Le post # 3 pour les débutants est consacré à la génération de distributions, de leurs propriétés et de graphiques pour leur analyse comparative.
Baker et Poincaré
Il existe une légende, presque certainement apocryphe, qui permet de considérer plus en détail la question de savoir comment le théorème central limite permet de raisonner sur le principe de la formation des distributions statistiques. Il s'agit du célèbre polymathe français du XIXe siècle, Henri Poincaré, qui, selon la légende, passait un an chaque jour à peser une miche de pain fraîche.
À cette époque, la cuisson était réglementée par l'État et Poincaré a constaté que, bien que les résultats de la pesée des pains de pain obéissent à une distribution normale, le pic ne se situait pas au 1 kg annoncé publiquement, mais à 950 g. Il a informé les autorités de la boulanger à qui il achetait régulièrement du pain et il a été condamné à une amende. C'est la légende ;-).
L'année suivante, Poincaré continue de peser des miches de pain du même boulanger. Il a constaté que la moyenne était maintenant de 1 kg, mais que la distribution n'était plus symétrique autour de la moyenne. Il a maintenant été déplacé vers la droite. Cela concordait avec le fait que le boulanger ne donnait plus à Poincaré que le plus lourd de ses pains. Poincaré a de nouveau dénoncé le boulanger aux autorités et le boulanger a été condamné une deuxième fois à une amende.
Que ce soit vraiment le cas ou non n'a pas d'importance ici; cet exemple ne sert qu'à illustrer un point clé - la distribution statistique d'une séquence de nombres peut nous dire quelque chose d'important sur le processus qui l'a créée.
Générer des distributions
, , stats.norm.rvs. (rvs . normal variates, .. ). 1000, 1 . , 30.
def honest_baker(mu, sigma):
''' '''
return pd.Series( stats.norm.rvs(loc, scale, size=10000) )
def ex_1_18():
''' '''
honest_baker(1000, 30).hist(bins=25)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, :

, . ( « ») :
def dishonest_baker(mu, sigma):
''' '''
xs = stats.norm.rvs(loc, scale, size=10000)
return pd.Series( map(max, bootstrap(xs, 13)) )
def ex_1_19():
''' '''
dishonest_baker(950, 30).hist(bins=25)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, :
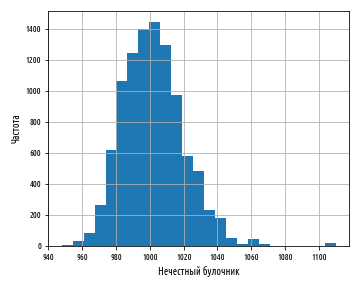
, , , . - 1 , . , .
. , , , . , , , .

pandas skew
:
def ex_1_20():
''' '''
s = dishonest_baker(950, 30)
return { '' : s.mean(),
'' : s.median(),
'': s.skew() }
{'': 0.4202176889083849,
'': 998.7670301469957,
'': 1000.059263920949}
, 0.4. , .
. , quantile
0 1 . 0.5- .
, . , -, Q-Q, . Q-Q plot. . , , . , .
. qqplot
, :
def qqplot( xs ):
''' ( -, Q-Q plot)'''
d = {0:sorted(stats.norm.rvs(loc=0, scale=1, size=len(xs))),
1:sorted(xs)}
pd.DataFrame(d).plot.scatter(0, 1, s=5, grid=True)
df.plot.scatter(0, 1, s=5, grid=True)
plt.xlabel(' ')
plt.ylabel(' ')
plt.title (' ', fontweight='semibold')
def ex_1_21():
'''
'''
qqplot( honest_baker(1000, 30) )
plt.show()
qqplot( dishonest_baker(950, 30) )
plt.show()
:

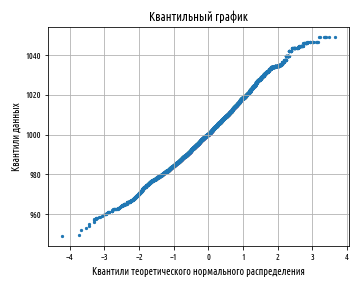
. :
, , , ; . , :

: , , , , ,
. ( ) .
() . , . , , .
, « », — , . :
def ex_1_22():
'''
'''
d = {' ' :honest_baker(1000, 30),
' ':dishonest_baker(950, 30)}
pd.DataFrame(d).boxplot(sym='o', whis=1.95, showmeans=True)
plt.ylabel(' (.)')
plt.show()
:

. — . — . , , . , .
. . , .
(), , . Cumulative Distribution Function (CDF), , , , x. , 0 1, 0 — , 1 — . , , . , 6?
5/6. , , , 1/6. — 50%.
, — , . , , , .
— . 0.5- 1000, 1000 0.5.
, pandas quantile
, empirical_cdf
0 1. , .. ( ) , , , , .
— , .
. pandas plot
, — — , . plot
, x y . pandas DataFrame
.
, plot
. pandas , . plot
, (ax
) plot
, (ax=ax
). . , . , (tp[1]
tp[3]
) , :
def empirical_cdf(x):
''' x'''
sx = sorted(x)
return pd.DataFrame( {0: sx, 1:sp.arange(len(sx))/len(sx)} )
def ex_1_23():
'''
'''
df = empirical_cdf(honest_baker(1000, 30))
df2 = empirical_cdf(dishonest_baker(950, 30))
ax = df.plot(0, 1, label=' ')
df2.plot(0, 1, label=' ', grid=True, ax=ax)
plt.xlabel(' ')
plt.ylabel('')
plt.legend(loc='best')
plt.show()
:
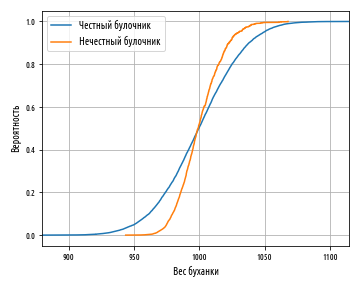
, -, , . , 0.5, 1000 . , .
, 4, «Python, » .