
SberCraft, CyberCode, Luxcity - vous avez peut-être entendu parler de ces jeux ou même participé à eux. Tout cela est l'oeuvre de Geecko. Les plus grands projets Geecko rassemblent chacun 20 000 joueurs, alors que jusqu'à récemment, l'entreprise ne disposait pas d'une équipe dédiée pour soutenir l'infrastructure.
La station-service de la société Nikita Obukhov et la directrice marketing Irina Fedorova ont parlé de l'incident, qui est devenu l'un des arguments pour réfléchir sérieusement aux changements d'infrastructure, passer aux K8 et embaucher une équipe DevOps.
Qu'y a-t-il à l'intérieur:
- perte de contrôle sur Facebook,
- un brusque afflux de trafic vendredi soir,
- Subvention de Microsoft Azure, Cloud Moving and Transformation Challenges.
Va!
Geecko — DevRel . IT- , : , , -.
Geecko
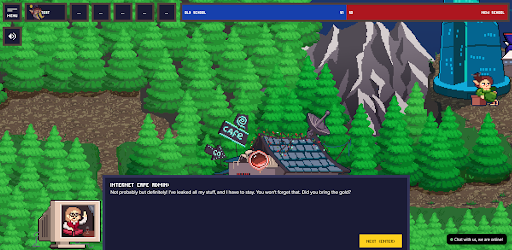
Sur quel moteur les jeux sont-ils créés, quels sont-ils techniquement?
Nikita: Nos jeux sont exclusivement basés sur un navigateur. Nous utilisons nos propres développements et bibliothèques éprouvées pour travailler avec Canvas, cartes, isométrie. Nous utilisons JS / TS, un framework Vue.js pour une interface utilisateur Web typique.
Nous n'écrivons pas encore pour les plates-formes mobiles - au mieux, nous prenons en charge les autorisations mobiles. Mais ce n'est pas souvent nécessaire - dans la plupart de nos jeux, vous devez écrire du code, et l'écriture de code à partir d'un téléphone mobile est une telle commodité.
À quel point les jeux sont-ils exigeants sur le processeur et la mémoire?
Nikita: Dans nos jeux, nous devons écrire du code, et nous devons exécuter ce code.
Nous prenons en charge 12 langues: compilées et interprétées dans différents environnements. Nous exécutons le code sur nos ressources serveur: la charge sur le processeur et la mémoire est intensive.
Nous exécutons également des services LSP qui fournissent un code de saisie semi-automatique pour notre IDE en ligne. Ils nécessitent également du CPU et surtout de la mémoire: quand il y a beaucoup de joueurs, la charge augmente considérablement.
Où sont hébergés les jeux?
Nikita: C'était toujours des nuages. Désormais, le fournisseur principal est Azure (Geecko a reçu une subvention de Microsoft pour une utilisation gratuite du cloud - ed.). Nous y lançons tous les nouveaux projets - et, ce qui est important pour nous, nous les lançons dans Kubernetes. Toute nouvelle infrastructure est basée sur Kubernetes et Docker.
Quel fournisseur aviez-vous auparavant et pourquoi avez-vous décidé de changer de fournisseur?
Nikita: Nous avons été et sommes toujours représentés dans DigitalOcean et Yandex.Cloud. Ce sont de bons fournisseurs, mais Microsoft s'est avéré être le programme de subventions le plus approprié pour nous.
Combien avez-vous dépensé auparavant sur les serveurs et dépensé maintenant?
Nikita: Il y a six mois, nous dépensions environ 30 mille roubles par mois, maintenant ce chiffre approche les 100 mille. La croissance est liée au nombre de projets: on n'arrête pas les anciens, ils continuent à travailler et reçoivent des inscriptions organiques. Nous lançons régulièrement de nouvelles activités: en un mois, nous pouvons sortir trois projets - par exemple, une bataille, un jeu et une rencontre.
Microsoft Grant couvre-t-il tous les coûts?
Nikita: Nos coûts d'infrastructure ne sont pas devenus nuls: nous ne pouvons pas tout transporter en même temps, ce n'est pas économiquement réalisable. Par conséquent, deux autres fournisseurs de cloud continuent de travailler avec nous, leur part diminue tout simplement.
Sauvegardes dans d'autres zones géographiques, reprise après sinistre des ressources dans un autre cloud - tout cela est important.
Dans l'ensemble, les coûts globaux sont réduits. Le service d'exécution de code a la plus grande consommation de ressources, et grâce à la subvention, ses coûts dans l'année à venir seront nuls. Si un certain nombre de conditions sont remplies, la subvention sera prolongée pour une deuxième année.

Capture d'écran du jeu Cybercode
Vendredi, le trafic Facebook
Avez-vous eu une situation où un afflux d'utilisateurs a fait chuter la production?
Nikita: Oui, une fois il y a eu un incident proche de ça. Nous avions une mission d'une entreprise internationale: trouver de nombreux développeurs anglophones.
De par sa conception, les joueurs doivent terminer collectivement la mission sur la même carte. La carte a des dimensions finies, il est donc impossible de placer tout le monde dessus. Nous avons divisé les utilisateurs en groupes de 100 personnes, dont chacune ne vit pas plus de cinq jours - c'est le cycle de jeu pour terminer la mission. Pendant ce temps, les participants gagnent ou perdent.
Nous nous attendions à ce que jusqu'à 10 de ces cartes soient actives en même temps, c'est-à-dire jusqu'à 1000 joueurs. Mais en fait, il y avait plus de 2000 joueurs ou 20 cartes au sommet.
Pourquoi est-ce arrivé? Pourquoi tant d'utilisateurs sont-ils soudainement venus au jeu?
Irina: L'histoire s'est produite début mars, lorsque Facebook a commencé à bloquer massivement et spontanément les comptes publicitaires pour incohérence avec la politique des annonceurs. De nombreuses entreprises ont alors perdu leurs bureaux de publicité, dont nous: notre siège social et les deux bureaux de sauvegarde ont chuté. Et tout cela au moment même où nous devions promouvoir le jeu.
Facebook est l'un des principaux canaux de promotion, car il est assez facile de sélectionner un public et de le segmenter en fonction des données disponibles. Et pendant 12 jours entiers, nous avons perdu l'accès à cette chaîne. Quand nous l'avons rendu avec sueur, sang et larmes, nous avons dû rattraper le KPI - 4500 enregistrements liquides pour certaines géolocalisations, principalement en Europe.
Il n'y avait pas d'autre choix que de pousser le budget: nous avons accéléré nos campagnes publicitaires.
Que signifie «pousser avec le budget»?
Irina: Si nous avons initialement dépensé 300 à 500 dollars par jour, alors ici nous sommes passés à plus de 1000.
Vous devez comprendre que généralement les campagnes publicitaires sont entraînées pendant plusieurs jours, puis elles commencent à fonctionner de la manière la plus rentable possible. Mais notre budget publicitaire était plus important que d'habitude, donc la campagne a appris plus vite et le deuxième jour, elle a commencé à générer des indicateurs vraiment sympas. À un moment donné, nous avons perdu le contrôle d'elle.
Nous comptions sur un certain taux de conversion, mais cela s'est avéré être plus simplement dû au fait que Facebook overclockait. Si le taux de conversion moyen dans de tels jeux est d'environ 8%, au moment de pointe, il atteint 15%.
Frais!
Irina: Oui, c'est à ce moment-là que nous avons compris ce que signifie un gros budget publicitaire. Certes, cela ne fonctionne que dans le cas de l'Occident - en Russie, il n'y a tout simplement pas de public pour dépenser autant d'argent.
Et, bien sûr, tout s'est passé vendredi. Classique! Vendredi soir, je reçois un message de Nikita disant que nous avons tellement de trafic que nous devons faire quelque chose à ce sujet.
Comment Nikita a-t-elle su cela? D'où vient ce signal?
Nikita: Nous avons des notifications automatiques de chargement du serveur. Voici à quoi cela ressemblait:

Une alerte arrive que la machine virtuelle (8 cœurs, 32 Go de mémoire) est chargée à 90% sur le CPU à la valeur seuil de 50%.
Ce n'est pas critique, car le service continue de fonctionner. Pour les joueurs, cela signifie qu'ils appuient sur le bouton "Exécuter le code" et attendent deux fois plus longtemps pour l'exécution. Mais cela signifie également que si de nouveaux joueurs continuent d'arriver, la situation va empirer, jusqu'à des temps d'arrêt.
En conséquence, le pire résultat a été évité - le service n'a pas complètement baissé?
Nikita: Heureusement, tout s'est bien terminé.
Bien sûr, si la situation était survenue au milieu de la journée de travail, nous ne nous serions pas du tout inquiétés - là, vous pouvez réagir rapidement. Mais pas vendredi soir. Le vendredi soir, vous vous rendez dans un bar et recevez ce message sur votre téléphone. Mais pour tout réparer, il ne suffit pas d'être au téléphone.
Comment avez-vous géré la situation?
Irina: Nous venons de réduire le coût des campagnes publicitaires de près de 70%.
Vous êtes-vous remis sur les rails plus tard?
Irina: Non, ils ne l'ont pas amené au même état, car la situation était imprévisible: Facebook augmentait et augmentait la conversion chaque jour. Si nous avions tourné à la même vitesse pendant une autre semaine, la conversion aurait peut-être été encore plus élevée. Mais des victoires héroïques n'étaient pas nécessaires, nous avons donc rétabli un niveau confortable. Il s'est avéré environ 10 cartes chargées, et le service a fonctionné tranquillement.
Nikita: Il faut noter qu'il y a d'autres aspects du problème: nous essayons de répondre rapidement aux messages des joueurs. Plus il y a de joueurs, plus ils génèrent de demandes d'assistance. Nous voulions maintenir un niveau de service élevé, et nous n'étions pas prêts à augmenter la quantité d'assistance aussi rapidement. Nous avons décidé qu'il serait plus sage de tout faire de manière plus fluide et prévisible que de faire un pic le week-end.
Cette fois, vous avez décidé d'étouffer la campagne publicitaire et ainsi sauvé la situation. Comment résolvez-vous généralement un problème de mise à l'échelle d'un point de vue technique?
Nikita: Nous évoluons en lançant des instances supplémentaires du service.
Dans ce cas, il ne s'agit pas de Kubernetes et il n'y a pas de mise à l'échelle automatique. Il est nécessaire de démarrer un clonage de machine virtuelle en mode semi-manuel - vous devez attendre jusqu'à une demi-heure pendant que la machine virtuelle est recréée à partir de l'image. Après cela, vous devez vérifier que la machine virtuelle fonctionne comme prévu et que tous les services qu'elle contient ont augmenté: serveurs LSP, exécuteurs de code. Ensuite, nous équilibrons le trafic vers les nouvelles machines et continuons à surveiller la charge de travail et les codes d'état.
Capture d'écran du jeu SberCraft
Conclusions et plans
Comment avez-vous réorganisé votre travail après cet incident?
Nikita: Nous avons déterminé la meilleure façon de planifier le marketing: quel investissement représente le montant des enregistrements.
Au niveau technique, nous sommes fermement convaincus que nous avons besoin d'une nouvelle façon de faire évoluer le service d'exécution de code, idéalement: l'autoscale.
Nous rendons le service d'exécution de code sans état (indépendant du système de stockage), apportons de petites modifications architecturales et modifions l'infrastructure - nous introduisons le même Kubernetes sur lequel les autres services s'exécutent.
Mais dans le cas d'un service d'exécution de code, le schéma est plus compliqué - il n'est pas aussi facile de le traduire que les autres. Nous vérifions toujours que tout fonctionne comme il se doit.
À l'heure actuelle, le code s'exécute sur DigitalOcean et s'exécutera sur le cloud Azure. Dans Kubernetes.
Vous utilisez Kubernetes en tant que service (Azure Kubernetes Service)?
Nikita: Oui. Nous utilisons Kubernetes en tant que service et envisageons également l'option Cloud Functions.
Comment fonctionne AWS Lambda?
Nikita: Oui, tous les principaux fournisseurs en ont. Ils vous permettent de payer exactement autant que vous effectuez des exécutions de code. Mais il existe des limitations techniques dans les capacités des environnements d'exécution.
Qui est actuellement en charge de l'infrastructure?
Nikita: Mes qualifications et qualifications de développeurs back-end ne sont pas toujours suffisantes, car DevOps, SRE sont un domaine très vaste. Et laisser les développeurs back-end en service pour les incidents n'est pas très correct. Par conséquent, au début de l'année, nous avons obtenu une équipe DevOps d'externalisation - les gars avec qui nous travaillions auparavant dans d'autres entreprises.
Pourquoi avez-vous commencé à collaborer avec l'équipe infrastructure et DevOps?
Nikita: L'incident avec le jeu a été le catalyseur de changements que nous reconnaissons depuis longtemps, mais que nous n'avons pas eu l'occasion de mettre en œuvre.
L'entreprise a grandi, des cas similaires ont commencé à se produire, ce qui a confirmé: oui, les gars, vous avez besoin d'ingénieurs DevOps, vous devez créer une infrastructure plus facile à mettre à l'échelle.
La tâche a été entièrement prise en charge il y a deux mois, lorsque nous avons reçu une subvention d'Azure. À l'heure actuelle, de nombreux services ont été déplacés vers le nouveau cloud.
Pourquoi avez-vous décidé d'externaliser plutôt que d'embaucher du personnel?
Nikita: De notre propre expérience, nous savons que DevOps est un domaine difficile à recruter. Et ici, il s'est avéré qu'il y avait des gars qui ont fait leurs preuves, et la forme de travail avec un entrepreneur est très pratique pour nous.
Eh bien, et le plus important: nous avons acquis non pas un ingénieur, mais toute une équipe qui surveille la disponibilité des services 24 heures sur 24 et est prête à répondre à un incident avant qu'il ne soit découvert par les utilisateurs.
L'équipe DevOps configure-t-elle tout à partir de zéro ou utilise-t-elle ce qu'elle était, y compris la surveillance?
Nikita: Nous avons emprunté la voie du déplacement. Nous démarrons de nouveaux projets dans une nouvelle infrastructure, y migrons les services de base et laissons les projets sous prise en charge dans l'ancienne. Tout est nouveau pour les nouveaux projets, y compris le suivi.
La particularité de la transformation est qu'il faut repenser l'architecture du service. Nous avons compris comment il peut être changé pour obtenir de nouvelles qualités.
Par conséquent, des travaux sont également en cours du côté backend: nous allons refactoriser le code, mettre à jour l'architecture, mais dans une quantité assez modérée.
Vous installez donc de nouveaux processus CI / CD en ce moment?
Tout d'abord, nous procédons à une restructuration organisationnelle. Nous avons un nouveau rôle, correspondant à l'équipe dédiée, et les modes de communication, de paramétrage des tâches ont changé.
Nous avions des processus CI / CD, ils ont juste commencé à passer à la nouvelle infrastructure. Bien sûr, ils s'améliorent, mais ils ne changent pas fondamentalement.
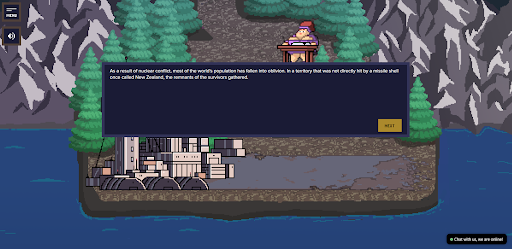
Capture d'écran du jeu SberCraft
Quelle conclusion globale avez-vous tirée pour vous-même?
À différentes étapes de la vie d'un projet, les choses sont différentes. Il y a six mois, nous n'aurions pas été prêts pour l'équipe DevOps nous-mêmes. Mais maintenant, nous pouvons communiquer avec eux de manière beaucoup plus substantielle. Nous comprenons clairement nos douleurs et sommes venus voir les gars avec une liste de questions et de suggestions sur la façon de faire quelque chose. Cela s'est avéré être une bonne collaboration: ensemble, nous sommes parvenus à des décisions de qualité et bien fondées.
Il y a encore beaucoup de travail à faire. Le service d'exécution de code dans le processus de migration, et comme le plus complexe de nos services, nécessitera beaucoup d'implication. Pendant un certain temps, nous aurons les deux versions du service en production et équilibrerons le trafic entre elles. Lorsque nous comprendrons que tout va bien, nous passerons complètement à Azure.
, . , .
, , , .
21 «» , .
:
— ,
— ,
— ,
— ,
— .
Databricks, Mail.ru Cloud Solutions TangoMe.