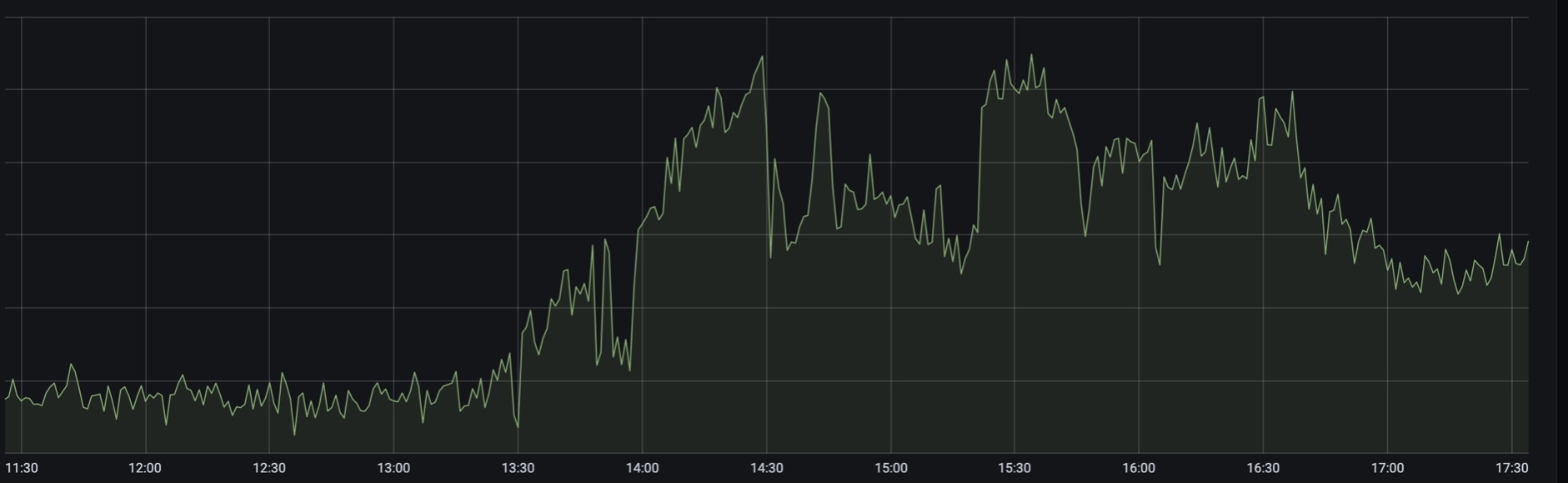
vers 13 h 30, la charge de recherche pour l'aviation et les billets de train a fortement augmenté. Quelque part à ce moment, les chemins de fer russes ont signalé des interruptions du site Web et de l'application, et nous avons commencé à verser de toute urgence des instances supplémentaires de backends dans tous les centres de données.
Mais en fait, les problèmes ont commencé plus tôt. Vers 8 heures du matin, la surveillance a envoyé une alerte sur le fait que sur l'une des répliques de la base de données, nous avons quelque chose de suspect de nombreux processus de longue durée. Mais nous l'avons manqué, considéré comme pas très important.
Introduction
Notre infrastructure s'est considérablement développée en près de vingt ans de développement. Les applications vivent sur trois plates-formes - l' ancien code php dans un monolithe , la première version des microservices est sur une plate-forme avec une orchestration auto-faite, la seconde, stratégiquement correcte, est OKD, où les services go, php et nodejs vivent. Autour de tout cela, des dizaines de bases mysql avec une liaison pour HA - la "guirlande" principale servant le monolithe, et de nombreuses paires maître-hotstandby pour les microservices. En plus d'eux, les memkesh, les kafkas, les mongas, les radis, les élastiques, sont également loin d'être un seul exemplaire. Nginx et envoyé en tant que proxy frontal . Le tout vit dans trois emplacements de réseau et nous partons de l'hypothèse que la perte de l'un d'entre eux n'affecte pas les utilisateurs.
-: mysql
Nous avons trois produits chargés. L'horaire des trains, où il y a juste beaucoup de trafic d'entrée. L'horaire des trains pour les trains longue distance et l'achat et la réservation de billets de train - il y a beaucoup de trafic et la recherche est plus difficile. Aviation avec des recherches très difficiles, cache multi-étapes, beaucoup d'options dues aux transferts et fourchettes "plus ou moins 3 jours". Il y a longtemps, les trois produits ne vivaient que dans un monolithe, puis nous avons commencé à déplacer lentement des pièces individuelles vers des microservices. Les premiers à être démantelés ont été les trains électriques et, malgré le fait que le pic de mai tombe généralement sur eux, la nouvelle architecture est très pratique et facile à adapter à la croissance de la charge. Dans le cas de l'aviation, la plus grande partie du monolithe a été volée, et au moment même du jour P, des tests A / B de la géographie sagest se déroulaient depuis une semaine. Nous avons comparé deux versions de l'implémentation - une nouvelle,sur elasticsearch et l'ancien mysql. Au moment de son lancement, le 15 avril, ils avaient déjà attrapé un tas de problèmes, mais ensuite ils ont été rapidement conçus, corrigé le code et décidé qu'il ne se déclencherait plus.
Tirer. Il convient de noter que l'ancienne version est sa propre implémentation de la recherche en texte intégral et du classement sur mysql. Ce n'est pas la meilleure solution, mais qui a fait ses preuves et qui fonctionne principalement. Les problèmes commencent lorsqu'une des tables est fortement fragmentée, puis toutes les requêtes avec sa participation commencent à ralentir et à charger fortement le système. Et, évidemment, à 8 heures du matin, nous avons franchi ce seuil de fragmentation, signalé par l'alerte. La réaction standard à une situation aussi rare, mais toujours attendue, est de retirer une réplique terne de la charge (avec notre couche de proxy de proxysql, c'est facile à faire), puis d'exécuter optimiser + analyser, puis de la renvoyer. Compte tenu de la réserve de marche en temps normal sous charge normale, cela ne pose aucun problème. Mais ici, dans un temps calme, nous n'avons pas traité cette alerte.
13:20
À cette époque, les nouvelles sur les vacances de mai et les jours chômés retentissent.
Trafic de pointe vers 13h30
Comme nous l'avons découvert plus tard, quelques minutes seulement après l'annonce du week-end supplémentaire (qui n'est pas un week-end, mais un «week-end»), le trafic a commencé à augmenter. Le chargement est allé brusquement. Au sommet, il était de 2,5 à 3 fois la norme, et cela a continué pendant plusieurs heures.
Nous avons été presque immédiatement bombardés par des «alertes d'urgence» - des alertes de niveau de criticité «réveiller et réparer». Tout d'abord, c'était une alerte sur la croissance de 50 * erreurs que nous envoyons aux clients depuis notre frontproxy. À un niveau inférieur, une alerte pour les erreurs de connexion à la base de données s'est déclenchée et dans les journaux, nous avons vu quelque chose comme ceci: "DB: Délai maximal de connexion atteint en atteignant le groupe d'hôtes 102 après 3162 ms". De plus, des alertes sur le manque de capacité des trois groupes de serveurs d'applications de l'ancienne plate-forme monolithique. Alerte tempête dans sa forme la plus pure.
L'idée des raisons est venue presque instantanément, avant même d'entrer dans le calendrier avec les demandes entrantes - les nouvelles sur les «vacances» avaient déjà clignoté dans la correspondance interne dans les chats.
Ayant repris leurs esprits un peu dans une situation d'Achtung presque complète, ils ont commencé à réagir. Mettez à l'échelle les serveurs d'applications, gérez les erreurs à l'interface entre l'application et la base. Nous nous sommes rapidement souvenus de l'alerte qui «brûlait» le matin et avons retrouvé nos vieilles connaissances de la géographie triste dans la liste des processus de la remarque malade. Nous avons contacté l’équipe d’avia et elle a confirmé que la croissance du trafic au cours des derniers jours d’avril, qui n’a même pas été proche au cours des 15 dernières années, est réelle. Et ce n'est pas une attaque, pas une sorte de problème d'équilibrage, mais des utilisateurs en direct naturels. Et sous leurs demandes vives, notre réplique déjà surchargée est devenue complètement malade.
Alexey, notre DBA, a retiré la réplique de la charge, a cloué des processus de longue durée et a suivi la procédure standard d'optimisation de table. Tout cela est rapide, quelques minutes, mais pendant ce temps, sous un tel trafic, les répliques restantes se sont encore aggravées. Nous l'avons compris, mais nous l'avons choisi comme le moindre des maux.
Presque en parallèle, vers 13h40, de nouveaux serveurs d'applications ont commencé à être versés, réalisant que cette charge n'est pas quelque chose qui ne disparaîtra pas rapidement d'elle-même, mais peut plutôt se développer, et le processus lui-même pour la partie monolithique ne l'est pas. très vite.
La manipulation de la base a aidé pendant un certain temps. De 13h50 à 14h30 environ, tout était calme.
Deuxième pic - vers 14h30
À ce moment-là, la surveillance nous a informés que le site Web des chemins de fer russes était en panne. Eh bien, en fait, il a dit que les backends des trains se sont détériorés, et nous avons appris l'existence des chemins de fer russes plus tard, lorsque la nouvelle est sortie . En temps réel, cela ressemblait à ça pour nous.

La charge semble être liée à des interruptions sur le site Web des chemins de fer russes
. Malheureusement, la plupart des trains vivent encore dans un monolithe et ne peuvent être mis à l'échelle au niveau de l'application qu'en ajoutant de nouveaux backends. Et ceci, comme je l'ai écrit plus haut, est une procédure lente et difficile à accélérer. Par conséquent, il ne restait plus qu'à attendre que les automatismes déjà lancés fonctionnent. Dans les microservices, tout est bien plus simple, bien sûr, mais le déménagement en lui-même ... bien que ce soit une autre histoire.
L'attente n'était pas ennuyeuse. En environ 5 minutes, le goulot d'étranglement du système d'une manière encore pas tout à fait claire "poussé" de la couche application à la couche base de données, soit à la base elle-même, soit à proxysql. Et à 14h40, nous avions complètement arrêté d'écrire sur le cluster mysql principal. Ce qui s'est passé exactement là-bas, nous n'avons pas encore compris, mais le changement du maître en réserve hotstandby a aidé. Et après 10 minutes, nous avons rendu le disque. À peu près au même moment, ils ont décidé de transférer de force toute la charge du sadget à l'élastique, sacrifiant les résultats de la campagne AB. À quel point cela a-t-il aidé, ils ne s'en sont pas rendu compte non plus, mais cela n'a certainement pas empiré.
15h00
L'enregistrement a pris vie, il semble que tout devrait bien se passer, et la charge sur les répliques et sur proxysql devant eux est normale. Mais pour une raison quelconque, les erreurs lors des requêtes de lecture de l'application vers la base de données ne s'arrêtent pas. En environ 15 à 20 minutes de coller aux graphiques sur différentes couches et de rechercher au moins certains modèles, nous avons réalisé que les erreurs proviennent d'un seul proxysql. Redémarrez-le et les erreurs ont disparu. La cause profonde a été déterrée beaucoup plus tard, avec une analyse détaillée de l'échec. Il s'est avéré que lors de la dernière urgence, une semaine auparavant, lors du début de la campagne AB sur sagest, proxysql n'a pas correctement fermé les connexions avec l'une des répliques de la guirlande, qui a ensuite été manipulée. Et sur cette instance de proxysql, nous avons bêtement rencontré un manque de ports pour le trafic sortant. Cette métrique, bien sûr, va, mais il ne nous est jamais venu à l'esprit de suspendre une alerte dessus. Maintenant, il est déjà là.
15:20
Tous les produits ont été restaurés, à l'exception des trains.
15:50
Les derniers backends de train ont été étendus. Habituellement, cela ne prend pas deux heures, mais une heure, mais ici, ils se sont un peu trompés dans une situation stressante.
Comme cela arrive souvent, il a été réparé à un endroit, cassé à un autre. Les backends ont commencé à accepter plus de connexions, les front-proxies ont commencé à moins abandonner les demandes des clients en raison du débordement des flux en amont, ce qui a entraîné une augmentation du trafic interservices interne. Et il y avait un service d'autorisation. Il s'agit d'un microservice, mais pas dans OKD, mais sur une ancienne plate-forme. La mise à l'échelle est plus simple que dans monolith, mais pire que dans OKD. Nous l'avons soulevé pendant environ 15 minutes, en modifiant plusieurs fois les paramètres et en ajoutant des capacités, mais à la fin, cela a également fonctionné.
16:10
Hourra, tout fonctionne, tu peux aller déjeuner.
Belles images
Ils sont beaux car ils ne sont pas pleinement informatifs, mais les axes n'ont pas été testés par le Conseil de sécurité.
Graphique des 500:

Le tableau général de la charge pendant 2 jours:
Conclusions du capitaine
- Merci de ne pas l'avoir fait ce soir.
- Vous devez faire quelque chose au sujet des alertes. Il y en a déjà beaucoup, mais, d'une part, ce n'est toujours pas suffisant, et d'autre part, certains sont épuisés, notamment à cause de la quantité. Et le coût du support augmente à chaque nouvelle alerte. En général, il y a encore une compréhension du problème, mais il n'y a pas de solution stratégique. Il se cache quelque part à la jonction des processus et des outils que nous recherchons. Mais nous avons déjà abordé quelques alertes tactiquement.
- . , - proxysql , . , .
- , OKD . .
- . , , , .