
YELP est un réseau à l'étranger qui aide les gens à trouver des entreprises et des services locaux en fonction des commentaires, des préférences et des recommandations. Dans les articles actuels, une certaine analyse en sera réalisée à l'aide de la plateforme Neo4j, liée au SGBD graph, ainsi qu'au langage python.
Ce que nous verrons:
- comment travailler avec Neo4j et les grands ensembles de données en utilisant YELP comme exemple;
- comment l'ensemble de données YELP peut être utile;
- partiellement: quelles sont les fonctionnalités des nouvelles versions de Neo4j et pourquoi le livre "Graph Algorithms" 2019 par O'REILLY est déjà dépassé.
Qu'est-ce que le jeu de données YELP et yelp?
Le réseau YELP couvre actuellement 30 pays, la Fédération de Russie n'est pas encore incluse dans leur nombre. La langue russe n'est pas prise en charge par le réseau. Le réseau lui-même contient une quantité assez volumineuse d'informations sur différents types d'entreprises, ainsi que des critiques à leur sujet. En outre, yelp peut être appelé en toute sécurité un réseau social, car il contient des données sur les utilisateurs qui ont laissé des avis. Il n'y a pas de données personnelles là-bas, seulement des noms. Néanmoins, les utilisateurs forment des communautés, des groupes, ou ils peuvent être davantage unis dans ces groupes et communautés selon divers critères. Par exemple, par le nombre d'étoiles (étoiles) attribuées au point (restaurant, station-service, etc.) que vous avez visité.
YELP se décrit comme suit:
- 8635403 avis
- 160585 entreprises
- 200 000 images
- 8 mégalopoles
1 162 119 recommandations de 2 189 457 utilisateurs.
Plus de 1,2 million d'accessoires commerciaux: heures d'ouverture, parking, disponibilité, etc.
Depuis 2013, Yelp organise régulièrement le concours de l'ensemble de données Yelp, encourageant tout le monde à
explorer et à explorer l'ensemble de données ouvert Yelp.
Le jeu de données lui-même est disponible sur le lien Le
jeu de données est assez volumineux et après décompression, il se compose de 5 fichiers json:
tout irait bien, mais seul YELP télécharge des données brutes et non traitées et, pour commencer à travailler avec elles, un prétraitement est nécessaire.
Installation et configuration rapide de Neo4j
Pour l'analyse, Neo4j sera utilisé, nous utiliserons les capacités du SGBD graphique et leur langage de chiffrement simple pour travailler avec l'ensemble de données.
À propos de Neo4j en tant que base de données de graphes écrite à plusieurs reprises sur Habre ( ici et ici pour un article pour les débutants), donc resoumettre cela n'a aucun sens.
Pour commencer à travailler avec la plate-forme, vous devez télécharger la version de bureau (environ 500 Mo) ou travailler dans le bac à sable en ligne. Au moment d'écrire ces lignes, Neo4j Enterprise 4.2.6 pour les développeurs est disponible, ainsi que d'autres versions antérieures pour l'installation.
De plus, l'option sera utilisée - travailler dans la version de bureau dans l'environnement Windows (Neo4j Desktop 1.4.5, versions de base de données 4.2.5, 4.2.1).
Malgré le fait que la version la plus récente soit la 4.2.6, il vaut mieux ne pas l'installer encore, car tous les plugins utilisés dans neo4j n'ont pas encore été mis à jour pour cela. La version précédente - 4.2.5 suffira.
Après avoir installé le package téléchargé, vous devrez:
- créer une nouvelle base de données locale, en spécifiant l'utilisateur neo4j et le mot de passe 123 (pourquoi exactement ils seront expliqués ci-dessous),
photo

- installez les plugins dont vous avez besoin - APOC, Graph Data Science Library.
photo

- vérifier si la base de données démarre et si le navigateur s'ouvre lorsque vous cliquez sur le bouton de démarrage
photo


* - activer le mode hors ligne afin que la base de données n'essaye pas sérieusement de suggérer de nouvelles versions.
photo

Chargement des données dans Neo4j
Si tout s'est bien passé avec l'installation de Neo4j, vous pouvez passer à autre chose et il y a trois façons.
La première consiste à aller loin depuis l'importation de données dans la base de données à partir de zéro, y compris leur nettoyage et leur transformation initiaux.
La deuxième méthode consiste à charger la base de données terminée à partir du vidage et à commencer à l'utiliser.
La troisième méthode consiste à charger la base de données terminée directement dans le dossier contenant la base de données nouvellement créée.
Par conséquent, dans tous les cas, vous devriez obtenir une base de données avec les paramètres suivants:

et le schéma final:
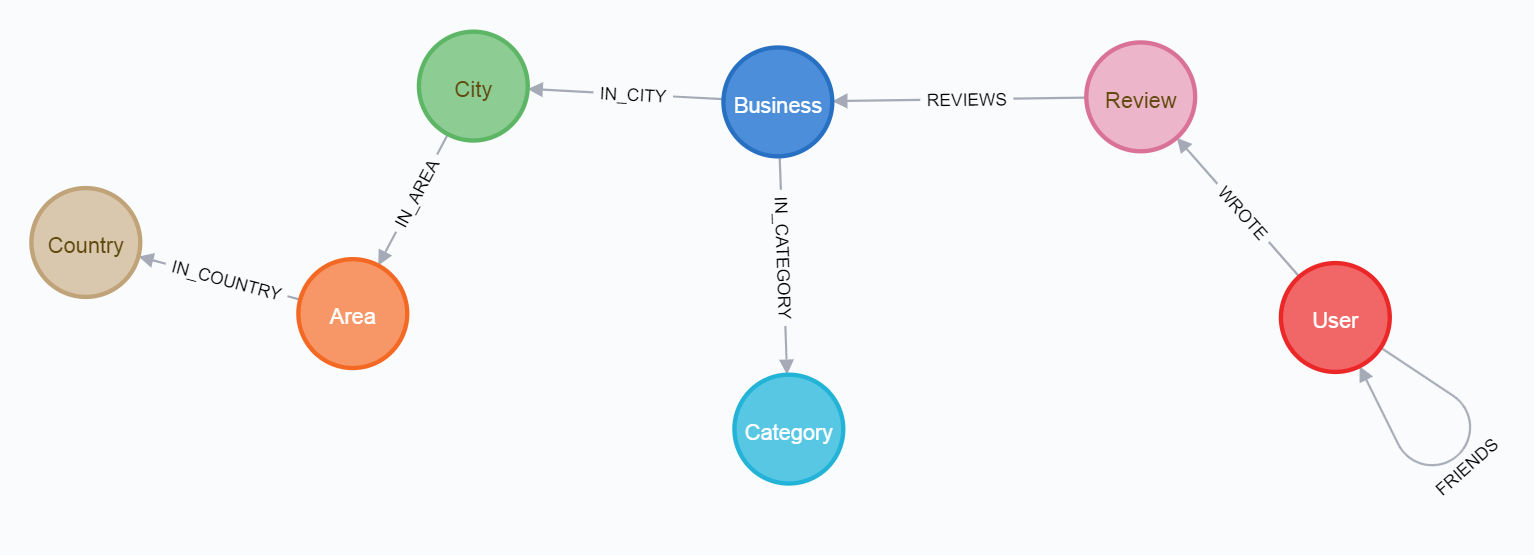
Pour passer par le premier chemin, il est préférable de lire d'abord l'article sur le support .
* Un grand merci à TRAN Ngoc Thach pour cela.
Et utilisez un notebook jupyter prêt à l'emploi (adapté par moi pour Windows) - lien .
Le processus d'importation n'est pas facile et prend assez de temps -

Il n'y a pas de problèmes de mémoire, même si vous n'avez que 8 Go de RAM, car l'importation par lots est utilisée.
Cependant, vous devrez créer un fichier d'échange de 10 Go, car lors de la vérification des données importées, jupyter se bloque, il y a une mention de ce point dans le cahier jupyter ci-dessus.
La deuxième manière est plus simple.
Créez une base de données, allez dans le dossier avec son neo4j-admin (chaque base de données a la sienne) et exécutez:
neo4j-admin load --from=G:\neo4j\dumps\neo4j.dump --database=neo4j --force
où G: \ neo4j \ dumps \ neo4j.dump est le chemin vers le vidage de la base de données.
La troisième voie est la plus rapide et a été découverte par accident. Cela implique de copier une base de données neo4j prête à l'emploi directement dans une base de données neo4j existante. Parmi les inconvénients (découverts jusqu'à présent) - vous ne pouvez pas sauvegarder la base de données en utilisant Neo4j (neo4j-admin dump --database = neo4j --to = D: \ neo4j \ neo4j.dump). Cependant, cela peut être dû à des différences de versions - dans la version 4.2.1, la base de données a été copiée à partir de la version 4.2.5. De plus, des artefacts apparaissent sur le schéma général de la base de données, qui n'affectent néanmoins pas son fonctionnement.
Comment cette méthode est implémentée:
- ouvrir l'onglet Gérer de la base de données où l'importation sera effectuée
photo


- allez dans le dossier contenant la base de données et copiez-y le dossier de données, en écrasant les correspondances possibles
photo

Dans ce cas, la base de données elle-même, où la copie a été effectuée, ne doit pas être démarrée.
- Redémarrez Neo4j.
Et c'est là que le mot de passe de connexion qui était précédemment utilisé (neo4j, 123) sera utile pour éviter les conflits.
Après le démarrage de la base de données copiée, une base de données avec un jeu de données yelp sera disponible:

Regarder YELP
Vous pouvez étudier YELP à la fois à partir du navigateur Neo4j et en envoyant des requêtes à la base de données à partir du même notebook jupyter.
En raison du fait que la base de données est graphique, le navigateur sera accompagné d'une image visuelle agréable sur laquelle ces graphiques seront affichés.
Pour commencer à se familiariser avec YELP, il est nécessaire de faire une réservation que la base de données ne contiendra que 3 pays US, KG et CA:

Vous pouvez afficher le schéma de la base de données en écrivant une requête en langage chiffré dans le navigateur neo4j:
CALL db.schema.visualization()
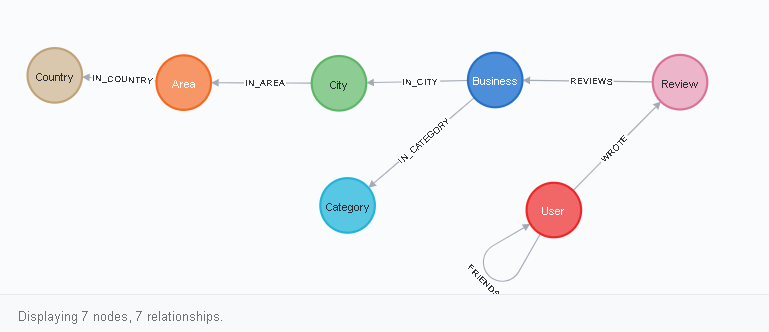
Comment lire ce diagramme? Tout ressemble à ça. Le nœud Utilisateur a un lien vers lui-même de type FRIENDS, ainsi qu'un lien WROTE vers le nœud Review. Rewiew, à son tour, a une connexion REVIEWS avec Business, et ainsi de suite. Vous pouvez le voir visuellement après avoir cliqué sur l'un des sommets (étiquettes de nœud), par exemple, sur Utilisateur: la

base de données sélectionnera 25 utilisateurs et les montrera:

Si vous cliquez sur l'icône correspondante directement sur l'utilisateur, alors tous les connexions directes de lui seront affichées, et ainsi que les connexions pour les utilisateurs de deux types - AMIS et EXAMEN, alors toutes apparaîtront:
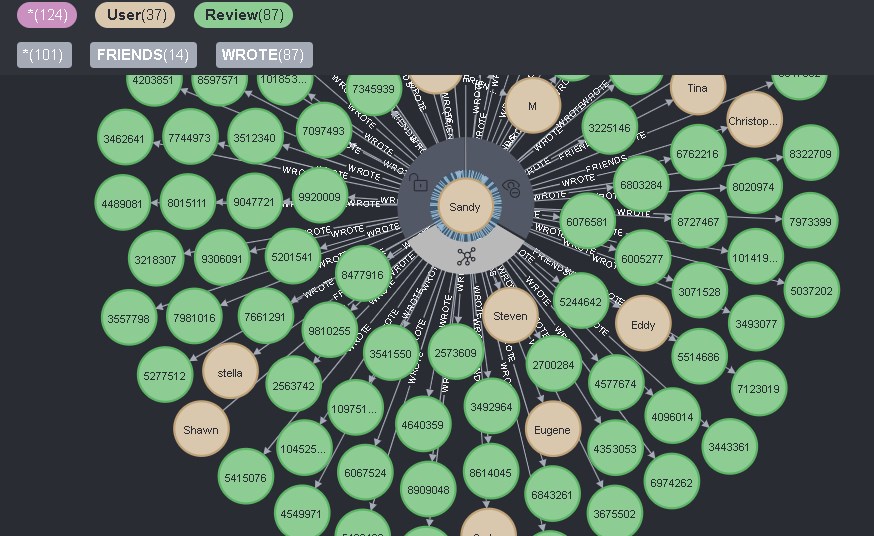
Ceci est pratique et peu pratique en même temps. D'une part, vous pouvez voir toutes les informations sur l'utilisateur en un seul clic, mais en même temps, vous ne pouvez pas supprimer les informations inutiles avec ce clic.
Mais il n'y a rien à craindre, vous pouvez trouver cet utilisateur et seulement tous ses amis par identifiant:
MATCH p=(:User {user_id:"u-CFWELen3aWMSiLAa_9VANw"}) -[r:FRIENDS]->() RETURN p LIMIT 25

De la même manière, vous pouvez voir quels avis une personne donnée a écrit:

YELP stocke déjà des avis de 2010! Utilité douteuse, mais néanmoins.
Pour lire ces avis, vous devez passer à la vue texte en cliquant sur A -

Regardons l'endroit que Sandy a écrit il y a environ 10 ans et trouvons-le sur yelp.com -

Un tel endroit existe vraiment - www.yelp.com/ biz / cafe-sushi-cambridge ,
et voici Sandy elle-même avec sa propre critique - www.yelp.com/biz/cafe-sushi-cambridge?q=I%20was%20really%20excited
photo

Requêtes Python dans la base de données Neo4j à partir du notebook Jupyter
Il utilisera partiellement les informations du livre gratuit mentionné "Graph Algorithms" 2019 d'O'REILLY. En partie parce que la syntaxe du livre est obsolète dans de nombreux endroits.
La base avec laquelle nous allons travailler doit être lancée, alors qu'il n'est pas nécessaire de lancer le navigateur neo4j lui-même.
Importation de bibliothèques:
from neo4j import GraphDatabase
import pandas as pd
from tabulate import tabulate
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
Connexion à la base de données:
driver = GraphDatabase.driver("bolt://localhost", auth=("neo4j", "123"))
Comptons le nombre de sommets pour chaque étiquette dans la base de données:
result = {"label": [], "count": []}
with driver.session() as session:
labels = [row["label"] for row in session.run("CALL db.labels()")]
for label in labels:
query = f"MATCH (:`{label}`) RETURN count(*) as count"
count = session.run(query).single()["count"]
result["label"].append(label)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Sortie:
+ ---------- + --------- +
| label | compte |
| ---------- + --------- |
| Pays | 3 |
| Zone | 15 |
| Ville | 355 |
| Catégorie | 1330 |
| Entreprise | 160585 |
| Utilisateur | 2189457 |
| Revue | 8635403 |
+ ---------- + --------- +
Cela semble être vrai, dans notre base de données il y a 3 pays, comme nous l'avons vu plus tôt avec le navigateur neo4j.
Et ce code comptera le nombre de liens (arêtes):
result = {"relType": [], "count": []}
with driver.session() as session:
rel_types = [row["relationshipType"] for row in session.run
("CALL db.relationshipTypes()")]
for rel_type in rel_types:
query = f"MATCH ()-[:`{rel_type}`]->() RETURN count(*) as count"
count = session.run(query).single()["count"]
result["relType"].append(rel_type)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Sortie:
+ ------------- + --------- +
| relType | compte |
| ------------- + --------- |
| IN_COUNTRY | 15 |
| IN_AREA | 355 |
| IN_CITY | 160585 |
| IN_CATEGORY | 708884 |
| AVIS | 8635403 |
| WROTE | 8635403 |
| AMIS | 8985774 |
+ ------------- + --------- +
Je pense que le principe est clair. Enfin, écrivons une requête et rendons-la.
Top 10 des hôtels de Vancouver avec le plus d'avis
# Find the 10 hotels with the most reviews
query = """
MATCH (review:Review)-[:REVIEWS]->(business:Business),
(business)-[:IN_CATEGORY]->(category:Category {category_id: $category}),
(business)-[:IN_CITY]->(:City {name: $city})
RETURN business.name AS business, collect(review.stars) AS allReviews
ORDER BY size(allReviews) DESC
LIMIT 10
"""
#MATCH (review:Review)-[:REVIEWS]->(business:Business),
#(business)-[:IN_CATEGORY]->(category:Category {category_id: "Hotels"}),
#(business)-[:IN_CITY]->(:City {name: "Vancouver"})
#RETURN business.name AS business, collect(review.stars) AS allReviews
#ORDER BY size(allReviews) DESC
#LIMIT 10
fig = plt.figure()
fig.set_size_inches(10.5, 14.5)
fig.subplots_adjust(hspace=0.4, wspace=0.4)
with driver.session() as session:
params = { "city": "Vancouver", "category": "Hotels"}
result = session.run(query, params)
for index, row in enumerate(result):
business = row["business"]
stars = pd.Series(row["allReviews"])
#print(dir(stars))
total = stars.count()
#s = pd.concat([pd.Series(x['A']) for x in data]).astype(float)
s = pd.concat([pd.Series(row['allReviews'])]).astype(float)
average_stars = s.mean().round(2)
# Calculate the star distribution
stars_histogram = stars.value_counts().sort_index()
stars_histogram /= float(stars_histogram.sum())
# Plot a bar chart showing the distribution of star ratings
ax = fig.add_subplot(5, 2, index+1)
stars_histogram.plot(kind="bar", legend=None, color="darkblue",
title=f"{business}\nAve:{average_stars}, Total: {total}")
#print(business)
#print(stars)
plt.tight_layout()
plt.show()
Le résultat doit ressembler à ceci: l'

axe X représente le nombre d'étoiles de l'hôtel et l'axe Y représente le pourcentage total de chaque note.
Comment le jeu de données YELP peut être utile
Parmi les avantages sont les suivants :
- un champ d'information assez riche en termes de contenu. En particulier, vous pouvez simplement collecter des avis avec 1,0 ou 5,0 étoiles et spammer toute entreprise. Hum. Un peu dans la mauvaise direction, mais le vecteur est clair;
- l'ensemble de données est volumineux, ce qui crée des difficultés supplémentaires agréables en termes de test des performances de diverses plates-formes d'exploration de données;
- les données présentées ont une certaine rétrospective et, en principe, il est possible de comprendre comment l'entreprise a évolué, sur la base des examens à son sujet;
- les données peuvent être utilisées comme références pour les entreprises, étant donné que les adresses sont disponibles;
- Les utilisateurs de l'ensemble de données forment souvent des structures interconnectées intéressantes qui peuvent être considérées telles quelles, sans former les utilisateurs en un social artificiel. réseau et ne pas collecter ce réseau à partir d'autres réseaux sociaux existants. réseaux.
Inconvénients :
- seuls trois pays sur 30 sont représentés et on soupçonne que ce n'est pas complètement,
- les avis sont conservés pendant 10 ans, ce qui peut fausser et souvent gâcher les caractéristiques d'une entreprise existante,
- il y a peu de données sur les utilisateurs, ils sont impersonnels, par conséquent, les systèmes de recommandation basés sur l'ensemble de données seront clairement boiteux,
- Les liens AMIS utilisent des graphiques dirigés, c'est-à-dire qu'Anya est amie -> Petya. Il s'avère que Petya n'est pas amie avec Anya. Cela peut être résolu par programme, mais c'est toujours gênant.
- l'ensemble de données est présenté «brut» et nécessite un effort considérable pour le prétraiter.
Neo4j
Neo4j est mis à jour dynamiquement et la nouvelle version de l'interface utilisée dans Neo4j Desktop 1.4.5 n'est pas très pratique, à mon avis. En particulier, il y a un manque de clarté en termes d'informations sur le nombre de nœuds et de liens dans la base de données, qui était dans les versions précédentes. De plus, l'interface de navigation dans les onglets lorsque vous travaillez avec la base de données a été modifiée et vous devez également vous y habituer.
Le principal inconvénient des mises à jour est l'intégration d'algorithmes de graphes dans le plugin Graph Data Science Library. Ils étaient auparavant appelés neo4j-graph-algorithms .
Après l'intégration, de nombreux algorithmes ont considérablement modifié leur syntaxe. Pour cette raison, étudier le livre 2019 Graph Algorithms par O'REILLY peut être difficile.
Dump de base de données Yelp pour Neo4j - Télécharger...