennent des centaines de milliers de commandes. Des camions remplis à ras bord de commandes quittent chaque entrepôt le soir. Il peut y avoir 5 à 6 000 commandes. Ces camions se déplacent vers des bâtiments plus petits appelés centres de tri. En eux, en quelques heures, un gros tas de commandes se transforme en petits tas pour les courriers. Et lorsque les coursiers arrivent en voiture le matin, chaque coursier sait qu'il doit en ramasser un paquet avec ce code QR, le charger dans sa voiture et aller livrer.
Et le backend dont je veux parler dans cet article concerne la toute dernière partie du processus lorsque les commandes sont transmises aux clients. Tout ce qui est avant cela, pour le moment, nous allons laisser de côté.
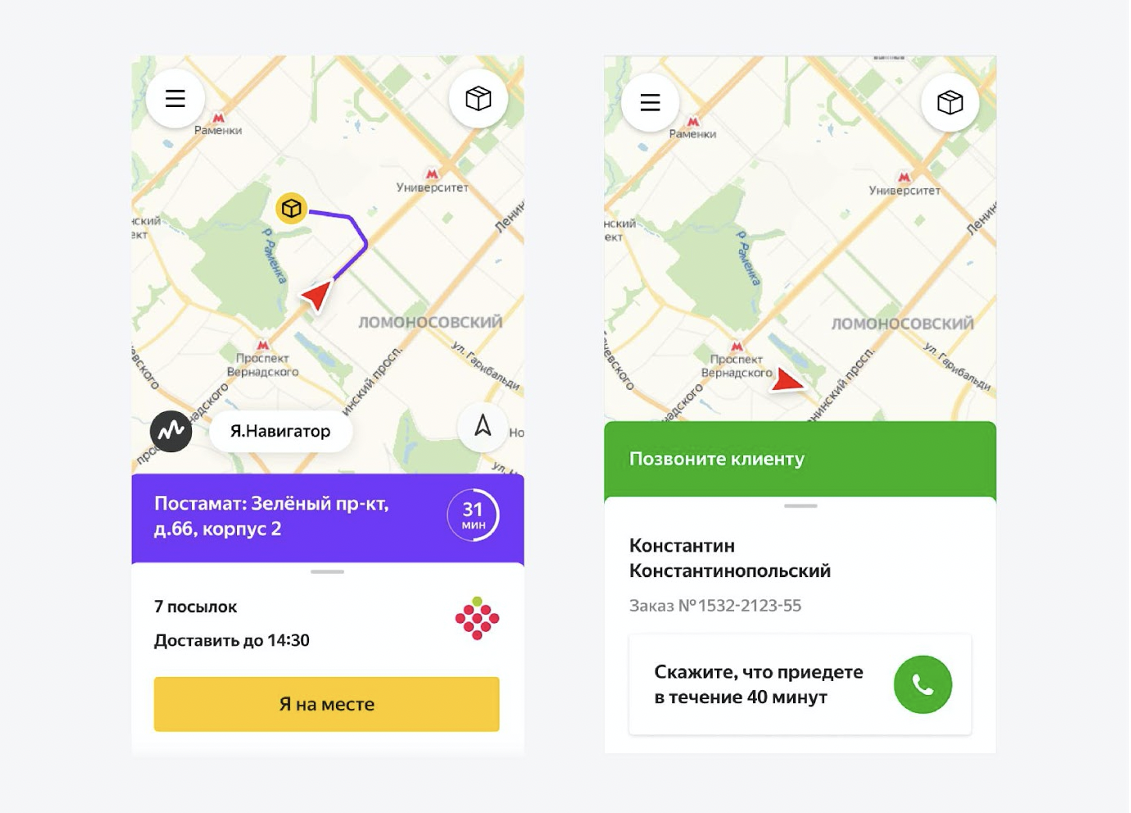
Comment le courrier le voit Les
courriers ont une application Android écrite en React Native. Et dans cette application, ils voient leur journée entière. Ils comprennent clairement la séquence: à quelle adresse aller en premier, laquelle plus tard. Quand appeler un client, quand récupérer les retours au centre de tri, comment commencer la journée, comment y mettre fin. Ils voient tout dans l'application et ne posent pratiquement pas de questions inutiles. Nous les aidons beaucoup. Fondamentalement, ils ne font que des missions.
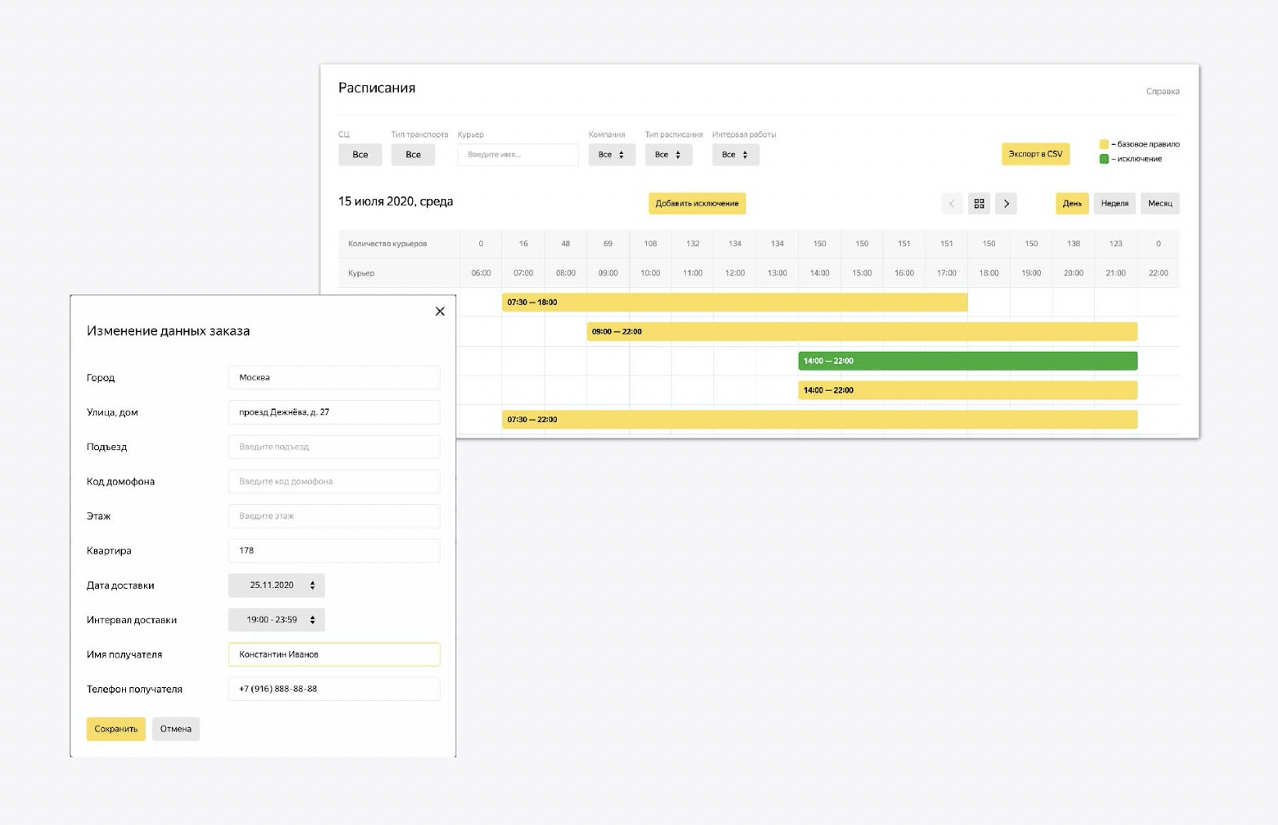
De plus, il y a des contrôles sur la plateforme. Il s'agit d'un panneau d'administration multifonctionnel que nous avons réutilisé à partir d'un autre service Yandex. Dans cette zone d'administration, vous pouvez configurer l'état du système. Nous y téléchargeons des données sur les nouveaux courriers, modifions les intervalles de travail. Nous pouvons ajuster le processus de création de tâches pour demain. Presque tout ce dont vous avez besoin est réglementé.
Au fait, à propos du backend. Sur le marché, nous aimons beaucoup Java, principalement la version 11. Et tous les services backend, dont nous parlerons, sont écrits en Java.
Architecture
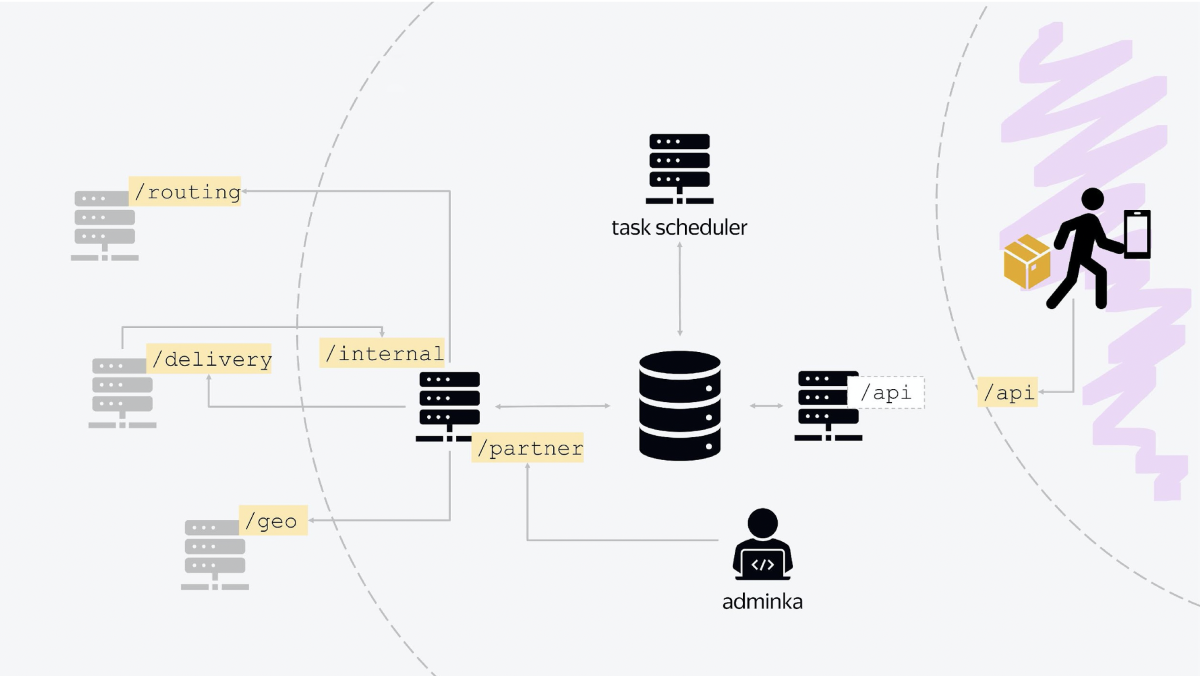
Il existe trois nœuds principaux dans l'architecture de notre plateforme. Le premier est responsable de la communication avec le monde extérieur. L'application de messagerie «frappe» sur l'équilibreur, qui est sorti, communiquant avec lui à l'aide de l'API HTTP JSON standard. En fait, ce nœud est responsable de toute la logique de la journée actuelle, lorsque les courriers transfèrent quelque chose, annulent quelque chose, émettent des commandes, reçoivent de nouvelles tâches.
Le deuxième nœud est un service qui communique avec les services internes de Yandex. Tous les services sont des services RESTful classiques avec une communication standard. Lorsque vous passez une commande sur le Marché, après un certain temps, un document au format JSON vous parviendra, où tout sera écrit: quand nous livrons, à qui nous livrons, à quel intervalle. Et nous enregistrerons cet état dans la base de données. C'est simple.
De plus, le deuxième nœud communique également avec d'autres services internes, non pas Market, mais Yandex. Par exemple, pour clarifier les géocoordonnées, nous allons au géoservice. Pour envoyer une notification push, nous allons vers le service qui envoie des push et des SMS. Nous utilisons un autre service pour l'autorisation. Un autre service de calcul d'itinéraire pour demain. Ainsi, toutes les communications avec les services internes sont effectuées.
Ce nœud est également un point d'entrée, il dispose d'une API sur laquelle s'appuie notre panneau d'administration. Il a son propre point de terminaison, qui est appelé, par exemple, / partner. Et notre panneau d'administration, l'état complet du système, est configuré via la communication avec ce service.
Le troisième nœud est la base des tâches d'arrière-plan. Ici Quartz 2 est utilisé, il y a des tâches qui sont lancées sur la couronne avec des conditions différentes pour différents points, pour différents centres de tri. Il y a des tâches de mise à jour de la journée, des tâches de fermeture de la journée, de démarrage d'une nouvelle journée.
Et au centre de tout se trouve la base de données, qui, en fait, stocke tout l'état. Tous les services sont inclus dans une seule base de données.
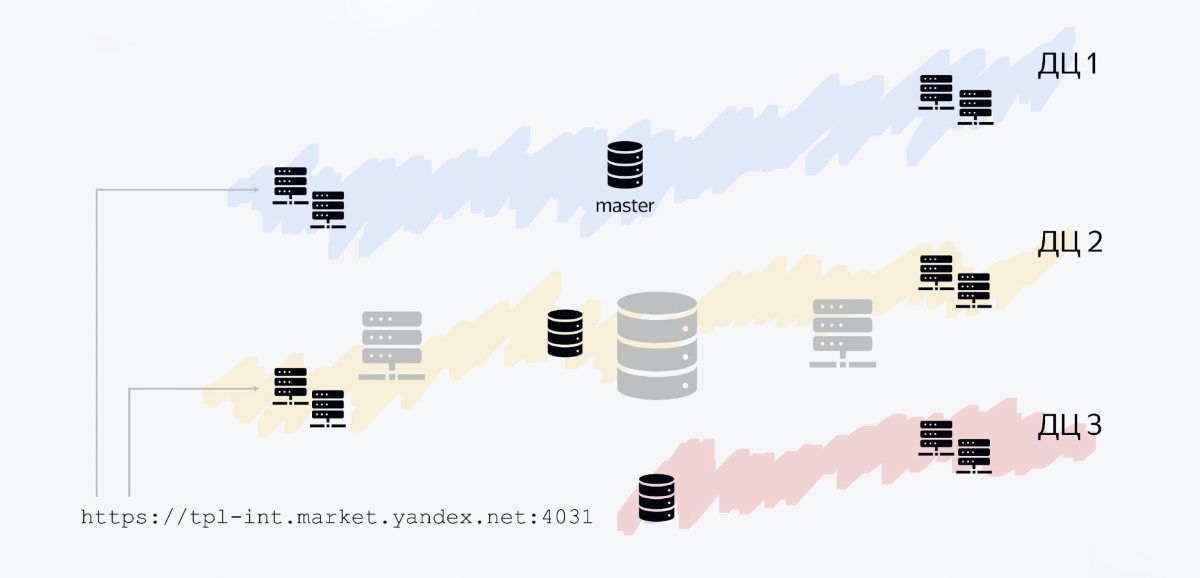
tolérance aux pannes
Yandex dispose de plusieurs centres de données et notre service est distribué au niveau régional dans trois centres de données. À quoi il ressemble.
La base de données se compose de trois hôtes, chacun dans son propre centre de données. Un hôte est le maître, les deux autres sont des répliques. Nous écrivons au maître, nous lisons à partir des lignes. Tous les autres services Java sont également des processus Java qui s'exécutent dans plusieurs centres de données.
L'un des nœuds est notre API. Il s'exécute dans les trois centres de données, car le flux de messages est supérieur à celui des services internes. De plus, une telle disposition vous permet de mettre à l'échelle horizontalement assez facilement.
Par exemple, si votre trafic entrant augmente neuf fois, vous pouvez optimiser, mais vous pouvez également «inonder» cette entreprise de fer en ouvrant plus de nœuds qui traiteront le trafic entrant.
L'équilibreur devra simplement diviser le trafic en un plus grand nombre de points qui répondent aux demandes. Et maintenant, par exemple, nous n'avons pas un nœud, mais deux nœuds dans chaque centre de données.
Notre architecture nous permet de faire face même à des cas tels que l'arrêt de l'un des centres de données. Par exemple, nous avons décidé de mener un exercice et de désactiver le centre de données de Vladimir - et notre service reste à flot, rien ne change. Les hôtes de base de données qui s'y trouvent disparaissent et le service reste opérationnel.
L'équilibreur comprend au bout d'un moment: oui, je n'ai plus un seul hôte en direct dans ce centre de données, et il ne redirige plus le trafic là-bas.
Tous les services de Yandex sont organisés de la même manière, nous savons tous comment survivre à la défaillance de l'un des centres de données. Nous avons déjà décrit comment cela est mis en œuvre, ce qu'est une dégradation gracieuse et comment les services Yandex gèrent l'arrêt de l'un des centres de données .
C'était donc l'architecture. Et maintenant, les histoires commencent.
La première histoire - à propos de Yandex.Rover
Récemment, nous avons eu une autre conférence, où Rover a reçu beaucoup d'attention. Je vais continuer le sujet.
Une fois, les gars de l'équipe Yandex.Rover sont venus nous voir et nous ont proposé de tester l'hypothèse selon laquelle les gens voudraient recevoir des commandes d'une manière aussi extraordinaire.
Yandex.Rover est un petit robot de la taille d'un chien moyen. Vous pouvez y mettre de la nourriture, quelques boîtes de commandes - il fera le tour de la ville et apportera des commandes sans aide humaine. Il y a un lidar, le robot comprend sa position dans l'espace. Il sait livrer les petites commandes.
Et nous avons pensé: pourquoi pas? Nous avons clarifié les détails de l'expérience: à ce moment-là, il était nécessaire de tester l'hypothèse que les gens l'apprécieraient. Et nous avons décidé de livrer 50 commandes en une semaine et demie dans un mode très léger.
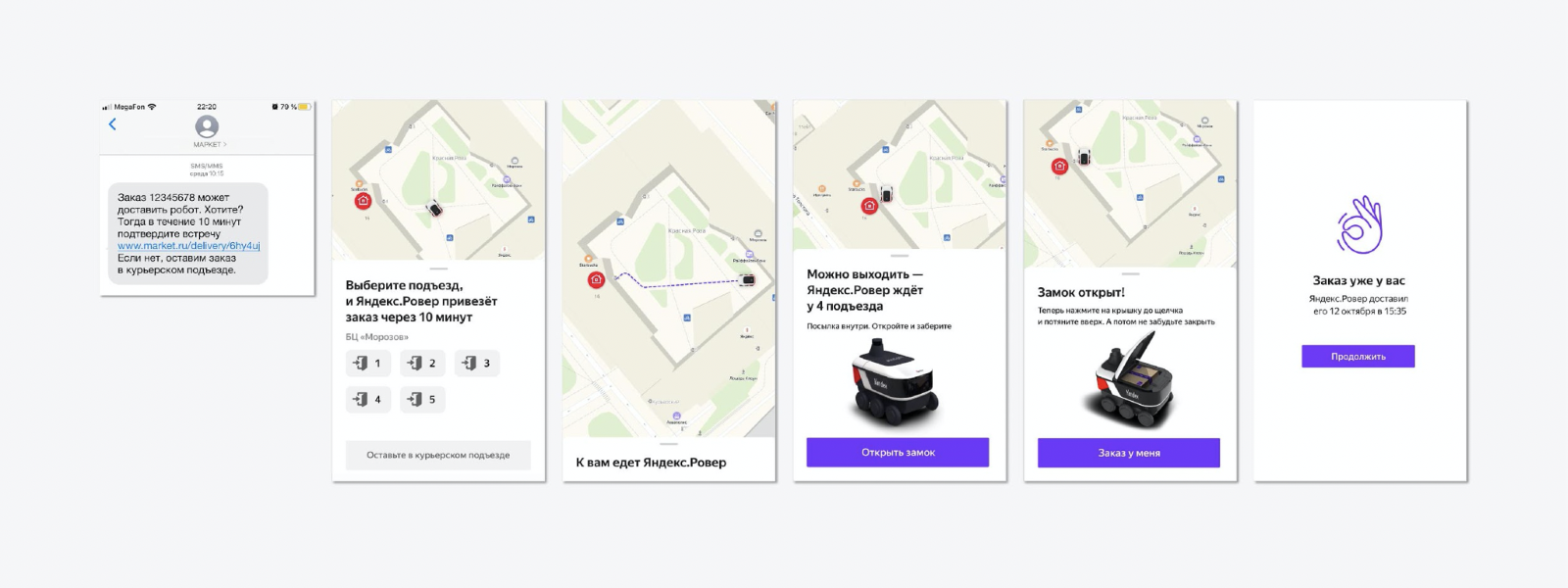
Nous avons proposé le flux le plus simple, lorsqu'une personne reçoit un SMS avec une proposition de méthode de livraison non standard - ce n'est pas le courrier qui l'apportera, mais le Rover. L'expérience entière a eu lieu dans la cour de Yandex. L'homme était en train de choisir l'entrée à laquelle le Rover se rendrait. Lorsque le robot est arrivé, le couvercle a été ouvert, le client a pris la commande, a fermé le couvercle et Rover est parti pour une nouvelle commande. C'est simple.
Ensuite, nous sommes allés à l'équipe de Rover pour négocier une API.
Il existe des méthodes simples dans l'API Rover: ouvrir le couvercle, fermer le couvercle, aller à un certain point, obtenir un état. Classique. Aussi JSON. Très simple.
Ce qui est également très important: à la fois ces petites histoires et toutes les grandes histoires sont mieux réalisées grâce à des indicateurs de fonctionnalité. En fait, vous disposez d'un commutateur par lequel vous pouvez activer cette histoire en production. Lorsque vous n'en avez plus besoin, que l'expérience s'est terminée avec succès ou pas, ou que vous avez remarqué des bugs, vous venez de le réduire. Et vous n'avez pas besoin de faire un autre déploiement de la nouvelle version du code pour la production. Cette chose rend la vie beaucoup plus facile.
Il semblerait que tout soit simple et que tout devrait fonctionner. Il n'y a même rien à y développer pendant deux semaines, vous pouvez le faire en quelques jours. Mais regardez où le chien est enterré.
Tous les processus sont pour la plupart synchrones. L'homme appuie sur un bouton, le couvercle s'ouvre. L'homme appuie sur le bouton, le couvercle se ferme. Mais l'un de ces processus est asynchrone. Au moment où le Rover vient à vous, vous devez avoir une sorte de processus d'arrière-plan qui permettra de suivre que le robot est revenu au point.
Et à ce moment, nous enverrons un SMS à la personne, par exemple, que le Rover attend sur place. Cela ne peut pas être fait de manière synchrone et vous devez en quelque sorte résoudre ce problème.
Il existe de nombreuses approches différentes. Nous l'avons rendu aussi simple que possible.
Nous avons décidé que nous pouvions exécuter le thread ou la tâche Java d'arrière-plan le plus courant dans Executer. Ce fil d'arrière-plan est immédiatement lancé pour suivre le processus. Et dès que le processus est terminé, nous envoyons une notification.
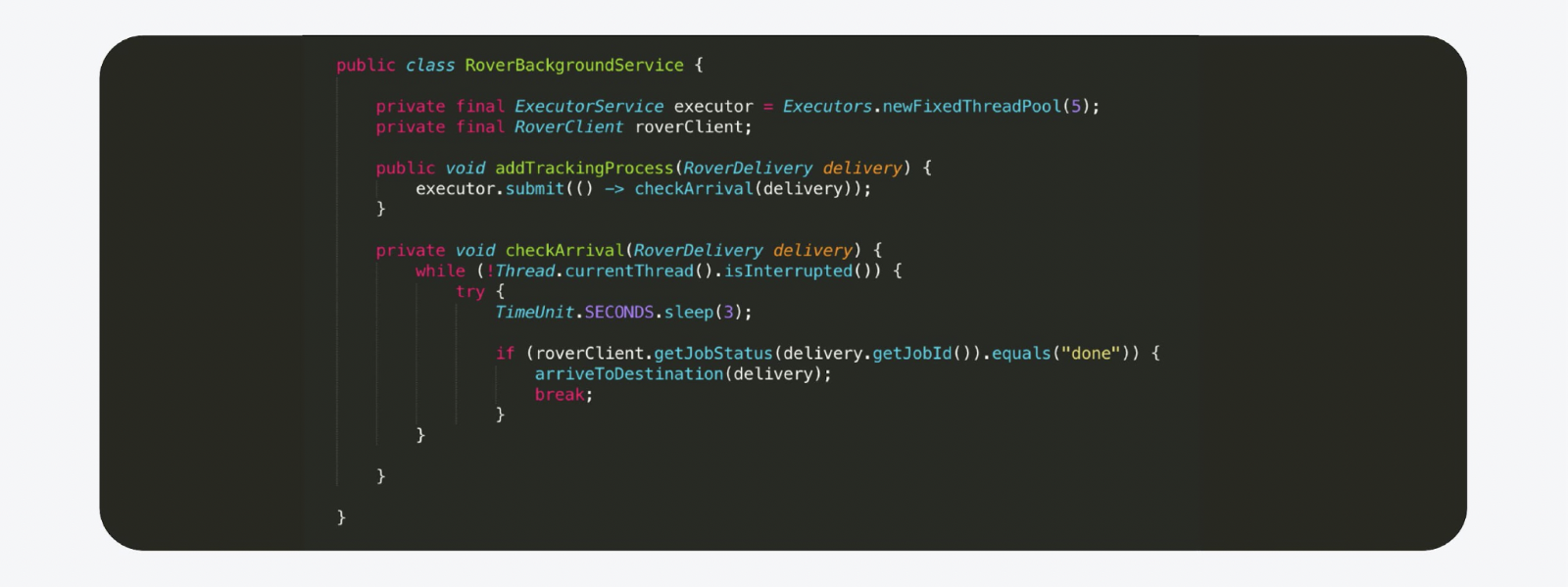
Par exemple, cela ressemble à ceci. Il s'agit pratiquement d'une copie du code de production, à l'exception des commentaires supprimés. Mais il ya un hic. Vous ne pouvez pas créer de systèmes sérieux de cette manière. Disons que nous déployons une nouvelle version sur le backend. L'hôte redémarre, l'état est perdu, et c'est tout, le Rover va à l'infini, personne d'autre ne le voit.
Mais pourquoi? Si nous savons que notre objectif est de livrer 50 commandes en une semaine et demie, nous choisissons l'heure à laquelle nous surveillons le backend. Si quelque chose ne va pas, vous pouvez modifier quelque chose manuellement. Pour une telle tâche, cette solution est plus que suffisante. Et c'est la morale de la première histoire.
Il existe des situations pour lesquelles vous devez créer la version minimale de la fonctionnalité. Il n'est pas nécessaire de clôturer un jardin et de sur-ingénier. Il vaut mieux le rendre aussi aliéné que possible. Pour ne pas trop changer la logique des objets internes. Et la complexité excessive, la dette technique inutile ne se sont pas accumulées.
La deuxième histoire - sur les bases de données
Mais d'abord, quelques mots sur l'organisation des principales entités. Il existe un service Yandex.Routing qui crée des itinéraires pour les coursiers à la fin de la journée.
Chaque itinéraire se compose de points sur la carte. Et à chaque moment, les courriers ont une tâche. Cela peut être une tâche pour passer une commande, ou appeler un client, ou le matin, charger au centre de tri, ramasser toutes les commandes.
De plus, les clients reçoivent un lien de suivi le matin. Ils peuvent ouvrir la carte et voir comment le courrier se déplace vers eux. Le client peut également choisir la livraison par Rover, ce que j'ai mentionné plus tôt.
Voyons maintenant comment ces entités peuvent être affichées dans la base de données. Ceci est fait, par exemple, comme ceci.
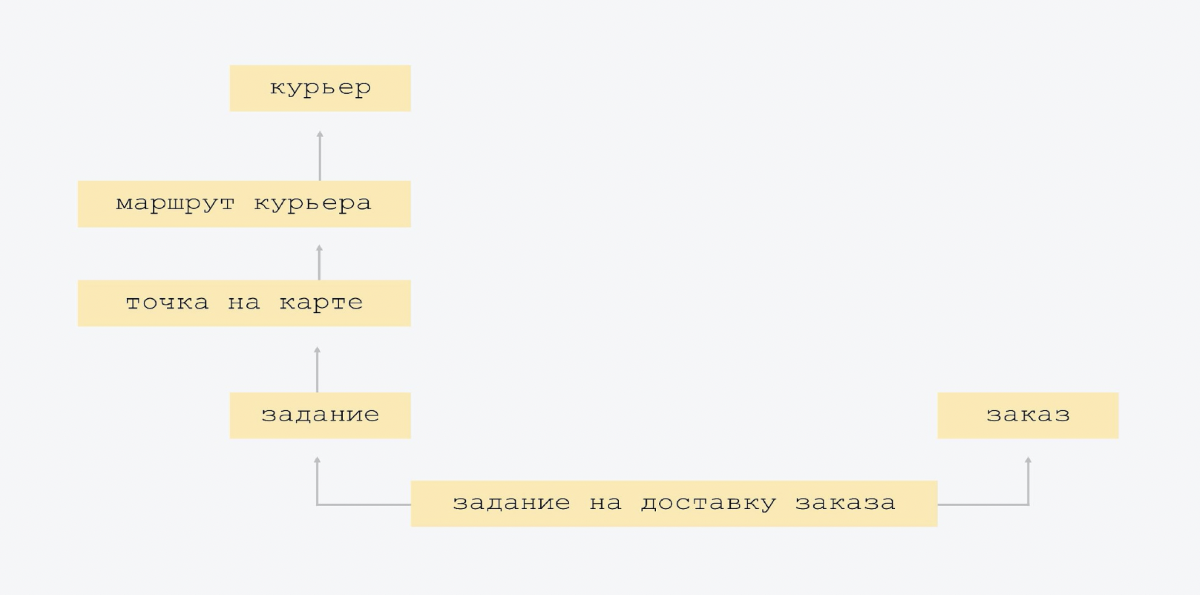
C'est un modèle de données très soigné. Nous n'avons pas inventé une seule nouvelle entité, et nous n'avons pas fortement effondré celles existantes.
Le diagramme montre que la flèche de bas en haut montre l'itinéraire du courrier, connaît le courrier dont il s'agit. Le signe de l'itinéraire du courrier contient le lien d'identification du courrier. Et la plaque supérieure ne le sait pas. Nous avons la connectivité la plus simple, il n'y a pas de grande intersection d'entités. Lorsque tout le monde connaît tout le monde, il est plus difficile à contrôler et, très probablement, il y aura redondance. Par conséquent, nous avons le schéma le plus simple possible.
La seule "exagération" que nous avons faite au tout début de la création de la plate-forme est la suivante. Nous avions un type de mission de livraison. Mais nous avons réalisé qu'à l'avenir, il y aura d'autres tâches. Et nous mettons un peu de flexibilité architecturale: nous avons des tâches, et l'un des types de tâches est la livraison des commandes.
Ensuite, nous avons ajouté le suivi et Rover. Juste deux comprimés. Lors du suivi, le courrier envoie ses coordonnées, nous les enregistrons dans une plaque séparée. Et il y a le suivi des commandes avec son propre modèle d'état, il y a des choses supplémentaires, telles que "SMS laissés / ne sont pas partis". Vous ne devez pas l'ajouter directement à la tâche. Il est préférable de le mettre dans une plaque séparée, car ce suivi n'est pas nécessaire pour tous les types de tâches.
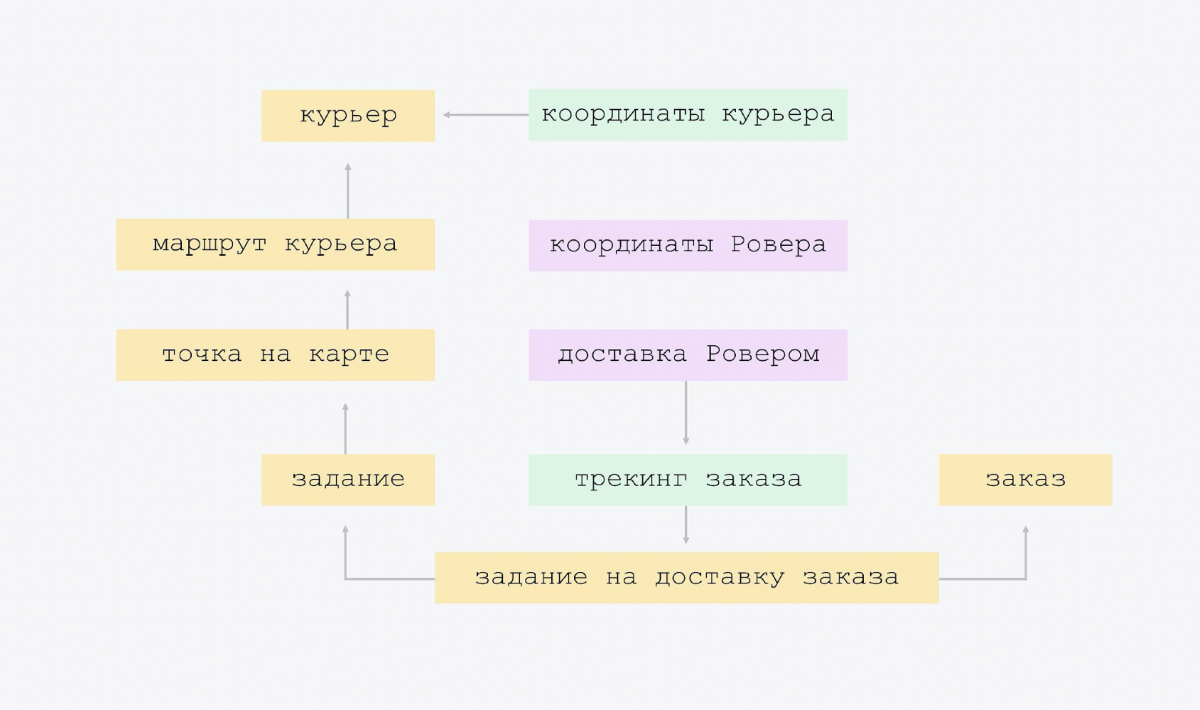
In Rover - ses coordonnées et livraison. Notre livraison par Rover est comme le suivi pour Rover. Vous pouvez l'ajouter à la commande de suivi, mais pourquoi? Après tout, lorsque nous nous débarrasserons de cette expérience, lorsqu'elle sera désactivée, ces options resteront à jamais dans l'essence du suivi. Il y aura des champs nuls.
La question peut se poser: pourquoi faire une plaque avec des coordonnées? Un Rover livre cinq commandes par jour. Vous n'avez pas besoin de stocker les coordonnées dans la base de données, vous pouvez simplement accéder à l'API Rover et les obtenir au moment de l'exécution.
L'essentiel est que cela a été fait au départ. Ce panneau n'était pas là, nous sommes immédiatement allés au service et avons tout pris. Mais lors des tests, nous avons vu que de nombreuses personnes ouvrent une carte avec un Rover roulant, et la charge sur ce service augmente plusieurs fois. Disons que sept personnes l'ont ouvert. Et là, sur la page, toutes les deux secondes, Java Script demande des coordonnées. Et des collègues nous ont écrit dans le chat: «D'où vient une telle charge? Vous avez une personne là-bas pour patiner. "
Et après cela, nous avons ajouté un signe. Nous avons commencé à y ajouter les coordonnées, l'heure à laquelle elles ont été reçues. Et maintenant, si les gens viennent nous voir trop souvent pour les coordonnées et que deux secondes ne se sont pas écoulées depuis le dernier reçu, on les retire de l'assiette. Il s'avère un tel cache au niveau de la base de données.
Cette histoire pourrait être réalisée avec 20 tables. Deux tables peuvent être utilisées: le courrier et la commande. Mais dans le premier cas, ce serait une sur-ingénierie, et dans le second cas, ce serait trop difficile à maintenir. Logique complexe, difficile à tester.
Et plus loin. La structure des bases de données, que nous avons réalisée il y a un an et demi, le cœur de ces entités est restée inchangée à ce jour. Et nous avons eu beaucoup de chance d'avoir pu choisir de telles entités sur lesquelles la base n'avait pas à être refaite. Il n'était pas nécessaire de redessiner considérablement les bases de données, de faire des migrations complexes, puis de lancer cette version, de la tester pendant très longtemps, puis de modifier la structure racine.
Le but de l'histoire est qu'il y a des aspects auxquels il vaut mieux accorder une attention particulière. Le premier est portez une attention particulière à la structure de l'API et de la base de données . Essayez de remarquer le type d'entités que vous avez dans la vraie vie. Essayez de numériser cette structure de la même manière. Essayez de ne pas trop le raccourcir, de ne pas trop l'agrandir.
Deuxièmement, il y a des erreurs qui coûtent cher à corriger . Les erreurs au niveau de l'API sont plus difficiles à corriger que les erreurs au niveau de la base de données car de nombreux clients utilisent généralement l'API. Et lorsque vous modifiez beaucoup l'API, vous devez:
- atteindre tous les clients, assurer la compatibilité descendante;
- déployer la nouvelle API, basculer tous les clients vers la nouvelle API;
- supprimez l'ancien code sur les clients, supprimez l'ancien code sur le backend.
Cela coûte très cher.
Les erreurs dans le code sont généralement absurdes par rapport à cela. Vous venez de réécrire le code, d'exécuter les tests. Les tests sont verts - vous avez poussé dans le maître. Portez une attention particulière à l'API de base de données.
Et peu importe à quel point vous essayez de garder une trace de la base de données, avec le temps, elle se transformera en quelque chose d'ingérable. Sur la capture d'écran, vous pouvez voir un dixième de notre base de données, qui existe maintenant.
Il y a un conseil. Lorsque vous développez quelque chose très rapidement, il y a des inexactitudes dans la base de données, parfois une clé étrangère est manquante ou un champ dupliqué apparaît. Par conséquent, parfois, une fois tous les deux ou trois mois, ne regardez que la base. La même Intellij IDEA peut générer des circuits froids. Et là, vous pouvez tout voir.
Votre base de données doit être adéquate. Il est très facile de faire une liste de six tickets en une heure: ajoutez une clé étrangère ici, là un index. Peu importe vos efforts, certains débris s'accumuleront inévitablement.
La troisième histoire concerne la qualité
Il y a des choses qu'il vaut mieux bien faire dès le départ. Il est important d'agir selon le principe «fais normalement, ça ira».
Par exemple, nous avons un processus essentiel pour la plate-forme. Toute la journée, nous collectons les commandes de demain, mais le soir, une note est déclenchée indiquant qu'après 22h00, nous ne collectons pas les commandes, mais avant 01h00, nous nous préparons pour demain. Puis commence la distribution des commandes aux centres de tri. Nous allons à Yandex.Routing, il construit des routes.
Et si ce travail préparatoire échoue, tout demain est remis en question. Demain, les courriers n'auront nulle part où aller. Ils n'ont pas créé d'État. Il s'agit du processus le plus critique de notre plateforme. Et des processus aussi importants ne peuvent pas être exécutés sur une base résiduelle, avec des ressources minimales.
Je me souviens que nous avons eu un moment où ce processus a échoué, et pendant plusieurs semaines, près de la moitié de l'équipe dans le chat résolvait ces problèmes, tout le monde sauvait la journée, retravaillait quelque chose, redémarrait.
Nous avons compris que si le processus n'est pas terminé de dix heures du soir à une heure du matin, alors les centres de tri ne sauront même pas comment trier les commandes, dans quels tas. Tout y sera oisif. Les courriers sortiront plus tard et nous aurons des échecs de qualité.
Il est préférable de faire de tels processus aussi bien que possible tout de suite, en réfléchissant à chaque étape où quelque chose peut mal tourner. Et mettez le maximum de paille partout.
Je vais vous parler de l'une des options pour mettre en place un tel processus.
Ce processus est multi-composants. Le calcul des itinéraires et leur publication peuvent être divisés en parties et, par exemple, des files d'attente peuvent être créées. Ensuite, nous avons plusieurs files d'attente qui sont responsables des sections de travail terminées. Et il y a des consommateurs sur ces files d'attente qui attendent les messages.
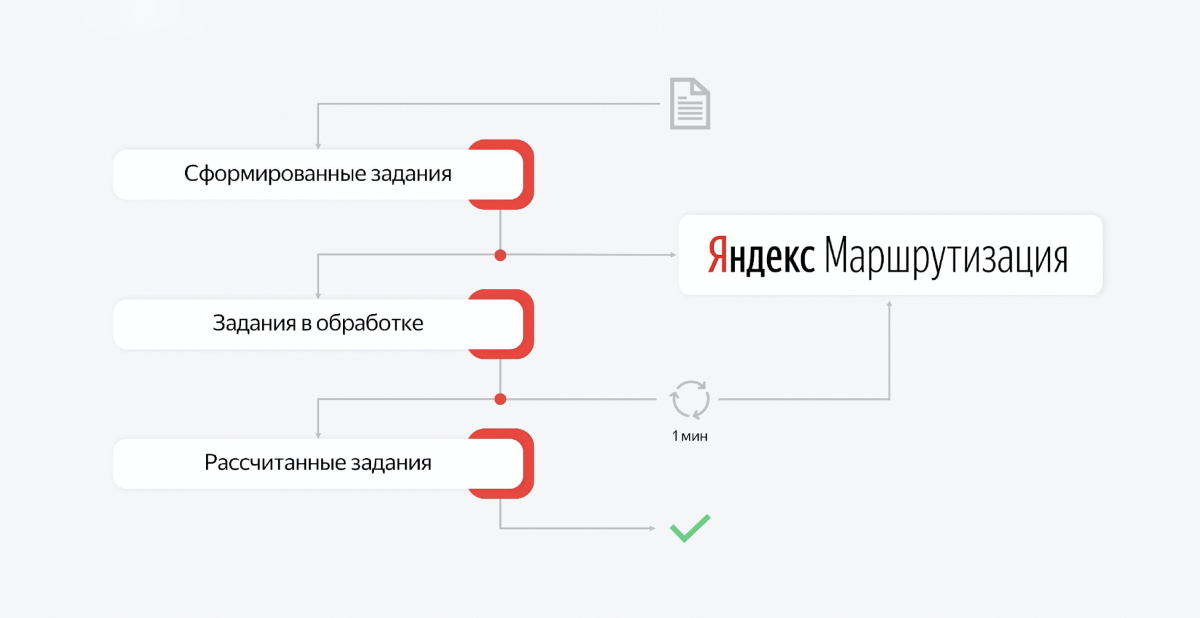
Par exemple, la journée est finie, nous voulons calculer les itinéraires de demain. Nous envoyons une demande tout d'abord: créez une tâche et lancez le calcul. Le consommateur prend le premier message, se dirige vers le service de routage. Il s'agit d'une API asynchrone. Le consommateur reçoit une réponse indiquant que la tâche a été exécutée.
Il place cet ID dans la base et met un nouveau travail dans la file d'attente avec des tâches en cours de traitement. Et c'est tout. Le message disparaît de la première file d'attente, le deuxième consommateur "se réveille". Il prend la deuxième tâche pour le traitement, et sa tâche est d'aller régulièrement au routage et de vérifier si cette tâche n'est pas encore terminée pour le calcul.
La tâche du niveau "créer des itinéraires pour 200 courriers qui livreront plusieurs milliers de commandes à Moscou" prend d'une demi-heure à une heure. C'est en effet une tâche très difficile. Et les gars de ce service sont très cool, ils résolvent le problème algorithmique le plus complexe qui prend beaucoup de temps.
En conséquence, le consommateur de la deuxième file d'attente va simplement vérifier, vérifier, vérifier. Après un certain temps, la tâche sera terminée. Lorsque la tâche est terminée, nous recevons une réponse sous la forme de la structure requise des itinéraires et des équipes de demain pour les courriers.
Nous mettons ce qui a été calculé dans la troisième priorité. Le message disparaît de la deuxième file d'attente. Et le troisième consommateur «se réveille», prend ce contexte du service Yandex.Routing et, sur sa base, crée l'état de demain. Il crée des commandes pour les courriers, il crée des commandes, crée des équipes. C'est aussi beaucoup de travail. Il passe du temps là-dessus. Et lorsque tout est créé, cette transaction se termine et le travail est supprimé de la file d'attente.
Si quelque chose ne va pas dans ce processus, le serveur redémarrera. Lors de la restauration ultérieure, nous verrons simplement le point auquel nous avons terminé. Disons que la première phase et la seconde sont passées. Et passons au troisième.
Avec cette architecture, ces derniers mois, tout s'est plutôt bien passé, il n'y a pas de problème. Mais avant, il y avait un solide essai. On ne sait pas où le processus a échoué, quels statuts ont été modifiés dans la base de données, etc.
Il y a des choses sur lesquelles il ne faut pas lésiner. Il y a des choses avec lesquelles vous vous sauverez un tas de cellules nerveuses si vous faites tout bien tout de suite.
Qu'avons-nous fait hors ligne
J'ai décrit la plupart de ce qui se passe sur notre plateforme. Mais quelque chose est resté dans les coulisses.
Nous avons découvert un logiciel qui aide les coursiers à livrer les commandes en une journée. Mais quelqu'un devrait faire ces tas pour les courriers. Dans un centre de tri, les gens doivent trier une grosse machine de commandes en petites piles. Comment c'est fait?
C'est la deuxième partie de la plateforme. Nous avons écrit tous les logiciels nous-mêmes. Nous avons maintenant des terminaux avec lesquels les commerçants lisent le code des boîtes et les placent dans les cellules appropriées. Il y a une logique assez compliquée. Ce backend n'est pas beaucoup plus simple que celui dont j'ai déjà parlé.
Cette deuxième pièce du puzzle était nécessaire pour permettre, avec la première, d'étendre le processus à d'autres villes. Sinon, il faudrait chercher un entrepreneur dans chaque nouvelle ville qui pourrait organiser l'échange de certains Excels par courrier, ou s'intégrer à notre API. Et ce serait très long.
Lorsque nous avons les première et deuxième pièces du puzzle, nous pouvons simplement louer un bâtiment, engager des coursiers dans des voitures. Dites-leur comment pousser, quoi pousser, comment choisir, quelle boîte mettre où, et c'est tout. Grâce à cela, nous avons déjà lancé dans sept villes, nous avons plus de dix centres de tri.
Et l'ouverture de notre plateforme dans une nouvelle ville prend très peu de temps. De plus, nous avons appris non seulement à livrer des commandes à des personnes spécifiques. Nous savons comment livrer les commandes aux points de retrait avec l'aide de coursiers. Nous avons également écrit des logiciels pour eux. Et à ces moments-là, nous donnons également des ordres aux gens.
Résultats
Au début, j'ai expliqué pourquoi nous avons commencé à créer notre propre plate-forme de messagerie. Maintenant, je vais vous dire ce que nous avons accompli. C'est incroyable, mais en utilisant notre plate-forme, nous avons pu nous rapprocher de presque 100% en atteignant l'intervalle. Par exemple, au cours de la semaine dernière, la qualité de la livraison à Moscou était d'environ 95 à 98%. Cela signifie que dans 95 à 98% des cas, nous ne sommes pas en retard. Nous nous inscrivons dans l'intervalle choisi par le client. Et nous ne pouvions même pas rêver d'une telle précision lorsque nous nous appuyions uniquement sur des services de livraison externes. Par conséquent, nous étendons progressivement notre plateforme à toutes les régions. Et nous améliorerons la délivrabilité.
Nous avons une transparence irréaliste. Nous avons également besoin de cette transparence. Tout est enregistré avec nous: toutes les actions, l'ensemble du processus d'émission d'une commande. Nous avons l'occasion de remonter dans l'histoire pendant cinq mois et de comparer certains paramètres avec l'actuel.
Mais nous avons également donné cette transparence aux clients. Ils voient un courrier venir vers eux. Ils peuvent interagir avec lui. Ils n'ont pas besoin d'appeler le service d'assistance, de dire: "Où est mon courrier?"
De plus, cela s'est avéré optimiser les coûts, car nous avons accès à tous les éléments de la chaîne. En conséquence, la livraison d'une commande coûte désormais un quart de moins qu'auparavant lorsque nous travaillions avec des services externes. Oui, le coût de livraison de la commande a diminué de 25%.
Et si vous résumez toutes les idées qui ont été discutées, les suivantes peuvent être distinguées.
Vous devez bien comprendre à quel stade de développement se trouve votre service actuel, votre projet actuel. Et s'il s'agit d'une entreprise établie, utilisée par des millions de personnes, utilisée, peut-être dans plusieurs pays, vous ne pouvez pas tout faire au même niveau qu'avec Rover.
Mais si vous avez une expérience ... L'expérience est différente en ce qu'à tout moment, si nous ne montrons pas les résultats promis, nous pouvons être fermés. Ça n'a pas décollé. Et ça va.
Et nous avons été dans ce régime pendant une dizaine de mois. Nous avions des intervalles de rapport, tous les deux mois, nous devions montrer le résultat. Et nous l'avons fait.
Dans ce mode, il me semble que vous n’avez pas le droit de faire quelque chose en investissant dans le long terme et en ne recevant rien à court terme. Il est impossible de jeter une base aussi solide pour l’avenir dans ce format de travail, car l’avenir ne viendra peut-être tout simplement pas.
Et tout développeur compétent, responsable technique doit constamment choisir entre faire avec des béquilles ou construire un vaisseau spatial tout de suite.
Bref, essayez de garder les choses aussi simples que possible, tout en laissant de la place à l'expansion.
Il y a un premier niveau où il faut le faire tout simplement. Et il y a le premier niveau avec un astérisque, quand vous restez simple, mais laissez au moins une petite marge de manœuvre pour qu'il puisse être élargi. Dans cet état d'esprit, il me semble que les résultats seront bien meilleurs.
Et la dernière chose. J'ai dit à Rover qu'il était bon de faire de tels processus en utilisant des indicateurs de fonction. Je vous conseille d'écouter le discours de Maria Kuznetsova du meetup Java. Elle a expliqué comment les indicateurs de fonctionnalités sont disposés dans notre système et notre surveillance.