 Bonjour, Habitants! Comment tout extraire de vos données? Comment prendre des décisions basées sur les données? Comment organiser la data science au sein de l'entreprise? Qui embaucher un analyste? Comment amener les projets d'apprentissage automatique et d'intelligence artificielle au plus haut niveau? Roman Zykov connaît la réponse à ces questions et à bien d'autres, car il analyse des données depuis près de vingt ans. L'historique de Roman comprend la création de sa propre entreprise à partir de zéro avec des bureaux en Europe et en Amérique du Sud, qui est devenue le leader de l'utilisation de l'intelligence artificielle (IA) sur le marché russe. De plus, l'auteur du livre a créé des analyses sur Ozon.ru à partir de zéro. Ce livre est destiné au lecteur réfléchi qui souhaite s'essayer à l'analyse de données et créer des services basés sur celle-ci. Cela vous sera utile si vous êtes manager,qui veut se fixer des objectifs et gérer les analyses. Si vous êtes un investisseur, cela vous permettra de mieux comprendre le potentiel d'une startup. Ceux qui ont «vu» leur startup trouveront ici des recommandations sur la manière de choisir la bonne technologie et de recruter une équipe. Et le livre aidera les spécialistes en herbe à élargir leurs horizons et à commencer à appliquer des pratiques auxquelles ils n'avaient pas pensé auparavant, ce qui les distinguera des professionnels dans un domaine aussi difficile et volatile.
Bonjour, Habitants! Comment tout extraire de vos données? Comment prendre des décisions basées sur les données? Comment organiser la data science au sein de l'entreprise? Qui embaucher un analyste? Comment amener les projets d'apprentissage automatique et d'intelligence artificielle au plus haut niveau? Roman Zykov connaît la réponse à ces questions et à bien d'autres, car il analyse des données depuis près de vingt ans. L'historique de Roman comprend la création de sa propre entreprise à partir de zéro avec des bureaux en Europe et en Amérique du Sud, qui est devenue le leader de l'utilisation de l'intelligence artificielle (IA) sur le marché russe. De plus, l'auteur du livre a créé des analyses sur Ozon.ru à partir de zéro. Ce livre est destiné au lecteur réfléchi qui souhaite s'essayer à l'analyse de données et créer des services basés sur celle-ci. Cela vous sera utile si vous êtes manager,qui veut se fixer des objectifs et gérer les analyses. Si vous êtes un investisseur, cela vous permettra de mieux comprendre le potentiel d'une startup. Ceux qui ont «vu» leur startup trouveront ici des recommandations sur la manière de choisir la bonne technologie et de recruter une équipe. Et le livre aidera les spécialistes en herbe à élargir leurs horizons et à commencer à appliquer des pratiques auxquelles ils n'avaient pas pensé auparavant, ce qui les distinguera des professionnels dans un domaine aussi difficile et volatile.
Dois-je pouvoir programmer?
Oui besoin. Au 21e siècle, il est souhaitable que chaque personne comprenne comment utiliser la programmation dans son travail. Auparavant, la programmation n'était accessible qu'à un cercle restreint d'ingénieurs. Au fil du temps, la programmation appliquée est devenue plus accessible, démocratique et pratique.
J'ai appris à programmer par moi-même lorsque j'étais enfant. Mon père a acheté un ordinateur «Partner 01.01» à la fin des années 1980, alors que j'avais environ onze ans, et j'ai commencé à me plonger dans la programmation. J'ai d'abord maîtrisé le langage BASIC, puis je suis arrivé à l'assembleur. J'ai tout étudié à partir des livres - alors il n'y avait personne à qui demander. Le travail de base qui a été fait dans l'enfance m'a été très utile dans la vie. À cette époque, mon instrument principal était un curseur blanc clignotant sur un écran noir, les programmes devaient être enregistrés sur un magnétophone - tout cela ne peut être comparé aux possibilités que nous avons actuellement. Les bases de la programmation ne sont pas si difficiles à apprendre. Quand ma fille avait cinq ans et demi, je l'ai mise dans un simple cours de programmation Scratch. Avec mes petits conseils, elle a suivi ce cours et a même obtenu sa certification MIT d'entrée de gamme.
La programmation d'application est ce qui vous permet d'automatiser une partie des fonctions d'un employé. Les premiers candidats à l'automatisation sont les actions répétitives.
Il existe deux méthodes d'analyse. La première consiste à utiliser des outils prêts à l'emploi (Excel, Tableau, SAS, SPSS, etc.), où toutes les actions sont effectuées à la souris, et la programmation maximale est d'écrire une formule. La seconde consiste à écrire en Python, R ou SQL. Ce sont deux approches fondamentalement différentes, mais une bonne personne doit maîtriser les deux. Lorsque vous travaillez sur n'importe quelle tâche, vous devez trouver un équilibre entre vitesse et qualité. Cela est particulièrement vrai pour la recherche d'informations. J'ai rencontré à la fois des adeptes ardents de la programmation et des tenaces qui ne pouvaient utiliser qu'une souris et au plus un programme. Un bon spécialiste sélectionnera son propre outil pour chaque tâche. Dans certains cas, il écrira un programme, dans un autre il fera tout dans Excel. Et dans le troisième, il combinera les deux approches: il téléchargera des données vers SQL, traitera l'ensemble de données en Python et l'analysera dans un tableau croisé dynamique Excel ou Google Docs.La vitesse de travail d'un spécialiste aussi avancé peut être d'un ordre de grandeur plus élevée que celle d'un one-liner. La connaissance donne la liberté.
Alors que j'étais encore étudiant, je parlais couramment plusieurs langages de programmation et j'ai même réussi à travailler pendant un an et demi en tant que développeur de logiciels. Les temps étaient difficiles à l'époque - je suis entré à l'Institut de physique et de technologie de Moscou en juin 1998, et en août, il y a eu un défaut. Il était impossible de vivre avec une bourse, je ne voulais pas prendre de l'argent à mes parents. Dans ma deuxième année, j'ai eu de la chance, j'ai été embauché comme développeur dans l'une des sociétés du MIPT - là j'ai approfondi mes connaissances d'assembleur et de C. Après un certain temps, j'ai trouvé un emploi dans le support technique de StatSoft Russie - ici j'ai amélioré mon analyse statistique. Chez Ozon.ru, il a suivi une formation et a reçu un certificat SAS, et a également beaucoup écrit en SQL. L'expérience de la programmation m'a beaucoup aidé - je n'avais pas peur de quelque chose de nouveau, je l'ai juste pris et je l'ai fait. Si je n'avais pas une telle expérience en programmation, il n'y aurait pas beaucoup de choses intéressantes dans ma vie, y compris la société Retail Rocket,que nous avons fondé avec mes partenaires.
Base de données
Un ensemble de données est un ensemble de données, le plus souvent sous la forme d'une table, qui a été déchargé du stockage (par exemple, via SQL) ou obtenu d'une autre manière. Une table est composée de colonnes et de lignes, communément appelées enregistrements. Dans l'apprentissage automatique, les colonnes elles-mêmes sont des variables indépendantes, ou prédicteurs, ou plus communément des caractéristiques et des variables dépendantes, des résultats. Vous trouverez cette division dans la littérature. La tâche de l'apprentissage automatique est de former un modèle qui, à l'aide des variables indépendantes (caractéristiques), sera capable de prédire correctement la valeur de la variable dépendante (en règle générale, il n'y en a qu'une dans l'ensemble de données).
Les deux principaux types de variables sont catégoriques et quantitatives. Une variable catégorielle contient le texte ou le codage numérique des «catégories». À son tour, cela peut être:
- Binaire - ne peut prendre que deux valeurs (exemples: oui / non, 0/1).
- Nominal - peut prendre plus de deux valeurs (exemple: oui / non / ne sais pas).
- Ordinal - lorsque l'ordre compte (par exemple, le rang de l'athlète, le numéro de ligne dans les résultats de la recherche).
Une variable quantitative peut être:
- Discret (discret) - la valeur est calculée par le compte, par exemple, le nombre de personnes dans la salle.
- Continu - toute valeur de l'intervalle, par exemple, poids de la boîte, prix du produit.
Regardons un exemple. Il y a un tableau avec les prix des appartements (variable dépendante), une ligne (enregistrement) pour un appartement, chaque appartement a un ensemble d'attributs (indépendants) avec les colonnes suivantes:
- Le prix de l'appartement est continu et dépendant.
- La superficie de l'appartement est continue.
- Le nombre de chambres est discret (1, 2, 3, ...).
- La salle de bain est combinée (oui / non) - binaire.
- Numéro d'étage - ordinal ou nominal (selon la tâche).
- La distance au centre est continue.
Statistiques descriptives
La toute première étape après le déchargement des données de l'entrepôt consiste à effectuer une analyse exploratoire des données, qui comprend des statistiques descriptives et une visualisation des données, en supprimant éventuellement les données en supprimant les valeurs aberrantes.
Les statistiques descriptives incluent généralement des statistiques différentes pour chacune des variables de l'ensemble de données d'entrée:
- Le nombre de valeurs non manquantes.
- Le nombre de valeurs uniques.
- Minimum Maximum.
- Moyenne.
- Médian.
- Écart-type.
- Centiles - 25%, 50% (médiane), 75%, 95%.
Tous les types de variables ne peuvent pas être calculés - par exemple, la moyenne ne peut être calculée que pour des variables quantitatives. Les progiciels statistiques et les bibliothèques d'analyses statistiques ont déjà des fonctions prêtes à l'emploi qui comptabilisent les statistiques descriptives. Par exemple, la bibliothèque pandas Python a une fonction describe qui affichera immédiatement plusieurs statistiques pour une ou toutes les variables de l'ensemble de données:
s = pd.Series([4-1, 2, 3])
s.describe()
count 3.0
mean 2.0
std 1.0
min 1.0
25% 1.5
50% 2.0
75% 2.5
max 3.0
Bien que ce livre ne soit pas destiné à être un manuel sur les statistiques, je vais vous donner quelques conseils utiles. Souvent, en théorie, on suppose que nous travaillons avec des données normalement distribuées, dont l'histogramme ressemble à une cloche (Figure 4.1).
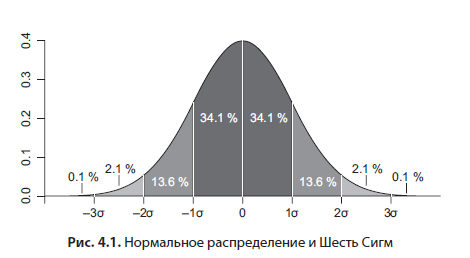
Je recommande vivement de vérifier cette hypothèse au moins à l'œil nu. La médiane est la valeur qui divise par deux l'échantillon. Par exemple, si les 25e et 75e centiles sont à des distances différentes de la médiane, cela indique déjà une distribution décalée. Un autre facteur est la forte différence entre la moyenne et la médiane; dans une distribution normale, ils coïncident pratiquement. Vous aurez souvent affaire à une distribution exponentielle lors de l'analyse du comportement des clients - par exemple, dans Ozon.ru, le temps entre les commandes successives des clients aura une distribution exponentielle. La moyenne et la médiane diffèrent considérablement. Par conséquent, le nombre correct est la médiane, la valeur qui divise par deux l'échantillon. Dans l'exemple avec Ozon.ru, c'est le temps pendant lequel 50% des utilisateurs passent la commande suivante après la première. La médiane est également plus robuste aux valeurs aberrantes dans les données.Si vous souhaitez travailler avec des moyennes, par exemple, en raison des limites du logiciel statistique, et que techniquement la moyenne est calculée plus rapidement que la médiane, dans le cas d'une distribution exponentielle, vous pouvez la traiter avec le logarithme naturel. Pour revenir à l'échelle de données d'origine, vous devez traiter la moyenne résultante avec l'exposant habituel.
Le centile est une valeur qu'une variable aléatoire donnée ne dépasse pas avec une probabilité fixe. Par exemple, la phrase "le 25e centile du prix des marchandises est égal à 150 roubles" signifie que 25% des biens ont un prix inférieur ou égal à 150 roubles, les 75% restants des biens sont plus chers que 150 roubles.
Pour une distribution normale, si la moyenne et l'écart-type sont connus, il existe des modèles théoriques utiles - 95% de toutes les valeurs tombent dans l'intervalle à une distance de deux écarts-types de la moyenne dans les deux directions, c'est-à-dire le la largeur de l'intervalle est de quatre sigma. Vous avez peut-être entendu un terme tel que Six Sigma (Figure 4.1) - ce chiffre caractérise la production sans rebut. Ainsi, cette loi empirique découle de la distribution normale: dans l'intervalle de six écarts-types autour de la moyenne (trois dans chaque direction), 99,99966% des valeurs correspondent - qualité idéale. Les centiles sont très utiles pour rechercher et supprimer les valeurs aberrantes des données. Par exemple, lors de l'analyse de données expérimentales, vous pouvez supposer que toutes les données en dehors du 99e centile sont des valeurs aberrantes et les supprimer.
Graphiques
Un bon graphique vaut mille mots. Les principaux types de graphiques que j'utilise:
- histogrammes;
- diagramme de dispersion;
- graphique de série chronologique avec une ligne de tendance;
- box plot, box et whiskers plot.
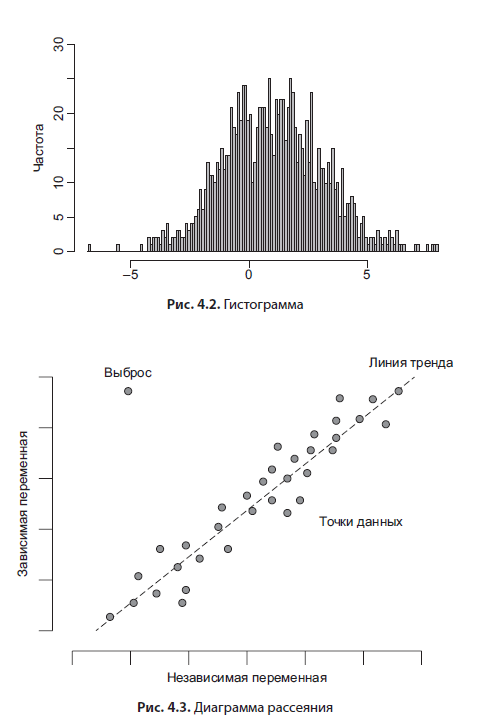
L'histogramme (Figure 4.2) est l'outil d'analyse le plus utile. Il vous permet de visualiser la distribution de fréquence de l'occurrence d'une valeur (pour une variable catégorielle) ou de diviser une variable continue en plages (bins). Le second est utilisé plus souvent, et si vous fournissez en plus des statistiques descriptives à un tel graphique, vous aurez alors une image complète décrivant la variable qui vous intéresse. L'histogramme est un outil simple et intuitif.
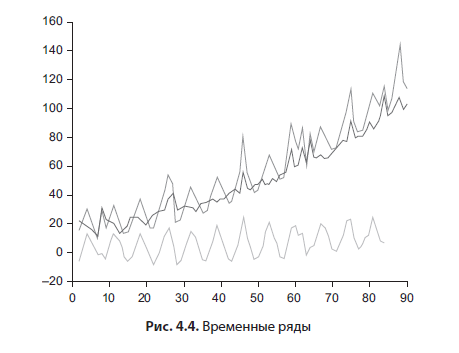
Un nuage de points (Figure 4.3) vous permet de voir comment deux variables dépendent l'une de l'autre. Il est construit simplement: sur l'axe horizontal - l'échelle de la variable indépendante, sur l'axe vertical - l'échelle de la personne à charge. Les valeurs (enregistrements) sont marquées par des points. Une ligne de tendance peut également être ajoutée. Dans les packages de statistiques avancées, vous pouvez signaler de manière interactive les valeurs aberrantes.
Les graphiques de séries chronologiques (figure 4.4) sont sensiblement les mêmes qu'un nuage de points, dans lequel la variable indépendante (sur l'axe horizontal) est le temps. Habituellement, deux composantes peuvent être distinguées d'une série chronologique - cyclique et tendance. Une tendance peut être construite en connaissant la durée du cycle, par exemple, un cycle de sept jours est un cycle de vente standard dans les épiceries, vous pouvez voir une image répétée sur le graphique tous les 7 jours. Ensuite, une moyenne mobile avec une longueur de fenêtre égale au cycle est superposée sur le graphique - et vous obtenez une ligne de tendance. Presque tous les progiciels statistiques, Excel, Google Sheets peuvent le faire. Si vous avez besoin d'obtenir la composante cyclique, cela se fait en soustrayant la ligne de tendance de la série chronologique. Sur la base de ces calculs simples, les algorithmes les plus simples pour la prévision des séries chronologiques sont construits.
La boîte à moustaches (Fig. 4.5) est très intéressante; dans une certaine mesure, il duplique les histogrammes, car il montre également une estimation de la distribution.
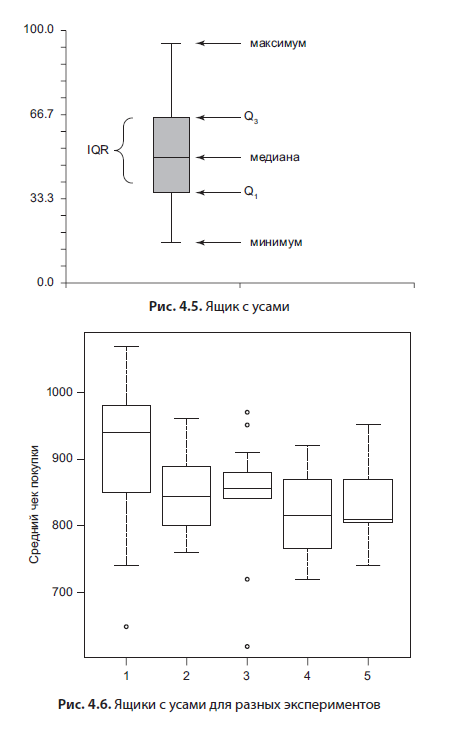
Il se compose de plusieurs éléments: une moustache, qui désigne le minimum et le maximum, une case dont le bord supérieur est le 75e percentile, le bord inférieur est le 25e percentile. Dans la boîte, la ligne est la médiane, la valeur "au milieu", qui divise l'échantillon en deux. Ce type de graphique est utile pour comparer les résultats expérimentaux ou les variables entre eux. Un exemple d'un tel graphique est présenté ci-dessous (Fig. 4.6). Je pense que c'est la meilleure façon de visualiser les résultats des tests d'hypothèses.
Approche générale de la visualisation des données
La visualisation des données est nécessaire pour deux choses: pour explorer les données et pour expliquer les résultats au client. Souvent, plusieurs méthodes sont utilisées pour présenter les résultats: un simple commentaire avec quelques chiffres, Excel ou un autre format de feuille de calcul, une présentation avec des diapositives. Ces trois méthodes combinent conclusion et preuve, c'est-à-dire une explication de la manière dont cette conclusion a été atteinte. Il est pratique d'exprimer la preuve sous forme de graphiques. Dans 90% des cas, les cartes des types décrits ci-dessus sont suffisantes pour cela.
Les graphiques exploratoires et les graphiques de présentation sont différents les uns des autres. Le but de la recherche est de trouver un modèle ou une cause, en règle générale, il y en a beaucoup, et il arrive qu'ils soient construits au hasard. Le but des graphiques de présentation est de guider le décideur (décideur) vers les conclusions du problème. Tout est important ici - à la fois le titre de la diapositive et leur séquence simple qui mène à la conclusion souhaitée. Un critère important pour le système de preuve d'inférence est la rapidité avec laquelle le client comprendra et sera d'accord avec vous. Il n'est pas nécessaire que ce soit une présentation. Personnellement, je préfère un texte simple - quelques phrases avec des conclusions, quelques graphiques et quelques chiffres prouvant ces conclusions, rien de plus.
Gene Zelazny, directeur des communications visuelles chez McKinsey & Company, déclare dans son livre Speak the Language of Diagrams:
«Le type de graphique n'est pas déterminé par les données (dollars ou intérêts) ou par certains paramètres (profit, rentabilité ou salaire). et votre idée est ce que vous voulez mettre dans le diagramme. "
Je vous recommande de prêter attention aux graphiques dans les présentations et les articles - prouvent-ils les conclusions de l'auteur? Aimez-vous tout à leur sujet? Pourraient-ils être plus convaincants?
Et voici ce que Jean Zelazny écrit sur les diapositives dans les présentations:
"L'utilisation généralisée de la technologie informatique a conduit au fait que maintenant, en quelques minutes, vous pouvez faire ce qui était auparavant des heures de travail minutieux - et les diapositives sont cuites comme des tartes ... insipides et insipides."
J'ai fait beaucoup de rapports: avec et sans diapositives, courts, pendant 5 à 10 minutes et longs - pendant une heure. Je peux vous assurer qu'il m'est beaucoup plus difficile de faire un texte convaincant pour une courte présentation sans diapositives qu'une présentation PowerPoint. Regardez les politiciens qui parlent: leur tâche est de convaincre, combien d'entre eux montrent des diapositives dans leurs discours? Le mot est plus convaincant, les diapositives ne sont que du matériel visuel. Et il faut plus de travail pour rendre votre mot clair et convaincant que de lancer des diapositives. Je me suis retrouvé à réfléchir à l'aspect de la présentation lors de la composition des diapositives. Et lors de la rédaction d'un rapport oral - à quel point mes arguments sont-ils convaincants, comment travailler avec l'intonation, à quel point ma pensée est claire. Veuillez considéreravez-vous vraiment besoin d'une présentation? Voulez-vous transformer une réunion en diapositives ennuyeuses au lieu de prendre des décisions?
«Les réunions doivent se concentrer sur de courts rapports écrits sur papier, plutôt que sur des résumés ou des bribes de listes projetées sur le mur», déclare Edward Tufty, un porte-parole éminent de l’école de visualisation de données, dans PowerPoint Cognitive Style.
Analyse de données appariées
J'ai appris la programmation en binôme auprès des développeurs [30] Retail Rocket. Il s'agit d'une technique de programmation dans laquelle le code source est créé par des paires de personnes programmant la même tâche et assises sur le même poste de travail. Un programmeur est assis au clavier, l'autre travaille avec sa tête, se concentre sur la vue d'ensemble et regarde continuellement le code produit par le premier programmeur. Ils peuvent changer d'endroit de temps en temps.
Et nous avons réussi à l'adapter aux besoins de l'analytique! L'analyse, comme la programmation, est un processus créatif. Imaginez que vous ayez besoin de construire un mur. Vous avez un travailleur. Si vous en ajoutez un de plus, la vitesse doublera environ. Dans le processus de création, cela ne fonctionnera pas. La vitesse de création de projet ne doublera pas. Oui, vous pouvez décomposer un projet, mais je discute maintenant d'une tâche qui ne peut pas être décomposée, et elle devrait être effectuée par une seule personne. L'approche par paires vous permet d'accélérer ce processus plusieurs fois. Une personne est au clavier, la seconde est assise à côté de lui. Deux chefs travaillent sur le même problème. Quand je résous des problèmes difficiles, je me parle. Lorsque deux têtes se parlent, elles cherchent une meilleure raison. Nous utilisons le schéma de travail par paires pour les tâches suivantes.
- Lorsqu'il est nécessaire de transférer la connaissance d'un projet d'un employé à un autre, par exemple, un nouvel arrivant a été embauché. Le «chef» sera un employé qui transfère des connaissances, des «mains» au clavier - à qui elles sont transférées.
- Lorsque le problème est complexe et incompréhensible. Ensuite, deux employés expérimentés dans une paire le résoudront beaucoup plus efficacement qu'un seul. Il sera plus difficile de rendre la tâche d'analyse unilatérale.
Habituellement, lors de la planification, nous transférons une tâche dans la catégorie des paires, s'il est clair qu'elle répond aux critères de celle-ci.
Les avantages de l'approche par paires sont que le temps est utilisé beaucoup plus efficacement, les deux personnes sont très concentrées, elles se disciplinent mutuellement. Les tâches complexes sont résolues de manière plus créative et d'un ordre de grandeur plus rapide. Moins - il est impossible de travailler dans ce mode pendant plus de quelques heures, vous êtes très fatigué.
Dette technique
Une autre chose importante que j'ai apprise des ingénieurs de Retail Rocket concerne la dette technique. La dette technique consiste à travailler avec d'anciens projets, à optimiser la vitesse de travail, à passer à de nouvelles versions de bibliothèques, à supprimer l'ancien code des tests d'hypothèses, à simplifier l'ingénierie des projets. Toutes ces tâches prennent un bon tiers du temps de développement analytique. Je citerai le directeur technique de Retail Rocket Andrey Chizh:
«Je n'ai encore rencontré aucune entreprise dans mon cabinet (et c'est plus de 10 entreprises dans lesquelles j'ai moi-même travaillé, et à peu près le même nombre que je connais bien de l'intérieur) , sauf pour la nôtre, qui avait des tâches pour supprimer la fonctionnalité, bien que, probablement, de telles existent. "
Je n'ai pas rencontré non plus. J'ai vu les «marais» des projets logiciels, où les vieux trucs interfèrent avec la création de quelque chose de nouveau. Le nœud de la dette technologique est que tout ce que vous avez fait auparavant doit être entretenu. C'est comme avec un entretien de voiture - cela doit être fait régulièrement, sinon la voiture tombera en panne au moment le plus inattendu. Un code qui n'a pas été modifié ou mis à jour depuis longtemps est un mauvais code. Habituellement, cela fonctionne déjà sur le principe de "fonctionne - ne touchez pas". Il y a quatre ans, j'ai parlé avec un développeur chez Bing. Il a dit que dans l'architecture de ce moteur de recherche, il y a une bibliothèque compilée dont le code est perdu. Et personne ne sait comment le restaurer. Plus cela prend du temps, plus les conséquences seront pires.
Comment les analystes de Retail Rocket servent la dette technologique:
- , . .
- - — , . , Spark , 1.0.0.
- - — .
- - — , , .
Faire face à la dette technique est la voie de la qualité. J'en ai été convaincu en travaillant sur le projet Retail Rocket. Du point de vue de l'ingénierie, le projet est réalisé comme dans les «meilleures maisons de Californie».
Plus de détails sur le livre peuvent être trouvés sur le site de la maison d'édition
» Table des matières
» Extrait
Pour Habitants un rabais de 25% sur le coupon - Data Science
Lors du paiement de la version papier du livre, un e-book est envoyé à la e-mail.