De nombreux projets utilisent désormais une architecture de microservices. Nous ne faisons pas non plus exception, et depuis plus de 2 ans maintenant, nous essayons de construire des RBS pour les personnes morales d'une banque utilisant des microservices.

Auteurs de l'article: ctimas et Alexey_Salaev
L'importance de l'architecture des microservices
Notre projet est un RBS pour les personnes morales. De nombreux processus différents sous le capot et une belle interface minimaliste. Mais ce ne fut pas toujours ainsi. Pendant longtemps, nous avons utilisé une solution d'un entrepreneur, mais un beau jour, il a été décidé de développer notre produit.
Au départ du projet, de nombreuses discussions ont eu lieu: quelle approche choisir? comment construire notre nouveau système RBS? Tout a commencé par des discussions «monolith vs microservices»: discuté des langages de programmation possibles utilisés, argumenté sur les frameworks («devrais-je utiliser spring cloud?», «Quel protocole dois-je choisir pour la communication entre microservices?»). Ces questions, en règle générale, ont un nombre limité de réponses, et nous choisissons simplement des approches et des technologies spécifiques en fonction des besoins et des capacités. Et la réponse à la question "Comment écrire des microservices eux-mêmes?" n'était pas tout à fait simple.
Beaucoup pourraient dire: «Pourquoi développer un concept d'architecture générale pour le microservice lui-même? Il existe une architecture d'entreprise et une architecture de projet, et un vecteur général de développement. Si vous attribuez une tâche à l'équipe, elle la terminera, le microservice sera écrit et il exécutera ses tâches. Après tout, c'est l'essence même des microservices - l'indépendance. " Et ils auront absolument raison! Mais avec le temps, les équipes deviennent plus grandes, par conséquent, le nombre de microservices et d'employés augmente, et il y a moins d'anciens. De nouveaux développeurs arrivent qui ont besoin de s'immerger dans le projet, certains développeurs changent d'équipes. De plus, les équipes cessent d'exister avec le temps, mais leurs microservices continuent de vivre et, dans certains cas, ils doivent être améliorés.
Tout en développant le concept général de l'architecture des microservices, nous nous laissons une grande réserve pour l'avenir:
- ;
- ;
- : .
Tous ceux qui travaillent avec des microservices sont bien conscients de leurs avantages et inconvénients, dont l'un est la possibilité de remplacer rapidement une ancienne implémentation par une nouvelle. Mais à quel point un microservice doit-il être petit pour pouvoir être facilement remplacé? Où se trouve la limite qui détermine la taille du microservice? Comment ne pas faire un mini monolithe ou un nanservice? Et vous pouvez toujours aller directement du côté des fonctions qui exécutent une petite partie de la logique et construire des processus métier en construisant l'ordre d'appeler de telles fonctions ...
Nous avons décidé de distinguer les microservices par domaines métiers (par exemple, le microservice pour roubles), et construisez eux-mêmes les microservices en fonction des tâches de ce domaine.
Prenons un exemple de processus métier standard pour n'importe quelle banque - "création d'un ordre de paiement"

Vous pouvez voir qu'une demande client apparemment simple est un ensemble d'opérations assez large. Ce scénario est approximatif, certaines étapes sont omises par souci de simplicité, certaines des étapes se produisent au niveau des composants d'infrastructure et n'atteignent pas la logique métier principale dans le service produit, l'autre partie des opérations fonctionne de manière asynchrone. L'essentiel est que nous avons un processus qui à un moment donné peut utiliser de nombreux services voisins, utiliser les fonctionnalités de différentes bibliothèques, implémenter une sorte de logique à l'intérieur de lui-même et enregistrer des données dans divers stockages.
En y regardant de plus près, vous pouvez voir que le processus métier est assez linéaire et qu'au cours de son travail, il devra soit obtenir des données quelque part, soit traiter d'une manière ou d'une autre les données dont il dispose, ce qui peut nécessiter de travailler avec des sources de données externes ( microservices, bases de données) ou logique (bibliothèques).

Certains microservices ne correspondent pas à ce concept, mais le nombre de ces microservices dans le pourcentage global est faible et s'élève à environ 5%.
Une architecture propre
Après avoir examiné différentes approches d'organisation du code, nous avons décidé d'essayer une approche «d'architecture propre» en organisant le code dans nos microservices sous forme de couches.
Concernant «l'architecture propre» elle-même, plus d'un livre a été écrit, il existe de nombreux articles à la fois sur Internet et sur Habré ( article 1 , article 2 ), plus d'une fois ses avantages et ses inconvénients ont été discutés.
Un diagramme populaire qui peut être trouvé sur ce sujet a été dessiné par Bob Martin dans son livre Clean Architecture:

Ici, le diagramme à secteurs sur la gauche au centre montre la direction des dépendances entre les couches, et modestement dans le coin droit, vous pouvez voir le direction du flux d'exécution.
Cette approche, comme, en fait, dans toute technologie de programmation, a ses avantages et ses inconvénients. Mais pour nous, il y a beaucoup plus d'aspects positifs que négatifs lors de l'utilisation de cette approche.
Implémentation d'une "architecture propre" dans le projet
Nous avons redessiné ce diagramme en fonction de notre scénario.
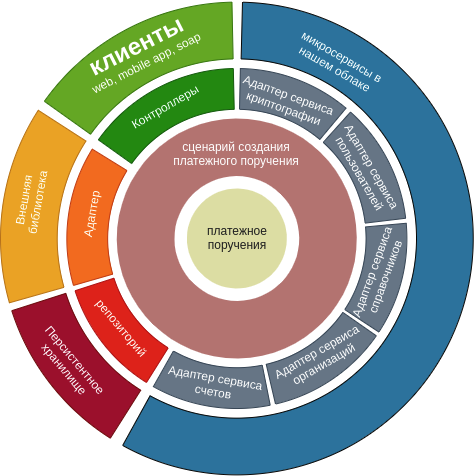
Naturellement, ce diagramme reflète un scénario. Il arrive souvent qu'un microservice effectue plus d'opérations sur une entité de domaine, mais, pour être honnête, de nombreux adaptateurs peuvent être réutilisés.
Différentes approches peuvent être utilisées pour séparer le microservice en couches, mais nous avons choisi la division en modules au niveau du constructeur de projet. La mise en œuvre au niveau du module fournit une perception visuelle plus facile du projet et fournit également une autre couche de protection pour les projets contre une mauvaise utilisation du style architectural.
Par expérience, nous avons remarqué que lorsqu'il est immergé dans un projet, un nouveau développeur a juste besoin de se familiariser avec la partie théorique et il peut facilement et rapidement naviguer dans presque tous les microservices.
Nous utilisons Gradle pour construire nos microservices en Java, de sorte que les couches principales sont formées comme un ensemble de ses modules:

Maintenant, notre projet se compose de modules qui implémentent des contrats ou les utilisent. Pour que ces modules commencent à fonctionner et à résoudre les problèmes, nous devons implémenter l'injection de dépendances et créer un point d'entrée qui lancera l'ensemble de notre application. Et ici il y a une question intéressante dans le livre Uncle Bob "Pure architecture" il y a des chapitres entiers qui nous parlent des détails, des modèles et des frameworks, mais nous ne construisons pas son architecture autour du framework ou autour de la base de données, nous les utilisons comme l'un des composants ...
Lorsque nous avons besoin de sauvegarder l'entité, nous nous référons à la base de données, par exemple, pour que notre script reçoive les implémentations de contrat dont il a besoin au moment de l'exécution, nous utilisons le framework qui donne notre architecture DI.
Il y a des tâches où nous devons implémenter un microservice sans base de données, ou nous pouvons abandonner DI, car la tâche est trop simple et il est plus rapide de la résoudre de front. Et si nous allons effectuer tout le travail avec la base de données dans le module "référentiel", alors où utilisons-nous le framework pour préparer toutes les DI pour nous? Il n'y a pas tellement d'options: soit nous ajoutons une dépendance à chaque module de notre application, soit nous essaierons de sélectionner la DI entière comme un module séparé.
Nous avons choisi une nouvelle approche de module distincte et l'appelons «infrastructure» ou «application».
Certes, lorsqu'un tel module est introduit, le principe est légèrement violé, selon lequel nous dirigeons toutes les dépendances vers le centre vers la couche de domaine, car il doit avoir accès à toutes les classes de l'application.
Cela ne fonctionnera pas d'ajouter une couche d'infrastructure à notre oignon sous la forme d'une couche, il n'y a tout simplement pas de place pour cela là-bas, mais ici vous pouvez tout regarder sous un angle différent, et il s'avère que nous avons un cercle " Infrastructure »et notre oignon feuilleté est dessus ... Pour plus de clarté, essayons de séparer un peu les couches pour les rendre plus visibles:

ajoutez un nouveau module et regardez l'arborescence des dépendances sur la couche d'infrastructure pour voir les dépendances finales entre les modules: il

ne reste plus qu'à ajouter le Cadre DI lui-même. Nous utilisons Spring dans notre projet, mais ce n'est pas obligatoire, vous pouvez prendre n'importe quel framework qui implémente DI (par exemple, micronaut).
Comment créer un microservice et où sera la partie du code - nous avons déjà décidé, et cela vaut la peine de revoir le scénario commercial, car il y a un autre point intéressant.
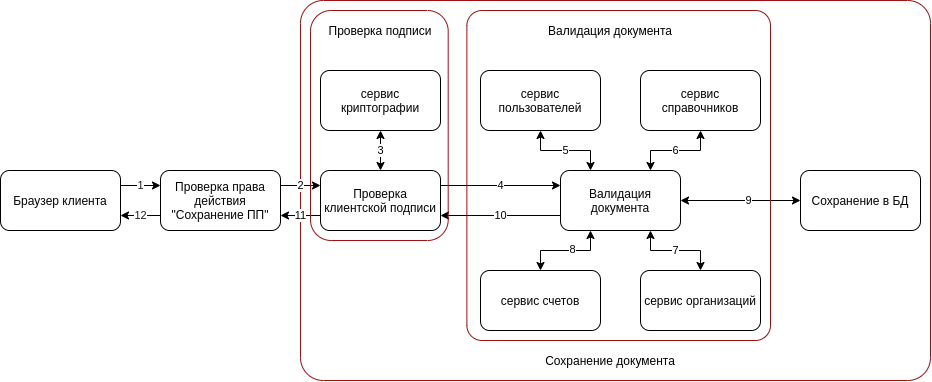
Le diagramme montre que la vérification du droit d'action peut ne pas être effectuée dans le script principal. Il s'agit d'une tâche distincte qui ne dépend pas de ce qui se passe ensuite. La vérification de signature pourrait être déplacée vers un microservice séparé, mais ici il y a de nombreuses contradictions lors de la définition de la limite du microservice, et nous avons décidé d'ajouter simplement une autre couche à notre architecture.
Dans des couches séparées, il est nécessaire de mettre en évidence les étapes qui peuvent être répétées dans notre application, par exemple, la vérification de signature. Cette procédure peut se produire lors de la création, de la modification ou de la signature d'un document. De nombreux scripts principaux démarrent d'abord les petites opérations, puis uniquement le script principal. Par conséquent, il nous est plus facile d'isoler les petites opérations en petits scripts, décomposés en couches afin de pouvoir les réutiliser plus facilement.
Cette approche facilite la compréhension de la logique métier et, au fil du temps, un ensemble de blocs de construction pour petites entreprises se formera et pourra être réutilisé.
Il n'y a pas grand chose à dire sur le code des adaptateurs, des contrôleurs et des référentiels. ils sont assez simples. Les adaptateurs pour un autre microservice utilisent un client généré à partir d'un swagger, d'un Spring RestTemplate ou d'un client Grpc. Dans les référentiels - l'une des variantes de l'utilisation d'Hibernate ou d'autres ORM. Les contrôleurs obéiront à la bibliothèque que vous utiliserez.
Conclusion
Dans cet article, nous voulions montrer pourquoi nous construisons une architecture de microservices, quelles approches nous utilisons et comment nous développons. Notre projet est jeune et n'en est qu'au tout début de son parcours, mais déjà maintenant nous pouvons mettre en évidence les principaux points de son développement du point de vue de l'architecture du microservice lui-même.
Nous construisons des microservices multi-modules, dont les avantages incluent:
- , - , , - , ;
- , , - ;
- , Api, , , , ;
- , , , , .
Pas sans, bien sûr, une mouche dans la pommade. Par exemple, la chose la plus évidente est que souvent chaque module fonctionne avec ses propres petits modèles. Par exemple, dans le contrôleur, vous aurez une description des modèles restants, et dans le référentiel, il y aura des entités de base de données. Dans ce contexte, vous devez beaucoup mapper les objets les uns aux autres, mais des outils tels que «mapstruct» vous permettent de le faire rapidement et de manière fiable.
En outre, les inconvénients incluent le fait que vous devez constamment surveiller les autres développeurs, car il y a une tentation de faire moins de travail que cela ne coûte. Par exemple, déplacer le cadre un peu plus d'un module, mais cela conduit à l'érosion de la responsabilité de ce cadre dans toute l'architecture, ce qui à l'avenir peut affecter négativement la vitesse des améliorations.
Cette approche de mise en œuvre de microservices convient aux projets à longue durée de vie et aux projets au comportement complexe. Étant donné que la mise en œuvre de toute l'infrastructure prend du temps, mais à l'avenir, elle est payante par la stabilité et des améliorations rapides.