Ce dernier article concerne l'analyse de la variance. Voir le post précédent ici .
Analyse de la variance
Analyse de la variance (variance), qui dans la littérature spécialisée est également appelée ANOVA de l'anglais. L'analyse de la variance est un ensemble de méthodes statistiques utilisées pour mesurer la signification statistique des différences entre les groupes. Il a été développé par le statisticien extrêmement doué Ronald Fisher, qui a également popularisé le test de signification statistique dans ses articles de recherche sur les tests biologiques.
Noter... Dans les articles précédents et dans cette série d'articles, le terme «variance» était utilisé dans notre terme accepté «variance» et le terme «variance» était indiqué entre parenthèses à certains endroits. Ce n’est pas une coïncidence. À l'étranger, il existe des termes appariés «variance» et «covariance», et en théorie, ils devraient être traduits avec une racine, par exemple, par «variance» et «covariance», mais en fait, nous avons une connexion appariée rompue, et ils sont traduit par «variance» et «covariance» complètement différentes. Mais ce n'est pas tout. La «dispersion» (variance statistique) à l'étranger est un concept générique distinct de dispersion, c'est-à-dire le degré d'étirement ou de contraction de la distribution et les mesures de la variance statistique sont la variance, l'écart type et l'intervalle interquartile. La dispersion, en tant que concept générique de dispersion, et la variance, en tant que l'une de ses mesures,mesurer la distance par rapport à la moyenne sont deux concepts différents. Plus loin dans le texte pour la variance, le terme généralement accepté "variance" sera utilisé partout. Cependant, cette divergence de terminologie doit être prise en compte.
z- t- . , , , .
, . , .
, page par page et combinée")
, , . - . , , .
— . , , . , , .
F-
F- — .
— 1, — . k , n — , :


F- pandas plot
:
def ex_2_Fisher():
''' F- '''
mu = 0
d1_values, d2_values = [4, 9, 49], [95, 90, 50]
linestyles = ['-', '--', ':', '-.']
x = sp.linspace(0, 5, 101)[1:]
ax = None
for (d1, d2, ls) in zip(d1_values, d2_values, linestyles):
dist = stats.f(d1, d2, mu)
df = pd.DataFrame( {0:x, 1:dist.pdf(x)} )
ax = df.plot(0, 1, ls=ls,
label=r'$d_1=%i,\ d_2=%i$' % (d1,d2), ax=ax)
plt.xlabel('$x$\nF-')
plt.ylabel(' \n$p(x|d_1, d_2)$')
plt.show()

F- , 100 , 5, 10 50 .
F-
, , F-. F- , . F- :
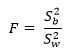
S2b — , S2w — .
F . , , . , , , .
F- , F. F .
F- . , . , k , x̅k, :

SSW — , xjk — j- .
SSW , Python, ssdev
, :
def ssdev( xs ):
'''
'''
mu = xs.mean()
square_deviation = lambda x : (x - mu) ** 2
return sum( map(square_deviation, xs) )
F- :

SST — , SSW — , . «» , :

, SST — - . Python SST SSW , .
ssw = sum( groups.apply( lambda g: ssdev(g) ) ) #
#
sst = ssdev( df['dwell-time'] ) #
ssb = sst – ssw #
F- . ssb
ssw
, F-.
Python F- :
msb = ssb / df1 #
msw = ssw / df2 #
f_stat = msb / msw
F- , F-.
F-
, , () , , .
scipy stats.f.sf
, . F- 20 , . , , F-. F-, F- F-, . f_test
, :
def f_test(groups):
m, n = len(groups), sum(groups.count())
df1, df2 = m - 1, n - m
ssw = sum( groups.apply(lambda g: ssdev(g)) )
sst = ssdev( df['dwell-time'] )
ssb = sst - ssw
msb = ssb / df1
msw = ssw / df2
f_stat = msb / msw
return stats.f.sf(f_stat, df1, df2)
def ex_2_24():
''' - F-'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
return f_test(groups)
0.014031745203658217
F- p-, scipy stats.f.sf
, . P- , .. - . . 5%- .
p-, 0.014, .. . - , .

- , :
def ex_2_25():
'''
- '''
df = load_data('multiple-sites.tsv')
df.boxplot(by='site', showmeans=True)
plt.xlabel(' -')
plt.ylabel(' , .')
plt.title('')
plt.suptitle('')
plt.show()
boxplot
, -. - 0, .

, - 10 , . , , , , 6, 144 .:
def ex_2_26():
'''T- 0 10 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_10 = groups.get_group(10)
_, p_val = stats.ttest_ind(site_0, site_10, equal_var=False)
return p_val
0.0068811940138903786
F-, , - 6 :
def ex_2_27():
'''t- 0 6 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_6 = groups.get_group(6)
_, p_val = stats.ttest_ind(site_0, site_6, equal_var=False)
return p_val
0.005534181712508717
, , , - 6 -. AcmeContent -. - - !
, , . , — , . . , , .
d
d — , , , , . , :
Sab — ( ) . :
def pooled_standard_deviation(a, b):
'''
( )'''
return sp.sqrt( standard_deviation(a) ** 2 +
standard_deviation(b) ** 2)
, 6 - d :
def ex_2_28():
''' d
- 6'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(6)
return (b.mean() - a.mean()) / pooled_standard_deviation(a, b)
0.38913648705499848
p-, d . , , . 0.5, , , 0.38 — . - , -, .
, . , , z-, t- F-.
, , , . — , — . , , F- 1- 2- .
.
Dans la prochaine série d'articles, si les lecteurs le souhaitent, nous appliquerons ce que nous avons appris sur la variance et le test F à des échantillons uniques. Nous présenterons une méthode d'analyse de régression et l'utiliserons pour trouver des corrélations entre des variables dans un échantillon d'athlètes olympiques.