
La nature n'a pas de mauvais temps, chaque temps est grâce. Les paroles de cette chanson lyrique peuvent être comprises au sens figuré, interprétant le temps comme une relation entre les gens. Vous pouvez comprendre littéralement, ce qui est également vrai, car il n'y aurait pas d'hiver enneigé et froid, nous ne valoriserions pas autant l'été, et vice versa. Mais les véhicules sans pilote sont dépourvus de sentiments lyriques et de perspectives poétiques, pour eux tout le temps n'est pas grâce, en particulier l'hiver. L'un des principaux problèmes rencontrés par les développeurs de "véhicules robotisés" est la diminution de la précision des capteurs qui indiquent à la voiture où aller en cas de mauvaises conditions météorologiques. Des scientifiques de la Michigan Technological University ont créé une base de données des conditions météorologiques sur les routes "à travers les yeux" des véhicules sans pilote. Ces données étaient nécessaires afin de comprendre ce qui doit être modifié ou amélioré pour que la vision des véhicules robotisés lors d'une tempête de neige ne soit pas pire,que par une belle journée d'été. Dans quelle mesure le mauvais temps affecte-t-il les capteurs des véhicules sans pilote, quelle méthode de résolution du problème les scientifiques proposent-ils et quelle est son efficacité ? Nous trouverons des réponses à ces questions dans le rapport des scientifiques. Va.
Base de recherche
Le fonctionnement des voitures autonomes peut être comparé à une équation dans laquelle de nombreuses variables doivent être prises en compte sans exception pour obtenir le résultat correct. Les piétons, les autres voitures, la qualité de la chaussée (visibilité des lignes de séparation), l'intégrité des systèmes du drone lui-même, etc. De nombreuses recherches de scientifiques, des déclarations provocatrices d'hommes politiques, des articles tranchants de journalistes sont basés sur le lien entre un véhicule sans pilote (ci-après simplement une voiture ou une voiture) et un piéton. C'est assez logique, car une personne et sa sécurité doivent primer, surtout compte tenu de l'imprévisibilité de son comportement. Les différends moraux et éthiques sur qui sera à blâmer si une voiture heurte un piéton qui a sauté sur la route continue à ce jour.
Cependant, si nous supprimons la variable « piéton » de notre équation figurative, alors il y aura toujours de nombreux facteurs potentiellement dangereux. La météo en fait partie. Évidemment, par mauvais temps (orage ou tempête de neige), la visibilité peut tellement diminuer qu'il suffit parfois de s'arrêter, car il est irréaliste de conduire. La vision des voitures, bien sûr, est difficile à comparer avec la vision d'une personne, mais leurs capteurs souffrent d'une visibilité réduite pas moins que nous. D'autre part, les voitures disposent d'un arsenal plus large de ces capteurs : caméras, radars à ondes millimétriques (MMW), système de positionnement global (GPS), stabilisateur gyroscopique (IMU), détection et télémétrie par la lumière (LIDAR) et même des systèmes à ultrasons. Malgré cette variété de sens, les voitures autonomes restent aveugles par mauvais temps.
Pour comprendre de quoi il s'agit, les scientifiques proposent de considérer des aspects dont la combinaison affecte d'une manière ou d'une autre une solution possible à ce problème : segmentation sémantique, détection d'un chemin passable (adapté) et combinaison de capteurs.
Avec la segmentation sémantique, au lieu de détecter un objet dans une image, chaque pixel est classé individuellement et affecté à la classe que le pixel représente le mieux. En d'autres termes, la segmentation sémantique est une classification au niveau du pixel. La segmentation sémantique classique - réseau de neurones convolutifs (CNN de Convolutional neural network A ) - consiste en un réseau de codage et de décodage.
Le réseau de codage sous-échantillonne les données d'entrée et extrait les fonctions, et le réseau de décodage utilise ces fonctions pour récupérer et sur-échantillonner les données d'entrée et enfin attribue une classe à chaque pixel.
Les deux composants clés des réseaux de décodage sont la couche dite MaxUnpooling et la couche de convolution Transpose. La couche MaxUnpooling (analogue de la couche MaxPooling - opération de pooling avec une fonction maximale) est nécessaire pour réduire la dimension des données traitées.
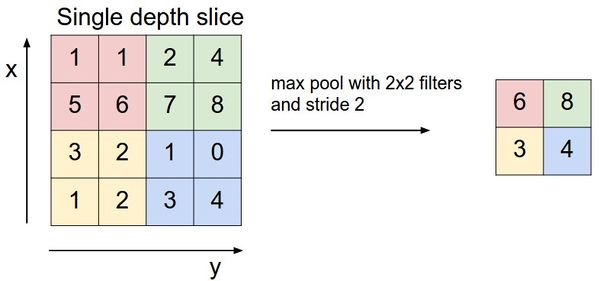
Un exemple de l'opération MaxPooling.
Il existe plusieurs méthodes pour distribuer des valeurs (c'est-à-dire tirer) qui ont pour objectif commun de stocker les emplacements des valeurs maximales dans la couche MaxPooling et d'utiliser ces emplacements pour replacer les valeurs maximales sur les emplacements correspondants dans le couche MaxUnpooling correspondante. Cette approche nécessite que le réseau de codecs soit symétrique, dans lequel chaque niveau MaxPooling dans le codeur a un niveau MaxUnpooling correspondant du côté du décodeur.
Une autre approche consiste à placer les valeurs dans un emplacement prédéterminé (par exemple, dans le coin supérieur gauche) dans la zone vers laquelle pointe le noyau. C'est cette méthode qui a été utilisée dans la modélisation, dont il sera question un peu plus tard.
Une couche convolutive transposée est l'opposé d'une couche convolutive régulière. Il se compose d'un noyau mobile qui scanne l'entrée et convolue les valeurs pour remplir l'image de sortie. Le volume de sortie des deux couches, MaxUnpooling et Transpose, peut être contrôlé en ajustant la taille du noyau, le remplissage et la hauteur.
Le deuxième aspect, qui joue un rôle important dans la résolution du problème des intempéries, est la détection d'un chemin carrossable.
Un chemin piétonnier est un espace dans lequel une voiture peut se déplacer en toute sécurité au sens physique, c'est-à-dire détection de chaussée. Cet aspect est extrêmement important pour diverses situations : stationnement, mauvais marquage au sol, mauvaise visibilité, etc.
Selon les scientifiques, la détection d'un chemin carrossable peut être mise en œuvre comme une étape préliminaire vers la détection d'une voie ou de tout objet. Ce processus découle de la segmentation sémantique, dont le but est de générer une classification pixel par pixel après apprentissage sur un jeu de données mappé en pixels.
Le troisième aspect, mais non moins important, est la fusion de capteurs. Cela signifie littéralement combiner les données de plusieurs capteurs pour obtenir une image plus complète et réduire les erreurs et les inexactitudes probables dans les données des capteurs individuels. Il existe une mise en commun homogène et hétérogène de capteurs. Un exemple du premier serait l'utilisation de plusieurs satellites pour affiner une position GPS. Un exemple de la seconde consiste à combiner les données de la caméra, le LiDAR et le radar pour les voitures autonomes.
Chacun des capteurs ci-dessus montre individuellement d'excellents résultats, mais uniquement dans des conditions météorologiques normales. Dans des conditions de travail plus dures, leurs lacunes deviennent apparentes.
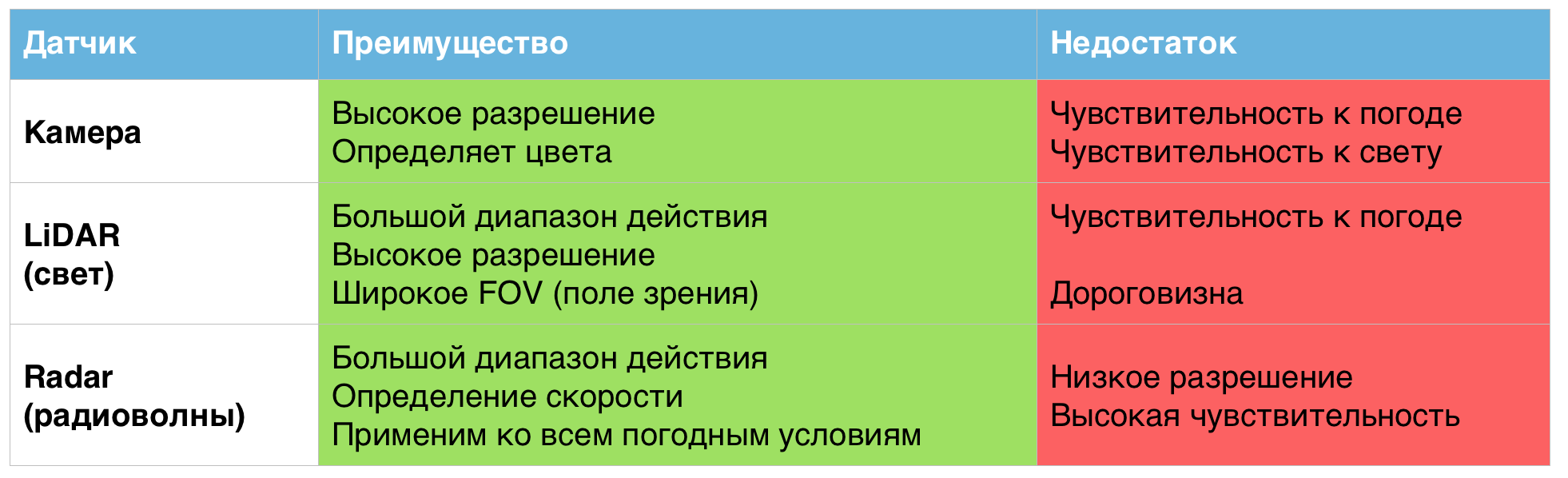
Un tableau des avantages et des inconvénients des capteurs utilisés dans les véhicules sans pilote.
C'est pourquoi, selon les scientifiques, combiner ces capteurs en un seul système peut aider à résoudre les problèmes liés aux mauvaises conditions météorologiques.
Collecte de données
Dans cette étude, comme mentionné précédemment, les réseaux de neurones convolutifs et la fusion de capteurs ont été utilisés pour résoudre le problème de trouver un chemin pour conduire dans des conditions météorologiques défavorables. Le modèle proposé est un réseau de neurones à convolution profonde multithread (un thread par capteur) qui sous-échantillonnera les cartes de fonction (le résultat de l'application d'un filtre à la couche précédente) de chaque flux, combinera les données, puis ré-échantillonnera le cartes pour effectuer une classification pixel par pixel.
Pour effectuer d'autres travaux, y compris les calculs, la modélisation et les tests, beaucoup de données étaient nécessaires. Plus il y en a, mieux c'est, disent les scientifiques eux-mêmes, et c'est assez logique quand il s'agit du fonctionnement de divers capteurs (caméras, LiDAR et Radar). Parmi les nombreux jeux de données déjà existants, DENSE a été choisi, qui couvre la plupart des nuances nécessaires à la recherche.
DENSEest également un projet visant à résoudre les problèmes de trouver un chemin dans des conditions météorologiques extrêmes. Les scientifiques travaillant sur DENSE ont parcouru environ 10 000 km à travers l'Europe du Nord, enregistrant les données de plusieurs caméras, plusieurs LiDAR, radars, GPS, IMU, capteurs de frottement routier et caméras thermiques. L'ensemble de données se compose de 12 000 échantillons, qui peuvent être divisés en sous-groupes plus petits décrivant des conditions spécifiques : jour + neige, nuit + brouillard, jour + clair, etc.
Cependant, pour que le modèle fonctionne correctement, il a fallu corriger les données de DENSE. Les images originales de la caméra dans l'ensemble de données sont de 1920 x 1024 pixels et ont été réduites à 480 x 256 pour une formation et des tests de modèle plus rapides.
Les données LiDAR sont stockées dans un format de tableau NumPy qui devait être converti en images, mis à l'échelle (jusqu'à 480 x 256) et normalisés.
Les données radar sont stockées dans des fichiers JSON, un fichier pour chaque image. Chaque fichier contient un dictionnaire des objets détectés et plusieurs valeurs pour chaque objet, notamment les coordonnées x, les coordonnées y, la distance, la vitesse, etc. Ce système de coordonnées est parallèle au plan du véhicule. Pour le convertir en un plan vertical, seule la coordonnée y doit être prise en compte.
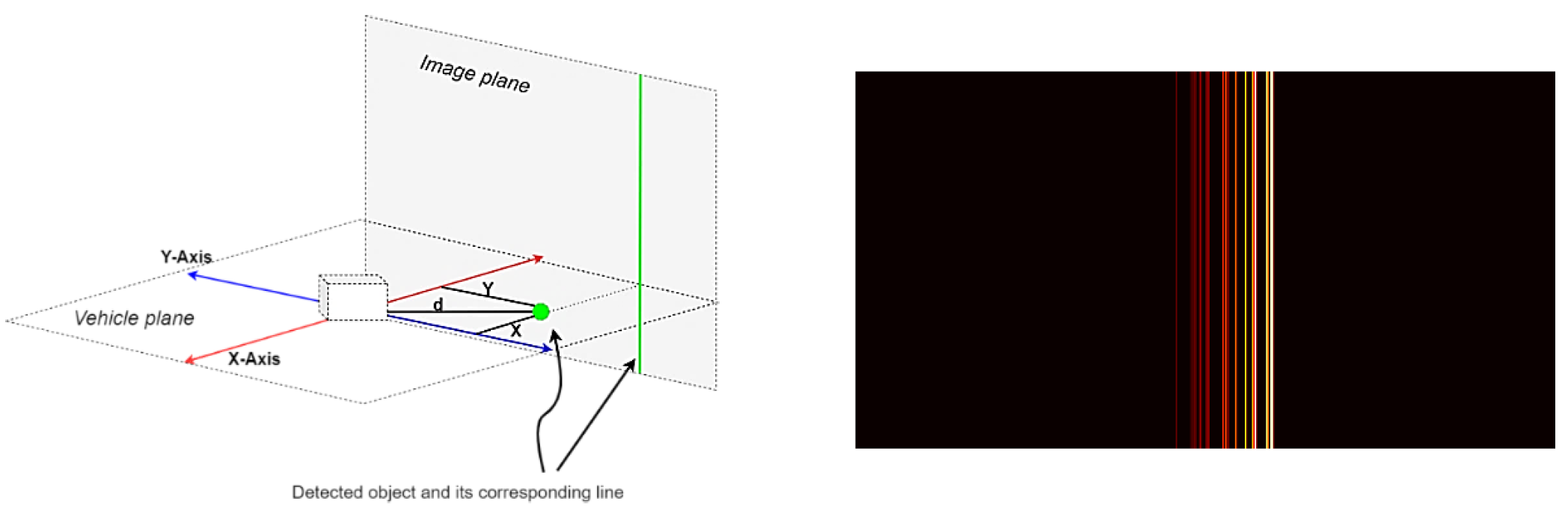
Image n°1 : projection de la coordonnée y sur le plan image (à gauche) et la trame radar traitée (à droite).
Les images résultantes ont été mises à l'échelle (jusqu'à 480 x 256) et normalisées.
Développer un modèle CNN
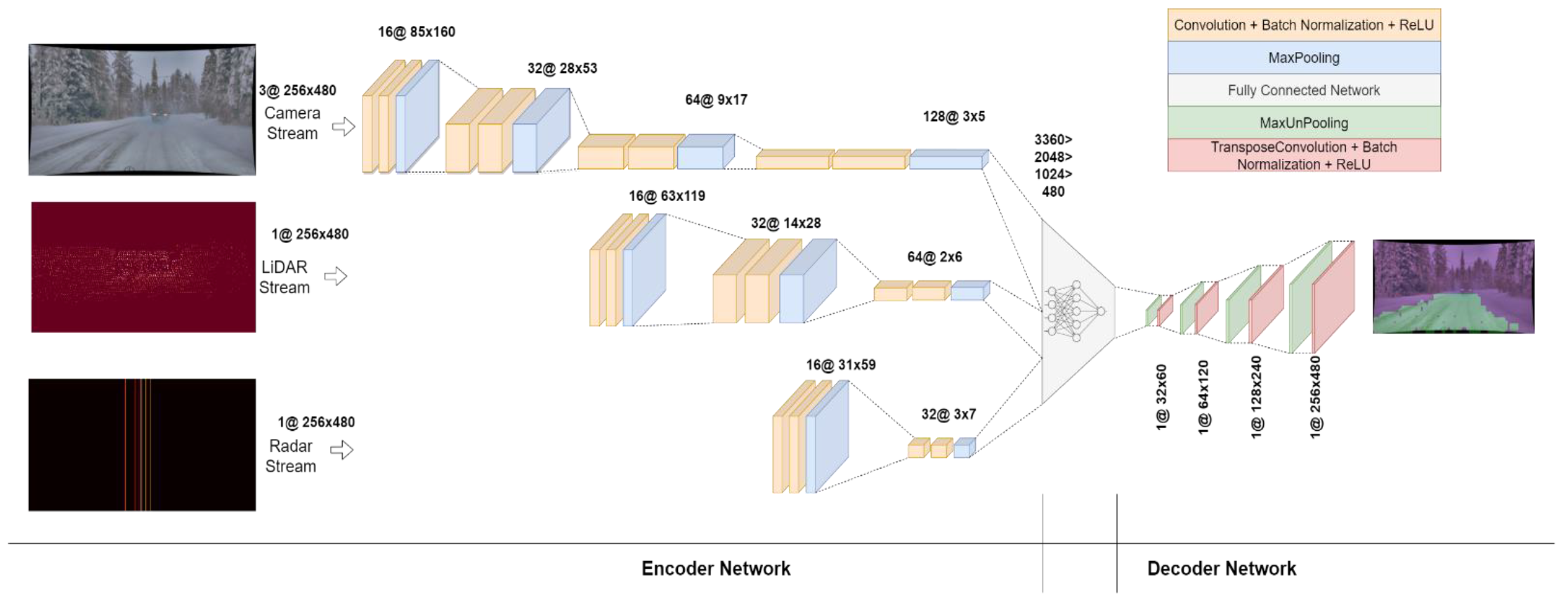
Image #2 : L'architecture du modèle CNN.
Le réseau a été conçu pour être aussi compact que possible, car les réseaux de codecs profonds nécessitent beaucoup de ressources de calcul. Pour cette raison, le réseau de décodage n'a pas été conçu avec autant de couches que le réseau de codage. Le réseau de codage se compose de trois flux : caméra, LiDAR et radar.
Étant donné que les images de la caméra contiennent plus d'informations, le flux de la caméra est rendu plus profond que les deux autres. Il se compose de quatre blocs, chacun composé de deux couches convolutives - une couche de normalisation par lots et une couche ReLU, suivies d'une couche MaxPooling.
Les données LiDAR ne sont pas aussi massives que les données des caméras, leur flux se compose donc de trois blocs. De même, le flux Radar est plus petit que le flux LiDAR, il ne se compose donc que de deux blocs.
La sortie de tous les flux est modifiée et combinée en un vecteur unidimensionnel connecté à un réseau de trois couches cachées avec activation ReLU. Les données sont ensuite converties en un tableau bidimensionnel, qui est transmis à un réseau de décodage composé de quatre étapes consécutives de MaxUnpooling et de convolution transposée pour suréchantillonner les données à une taille d'entrée (480x256).
Résultats de la formation/des tests de modèles CNN
La formation et les tests ont été effectués sur Google Colab à l'aide d'un GPU. Le sous-ensemble de données étiqueté à la main se composait de 1000 échantillons de données de caméras, LiDAR et radar - 800 pour la formation et 200 pour les tests.
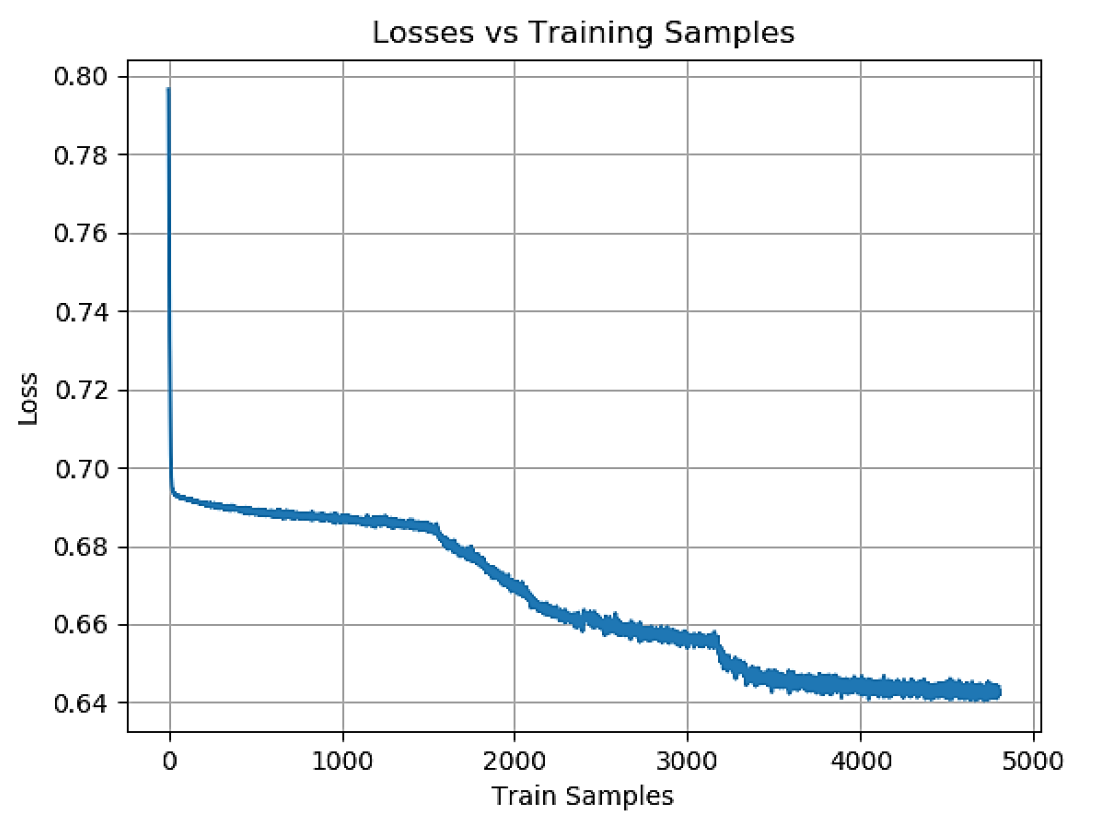
Image n°3 : Perte d'échantillons d'apprentissage pendant la phase d'apprentissage.
La sortie du modèle a été post-traitée avec expansion et érosion d'image avec différentes tailles de noyau pour réduire la quantité de bruit dans la sortie de classification de pixels.
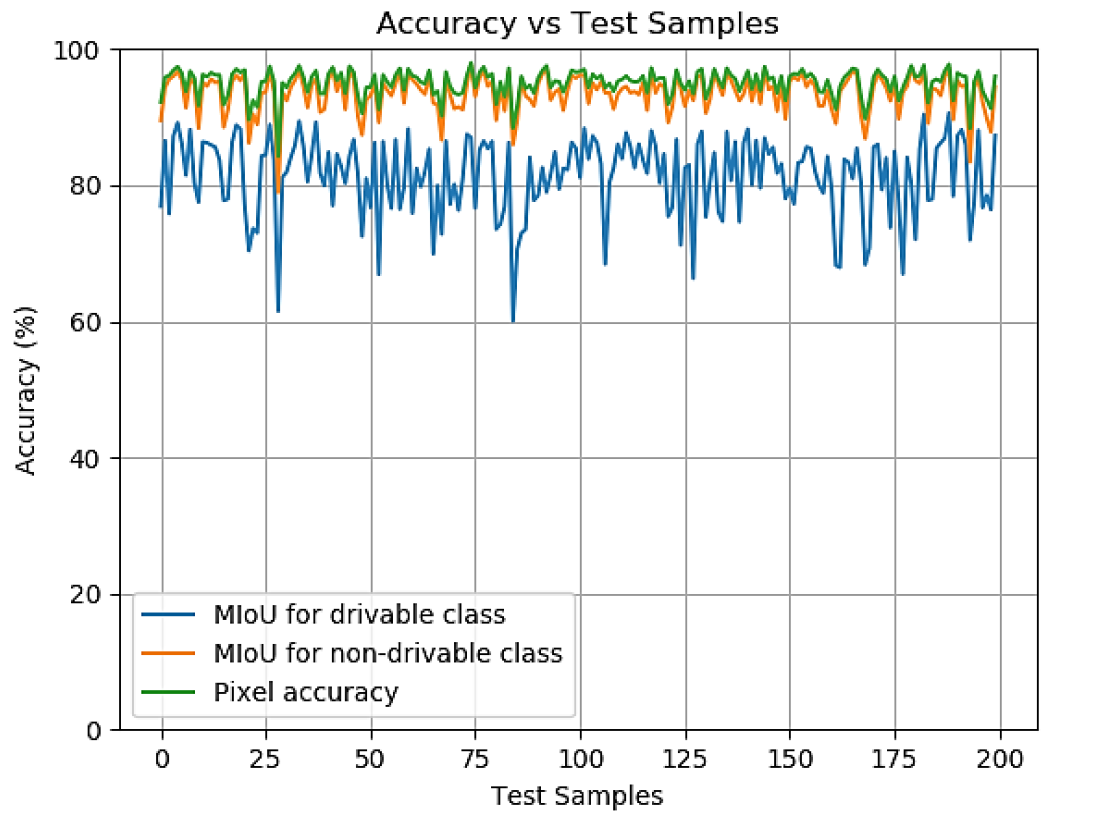
Image # 4: Précision dans les échantillons de test pendant la phase de test.
Les scientifiques notent que l'indicateur le plus simple de la précision du système est le pixel, c'est-à-dire le rapport des pixels correctement définis et des pixels incorrectement définis à la taille de l'image. La précision des pixels a été calculée pour chaque échantillon de l'ensemble de test, et la moyenne de ces valeurs représente la précision globale du modèle.
Cependant, ce chiffre n'est pas idéal. Dans certains cas, une certaine classe est sous-représentée dans l'échantillon, à partir de laquelle la précision des pixels sera nettement plus élevée (qu'elle ne l'est réellement) en raison du fait qu'il n'y a pas assez de pixels pour tester le modèle pour une certaine classe. Par conséquent, il a été décidé d'utiliser en plus MIoU - le rapport moyen de la zone d'intersection à la zone d'union.
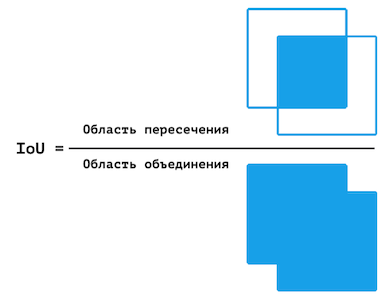
Représentation visuelle de l'IoU.
Semblable à la précision des pixels, la précision IoU est calculée pour chaque image et la précision finale est la moyenne de ces valeurs. Cependant, le MIoU est calculé séparément pour chaque classe.

Tableau des valeurs de précision.

Image # 5
L'image ci-dessus montre quatre images sélectionnées du mouvement de la neige à partir de la caméra, du LiDAR, du radar, des données au sol et de la sortie du modèle. Il est évident à partir de ces images que le modèle peut délimiter la circonférence générale de la zone dans laquelle le véhicule peut se déplacer en toute sécurité. Le modèle ignore les lignes et les bords qui pourraient autrement être interprétés comme les bords de la chaussée. Le modèle fonctionne également bien dans des conditions de faible visibilité (par exemple, le brouillard).
Le modèle évite également les piétons, les autres voitures et les animaux, bien que ce ne soit pas l'objectif principal de cette étude particulière. Cependant, cet aspect particulier doit être amélioré. Cependant, étant donné que le système se compose de moins de couches, il apprend beaucoup plus rapidement que ses prédécesseurs.
Pour une connaissance plus détaillée des nuances de l'étude, je vous recommande de consulter le rapport des scientifiques et des données supplémentaires .
Épilogue
L'attitude envers les voitures autonomes est ambiguë. D'une part, la voiture-robot annule les risques tels que le facteur humain : conducteur ivre, imprudence, attitude irresponsable vis-à-vis du code de la route, peu d'expérience de conduite, etc. En d'autres termes, le robot ne se comporte pas comme un humain. C'est bon, n'est-ce pas ? Oui et non. Les véhicules autonomes surpassent les conducteurs en chair et en os à bien des égards, mais pas du tout. Le mauvais temps en est un parfait exemple. Il n'est bien sûr pas facile pour une personne de conduire pendant une tempête de neige, mais pour les véhicules sans pilote, c'était presque irréaliste.
Dans ce travail, les scientifiques ont attiré l'attention sur ce problème, en proposant de rendre les machines un peu plus humaines. Le fait est qu'une personne dispose également de capteurs qui fonctionnent en équipe pour s'assurer qu'elle reçoit un maximum d'informations sur l'environnement. Si les capteurs d'un véhicule sans pilote fonctionnent également comme un système unique, et non comme des éléments séparés de celui-ci, il sera possible d'obtenir plus de données, c'est-à-dire pour améliorer la précision de la recherche du chemin carrossable.
Bien sûr, le mauvais temps est un terme collectif. Pour certains, de légères chutes de neige sont du mauvais temps, mais pour d'autres, c'est une tempête de grêle. Des recherches et des tests supplémentaires sur le système développé devraient lui apprendre à reconnaître la route dans toutes les conditions météorologiques.
Merci pour votre attention, restez curieux et bonne semaine de travail, les gars. :)
Un peu de pub
Merci de rester avec nous. Vous aimez nos articles ? Vous voulez voir du contenu plus intéressant ? Soutenez-nous en passant une commande ou en recommandant à des amis, Cloud VPS pour développeurs à partir de 4,99 $ , un analogue unique de serveurs d'entrée de gamme que nous avons inventé pour vous : The Whole Truth About VPS (KVM) E5-2697 v3 (6 Cores) 10Go DDR4 480Go SSD 1Gbps à partir de 19$ ou comment bien répartir le serveur ? (options disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Le Dell R730xd 2x moins cher dans le centre de données Maincubes Tier IV à Amsterdam ? Seulement nous avons 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64Go DDR4 4x960Go SSD 1Gbps 100 TV à partir de 199$ aux Pays-Bas !Dell R420 - 2x E5-2430 2.2Ghz 6C 128Go DDR3 2x960Go SSD 1Gbps 100To - A partir de 99$ ! Lisez à propos de Comment construire l'infrastructure de Bldg. classe avec l'utilisation de serveurs Dell R730xd E5-2650 v4 à un coût de 9000 euros pour un sou ?