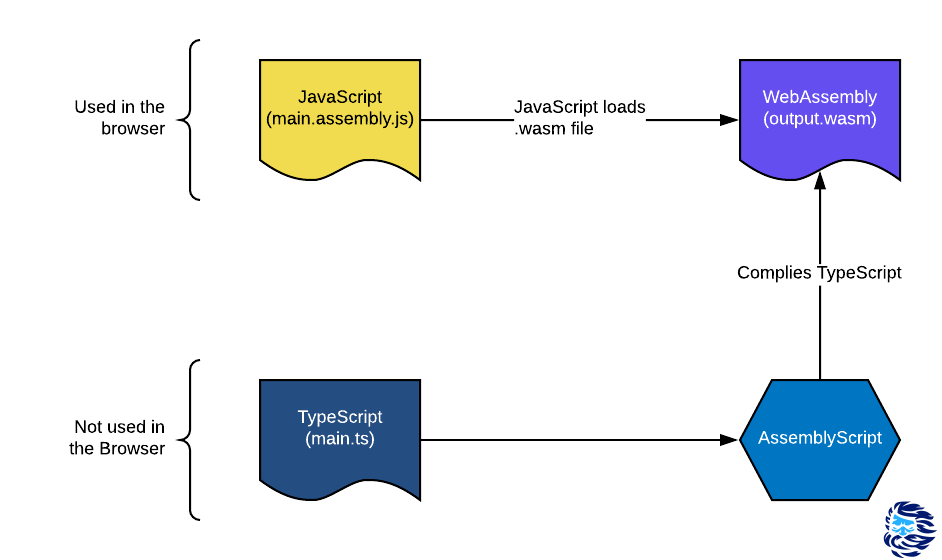
Pour améliorer les performances des applications Web, utilisez WebAssembly en conjonction avec AssemblyScript pour réécrire les composants JavaScript essentiels aux performances d'une application Web. «Et cela va-t-il vraiment aider?», Demandez-vous.
Malheureusement, il n'y a pas de réponse claire à cette question. Tout dépend de la façon dont vous les utilisez. Il existe de nombreuses options: dans certains cas, la réponse sera négative, dans d'autres, elle sera positive. Dans une situation, il est préférable de choisir JavaScript plutôt que AssemblyScript, et dans une autre, c'est l'inverse. Ceci est influencé par de nombreuses conditions différentes.
Dans cet article, nous analyserons ces conditions, proposerons un certain nombre de solutions et les testerons sur plusieurs exemples de code de test.
Qui suis-je et pourquoi est-ce que je fais ce sujet?
(Vous pouvez sauter cette section, elle n'est pas essentielle pour comprendre davantage de matériel).
J'aime beaucoup le langage AssemblyScript . J'ai même commencé à aider financièrement les développeurs à un moment donné. Ils ont une petite équipe dans laquelle tout le monde est sérieusement passionné par ce projet. AssemblyScript est un tout jeune langage de type TypeScript capable de se compiler en WebAssembly (Wasm). C'est précisément l'un de ses avantages. Auparavant, pour utiliser Wasm, un développeur Web devait apprendre des langages étrangers comme C, C ++, C #, Go ou Rust, car ces langages de haut niveau avec typage statique pouvaient être compilés dans WebAssembly à partir du le tout début.
Bien que AssemblyScript (ASC) soit similaire à TypeScript (TS), il n'est pas associé à ce langage et ne se compile pas en JS. La similitude dans la syntaxe et la sémantique est nécessaire pour faciliter le processus de "portage" de TS vers ASC. Ce portage se résume essentiellement à l'ajout d'annotations de type.
J'ai toujours été intéressé à prendre du code JS, à le porter sur ASC, à le compiler vers Wasm et à comparer les performances. Lorsque mon collègue Ingvar m'a envoyé un extrait de code JavaScript pour brouiller les images , j'ai décidé de l'utiliser. J'ai fait une petite expérience pour voir si cela valait la peine d'explorer ce sujet plus en profondeur. Cela en valait la peine. En conséquence, cet article est apparu.
Pour mieux connaître AssemblyScript, vous pouvez consulter le site officiel , rejoindre la chaîne Discord ou regarder la vidéo d' introduction sur ma chaîne Youtube. Et nous passons à autre chose.
Avantages de WebAssembly
Comme je l'ai écrit ci-dessus, pendant longtemps, la tâche principale de Wasm était la capacité de compiler du code écrit dans des langages à usage général de haut niveau. Par exemple, chez Squoosh (un outil de traitement d'images en ligne), nous utilisons des bibliothèques de l'écosystème C / C ++ et Rust. Ces bibliothèques n'ont pas été conçues à l'origine pour être utilisées dans des applications Web, mais WebAssembly le permet.
De plus, selon la croyance populaire, la compilation du code source dans Wasm est également nécessaire car l'utilisation de binaires Wasm permet d'accélérer le travail d'une application Web. Je conviens, au minimum, que dans des conditions idéales (de laboratoire), les binaires WebAssembly et JavaScript peuventfournissent des valeurs approximativement égales de performances de pointe. Cela n'est guère possible sur les projets Web de combat.
À mon avis, il est plus logique de penser à WebAssembly comme un outil d'optimisation des valeurs de performance de travail moyennes. Bien que récemment, Wasm ait la possibilité d'utiliser des instructions SIMD et des flux de mémoire partagée. Cela devrait accroître sa compétitivité. Mais dans tous les cas, comme je l'ai écrit ci-dessus, tout dépend de la situation spécifique et des conditions initiales.
Ci-dessous, nous examinerons plusieurs de ces conditions:
Manque d'échauffement
Le moteur V8 JS traite le code source et le présente sous la forme d'un arbre de syntaxe abstraite (AST). Basé sur l'AST construit, l'interpréteur Ignition optimisé génère du bytecode. Le bytecode résultant est pris par le compilateur Sparkplug et à la sortie, il produit le code machine pas encore optimisé, avec une grande empreinte. Lors de l'exécution du code, la V8 collecte des informations sur les formes (types) des objets utilisés puis exécute le compilateur d'optimisation TurboFan. Il génère des instructions machine de bas niveau optimisées pour l'architecture cible en fonction des informations collectées sur les objets.
Vous pouvez comprendre le fonctionnement des moteurs JS en étudiant la traduction de cet article .

Pipeline de moteur JS. Schéma général
D'autre part, WebAssembly utilise le typage statique, de sorte que vous pouvez immédiatement générer du code machine à partir de celui-ci. Le moteur V8 dispose d'un compilateur Wasm en streaming appelé Liftoff. Comme Ignition, il vous aide à préparer et à exécuter rapidement du code non optimisé. Et après cela, le même TurboFan se réveille et optimise le code machine. Il fonctionnera plus rapidement qu'après la compilation de Liftoff, mais sa génération prendra plus de temps.
La différence fondamentale entre le pipeline JavaScript et le pipeline WebAssembly: le moteur V8 n'a pas besoin de collecter des informations sur les objets et les types, car Wasm a un typage statique et tout est connu à l'avance. Cela fait gagner du temps.
Manque de désoptimisation
Le code machine généré par TurboFan pour JavaScript ne peut être utilisé que tant que les hypothèses de type sont conservées. Disons que TurboFan a généré du code machine, par exemple, pour une fonction f avec un paramètre numérique. Ensuite, lors de la rencontre d'un appel à cette fonction avec un objet au lieu d'un nombre, le moteur utilise à nouveau Ignition ou Sparkplug. C'est ce qu'on appelle la désoptimisation.
Pour WebAssembly, les types ne peuvent pas changer pendant l'exécution du programme. Par conséquent, une telle désoptimisation n'est pas nécessaire. Et les types eux-mêmes pris en charge par Wasm sont traduits de manière organique en code machine.
Minimiser les binaires pour les grands projets
Wasm a été conçu à l' origine avec le format de fichier binaire compact à l'esprit. Par conséquent, ces binaires se chargent rapidement. Mais dans de nombreux cas, ils s'avèrent encore plus que nous ne le souhaiterions (du moins en termes de volumes acceptés sur le réseau). Cependant, avec gzip ou brotli, ces fichiers se compresseront bien.
Au fil des ans, JavaScript a appris beaucoup de choses hors de la boîte: tableaux, objets, dictionnaires, itérateurs, traitement de chaînes, héritage prototypique, etc. Tout cela est intégré à son moteur. Et le langage C ++, par exemple, peut se vanter d'une portée beaucoup plus large. Et chaque fois que vous utilisez l'une de ces abstractions de langage lors de la compilation vers WebAssembly, le code correspondant sous le capot doit être inclus dans votre binaire. C'est l'une des raisons de la prolifération des binaires WebAssembly.
Wasm ne sait vraiment rien du C ++ (ou de tout autre langage). Par conséquent, le runtime Wasm ne fournit pas de bibliothèque C ++ standard et le compilateur doit l'ajouter à chaque fichier binaire. Mais un tel code ne doit être connecté qu'une seule fois. Par conséquent, pour les projets plus importants, cela n'affecte pas beaucoup la taille résultante du binaire Wasm, qui au final est souvent plus petit que les autres binaires.
Il est clair que dans tous les cas, il n'est pas possible de prendre une décision éclairée en comparant uniquement les tailles des binaires. Si, par exemple, le code source AssemblyScript est compilé dans Wasm, alors le binaire se révélera vraiment très compact. Mais à quelle vitesse fonctionnera-t-il? Je me suis fixé la tâche de comparer différentes versions de binaires JS et ASC en fonction de deux critères à la fois: la vitesse et la taille.
Portage vers AssemblyScript
Comme je l'ai déjà écrit, TypeScript et ASC sont très similaires en syntaxe et en sémantique. Il est facile de supposer qu'il existe des similitudes avec JS, donc le portage consiste principalement à ajouter des annotations de type (ou à remplacer des types). Pour commencer à porter Glur , bibliothèque JS pour le flou d'image.
Mappage des types de données
Les types AssemblyScript intégrés sont implémentés de la même manière que les types de machine virtuelle Wasm (WebAssembly VM). Si dans TypeScript, par exemple, le type Number est implémenté en tant que nombre à virgule flottante 64 bits (selon la norme IEEE754), alors en ASC il existe un certain nombre de types numériques: u8, u16, u32, i8, i16, i32 , f32 et f64. En outre, vous pouvez trouver des types de données composites courants (chaîne, Array, ArrayBuffer, Uint8Array, etc.) dans la bibliothèque standard AssemblyScript, qui, avec certaines réserves, sont présentes dans TypeScript et JavaScript. Je ne considérerai pas ici les tables de mappage de type AssemblyScript, TypeScript et Wasm VM, ceci est un sujet pour un autre article. La seule chose que je veux noter est que ASC implémente le type StaticArray, pour lequel je n'ai pas trouvé d'analogues dans JS et WebAssembly VM.
Enfin, nous passons à notre exemple de code de la bibliothèque glur.
JavaScript:
function gaussCoef(sigma) {
if (sigma < 0.5)
sigma = 0.5;
var a = Math.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
return new Float32Array([
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
]);
}
AssemblyScript:
function gaussCoef(sigma: f32): Float32Array {
if (sigma < 0.5)
sigma = 0.5;
let a: f32 = Mathf.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
const r = new Float32Array(8);
const v = [
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
];
for (let i = 0; i < v.length; i++) {
r[i] = v[i];
}
return r;
}
Le fragment de code AssemblyScript contient une boucle supplémentaire à la fin, car il n'y a aucun moyen d'initialiser le tableau via le constructeur. ASC n'implémente pas la surcharge de fonction, donc dans ce cas, nous n'avons qu'un seul constructeur Float32Array (lengthOfArray: i32). AssemblyScript a des rappels, mais pas de fermetures, il n'y a donc aucun moyen d'utiliser .forEach () pour remplir un tableau avec des valeurs. J'ai donc dû utiliser une boucle for régulière pour copier un élément à la fois.
Vous avez peut-être remarqué que dans l'extrait de code sur AssemblyScript Math, Mathf. , 64- , — 32-. Math . - , , f32. . .
:
J'ai mis du temps à comprendre: le choix des types est très important. Le flou de l'image implique des opérations de convolution, et c'est tout un tas de boucles for traversant tous les pixels. Il était naïf de penser que si tous les indices de pixels sont positifs, les compteurs de boucles seront également positifs. Je n'aurais pas dû choisir le type u32 (entier non signé 32 bits) pour eux. Si l'une de ces boucles s'exécute dans la direction opposée, elle deviendra infinie (le programme bouclera):
let j: u32;
// ... many many lines of code ...
for (j = width — 1; j >= 0; j--) {
// ...
}
Je n'ai trouvé aucune autre difficulté lors du portage.
Benchmarks du shell D8
D'accord, les extraits de code bilingues sont prêts. Vous pouvez maintenant compiler ASC vers Wasm et exécuter les premiers tests de performance.
Quelques mots sur d8: il s'agit d'un shell de commande pour le moteur V8 (il ne possède pas lui-même sa propre interface), qui vous permet d'effectuer toutes les actions nécessaires avec Wasm et JS. En principe, d8 peut être comparé à Node, qui a soudainement coupé la bibliothèque standard et seul ECMAScript pur est resté. Si vous n'avez pas de version compilée de V8 dans les paramètres régionaux (comment la compiler est décrite ici ), vous ne pouvez pas utiliser d8. Pour installer d8, utilisez l'outil jsvu .
Cependant, comme le titre de cette section contient le mot "Benchmarks", je trouve important de fournir une sorte d'avertissement ici: les chiffres et les résultats que j'ai reçus font référence au code que j'ai écrit dans les langues de mon choix fonctionnant sur mon ordinateur (MacBook Air M1 2020) à l'aide des scripts de test que j'ai créés. Les résultats sont au mieux des lignes directrices approximatives. Par conséquent, il serait imprudent de donner des estimations quantitatives généralisées des performances d'AssemblyScript avec WebAssembly ou de JavaScript avec V8 en fonction de celles-ci.
Vous avez peut-être une autre question: pourquoi ai-je choisi d8 et n'ai pas exécuté de scripts dans le navigateur ou Node? Je crois que le navigateur et Node, dirons-nous, ne sont pas assez stériles pour mes expériences. En plus de la stérilité nécessaire, le d8 permet de contrôler la canalisation du moteur V8. Je peux capturer n'importe quel scénario d'optimisation et utiliser, par exemple, uniquement Ignition, uniquement Sparkplug ou Liftoff afin que les caractéristiques de performance ne changent pas au milieu du test.
Technique expérimentale
Comme je l'ai écrit ci-dessus, nous avons la possibilité de "réchauffer" le moteur JavaScript avant d'exécuter le test de performance. Au cours de ce processus de préchauffage, le V8 effectue l'optimisation nécessaire. J'ai donc exécuté le programme de flou 5 fois avant de commencer les mesures, puis j'ai exécuté 50 courses et j'ai ignoré les 5 courses les plus rapides et les plus lentes pour supprimer les valeurs aberrantes potentielles et trop de valeurs aberrantes.
Voyez ce qui s'est passé:

D'une part, j'étais heureux que Liftoff ait produit un code plus rapide par rapport à Ignition et Sparkplug. Mais le fait que AssemblyScript, compilé dans Wasm en utilisant l'optimisation, s'est avéré être plusieurs fois plus lent que le bundle JavaScript - TurboFan, j'étais perplexe.
Bien que plus tard, j'ai néanmoins admis que les forces n'étaient pas égales au départ: une énorme équipe d'ingénieurs travaille sur JS et son moteur V8 depuis de nombreuses années, mettant en œuvre l'optimisation et d'autres choses intelligentes. AssemblyScript est un projet relativement jeune avec une petite équipe. Le compilateur ASC lui-même est en un seul passage et met tous les efforts d'optimisation sur la bibliothèque Binaryen... Cela signifie que l'optimisation est effectuée au niveau du bytecode Wasm VM après que la plupart des sémantiques de haut niveau ont déjà été compilées. Le V8 a ici un net avantage. Cependant, le code de flou est très simple - ce sont les opérations arithmétiques habituelles avec des valeurs de la mémoire. Il semblait que ASC et Wasm auraient dû faire mieux avec cette tâche. Quel est le problème ici?
Creusons plus profondément
J'ai rapidement consulté les gars intelligents de l'équipe V8 et les gars tout aussi intelligents de l'équipe AssemblyScript (merci à Daniel et Max!). Il s'est avéré que lors de la compilation de l'ASC, le "contrôle des limites" (valeurs limites) n'est pas démarré.
V8 peut consulter le code JS source à tout moment et comprendre sa sémantique. Il utilise ces informations pour une optimisation répétée ou supplémentaire. Par exemple, vous avez un ArrayBuffer contenant un ensemble de données binaires. Dans ce cas, V8 s'attend à ce qu'il soit plus raisonnable non seulement de parcourir de manière chaotique les cellules de mémoire, mais d'utiliser un itérateur via une boucle for ... of.
for (<i>variable</i> of <i>iterableObject</i>) {
<i>statement</i>
}
La sémantique de cet opérateur garantit que nous ne dépassons jamais les limites du tableau. Par conséquent, le compilateur TurboFan ne gère pas la vérification des limites. Mais avant de compiler ASC vers Wasm, la sémantique AssemblyScript n'est pas utilisée pour une telle optimisation: toute l'optimisation est effectuée au niveau de la machine virtuelle WebAssembly.
Heureusement, ASC a toujours un atout dans sa manche - l'annotation non cochée (). Il indique quelles valeurs doivent être vérifiées pour la possibilité de sortir des limites.
- prev_prev_out_r = prev_src_r * coeff [6];
- ligne [line_index] = prev_out_r;
Les 2 lignes précédentes doivent être réécrites comme suit:
+ prev_prev_out_r = prev_src_r * non coché (coeff [6]);
+ décoché (ligne [line_index] = prev_out_r);
Oui, il y a plus. Dans AssemblyScript, les tableaux typés (Uint8Array, Float32Array, etc.) sont implémentés dans l'image et la ressemblance d'ArrayBuffer. Cependant, en raison du manque d'optimisation de haut niveau pour accéder à l'élément du tableau avec l'index i, chaque fois que vous devez accéder à la mémoire deux fois: la première fois pour charger le pointeur sur le premier élément du tableau et la deuxième fois pour charger l'élément à offset i * sizeOfType. Autrement dit, vous devez faire référence au tableau en tant que tampon (via un pointeur). Dans le cas de JS, le plus souvent, cela ne se produit pas, car V8 parvient à effectuer une optimisation de haut niveau de l'accès au tableau en utilisant un seul accès mémoire.
Pour améliorer les performances, AssemblyScript implémente des tableaux statiques (StaticArray). Ils sont similaires à Array sauf qu'ils ont une longueur fixe. Et par conséquent, il n'est pas nécessaire de stocker un pointeur vers le premier élément du tableau. Si possible, utilisez ces tableaux pour accélérer vos programmes.
Donc, j'ai pris le groupe AssemblyScript - TurboFan (cela a fonctionné plus rapidement) et l'ai appelé naïf. Ensuite, j'ai ajouté les deux optimisations dont j'ai parlé dans cette section et j'ai obtenu une variante appelée optimisée.

Bien mieux! Nous avons fait des progrès significatifs. Cependant, AssemblyScript est toujours plus lent que JavaScript. Est-ce tout ce que nous pouvons faire? [spoiler: non]
Oh, ces silences
Les membres de l'équipe AssemblyScript m'ont également dit que l'indicateur --optimize est équivalent à -O3s. Il optimise bien la vitesse de travail, mais ne l'amène pas au maximum, car en même temps, il empêche la croissance du fichier binaire. L'indicateur -O3 n'optimise que la vitesse et le fait jusqu'à la fin. Utiliser -O3s par défaut semble être correct, car il est habituel dans le développement Web de réduire la taille des binaires, mais en vaut-il la peine? Au moins dans cet exemple particulier, la réponse est non: -O3s économise environ 30 octets, mais néglige une baisse significative des performances:

Un seul indicateur d'optimisation fait basculer le jeu: Enfin, AssemblyScript a dépassé JavaScript (dans ce cas de test particulier!).
Je n'indiquerai plus le drapeau O3 dans le tableau, mais rassurez-vous: à partir de maintenant jusqu'à la fin de l'article, il nous sera invisible.
Tri à bulles
Pour m'assurer que l'exemple flou n'est pas qu'un accident, j'ai décidé d'en prendre un autre. J'ai pris l'implémentation du tri sur StackOverflow et j'ai suivi le même processus:
- porté le code en ajoutant des types;
- a lancé le test;
- optimisé;
- a relancé le test.
(Je n'ai pas testé la création et le remplissage d'un tableau pour le tri à bulles).
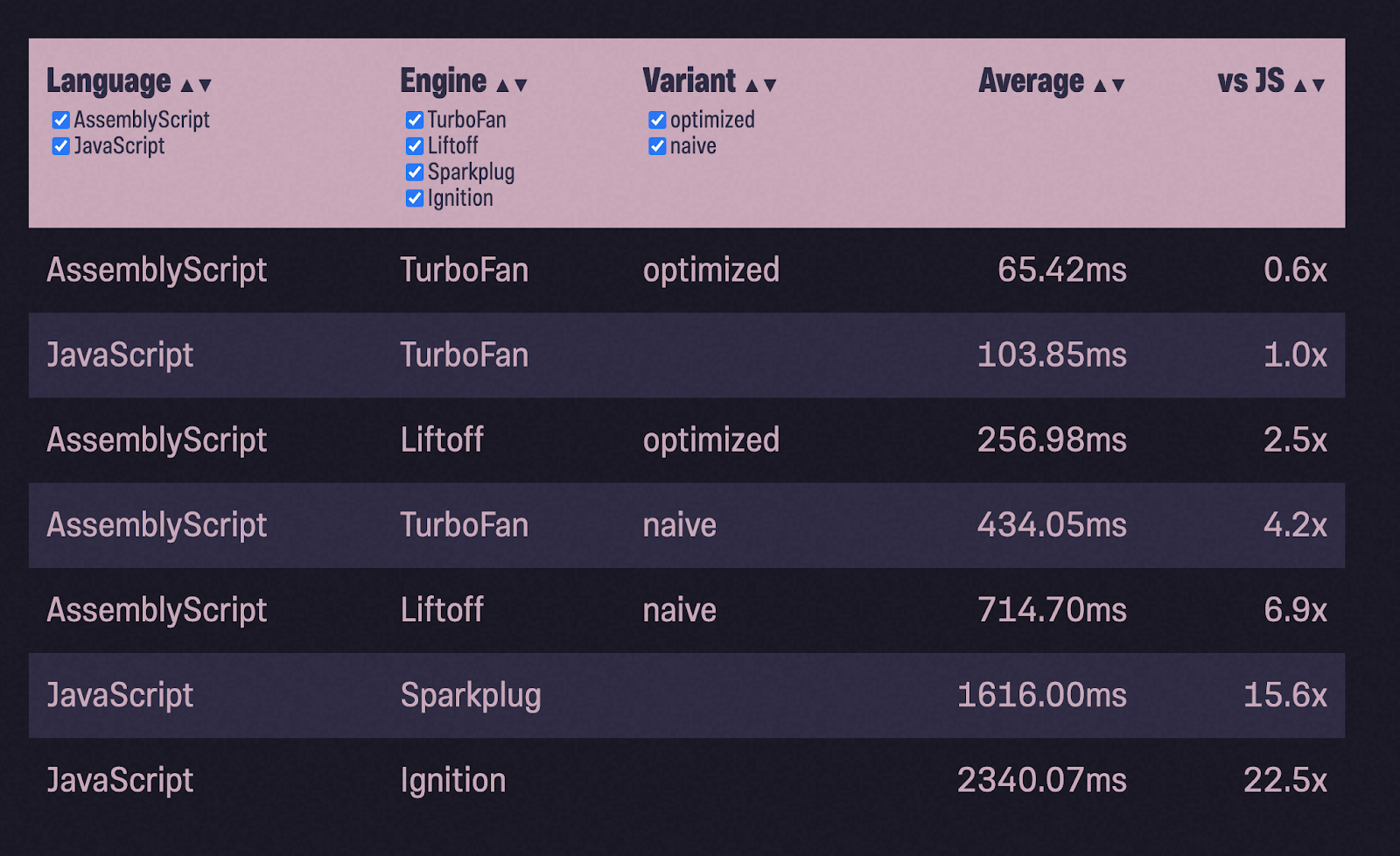
On l'a encore fait! Cette fois avec un gain de vitesse encore plus important: le AssemblyScript optimisé est presque deux fois plus rapide que JavaScript. Mais ce n'est pas tout. D'autres hauts et bas m'attendent à nouveau. Veuillez ne pas changer!
Gestion de la mémoire
Certains d'entre vous ont peut-être remarqué que ces deux exemples ne montrent pas vraiment comment travailler avec la mémoire. En JavaScript, V8 s'occupe de toute la gestion de la mémoire (et du ramasse-miettes) pour vous. Dans WebAssembly, par contre, vous vous retrouvez avec un morceau de mémoire linéaire et vous devez décider comment l'utiliser (ou plutôt Wasm doit décider). Dans quelle mesure notre table changera-t-elle si nous utilisons le tas de manière intensive?
J'ai décidé de prendre un nouvel exemple avec une implémentation de tas binaire... Pendant les tests, je remplis un tas avec 1 million de nombres aléatoires (avec la permission de Math.random ()) et pop () les renvoie, vérifiant si les nombres sont dans l'ordre croissant. Le schéma général de travail reste le même: portez le code JS vers ASC, compilez avec la configuration naïve, exécutez les tests, optimisez et relancez les tests:
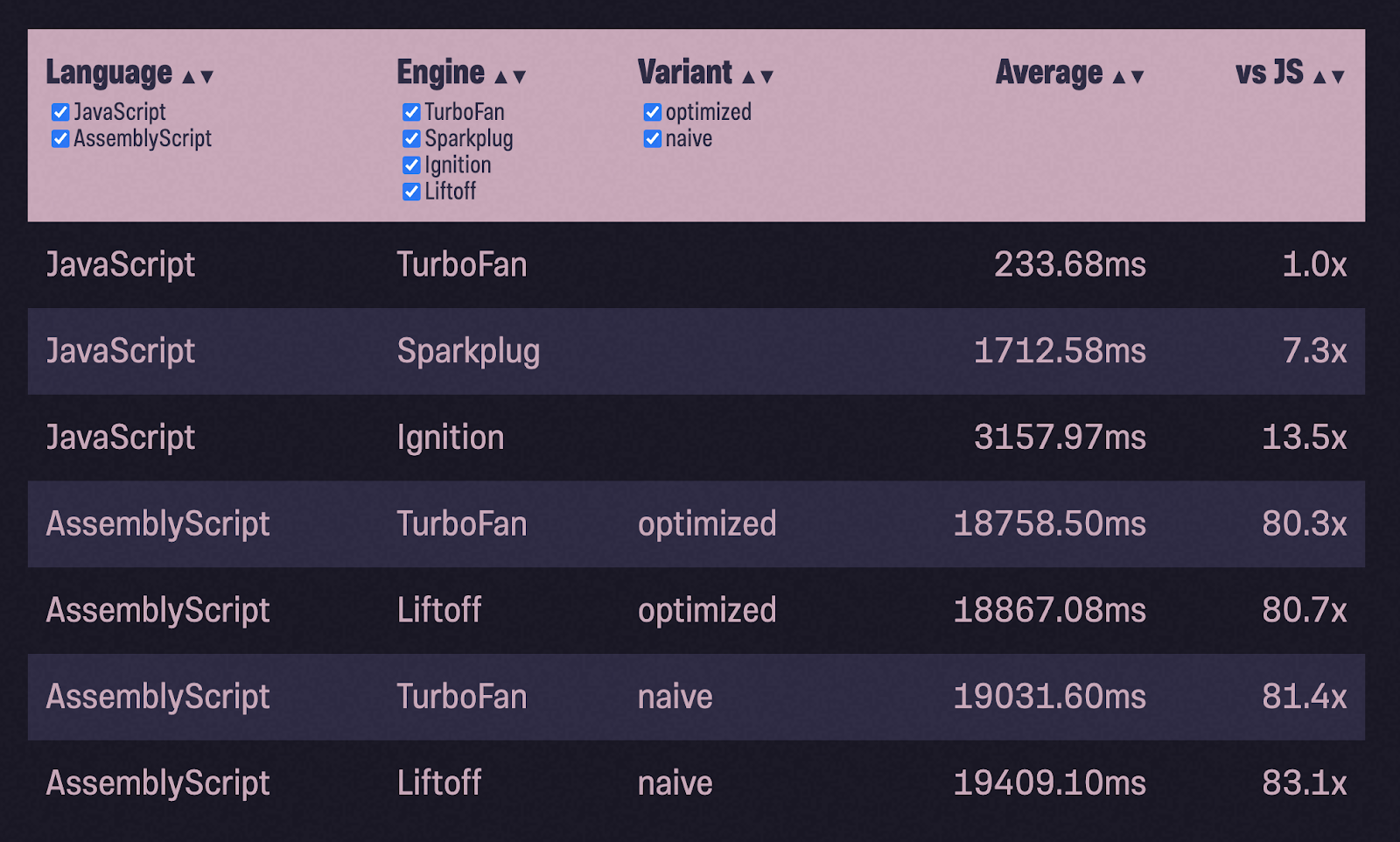
80x plus lent que JavaScript avec TurboFan?! Et 6x plus lent que l'allumage! Qu'est ce qui ne s'est pas bien passé?
Configuration de l'environnement d'exécution
Toutes les données que nous générons dans AssemblyScript doivent être stockées en mémoire. Mais nous devons nous assurer de ne pas écraser tout ce qui existe déjà. Étant donné que AssemblyScript a tendance à imiter le comportement JavaScript, il dispose également d'un garbage collector et, une fois compilé, il ajoute ce collecteur au module WebAssembly. ASC ne veut pas que vous vous inquiétiez de quand allouer et quand libérer de la mémoire.
Dans ce mode (appelé incrémental), il fonctionne par défaut. Dans le même temps, seulement environ 2 Ko dans l'archive gzip sont ajoutés au module Wasm. AssemblyScript propose également des modes alternatifs, minimal et stub. Les modes peuvent être sélectionnés à l'aide de l'indicateur --runtime. Minimal utilise le même allocateur de mémoire, mais un garbage collector plus léger qui ne démarre pas automatiquement, mais doit être appelé manuellement. Ceci est utile lors du développement d'applications hautes performances (comme des jeux) pour lesquelles vous souhaitez contrôler le moment où le garbage collector met votre programme en pause. En mode stub, très peu de code est ajouté au module Wasm (~ 400B au format gzip). Cela fonctionne rapidement, car un allocateur de sauvegarde est utilisé (plus de détails sur les allocateurs sont écrits ici ).
Les allocateurs redondants sont très rapides, mais ils ne peuvent pas libérer de mémoire. Cela peut sembler idiot, mais cela peut être utile pour les instances "ponctuelles" de modules, où après avoir terminé la tâche, au lieu de libérer de la mémoire, vous supprimez toute l'instance WebAssembly et en créez une nouvelle.
Voyons comment notre module fonctionnera dans différents modes:

Le minimum et le stub nous ont rapprochés nettement du niveau de performance JavaScript. Je me demande pourquoi? Comme mentionné ci-dessus, minimal et incrémental utilisent le même allocateur. Les deux ont également un garbage collector, mais minimal ne l'exécute pas à moins qu'il ne soit appelé explicitement (ce que je ne fais pas). Cela signifie que le fait est que l'incrémental démarre automatiquement le garbage collection et le fait souvent inutilement. Eh bien, pourquoi est-ce nécessaire s'il n'a besoin de suivre qu'un seul tableau?
Problème d'allocation de mémoire
Après avoir exécuté le module Wasm en mode débogage (--debug) plusieurs fois, j'ai constaté que la vitesse de travail ralentissait en raison de la bibliothèque libsystem_platform.dylib. Il contient des primitives au niveau du système d'exploitation pour la gestion des threads et de la mémoire. Les appels à cette bibliothèque sont effectués à partir de __new () et __renew (), qui à leur tour sont appelés à partir de Array # push: Je vois: il y a un problème de gestion de la mémoire ici. Mais JavaScript parvient d'une manière ou d'une autre à traiter rapidement un tableau de plus en plus grand. Alors pourquoi AssemblyScript ne peut-il pas faire cela? Heureusement, la source de la bibliothèque standard AssemblyScript est disponible publiquement , alors jetons un coup d'œil à cette sinistre fonction push () de la classe Array:
[Bottom up (heavy) profile]:
ticks parent name
18670 96.1% /usr/lib/system/libsystem_platform.dylib
13530 72.5% Function: *~lib/rt/itcms/__renew
13530 100.0% Function: *~lib/array/ensureSize
13530 100.0% Function: *~lib/array/Array#push
13530 100.0% Function: *binaryheap_optimized/BinaryHeap#push
13530 100.0% Function: *binaryheap_optimized/push
5119 27.4% Function: *~lib/rt/itcms/__new
5119 100.0% Function: *~lib/rt/itcms/__renew
5119 100.0% Function: *~lib/array/ensureSize
5119 100.0% Function: *~lib/array/Array#push
5119 100.0% Function: *binaryheap_optimized/BinaryHeap#push
export class Array<T> {
// ...
push(value: T): i32 {
var length = this.length_;
var newLength = length + 1;
ensureSize(changetype<usize>(this), newLength, alignof<T>());
// ...
return newLength;
}
// ...
}
Jusqu'à présent, tout est correct: la nouvelle longueur du tableau est égale à la longueur actuelle, augmentée de 1. Ensuite, un appel à la fonction ensureSize () suit pour s'assurer qu'il y a suffisamment de capacité dans le buffer (Capacity) pour le nouvel élément.
function ensureSize(array: usize, minSize: usize, alignLog2: u32): void {
// ...
if (minSize > <usize>oldCapacity >>> alignLog2) {
// ...
let newCapacity = minSize << alignLog2;
let newData = __renew(oldData, newCapacity);
// ...
}
}
La fonction ensureSize () vérifie à son tour: La capacité est-elle inférieure au nouveau minSize? Si tel est le cas, allouez un nouveau tampon minSize à l'aide de la fonction _renew (). Cela implique de copier toutes les données de l'ancien tampon vers le nouveau tampon. Pour cette raison, notre test de remplissage du tableau avec 1 million de valeurs (un élément après l'autre) conduit à la réallocation d'une grande quantité de mémoire et crée beaucoup de déchets.
Dans d'autres bibliothèques (comme std :: vec dans Rust ou slicesdans Go), le nouveau tampon a deux fois la capacité de l'ancien, ce qui contribue à rendre le processus de travail avec la mémoire moins coûteux et plus lent. Je travaille sur ce problème dans ASC, et jusqu'à présent, la seule solution est de créer mon propre CustomArray, avec sa propre optimisation de la mémoire.

Désormais, l'incrémental est aussi rapide que minimal et stub. Mais JavaScript reste le leader dans ce cas de test. Je pourrais probablement faire plus d'optimisations au niveau du langage, mais ce n'est pas un article sur la façon d'optimiser AssemblyScript lui-même. J'ai déjà plongé assez profondément.
Il existe de nombreuses optimisations simples que le compilateur AssemblyScript pourrait faire pour moi. À cette fin, l'équipe ASC travaille sur un optimiseur IR (Intermediate Representation) de haut niveau appelé AIR. Cela peut-il accélérer le travail et m'éviter d'avoir à optimiser manuellement l'accès à la baie à chaque fois? Le plus probable. Sera-ce plus rapide que JavaScript? Dur à dire. Mais en tout cas, c'était intéressant pour moi de concourir pour ASC, d'évaluer les capacités de JS et de voir ce qu'un langage plus "mature" avec des outils de compilation "très intelligents" peut réaliser.
Rouille et C ++
J'ai réécrit le code dans Rust, aussi idiomatiquement que possible, et je l'ai compilé en WebAssembly. Il s'est avéré plus rapide que AssemblyScript (naïf), mais plus lent que notre AssemblyScript optimisé avec CustomArray. Ensuite, j'ai optimisé le module compilé à partir de Rust de la même manière que AssemblyScript. Avec cette optimisation, le module Wasm basé sur Rust est plus rapide que notre AssemblyScript optimisé, mais toujours plus lent que JavaScript.
J'ai adopté la même approche pour C ++, en utilisant Emscripten pour compiler en WebAssembly . À ma grande surprise, même la première option sans optimisation s'est avérée être pas pire que JavaScript.

Il n'y a pas d'URL d'image ici. J'ai moi-même pris une capture d'écran.
Les versions marquées comme idiomatiques étaient de toute façon influencées par le code source de JS. J'ai essayé d'utiliser ma connaissance des idiomes de Rust, C ++, mais l'installation était fermement dans ma tête que je faisais du portage. Je suis sûr que quelqu'un avec plus d'expérience dans ces langages pourrait implémenter la tâche à partir de zéro et le code serait différent.
Je suis presque sûr que les modules Rust et C ++ pourraient fonctionner encore plus rapidement. Mais je n'avais pas une connaissance assez approfondie de ces langues pour en tirer davantage.
Encore une fois sur la taille des binaires
Jetons un coup d'œil aux tailles des binaires après la compression gzip. Par rapport à Rust et C ++, les binaires AssemblyScript sont en effet beaucoup plus légers.
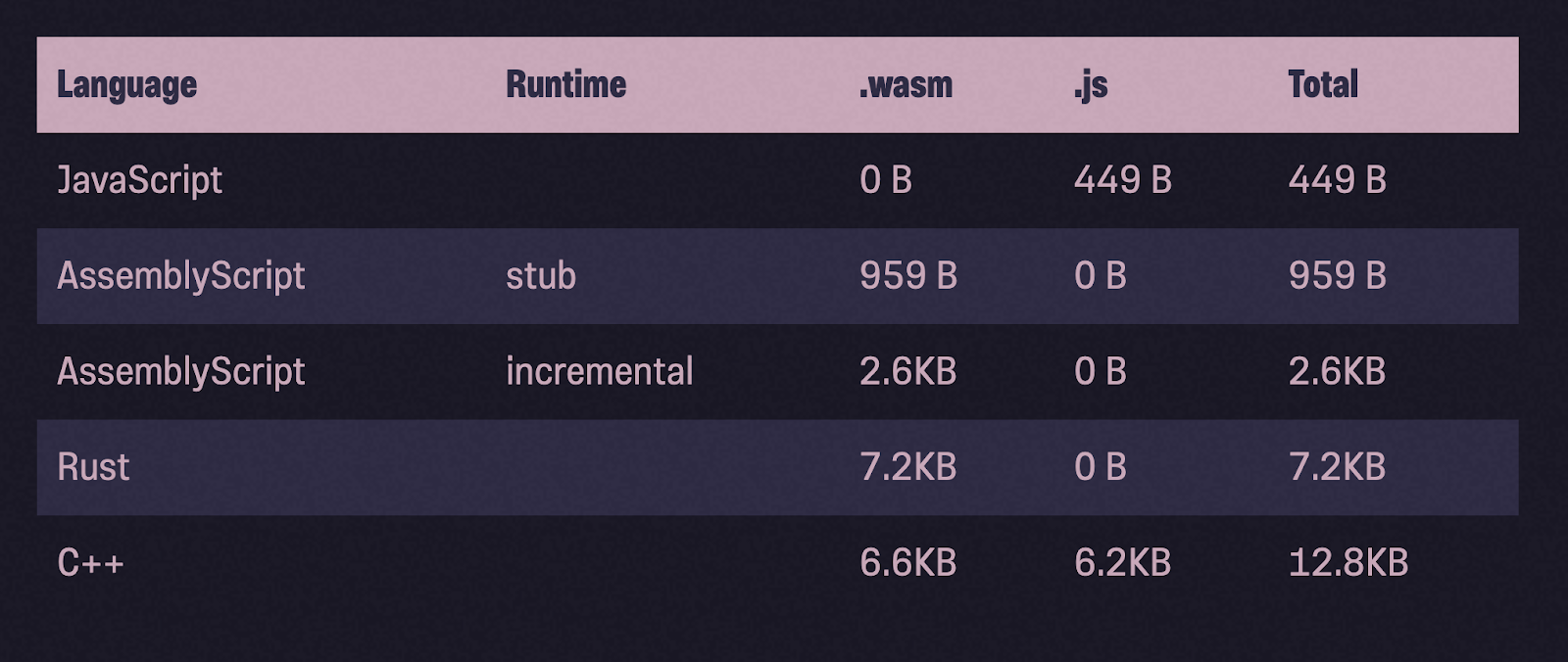
Et pourtant ... des recommandations
J'ai écrit à ce sujet au début de l'article, et je vais le répéter maintenant: les résultats sont, au mieux, des lignes directrices approximatives. Par conséquent, il serait imprudent de donner des estimations quantitatives généralisées de la productivité sur leur base. Par exemple, vous ne pouvez pas dire que Rust est 1,2 fois plus lent que JavaScript dans tous les cas. Ces chiffres sont très dépendants du code que j'ai écrit, des optimisations que j'ai appliquées et de la machine que j'ai utilisée.
Néanmoins, je pense qu'il existe des lignes directrices générales que nous pouvons apprendre pour vous aider à mieux comprendre le sujet et à prendre de meilleures décisions:
- Liftoff AssemblyScript Wasm-, , , Ignition SparkPlug JavaScript. JS-, WebAssembly — .
- V8 JavaScript-. WebAssembly , JavaScript, , .
- , , .
- Les modules AssemblyScript sont généralement beaucoup plus légers que les modules Wasm compilés à partir d'autres langages. Dans cet article, le binaire AssemblyScript n'était pas plus petit que le binaire JavaScript, mais l'inverse est vrai pour les modules plus volumineux, comme indiqué par l'équipe de développement ASC.
Si vous ne me croyez pas (et que vous n’êtes pas obligé) et que vous voulez découvrir le code des cas de test par vous-même, les voici .
Nos serveurs peuvent être utilisés pour le développement WebAssembly.
Inscrivez-vous en utilisant le lien ci-dessus ou en cliquant sur la bannière et bénéficiez d'une remise de 10% pour le premier mois de location d'un serveur de toute configuration!
