
Je m'appelle Sasha, chez SberDevices je travaille sur la reconnaissance vocale et comment les données peuvent l'améliorer. Dans cet article, je parlerai du nouvel ensemble de données vocales Golos, qui se compose de fichiers audio et de transcriptions correspondantes. La durée totale des enregistrements est d'environ 1240 heures, la fréquence d'échantillonnage est de 16 kHz. Pour le moment, il s'agit du plus grand corpus d'enregistrements audio en russe, marqué à la main. Nous avons publié le corpus sous une licence proche de CC Attribution ShareAlike , ce qui lui permet d'être utilisé à la fois à des fins de recherche scientifique et à des fins commerciales. Je parlerai de ce en quoi consiste l'ensemble de données, de la manière dont il a été assemblé et des résultats qu'il peut obtenir.
Structure du jeu de données Golos
Lors de la création du jeu de données, nous avons été guidés par la volonté de résoudre le problème du démarrage à froid, lorsque les données d'utilisateurs réels n'étaient pas encore disponibles. C'est ce qui a finalement permis de le rendre accessible au public, puisque le discours des vrais utilisateurs n'y est pas.
Les enregistrements audio de l'ensemble de données sont collectés à partir de deux sources. La première source est une plateforme de crowdsourcing, c'est pourquoi nous l'appelons Crowd Domain. La deuxième source est constituée des enregistrements créés dans le studio à l'aide du périphérique cible SberPortal. Il dispose d'un système de microphone spécial, et c'est l'un des appareils sur lesquels notre reconnaissance vocale devrait fonctionner.
Nous appelons cette source Farfield-domain, car la distance entre l'utilisateur et l'appareil est généralement assez grande. Pour enregistrer via SberPortal en studio, nous avons utilisé trois distances: 1, 3 et 5 mètres de l'utilisateur à l'appareil. Chaque domaine a une partie formation et test, la structure résultante est indiquée dans le tableau:
| Domaines | Partie formation | Partie test |
|---|---|---|
| Foule | 979 796 fichiers | 1095 heures | 9994 fichiers | 11,2 heures |
| Farfield | 124 003 fiches | 132,4 heures | 1916 fiches | 1,4 heures |
| Le total | 1 103 799 fichiers | 1227,4 heures | 11910 fiches | 12,6 heures |
Il n'y a pas d'informations personnelles dans l'ensemble de données, telles que l'âge, le sexe ou l'identifiant d'utilisateur - tout est impersonnel. Les parties de formation et de test peuvent contenir le discours du même utilisateur.
| Statistiques \ Domaines | Foule | Farfield |
|---|---|---|
| numéro | 979796 fiches | 124003 fiches |
| Moyenne | 4,0 s | 3,8 sec. |
| Écart-type | 1,9 sec. | 1,6 sec. |
| 1er centile | 1,4 sec. | 2,0 sec. |
| 50e centile | 3,7 sec. | 3,5 sec. |
| 95e centile | 7,3 sec. | 6,8 sec. |
| 99e centile | 10,5 sec. | 9,6 sec. |
Le tableau ci-dessus fournit des informations statistiques sur les entrées: moyenne, écart type et centiles. Pour plus de clarté, la figure montre deux histogrammes de la distribution des longueurs d'enregistrement:
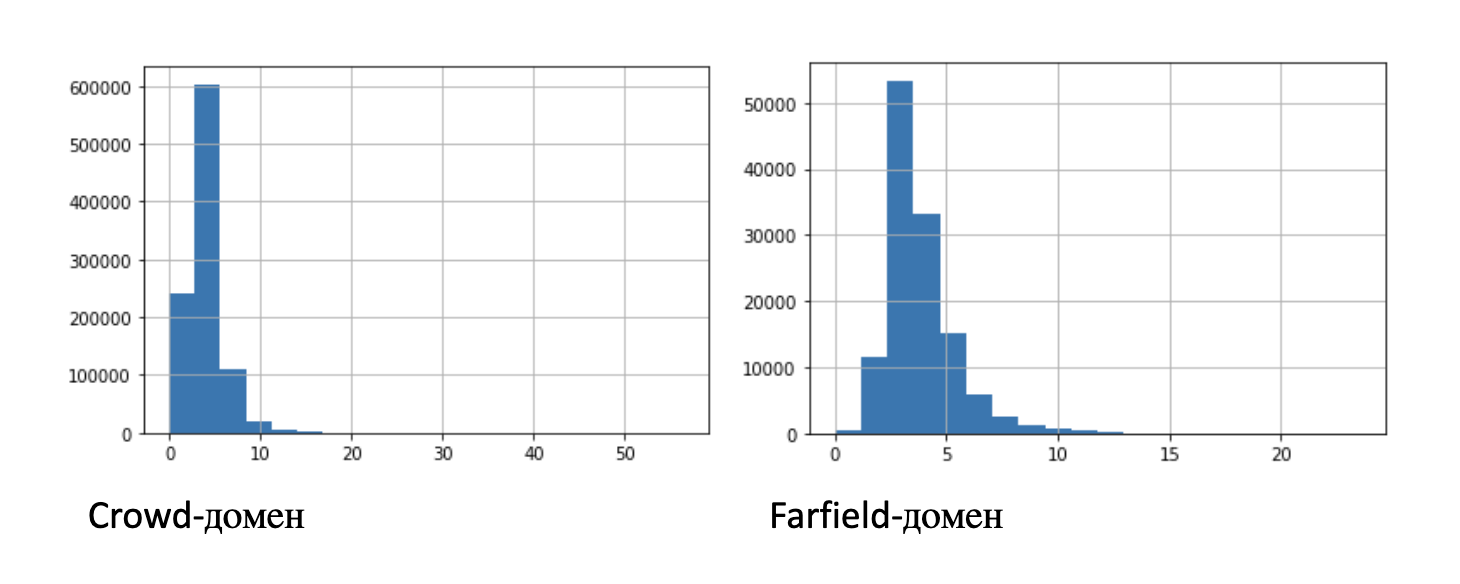
Pour les expériences avec un nombre limité d'enregistrements, nous avons identifié des sous-ensembles de plus courte durée: 100 heures, 10 heures, 1 heure, 10 minutes.
Collecte de données
Chez SberDevices, nous développons la famille d'assistants virtuels Salute, nous avons donc généré un discours similaire aux demandes des utilisateurs pour un assistant. Nous avons créé un système de modèles pour décrire les demandes dans divers domaines - musique, films, commande de produits et autres. Ce sont des expressions qui décrivent la structure d'une requête et la décomposent en composants. À l'aide de modèles, nous pouvons générer des requêtes raisonnables, recycler le modèle acoustique, créer un modèle de langage basé sur ces requêtes, et bien plus encore.
Exemples de modèles:
| Modèle | Exemple |
|---|---|
| [command_demands_vp] + [film_syn_vp] + [film_title_ip] | Lire le livre vert du film |
| [command_demands_ip] + [film_syn_ip] + [film_title_ip] | Vous avez un livre vert de film |
| [command_demands_ip] + [film_title_ip] | Avez-vous un livre vert |
| [film_title_ip] + [command_demands_vp] | mettre le livre vert |
| [film_syn_ip] + [film_title_ip] + [command_demands_vp] | filmer le livre vert mis |
| [film_title_ip] | livre vert |
| [command_demands_vp] + [film_title_ip] | allume le livre vert |
| [film_syn_ip] + [film_title_ip] | livre vert film |
| [command_demands_vp] + [film_title_ip] | Allumez le livre vert |
| ... | ... |
Entre crochets - la désignation de l'entité correspondante. Plus loin dans le tableau pour deux entités «film_title_ip» et «film_title_vp», il existe des options possibles pour le remplir:
| film_title_ip | film_title_vp |
|---|---|
| obsession | obsession |
| l'évasion | l'évasion |
| La belle et la bête | la belle et la Bête |
| île | île |
| Jane Eyre | Jane Eyre |
| Les Hauts de Hurlevent | Les Hauts de Hurlevent |
| ... | ... |
Le processus de création d'un jeu de données audio balisé se compose de plusieurs étapes:
- Étape 1. Tout d'abord, nous créons des modèles pour un certain domaine.
- 2. - . , :
- 3. «» :
- 4. – , , . – . 80% Golos. , “”, , . , , .
- 4*. - , , , , , , . , . , , , , , . , .

- 5*. , . , . , , , . , , , . , , , . , . :

:
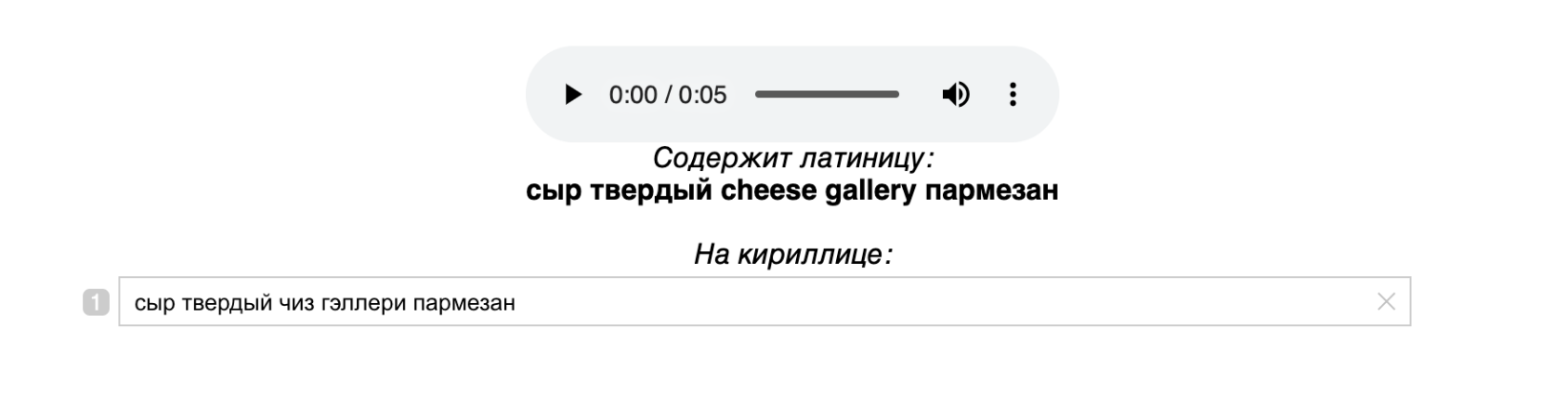
, . .
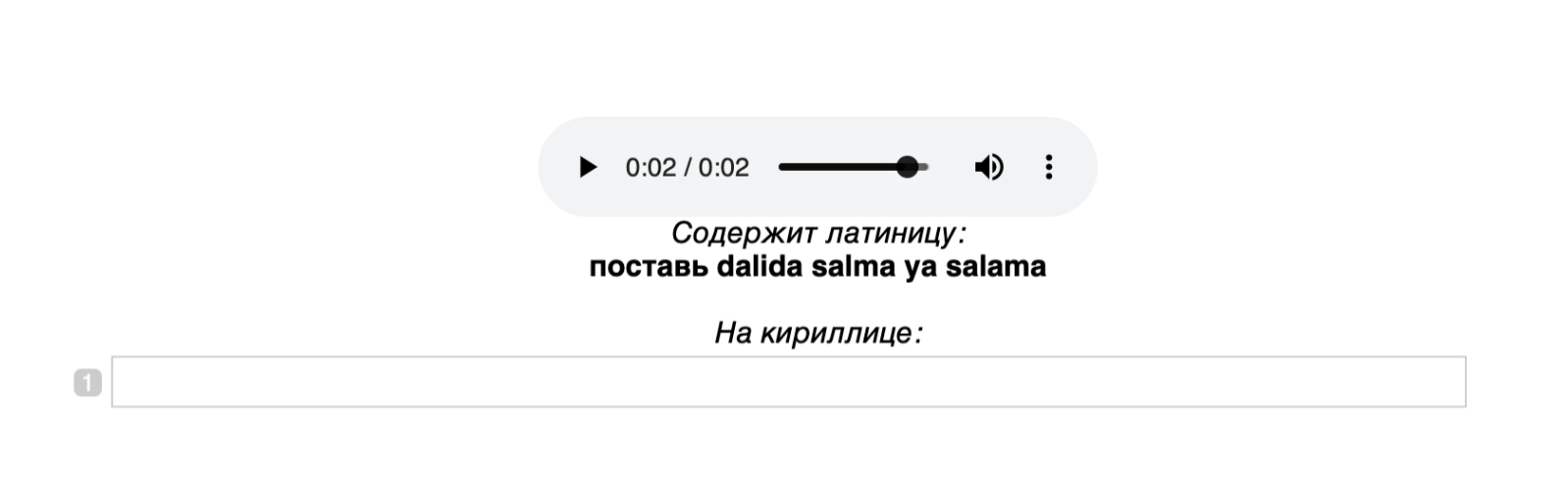
, , , .
- 5 . 3 , .
. -, , . -, . , .
, , “” – , “” - . , , , ( ) . bias , , . , . , .
Le processus décrit de création d'un ensemble de données vous permet de rendre le balisage de la plus haute qualité possible, ce qui le distingue des autres créés automatiquement ou semi-automatiquement. Nous utilisons ces données pour créer un système de reconnaissance vocale dans nos appareils. En raison de la haute qualité des marquages, la précision du système résultant est comparable à celle d'un humain. Toutes les données, ainsi que les modèles acoustiques et linguistiques formés pour la reconnaissance vocale, sont disponibles sur la page GitHub du projet , ainsi que dans ML Space de Sbercloud , un service de formation de modèles d'apprentissage automatique, où notre ensemble de données peut être téléchargé de manière transparente directement dans l'interface. . Nous vous en dirons plus sur l'utilisation de ML Space et sur la manière dont nous l'avons utilisé pour enseigner les modèles de reconnaissance vocale dans le prochain article.
Actuellement, il y a beaucoup de données ouvertes en anglais, mais il n'y avait pas de jeu de données de haute qualité en langue russe. Maintenant, un corpus est également disponible en russe, qui peut être utilisé pour la reconnaissance et la synthèse de la parole, et le modèle formé sur eux montre une très haute qualité. Nous pensons que l'ensemble de données Golos permettra à la communauté scientifique russe d'avancer encore plus rapidement dans l'amélioration des technologies de la parole en russe.