«Je ne vois rien en elle,» dis-je en rendant le chapeau à Sherlock Holmes.
«Non, Watson, tu vois, mais tu ne prends pas la peine de réfléchir à ce que tu vois.
Arthur Conan Doyle. Carbuncle bleu
Dans la série précédente pour débutants (premier article ici ) d'un remix du livre de Henry Garner Clojure for Data Science in Python, plusieurs approches numériques et visuelles ont été présentées pour comprendre ce qu'est une distribution normale. Nous avons discuté de plusieurs statistiques descriptives telles que la moyenne et l'écart type, et comment elles peuvent être utilisées pour résumer de grandes quantités de données en un mot.
Un ensemble de données est généralement un échantillon d'une population plus large ou de la population générale. Parfois, cette population est trop importante pour être entièrement mesurée. Parfois, il est incommensurable dans la nature parce qu'il est de taille infinie ou parce qu'il n'est pas directement accessible. Dans tous les cas, nous sommes contraints de tirer des conclusions sur la base des données dont nous disposons.
Dans cette série de 4 publications, nous examinerons l'implication statistique de la façon dont vous pouvez aller au-delà de la simple description d'échantillons et plutôt décrire la population à partir de laquelle ils ont été tirés. Nous examinerons de plus près notre degré de confiance dans les conclusions que nous tirons des données échantillonnées. Nous allons révéler l'essence d'une approche robuste pour résoudre des problèmes dans le domaine de la science des données, qui est le test d'hypothèses statistiques, qui apporte juste de la scientificité à l'étude des données.
En outre, au cours de la présentation, les points douloureux associés à la dérive terminologique des statistiques nationales, occultant parfois le sens et les concepts de substitution, seront mis en évidence. À la fin du dernier message, vous pouvez voter pour ou contre la prochaine série de messages. Jusque là ...
, AcmeContent, .
AcmeContent
, , , AcmeContent . -, .
, AcmeContent - — . , -. , , - , - , AcmeContent , .
(dwell time)— , - , .
(bounce) — , — .
, , - - - - - - AcmeContent.
, : scipy, pandas matplotlib. pandas Excel, read_excel
. . pandas read_csv
, URL- .
- AcmeContent — - . :
ex_N_M, ex - example (), N - M - . . , .. - . , .
def load_data( fname ):
return pd.read_csv('data/ch02/' + fname, '\t')
def ex_2_1():
return load_data('dwell-times.tsv').head()
( Python Jupyter), , :
|
|
date |
dwell-time |
0 |
2015-01-01T00:03:43Z |
74 |
1 |
2015-01-01T00:32:12Z |
109 |
2 |
2015-01-01T01:52:18Z |
88 |
3 |
2015-01-01T01:54:30Z |
17 |
4 |
2015-01-01T02:09:24Z |
11 |
… |
… |
… |
, .
, dwell-time hist:
def ex_2_2():
load_data('dwell-times.tsv')['dwell-time'].hist(bins=50)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
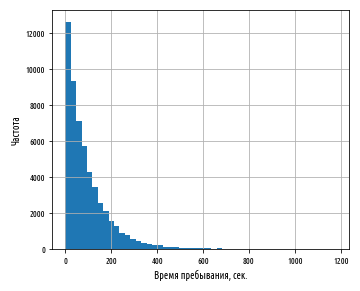
, ; . ( - 0 .). X , , .
, , , Y . , , . , « », . , , .
, , . , 10, , 5 10 4 . , — 30 10 20 . — .
Y logy=True
pandas plot.hist
:
def ex_2_3():
load_data('dwell-times.tsv')['dwell-time'].plot.hist(bins=20, logy=True)
plt.xlabel(' , .')
plt.ylabel(' ')
plt.show()
pandas , 10 . , , -. , - ( , loglog=True
).
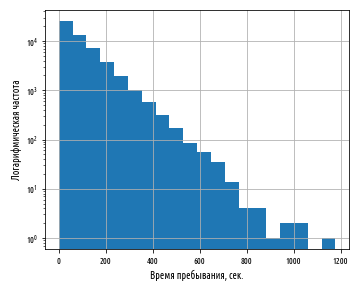
, — . , 10, , , .
— .
( ) , . , , , .
, — . , , . , — , -.
. :
def ex_2_4():
ts = load_data('dwell-times.tsv')['dwell-time']
print(': ', ts.mean())
print(': ', ts.median())
print(' :', ts.std())
: 93.2014074074074
: 64.0
: 93.96972402519819
. , . — .
.
( ). . , -, , , -, . 93 ., , 93 ., - .
, , - 93 . , , - 93 ., 5 . , .
x .
, . , ( ).
64 ., - . 93 . , . 6 . , . .
- . , , . Python, pandas — to_datetime.
, date-time, , , 1- Series
pandas , . , errors='ignore'
, . , mean_dwell_times_by_date
resample
. -, . 'D'
, mean
. , dt.resample('D').mean()
:
def with_parsed_date(df):
''' date date-time'''
df['date'] = pd.to_datetime(df['date'], errors='ignore')
return df
def filter_weekdays(df):
''' '''
return df[df['date'].index.dayofweek < 5] # ..
def mean_dwell_times_by_date(df):
''' '''
df.index = with_parsed_date(df)['date']
return df.resample('D').mean() #
def daily_mean_dwell_times(df):
''' - '''
df.index = with_parsed_date(df)['date']
df = filter_weekdays(df)
return df.resample('D').mean()
, :
def ex_2_5():
df = load_data('dwell-times.tsv')
mus = daily_mean_dwell_times(df)
print(': ', float(means.mean()))
print(': ', float(means.median()))
print(' : ', float(means.std()))
: 90.21042865056198
: 90.13661202185793
: 3.7223429053200348
90.2 . , , . , 3.7 . , , . :
def ex_2_6():
df = load_data('dwell-times.tsv')
daily_mean_dwell_times(df)['dwell-time'].hist(bins=20)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
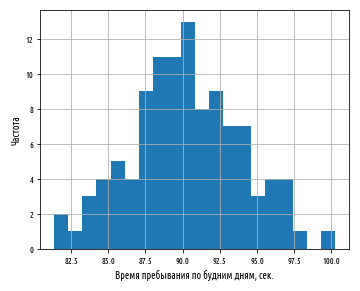
, 90 . 3.7 . , , .. , .
, . , , .
, , .
, - , — , , , . , , .
. , , . ( dropna, , ):
def ex_2_7():
''' '''
df = load_data('dwell-times.tsv')
means = daily_mean_dwell_times(df)['dwell-time'].dropna()
ax = means.hist(bins=20, normed=True)
xs = sorted(means) #
df = pd.DataFrame()
df[0] = xs
df[1] = stats.norm.pdf(xs, means.mean(), means.std())
df.plot(0, 1, linewidth=2, color='r', legend=None, ax=ax)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
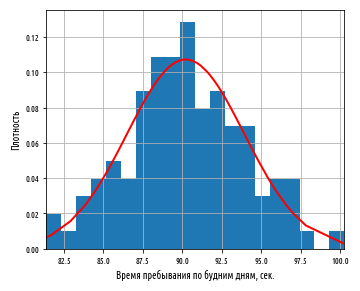
, , , 3.7 . , , 90 . , . 3.7 . — , , .
, (Standard Error, . SE) , , .
— .
, 6 . , , :

σx — , x, n — . , . . , — , :
def variance(xs):
''' () n <= 30'''
x_hat = xs.mean()
n = len(xs)
n = n-1 if n in range(1, 30) else n
square_deviation = lambda x : (x – x_hat) ** 2
return sum( map(square_deviation, xs) ) / n
def standard_deviation(xs):
return sp.sqrt(variance(xs))
def standard_error(xs):
return standard_deviation(xs) / sp.sqrt(len(xs))
:
. , , , .
, , , . , .
Le sujet du prochain article, le post # 2 , sera la différence entre les échantillons et la population, ainsi que l'intervalle de confiance. Oui, c'est l'intervalle de confiance , pas l'intervalle de confiance.