
!
, Head of AI Celsus. .
, , ML- . «» — , , .
ML- DS-, , CV .
Alors, supposons que vous décidiez de fonder une start-up d'IA pour détecter le cancer du sein (au fait, le type d'oncologie le plus courant chez les femmes) et que vous allez créer un système qui détectera avec précision les signes de pathologie lors des examens mammographiques, assurez-vous que le médecin contre les erreurs, et réduire le temps de poser un diagnostic ... Une mission brillante, n'est-ce pas?

Vous avez réuni une équipe de programmeurs, d'ingénieurs et d'analystes ML talentueux, acheté du matériel coûteux, loué un bureau et élaboré une stratégie marketing. Tout semble prêt pour commencer à changer le monde pour le mieux! Hélas, tout n'est pas si simple, car vous avez oublié la chose la plus importante - les données. Sans eux, vous ne pouvez pas entraîner un réseau de neurones ou un autre modèle d'apprentissage automatique.
C'est là que réside l'un des principaux obstacles - la quantité et la qualité des ensembles de données disponibles. Malheureusement, dans le domaine de la médecine diagnostique, il existe encore très peu d'ensembles de données complets, vérifiés et de haute qualité, et encore moins d'entre eux sont accessibles au public pour les chercheurs et les entreprises d'IA.
Considérez la situation en utilisant le même exemple de détection du cancer du sein. Des ensembles de données publiques plus ou moins de haute qualité peuvent être comptés sur les doigts d'une main: DDSM (environ 2600 cas), InBreast (115), MIAS (161). Il existe également OPTIMAM et BCDR avec une procédure assez compliquée et déroutante pour accéder.
Et même si vous avez pu collecter une quantité suffisante de données publiques, le prochain obstacle vous attend: la quasi-totalité de ces ensembles de données ne peuvent être utilisées qu'à des fins non commerciales. De plus, le balisage peut être complètement différent - et ce n'est pas un fait qu'il convient à votre tâche. En général, sans collecter vos propres jeux de données et leur balisage, il sera possible de ne faire qu'un MVP, mais pas un produit de haute qualité, prêt à fonctionner en conditions de combat.
Ainsi, vous avez envoyé des demandes aux institutions médicales, soulevé toutes vos connexions et contacts, et reçu une collection hétéroclite de diverses photos entre vos mains. Ne vous réjouissez pas à l'avance, vous êtes au tout début du chemin! En effet, malgré la présence d'une norme unifiée pour le stockage des images médicales, DICOM(Imagerie numérique et communications en médecine), dans la vraie vie, tout n'est pas si rose. Par exemple, les informations sur le côté (gauche / droite) et la projection ( CC / MLO ) d'une image du sein peuvent être stockées dans différentes sources de données dans des champs complètement différents. La seule solution ici est de collecter des données à partir du plus grand nombre de sources possible et d'essayer de prendre en compte toutes les options possibles dans la logique du service.
Ce que vous marquez est ce que vous récoltez
Nous sommes finalement arrivés à la partie amusante - le processus de balisage des données. Qu'est-ce qui le rend si spécial et inoubliable dans le domaine médical? Premièrement, le processus de marquage lui-même est beaucoup plus compliqué et plus long que dans la plupart des industries. Les rayons X ne peuvent pas être téléchargés sur Yandex.Toloka et vous pouvez obtenir un ensemble de données étiqueté pour un centime. Cela nécessite un travail minutieux de la part de médecins spécialistes, et il est conseillé de donner chaque image pour le marquage à plusieurs médecins - ce qui est coûteux et prend du temps.
Pire encore: les experts sont souvent en désaccord et donnent des marques complètement différentes des mêmes images à la sortie. Les médecins ont des qualifications, une formation et un niveau de «suspicion» différents. Quelqu'un marque parfaitement tous les objets de l'image le long du contour, et quelqu'un - avec des cadres larges. Enfin, l'un d'eux est plein d'énergie et d'enthousiasme, tandis qu'un autre marque des photos sur un petit écran d'ordinateur portable après un quart de travail de vingt heures. Tous ces écarts "rendent naturellement fous" les réseaux de neurones, et vous n'obtiendrez pas un modèle de haute qualité dans de telles conditions.
La situation n'est pas non plus améliorée par le fait que la plupart des erreurs et des écarts se produisent précisément dans les cas les plus complexes, les plus précieux pour l'entraînement des neurones. Par exemple, la recherchemontrent que la plupart des erreurs commises par les médecins lorsqu'ils posent un diagnostic sur des mammographies avec une densité accrue de tissu mammaire, il n'est donc pas surprenant qu'elles soient également les plus difficiles pour les systèmes d'IA.
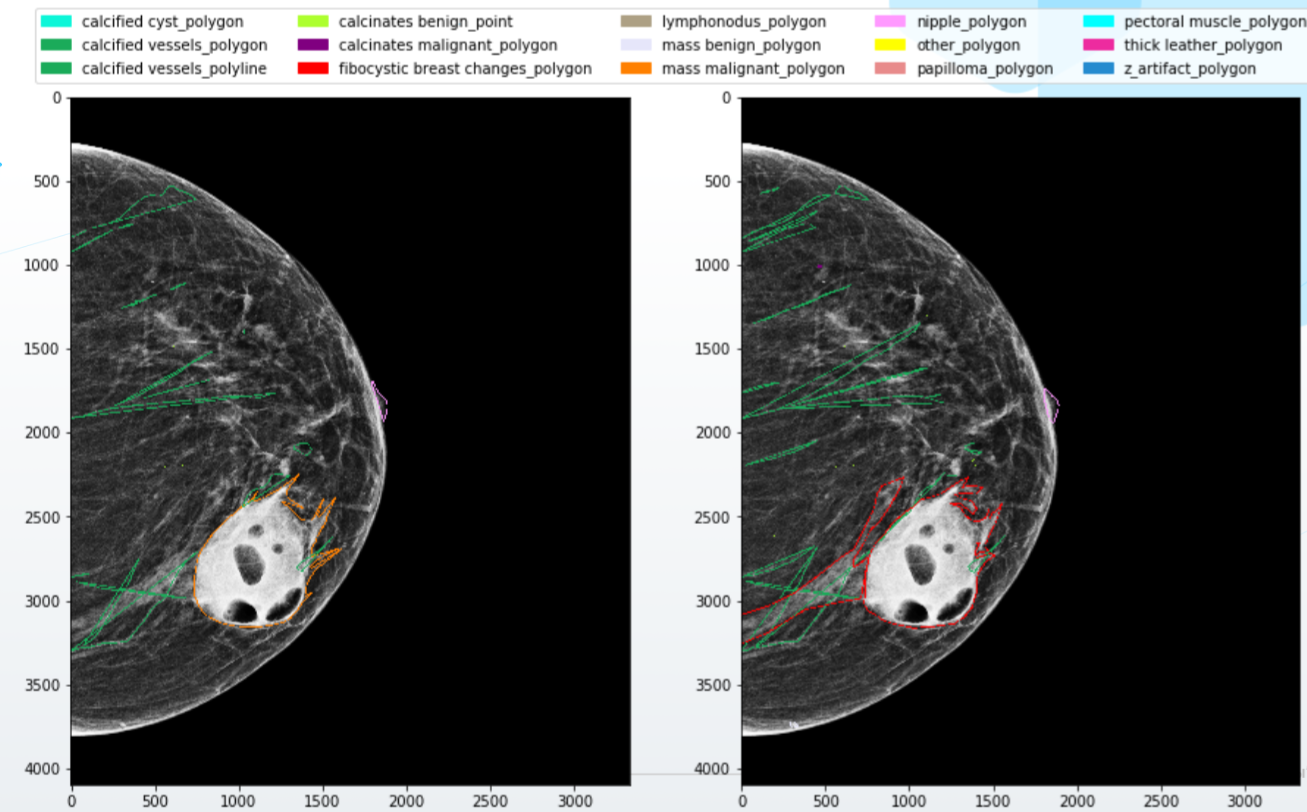
Que faire? Bien sûr, tout d'abord, vous devez construire un système d'interaction de haute qualité avec les médecins. Rédigez des règles détaillées pour le balisage, avec des exemples et des visualisations, fournissez aux spécialistes des logiciels et des équipements de haute qualité, notez la logique de combinaison de conflits mineurs dans le balisage et demandez un avis supplémentaire en cas de conflits plus graves.
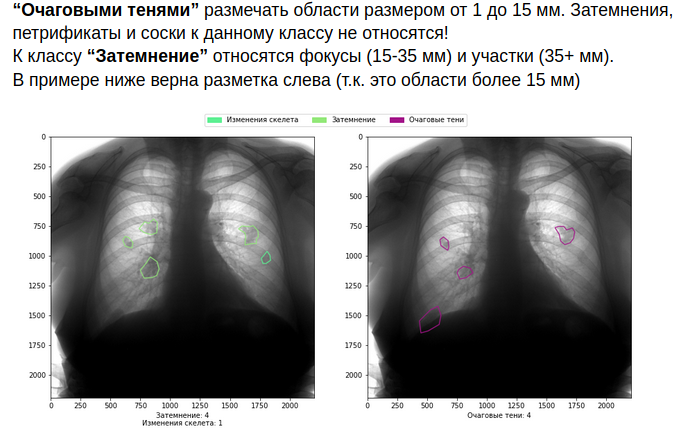
Comme vous pouvez l'imaginer, tout cela augmente le coût de la majoration. Mais si vous n'êtes pas prêt à les prendre sur vous, mieux vaut ne pas vous lancer dans le domaine de la médecine.
Bien sûr, si vous abordez le processus avec sagesse, les coûts peuvent et doivent être réduits - par exemple, grâce à un apprentissage actif. Dans ce cas, le système ML lui-même indique aux médecins quelles images doivent être marquées en plus afin de maximiser la qualité de la reconnaissance de la pathologie. Il existe différentes façons d'évaluer la confiance d'un modèle dans ses prédictions - perte d'apprentissage, apprentissage actif discriminant, décrochage MC, entropie des probabilités prédites, branche de confiance et bien d'autres. Lequel est préférable d'utiliser, seules les expériences sur vos modèles et ensembles de données s'afficheront.
Enfin, vous pouvez complètement abandonner le balisage des médecins et ne vous fier qu'aux résultats finaux et confirmés - par exemple, le décès ou le rétablissement du patient. C'est peut-être la meilleure approche (bien qu'il y ait beaucoup de nuances ici), mais elle ne peut commencer à fonctionner que dans dix à quinze ans, au mieux, avec des PACS à part entière (systèmes d'archivage d'images et de communication) et des systèmes d'information médicale (MIS ) et quand suffisamment de données ont été accumulées. Mais même dans ce cas, personne ne garantit la pureté et la qualité de ces données.
Bon modèle - bon prétraitement

Hourra! Le modèle a été formé, montre d'excellents résultats et est prêt à être testé. Des accords de coopération ont été conclus avec plusieurs organisations médicales, le système a été installé et configuré, une démonstration a été effectuée auprès des médecins et les capacités du système ont été présentées.
Et maintenant, le premier jour du fonctionnement du système est terminé, vous ouvrez le tableau de bord avec des métriques avec un cœur qui coule ... Et vous voyez l'image suivante: un tas de requêtes au système, avec zéro objet détecté par le système et, de bien sûr, une réaction négative des médecins. Comment? Après tout, le système s'est avéré excellent dans les tests internes!
Après une analyse plus approfondie, il s'avère que dans cette institution médicale, il existe une sorte d'appareil à rayons X qui ne vous est pas familier avec ses propres paramètres et que, par conséquent, les images sont complètement différentes. Le réseau neuronal n'a pas été formé sur de telles images, il n'est donc pas surprenant qu'il "échoue" sur elles et ne détecte rien. Dans le monde de l'apprentissage automatique, de tels cas sont communément appelés données hors distribution. Les modèles fonctionnent généralement bien moins bien sur ces données, et c'est l'un des principaux problèmes de l'apprentissage automatique.
Exemple illustratif: notre équipe a testé un modèle publicde chercheurs de l'Université de New York, formés sur un million d'images. Les auteurs de l'article soutiennent que le modèle a démontré une haute qualité de détection de l'oncologie sur les mammographies, et plus précisément, ils parlent du taux de précision ROC-AUC dans la région de 0,88 à 0,89. Sur nos données, le même modèle montre des résultats nettement moins bons - de 0,65 à 0,70, selon l'ensemble de données.
La solution la plus simple à ce problème en surface est de collecter tous les types d'images possibles, de tous les appareils, avec tous les paramètres, de les marquer et de former le système sur eux. Les inconvénients? Encore une fois, long et coûteux. Dans certains cas, vous pouvez vous passer de balisage - un apprentissage non supervisé vous viendra en aide. Les images non étiquetées sont données au neurone d'une certaine manière, et le modèle «s'habitue» à leurs caractéristiques, ce qui lui permet de détecter avec succès des objets dans des images similaires à l'avenir. Cela peut être fait, par exemple, en utilisant un pseudo-balisage d'images non étiquetées ou diverses tâches auxiliaires.
Cependant, ce n'est pas non plus une panacée. De plus, cette méthode vous oblige à collecter tous les types d'images existant dans le monde, ce qui, en principe, semble être une tâche impossible. Et la meilleure solution ici serait d'utiliser le prétraitement universel.
Le prétraitement est un algorithme permettant de traiter les données d'entrée avant de les alimenter dans un réseau neuronal. Cette procédure peut inclure des changements automatiques de contraste et de luminosité, diverses normalisations statistiques et la suppression des parties inutiles de l'image (artefacts).
Par exemple, après de nombreuses expériences, notre équipe a réussi à créer un prétraitement universel pour les images radiographiques de la glande mammaire, qui donne à presque toutes les images d'entrée une forme uniforme, ce qui permet au réseau neuronal de les traiter correctement.

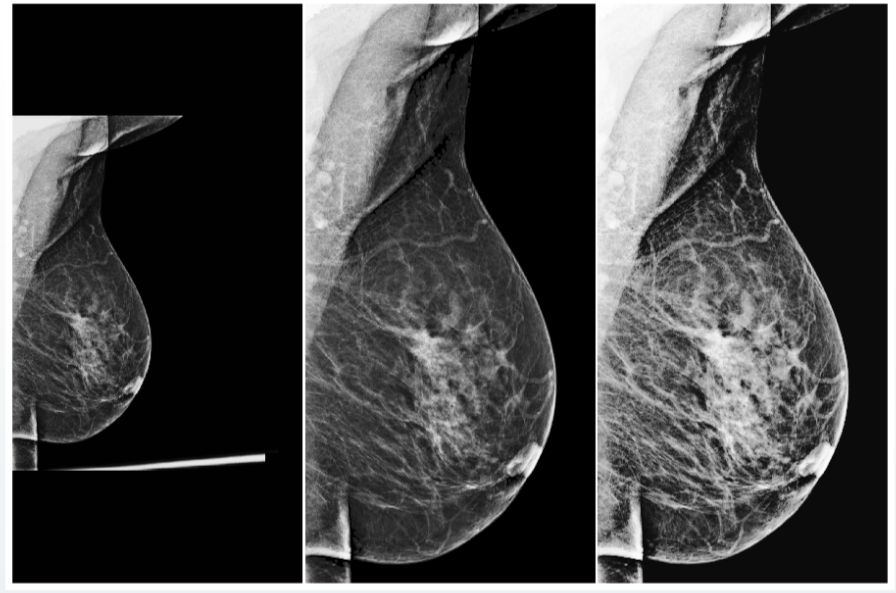
Mais même avec le prétraitement universel, vous ne devez pas oublier les contrôles de qualité des données d'entrée. Par exemple, dans les ensembles de données fluorographiques, nous sommes souvent tombés sur des images de test, qui comprenaient des sacs, des bouteilles et d'autres objets. Si le système attribue une probabilité de présence d'une pathologie dans une telle image, cela n'augmente clairement pas la confiance de la communauté médicale dans votre modèle. Pour éviter de tels problèmes, les systèmes d'IA doivent également signaler leur confiance dans les prévisions correctes et dans la validité des données d'entrée.

Un matériel différent n'est pas le seul problème lié à la capacité des systèmes d'IA à généraliser, généraliser et travailler avec de nouvelles données. Les caractéristiques démographiques de l'ensemble de données sont un paramètre très important. Par exemple, si votre échantillon de formation est dominé par des Russes de plus de 60 ans, personne ne peut garantir que le modèle fonctionnera correctement sur les jeunes Asiatiques. Il est impératif de contrôler la similitude des indicateurs statistiques de l'échantillon de formation et de la population réelle pour laquelle le système sera utilisé.
Si des divergences sont constatées, il est impératif de procéder à des tests et, très probablement, à une formation supplémentaire ou à un réglage fin du modèle. Il est impératif d'effectuer un suivi constant et une révision régulière du système. Dans le monde réel, un million de choses peuvent arriver: l'appareil à rayons X a été remplacé, un nouvel assistant de laboratoire est arrivé qui fait des recherches d'une manière différente, des foules de migrants d'un autre pays ont soudainement envahi la ville. Tout cela peut conduire à une dégradation de la qualité de votre système d'IA.
Cependant, comme vous l'avez peut-être deviné, l'apprentissage n'est pas tout. Le système doit être évalué au minimum et les mesures standard peuvent ne pas être applicables dans le domaine médical. Cela rend également difficile l'évaluation des services d'IA concurrents. Mais c'est le sujet de la deuxième partie du matériel - comme toujours, basé sur notre expérience personnelle.