
Une fonctionnalité intéressante a été récemment ajoutée à la ligne principale du compilateur Clang . En utilisant les attributs
[[clang::musttail]]
ou ,
__attribute__((musttail))
vous pouvez désormais obtenir des appels de queue garantis en C, C ++ et Objective-C.
int g(int);
int f(int x) {
__attribute__((musttail)) return g(x);
}
( Compilateur en ligne )
Habituellement, ces appels sont associés à la programmation fonctionnelle, mais je ne m'intéresse à eux que du point de vue des performances. Dans certains cas, avec leur aide, vous pouvez obtenir un meilleur code du compilateur - au moins avec les technologies de compilation disponibles - sans recourir à un assembleur.
L'utilisation de cette approche pour analyser le protocole de sérialisation a donné des résultats étonnants: nous avons pu analyser à des vitesses supérieures à 2 Gb / s. , plus de deux fois plus vite que la meilleure solution précédente. Cette accélération sera utile dans de nombreuses situations, il serait donc incorrect de se limiter à l'instruction "tail calls == double speedup". Cependant, ces défis sont un élément clé qui a rendu possible de tels gains de vitesse.
Je vais vous dire quels sont les avantages des appels de queue, comment nous analysons le protocole en les utilisant et comment nous pouvons étendre cette technique aux interprètes. Je pense que grâce à lui, les interprètes de tous les principaux langages écrits en C (Python, Ruby, PHP, Lua, etc.) peuvent obtenir des gains de performances significatifs. Le principal inconvénient est lié à la portabilité: il
musttail
s'agit aujourd'hui d' une extension de compilateur non standard. Bien que j'espère que cela se propagera, il faudra un certain temps avant que l'extension ne se propage suffisamment pour que le compilateur C de votre système puisse la prendre en charge. Lors de la construction, vous pouvez sacrifier l'efficacité en échange de la portabilité si elle s'avère
musttail
indisponible.
Principes de base de l'appel de queue
Un appel de queue est un appel à n'importe quelle fonction en position de queue, la dernière action avant que la fonction ne renvoie un résultat. Lors de l'optimisation des appels de queue, le compilateur compile l'instruction pour l'appel de queue
jmp
, pas
call
. Cela n'effectue pas d'actions de surcharge qui permettraient normalement
g()
à l'appelé de revenir à l'appelant
f()
, telles que la création d'un nouveau cadre de pile ou la transmission d'une adresse de retour. Au lieu de cela, il s'y
f()
réfère directement
g()
comme s'il faisait partie de lui-même et
g()
renvoie le résultat directement à l'appelant
f()
. Cette optimisation est sûre car le cadre de pile
f()
n'est plus nécessaire après le début de l'appel final, car il est devenu impossible d'accéder à une variable locale
f()
.
Même si cela semble trivial, cette optimisation a deux fonctionnalités importantes qui ouvrent de nouvelles possibilités pour l'écriture d'algorithmes. Premièrement, en exécutant n appels de queue consécutifs, la pile mémoire est réduite de O (n) à O (1). Ceci est important car la pile est limitée et un débordement peut planter le programme. Donc, sans cette optimisation, certains algorithmes sont dangereux. Deuxièmement, il
jmp
élimine les frais généraux de
call
et par conséquent, l'appel de fonction devient aussi efficace que n'importe quelle autre branche. Ces deux caractéristiques permettent d'utiliser les appels de queue comme une alternative efficace aux structures de contrôle itératives conventionnelles telles que
for
et
while
.
Cette idée n'est pas du tout nouvelle et remonte à 1977, lorsque Guy Steele a écrit tout un article dans lequel il affirmait que les appels de procédure sont plus propres que les architectures
GOTO
, tandis que l'optimisation des appels de queue ne perd pas de vitesse. C'était l'un des "Lambda Works" écrits entre 1975 et 1980, qui a formulé de nombreuses idées derrière Lisp et Scheme.
L'optimisation des appels de queue n'a rien de nouveau, même pour Clang. Il pouvait les optimiser auparavant, comme GCC et de nombreux autres compilateurs. En fait, l'attribut
musttail
dans cet exemple ne change pas du tout la sortie du compilateur: Clang a déjà optimisé les appels de queue pour
-O2
.
Nouveau ici est une garantie . Alors que les compilateurs réussissent souvent à optimiser les appels de queue, c'est la «meilleure chose possible» et vous ne pouvez pas vous y fier. En particulier, l'optimisation ne fonctionnera sûrement pas dans les versions non optimisées: le compilateur en ligne . Dans cet exemple, l'appel de queue est compilé dans
call
, donc nous sommes de retour sur une pile de taille O (n). C'est pourquoi nous avons besoin
musttail
: Tant que nous n'avons pas la garantie du compilateur que nos appels de queue seront toujours optimisés dans tous les modes d'assemblage, il sera dangereux d'écrire des algorithmes avec de tels appels pour l'itération. Et s'en tenir à un code qui ne fonctionne qu'avec les optimisations activées est une contrainte assez difficile.
Le problème des boucles d'interprétation
Les compilateurs sont une technologie incroyable, mais ils ne sont pas parfaits. Mike Pall, l'auteur de LuaJIT, a décidé d'écrire l'interpréteur LuaJIT 2.x en langage d'assemblage, et non en C, et il a appelé cela le facteur principal qui a rendu l'interpréteur si rapide . Paul a expliqué plus tard plus en détail pourquoi les compilateurs C ont du mal à trouver les principales boucles d'interprétation . Deux points principaux:
- , .
- , .
Ces observations reflètent bien notre expérience dans l'optimisation de l'analyse du protocole de sérialisation. Et les appels de queue nous aideront à résoudre les deux problèmes.
Vous pourriez trouver étrange de comparer les boucles d'interpréteur aux analyseurs de protocole de sérialisation. Cependant, leur similitude inattendue est déterminée par la nature du format filaire du protocole: il s'agit d'un ensemble de paires clé-valeur dans lequel la clé contient le numéro de champ et son type. La clé fonctionne comme un opcode dans l'interpréteur: elle nous indique quelle opération doit être effectuée pour analyser ce champ. Les numéros de champ dans le protocole peuvent aller dans n'importe quel ordre, vous devez donc être prêt à accéder à n'importe quelle partie du code à tout moment.
Il serait logique d'écrire un tel analyseur en utilisant une boucle
while
avec une expression imbriquée
switch
... Cela a été la meilleure approche pour analyser un protocole de sérialisation au cours de la durée de vie du protocole. Par exemple, voici le code d'analyse de la version C ++ actuelle . Si nous représentons graphiquement le flux de contrôle, nous obtenons le schéma suivant:
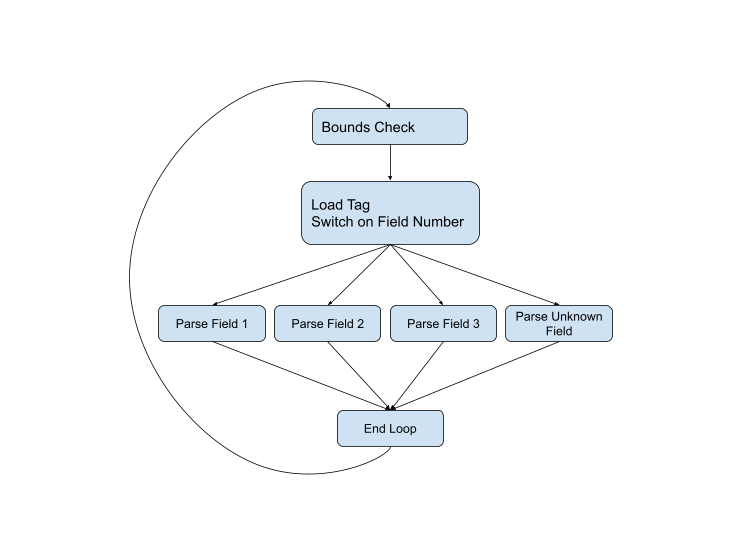
Mais le diagramme n'est pas complet, car des problèmes peuvent survenir à presque toutes les étapes. Le type de champ peut être incorrect, ou les données peuvent être corrompues, ou nous pourrions simplement sauter à la fin du tampon actuel. Le diagramme complet ressemble à ceci:
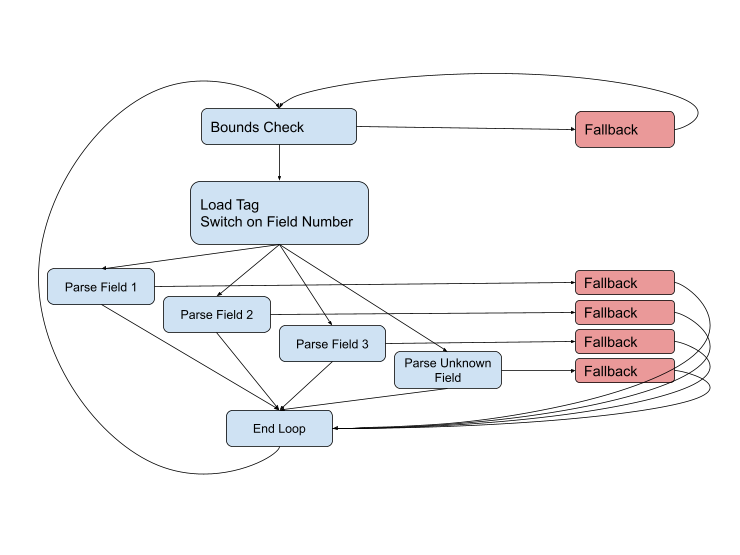
Nous devons rester sur les chemins rapides (bleus) le plus longtemps possible, mais face à une situation difficile, nous devrons la gérer en utilisant le code de secours. Ces chemins sont généralement plus longs et plus complexes que les chemins rapides, ils impliquent plus de données et utilisent souvent des appels maladroits à d'autres fonctions pour gérer des cas encore plus complexes.
En théorie, si vous combinez ce schéma avec le profil, le compilateur obtiendra toutes les informations dont il a besoin pour générer le code le plus optimal. Mais en pratique, avec cette taille de fonction et le nombre de connexions, nous devons souvent lutter avec le compilateur. Il jette une variable importante que nous voulons stocker dans le registre. Il applique la manipulation du cadre de pile que nous voulons envelopper autour de l'appel à la fonction de secours. Il concatène des chemins de code identiques que nous voulons garder séparés pour la prédiction de branche. Tout cela ressemble à essayer de jouer du piano avec des mitaines.
Amélioration des boucles d'interprétation avec les appels de queue
Le raisonnement décrit ci-dessus est en grande partie une reformulation des observations de Paul sur les principaux cycles de l'interprète . Mais au lieu de nous lancer dans l'assembleur, nous avons constaté qu'une architecture personnalisée peut nous donner le contrôle dont nous avons besoin pour obtenir un code presque optimal à partir de C. J'ai travaillé là-dessus avec mon collègue Gerben Stavenga, qui a conçu la majeure partie de l'architecture. Notre approche est similaire à l' interpréteur wasm3 WebAssembly , qui appelle ce modèle "metamachine" .
Nous mettons le code de notre analyseur 2 gigabits en upb, une petite bibliothèque protobuf en C. Elle fonctionne pleinement et passe tous les tests de conformité avec le protocole de sérialisation, mais n'a encore été déployée nulle part, et l'architecture n'a pas été implémentée dans la version C ++ du protocole. Mais lorsque l'extension est arrivée à Clang
musttail
(et upb a été mis à jour pour l'utiliser ), l'un des principaux obstacles à l'implémentation complète de notre analyseur rapide a été abandonné.
Nous nous sommes éloignés d'une grande fonction d'analyse et appliquons sa propre petite fonction pour chaque opération. Chaque fonction de queue appelle l'opération suivante de la séquence. Par exemple, voici une fonction d'analyse d'un seul champ de taille fixe (le code est simplifié par rapport à upb, j'ai supprimé de nombreux petits détails de l'architecture).
Le code
#include <stdint.h>
#include <stddef.h>
#include <string.h>
typedef void *upb_msg;
struct upb_decstate;
typedef struct upb_decstate upb_decstate;
// The standard set of arguments passed to each parsing function.
// Thanks to x86-64 calling conventions, these will be passed in registers.
#define UPB_PARSE_PARAMS \
upb_decstate *d, const char *ptr, upb_msg *msg, intptr_t table, \
uint64_t hasbits, uint64_t data
#define UPB_PARSE_ARGS d, ptr, msg, table, hasbits, data
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
const char *fallback(UPB_PARSE_PARAMS);
const char *dispatch(UPB_PARSE_PARAMS);
// Code to parse a 4-byte fixed field that uses a 1-byte tag (field 1-15).
const char *upb_pf32_1bt(UPB_PARSE_PARAMS) {
// Decode "data", which contains information about this field.
uint8_t hasbit_index = data >> 24;
size_t ofs = data >> 48;
if (UNLIKELY(data & 0xff)) {
// Wire type mismatch (the dispatch function xor's the expected wire type
// with the actual wire type, so data & 0xff == 0 indicates a match).
MUSTTAIL return fallback(UPB_PARSE_ARGS);
}
ptr += 1; // Advance past tag.
// Store data to message.
hasbits |= 1ull << hasbit_index;
memcpy((char*)msg + ofs, ptr, 4);
ptr += 4; // Advance past data.
// Call dispatch function, which will read the next tag and branch to the
// correct field parser function.
MUSTTAIL return dispatch(UPB_PARSE_ARGS);
}
Pour une fonction aussi petite et simple, Clang génère du code presque impossible à battre:
upb_pf32_1bt: # @upb_pf32_1bt
mov rax, r9
shr rax, 24
bts r8, rax
test r9b, r9b
jne .LBB0_1
mov r10, r9
shr r10, 48
mov eax, dword ptr [rsi + 1]
mov dword ptr [rdx + r10], eax
add rsi, 5
jmp dispatch # TAILCALL
.LBB0_1:
jmp fallback # TAILCALL
Notez qu'il n'y a pas de prologue ou d'épilogue, pas de préemption de registre, pas d'utilisation de pile du tout. Les seules sorties proviennent
jmp
de deux appels de queue, mais aucun code n'est nécessaire pour passer les paramètres, car les arguments sont déjà dans les registres corrects. La seule amélioration possible que nous voyons ici est peut-être un saut conditionnel pour un appel final
jne fallback
au lieu d'
jne
un appel ultérieur
jmp
.
Si vous voyiez un démontage de ce code sans informations symboliques, vous ne vous rendriez pas compte qu'il s'agissait de toute la fonction. Cela pourrait également être l'unité de base d'une fonction plus large. Et c'est exactement ce que nous faisons: nous prenons la boucle d'interprétation, qui est une fonction volumineuse et complexe, et la programmons bloc par bloc, en passant le flux de contrôle entre eux via des appels de queue. Nous avons un contrôle complet sur la distribution des registres à la limite de chaque bloc (au moins six registres), et comme la fonction est assez simple et ne préempte pas les registres, nous avons atteint notre objectif de stocker l'état le plus important tout au long du rapide chemins.
Nous pouvons optimiser indépendamment chaque séquence d'instructions. Et le compilateur gérera également toutes les séquences indépendamment, car elles sont situées dans des fonctions séparées (si nécessaire, vous pouvez empêcher l'inlining avec
noinline
). C'est ainsi que nous résolvons le problème décrit ci-dessus, dans lequel le code des chemins de secours dégrade la qualité du code des chemins rapides. En plaçant les chemins lents dans des fonctions complètement séparées, la stabilité de vitesse des chemins rapides peut être garantie. Le bel assembleur reste inchangé, il n'est affecté par aucun changement dans d'autres parties de l'analyseur.
Si nous appliquons ce modèle à l'exemple de Paul de LuaJIT , alors nous pouvons à peu près corréler son assembleur manuscrit avec de petites dégradations de la qualité du code :
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
return fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
L'assembleur résultant:
ADDVN: # @ADDVN
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
movzx eax, dl
movsd xmm0, qword ptr [r8 + 8*rax] # xmm0 = mem[0],zero
mov eax, edi
addsd xmm0, qword ptr [r9 + 8*rax]
movsd qword ptr [r9 + 8*rax], xmm0
mov edx, dword ptr [rcx]
add rcx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [rsi + 8*rax]
jmp rax # TAILCALL
.LBB0_1:
jmp fallback
La seule amélioration que je vois ici en plus de ce qui précède est
jne fallback
que, pour une raison quelconque, le compilateur ne veut pas générer
jmp qword ptr [rsi + 8*rax]
, au lieu de cela, il se charge
rax
et s'exécute
jmp rax
. Ce sont des problèmes de codage mineurs que j'espère que Clang corrigera bientôt sans trop de difficultés.
Limites
L'un des principaux inconvénients de cette approche est que toutes ces belles séquences de langage d'assemblage sont catastrophiquement pessimisées en l'absence d'appels de queue. Tout appel non personnalisé créera un cadre de pile et poussera beaucoup de données sur la pile.
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
// When we leave off "return", things get real bad.
fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
Soudain, nous obtenons ceci
ADDVN: # @ADDVN
push rbp
push r15
push r14
push r13
push r12
push rbx
push rax
mov r15, r9
mov r14, r8
mov rbx, rcx
mov r12, rsi
mov ebp, edi
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
.LBB0_2:
movzx eax, dl
movsd xmm0, qword ptr [r14 + 8*rax] # xmm0 = mem[0],zero
mov eax, ebp
addsd xmm0, qword ptr [r15 + 8*rax]
movsd qword ptr [r15 + 8*rax], xmm0
mov edx, dword ptr [rbx]
add rbx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [r12 + 8*rax]
mov rsi, r12
mov rcx, rbx
mov r8, r14
mov r9, r15
add rsp, 8
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
jmp rax # TAILCALL
.LBB0_1:
mov edi, ebp
mov rsi, r12
mov r13d, edx
mov rcx, rbx
mov r8, r14
mov r9, r15
call fallback
mov edx, r13d
jmp .LBB0_2
Pour éviter cela, nous avons essayé d'appeler d'autres fonctions uniquement via des appels inlining ou tail. Cela peut être fastidieux si l'opération comporte de nombreux endroits dans lesquels une situation inhabituelle qui n'est pas une erreur peut se produire. Par exemple, lorsque nous analysons le protocole de sérialisation, les variables entières ont souvent une longueur d'un octet, mais les plus longues ne sont pas une erreur. L'intégration de la gestion de telles situations peut dégrader la qualité du chemin rapide si le code de secours est trop complexe. Mais l'appel de fin de la fonction de secours ne facilite pas le retour à l'opération lors du traitement d'une anomalie, la fonction de secours doit donc pouvoir terminer l'opération. Cela conduit à une duplication et à une complication du code.
Idéalement, ce problème peut être résolu en ajoutant __attribute __ ((preserve_most))dans une fonction de secours suivie d'un appel normal, pas d'un appel de fin. L'attribut
preserve_most
rend l'appelé responsable de la préservation de presque tous les registres. Cela vous permet de déléguer la tâche de préemption des registres aux fonctions de secours, si nécessaire. Nous avons expérimenté cet attribut, mais nous sommes tombés sur des problèmes mystérieux que nous ne pouvions pas résoudre. Peut-être avons-nous fait une erreur quelque part, nous y reviendrons dans le futur.
La principale limitation est
musttail
qu'il n'est pas portable. J'espère vraiment que l'attribut prendra racine, il sera implémenté dans GCC, Visual C ++ et d'autres compilateurs, et un jour il sera même normalisé. Mais cela n'arrivera pas de sitôt, mais que devons-nous faire maintenant?
Quand l'expansion
musttail
n'est pas disponible, vous devez en exécuter au moins un correct
return
sans appel de fin pour chaque itération théorique de la boucle . Nous n'avons pas encore implémenté une telle solution de secours dans la bibliothèque upb, mais je pense qu'elle se transformera en une macro qui, selon la disponibilité,
musttail
effectuera des appels finaux ou retournera simplement.