Vidéo de floraison sous le capot
Je continue de parler de mon passe-temps inhabituel. Mon passe-temps est la transformation algorithmique d'anciennes vidéos en noir et blanc en un matériel d'apparence moderne. Mon premier travail est décrit dans cet article . Le temps a passé, mes compétences se sont améliorées, et maintenant je ne ris plus du mème "Zoom et améliorez" .

Le passe-temps peut sembler étrange, mais il est vrai qu'il est agréable. C'est peut-être la capacité d'être un sorcier qui transforme les cendres du passé en feu avec l'aide de la technomagie, ou peut-être que la raison en est dans de nombreux puzzles intellectuels qui n'ont pas de solution toute faite, peut-être est-ce la compensation d'un manque d'expression créative de soi, peut-être tous ensemble. À chaque nouvelle vidéo, le processus se complique de détails, le nombre d'outils et de scripts tiers impliqués augmente.
Il est nécessaire de préciser que nous ne parlons pas de restauration et de coloration manuelles, qui nécessitent des tonnes d'Indiens et des kilogrammes d'argent, mais de l'utilisation d' algorithmes d'autoréglage (souvent appelés « IA », « réseaux de neurones »).
Autrefois, mes œuvres étaient légèrement meilleures en clarté et en couleur que les œuvres similaires d'autres amateurs, mais maintenant l'arsenal d'outils utilisés s'est tellement étendu que la qualité du résultat final ne dépend que du temps investi.
Petite histoire
De l'extérieur, le processus de décoloration automatique de la vidéo n'est pas perçu comme quelque chose d'abstrait, car il est évident qu'il suffit de télécharger un certain programme et d'y jeter un enregistrement vidéo, et tout le travail complexe a déjà été fait par celui qui a conçu l'algorithme de décoloration des couleurs et dépensé de l'électricité pour s'entraîner.
Permettez - moi de vous dire maintenant comment le Deoldify révolutionnaire couleur algorithme fondu est venu à propos . Même si vous aimez l'apprentissage automatique, ce n'est pas un fait que vous sachiez qui est Jeremy Howard . Sa carrière professionnelle a commencé en tant que consultant embauché, il y a 20 ans, il était engagé dans ce qu'on appelle maintenant la science des données, c'est-à-dire tirer profit des données en utilisant les mathématiques.
La vente de quelques startups lui a permis de réfléchir à une contribution volontairement positive au développement de l'humanité. Après avoir déménagé à Dolina, il a rejoint la foule des meilleurs spécialistes de l'apprentissage automatique et, en 2011, il est devenu le meilleur participant au concours Kaggle.
Un tournant majeur est survenu en 2014, lorsque son projet de détection automatique des anomalies médicales sur les radiographies a montré des résultats dépassant la qualité du travail des médecins expérimentés. En même temps, le projet ne représentait rien de grandiose en termes de ressources intellectuelles et matérielles investies, et la formation finale a été réalisée la veille de la présentation. Un projet de travail typique, qui par son existence symbolisait un point de transition dans le progrès technique.
Jeremy a clairement compris qu'un outil aussi puissant peut être une source de croissance dans n'importe quel domaine. Le problème principal était (et est) que le nombre de spécialistes des systèmes d'auto-apprentissage est incomparable avec le nombre de projets dans lesquels leurs capacités pourraient être utilisées. De son point de vue, il serait bien plus efficace de donner cet outil à tout le monde. C'est ainsi qu'est né le projet Fast.Ai , qui est la symbiose d'un code et d'une formation. Le code d'une part rend Pytorch beaucoup plus facile à utiliser (un outil pour construire des algorithmes d'apprentissage automatique), et d'autre part, il contient de nombreuses techniques toutes faites que les professionnels utilisent pour augmenter la vitesse et la qualité de l'apprentissage. Le programme est structuré de haut en bas, les étudiants apprennent d'abord à utiliser des pipelines standard, puis Jeremy montre comment chaque élément du pipeline peut être écrit à partir de zéro, en commençant par une démonstration en direct sur une feuille Excel de l'algorithme clé derrière tout le Deep Learning. L'objectif du projet Fast.Ai est d'apprendre à un spécialiste de n'importe quel domaine à résoudre des problèmes typiques sur des architectures typiques (bien sûr, si vous avez des compétences en programmation). Les miracles ne se produisent pas, le niveau de compétences après une telle formation ne dépasse pas le niveau de "round kati - square vert", mais même cela suffit pour résoudre les problèmes de travail à un nouveau niveau, inaccessible aux collègues.
Dans le tutoriel Fast.Ai, une des rubriques est consacrée à l'utilisation de l'architecture UNet , qui se concentre sur la réinterprétation des images. Par exemple, cette architecture peut être entraînée pour générer des photographies réalistes à partir d'images capturées avec une caméra thermique, ou pour contraster des anomalies dans les images. D'une manière générale, une telle architecture, par sa forme et ses propriétés connues, permet de prédire la présence de propriétés dans la forme dont l'identification était le but de l'apprentissage.
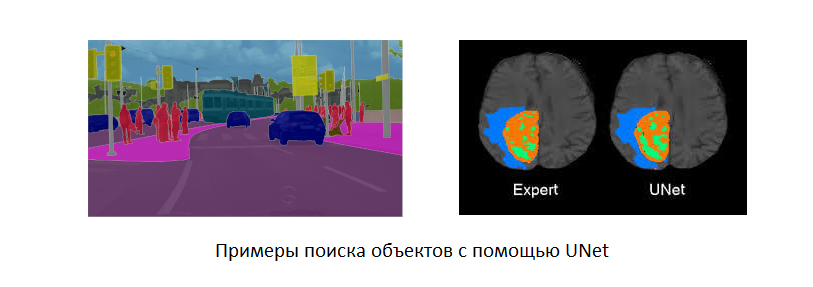
Comme devoir, les étudiants du cours ont été encouragés à utiliser UNet pour résoudre tout problème intéressant. Un certain Jason Antic s'est intéressé à la conversion de photographies en noir et blanc en couleur. Ses expériences ont montré qu'une telle architecture produit des résultats adéquats et qu'il existe un potentiel important de développement ultérieur. C'est ainsi qu'est né le projet Deoldify qui, avec l'aide de Jeremy Howard lui-même, est devenu un produit fini et a finalement fait exploser Internet. L'auteur a rendu la première version accessible à tous et il a lui-même commencé à développer une version commerciale fermée, qui, sous une forme limitée, peut être utilisée sur le projet généalogique MyHeritage.com (inscription obligatoire, plusieurs photos sont gratuites).

▍ « »
Le principal problème avec les projets d'apprentissage automatique open source de pointe est que la convivialité est généralement à gauche de zéro. L'auteur du projet se concentre sur le pipeline d'apprentissage, il a besoin des résultats de l'algorithme uniquement pour la présentation à la communauté, ce qui est normal, car le but de tels projets est l'auto-promotion et la contribution à la recherche. L'auto-achèvement des projets par l'utilisateur est la norme. Afin de ne pas aller loin : avant de traiter la vidéo, elle doit être décodée, traitée chaque image et la compression résultante dans un fichier vidéo, si une vidéo est traitée avec plusieurs outils, alors après compression successive, vous pouvez oublier la qualité. Chaque nouvel outil doit être refait pour fonctionner avec une pile d'images.Mais que se passe-t-il si dans l'outil au niveau du pipeline, l'utilisation de pas plus de 8 images par exécution est intégrée ? L'algorithme est suffisant pour la démonstration, mais pas à des fins pratiques. Vous devrez écrire un wrapper externe pour l'exécuter plusieurs fois, car il est peu probable que vous puissiez modifier le pipeline de quelqu'un d'autre sans perdre la compatibilité avec l'état pré-entraîné de l'algorithme. Et, bien sûr, les auteurs universitaires ne se soucient pas vraiment de l'optimisation. Il y a un projet qui a refusé de travailler avec des images plus grandes qu'une boîte d'allumettes, après optimisation, il a commencé à nécessiter 5 fois moins de mémoire vidéo et maintenant il peut gérer le FullHd.qu'il sera possible de changer le pipeline de quelqu'un d'autre sans perdre la compatibilité avec l'état pré-entraîné de l'algorithme. Et, bien sûr, les auteurs universitaires ne se soucient pas vraiment de l'optimisation. Il y a un projet qui a refusé de travailler avec des images plus grandes qu'une boîte d'allumettes, après optimisation, il a commencé à nécessiter 5 fois moins de mémoire vidéo et maintenant il peut gérer le FullHd.qu'il sera possible de changer le pipeline de quelqu'un d'autre sans perdre la compatibilité avec l'état pré-entraîné de l'algorithme. Et, bien sûr, les auteurs universitaires ne se soucient pas vraiment de l'optimisation. Il y a un projet qui a refusé de travailler avec des images plus grandes qu'une boîte d'allumettes, après optimisation, il a commencé à nécessiter 5 fois moins de mémoire vidéo et maintenant il peut gérer le FullHd.
Vous pouvez lister les jambages rencontrés depuis longtemps, il suffit de s'attarder sur le fait que l'installation de librairies instrumentales est nécessaire pour que tout algorithme fonctionne, parfois cela peut prendre 2-3 jours d'expérimentations avant que les librairies s'arrêtent en conflit les unes avec les autres (même s'il existe une liste de versions exactes, il y a de nombreuses raisons pour lesquelles il faudra chercher longtemps sur Google).
Une minute de beauté
Choisir un matériau pour la colorisation n'est pas si facile. D'une part, le contenu devrait m'intéresser, d'autre part, le long film publicitaire de la société Diesel, saturé de détails techniques, a peu de chance d'intéresser un large public, d'autre part, il y a des restrictions dans le choix en raison du droit d'auteur. Les nouvelles options proviennent de la mémoire ou de la recherche d'enregistrements spécifiques. Mes dernières œuvres sont dédiées à la ballerine russe Anna Pavlova. On a assez écrit et dit sur elle, de nombreuses photographies ont survécu, mais comme son activité professionnelle est associée au mouvement dans le temps et dans l'espace, le témoin le plus intéressant est le film. Malheureusement, certains des documents survivants sont inconnus du grand public, et ce qui est maintenant recherché est d'une qualité absolument dégoûtante. Ce qui est intéressant dans la figure d'Anna Pavlova,c'est donc littéralement un chiffre. Elle peut être considérée comme le prototype du standard de la ballerine moderne, ce ne sera peut-être pas une découverte pour vous qu'à la fin du 19ème siècle, la minceur était encore collectivement perçue comme un signe de maladie ou de pauvreté, bien sûr, chez les gens riches, il y avait des chiffres différents, mais en général, l'embonpoint était perçu comme un marqueur d'une vie réussie. Des femmes pleines de santé se produisaient souvent sur la scène du théâtre, voici des photos de trois stars de cette époque.Des femmes pleines de santé se produisaient souvent sur la scène du théâtre, voici des photos de trois stars de cette époque.Des femmes pleines de santé se produisaient souvent sur la scène du théâtre, voici des photos de trois stars de cette époque.

Dans une de mes œuvres, vous pouvez même voir à quoi cela ressemblait. Les spectateurs qui n'ont pas une bonne compréhension de l'histoire ne prennent guère une telle image au sérieux, même si les habitants les plus avancés de notre planète y trouveront sûrement un point positif.
Revenons à Anna Pavlova : il existe plusieurs films mettant en scène une ballerine en danse. Ils existent en bonne qualité, mais ils ne sont pas accessibles au public. Mais au cours de la recherche, à ma grande surprise, j'ai trouvé tout un long métrage dans lequel notre ballerine jouait le rôle principal. Au début du film, un numéro avec une danse qui n'a rien à voir avec l'intrigue est inséré, il est donc tout à fait approprié de le considérer comme une vidéo distincte, sur laquelle j'ai travaillé.
Problèmes au début
Décodez la vidéo originale en une série de fichiers PNG. Nous regardons les images résultantes et remarquons qu'il y a des images qui répètent les précédentes.
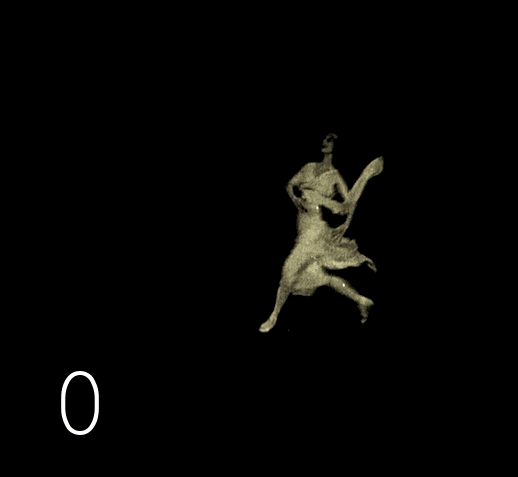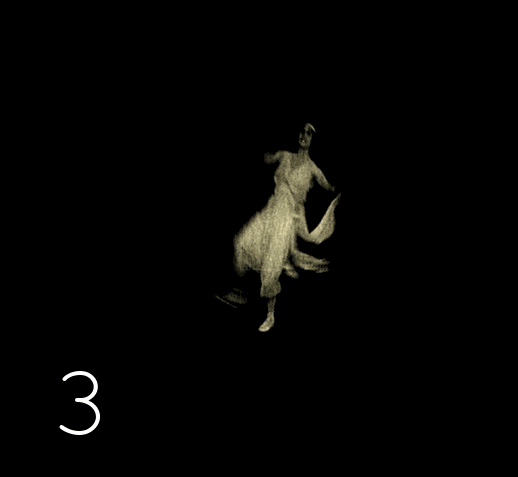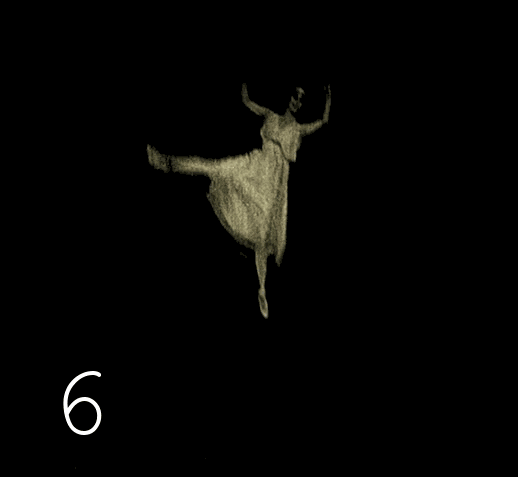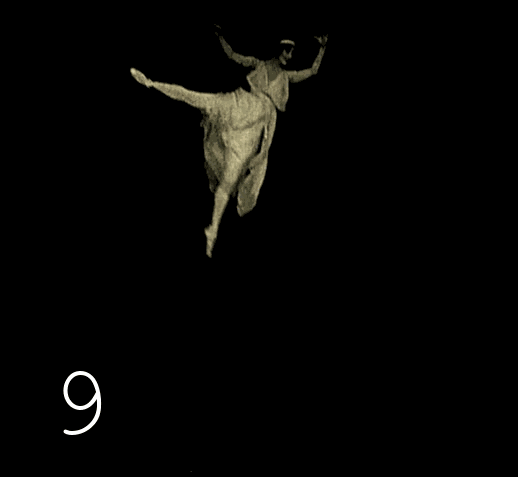
Il s'agit d'une histoire standard, car à l'aube de la cinématographie, une vitesse de prise de vue de 12 à 19 images par seconde (ci-après appelée fps) était utilisée pour enregistrer le film. À la fin de l'ère analogique, lorsque 99 % des images étaient à 24-25 ips, les anciennes bandes étaient copiées image par image, ce qui accélère la lecture. Par conséquent, dans l'esprit de la majorité, la vieille chronique est fermement associée à des petits hommes indistinctes et pressés. La vérité est que les films originaux en noir et blanc se conservent très bien, même mieux que les films en couleur, et ont une résolution entre DVD et FullHD. Tout ce que vous pouviez voir dans la plupart des cas, c'était des copies de mauvaise qualité, re-tirées de la projection à l'écran. Bien que de nombreux films n'aient survécu que sur de telles copies (les pertes sont dues au facteur humain), le nombre d'originaux qui ont survécu est encore important.Seuls quelques privilégiés ont accès aux originaux, heureusement, de nos jours, le traitement informatique des images permet une réplication illimitée de copies numérisées de haute qualité d'originaux, de nettoyer les défauts et de reproduire le matériel à une fréquence d'images normale.
Il y a deux problèmes distincts avec des fréquences d'images faibles. Premièrement, ce n'est pas standard, si une vitesse de lecture peut être utilisée sur un ordinateur personnel, il existe de nombreux cas où il est nécessaire de respecter la plage de 24 à 30 ips. Le moyen le plus simple de corriger la fréquence d'images est de répéter la dernière toutes les 3-4 images. Dans le même temps, la vitesse de déplacement des objets devient naturelle, mais l'image est perçue comme tremblante, c'est en fait le deuxième problème. En 2021, les technologies vous permettront de faire une image fluide en interpolant des trames. La technologie d'interpolation d'images dans les téléviseurs et les lecteurs vidéo logiciels a commencé à être trouvée vers 2005. En raison d'algorithmes mathématiques, deux images adjacentes sont mélangées de sorte que pendant la lecture, il y a une sensation de mouvement fluide dans l'image. Cela fonctionne bien pour 24 fps,car la différence entre les trames est rarement significative. Mais pour 12-19 fps, de tels algorithmes ne conviennent pas : ils dessinent une double image floue ou des artefacts fous. Ce problème est résolu avec plus de succès par des algorithmes d'auto-apprentissage capables de se rappeler exactement comment dessiner une image intermédiaire pour différents mouvements de différents types d'objets.
Dans les rééditions modernes de films de l'ère du cinéma muet, l'utilisation de l'interpolation n'est pas encore utilisée, respectivement, il y a des images répétées dans notre vidéo, et si elles ne sont pas supprimées, alors en ce qui concerne l'interpolation d'images, cela tournera être un non-sens, ce qui signifie qu'il est nécessaire de supprimer les inutiles.
Torsion inattendue
Retirez-le avec des stylos - vous serez torturé, nagé, nous le savons. Nous exécutons le script pour détecter les images identiques, le script tombe avec l'erreur "Plusieurs correspondances d'affilée". Et bien, bien sûr : les images sont trop sombres, la recherche rassemble les mêmes images et des images différentes en un seul tas. Exécutez le script de normalisation de la plage dynamique, qui crée automatiquement des bordures contrastées, le noir conduit au noir, le blanc au blanc, puis renvoie à l'endroit les nuances de gris perdues lors de telles manipulations.

Nous recommençons la recherche de doublons, le processus est maintenant plus sûr, mais après avoir supprimé les images inutiles, quelque chose de nouveau est trouvé. Avec une certaine périodicité, il y a une répétition des trames dans l'ordre inverse. Nous lançons la vidéo originale et regardons attentivement, wow, ils ont vraiment utilisé une astuce qui utilise l'inertie de la vision, et l'image est perçue moins nerveuse qu'avec des images en double ordinaires.
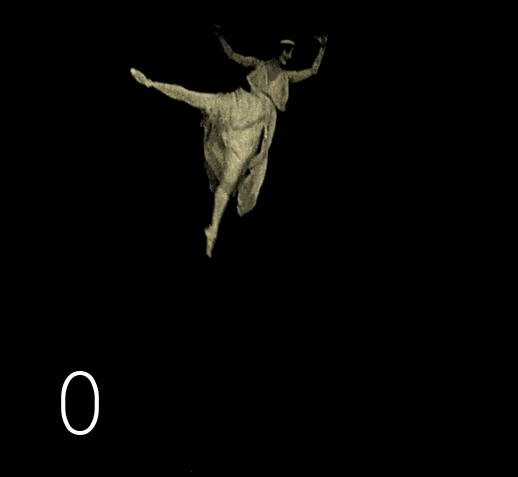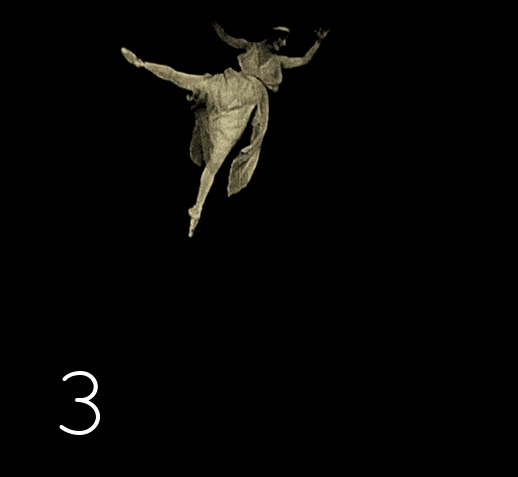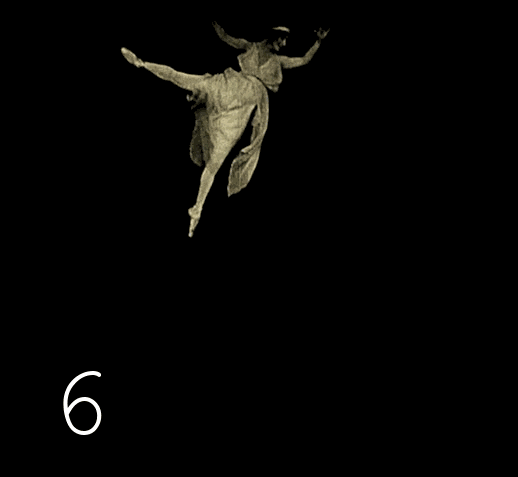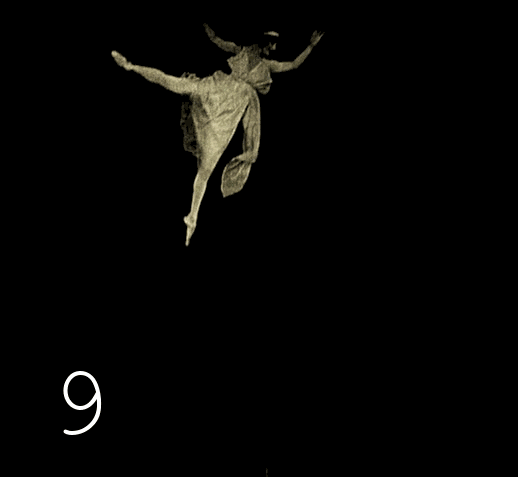

Nous changeons le script de la recherche de trames identiques dans une rangée à la recherche de trames identiques via une trame intermédiaire . Nous vérifions les résultats - encore une surprise : il y a une répétition dans deux trames. Après avoir vérifié la troisième version du script, les surprises se terminent.
Le problème de la suppression des images supplémentaires est soudainement devenu très sérieux. Sur une telle sombre et non saturée de détails, vous ne pouvez pas faire confiance à la recherche automatique de doublons, elle fera des erreurs à plusieurs reprises, en sautant le inutile et en supprimant le nécessaire. Nous effectuons la recherche de tous types de prises sur un autre épisode du film, dans lequel le nombre d'erreurs sera minime. Dans le cas d'une simple répétition, en mettant en évidence les prises dans le gestionnaire de fichiers, vous pouvez comprendre le schéma de répétition et supprimer les fichiers inutiles par programmation.
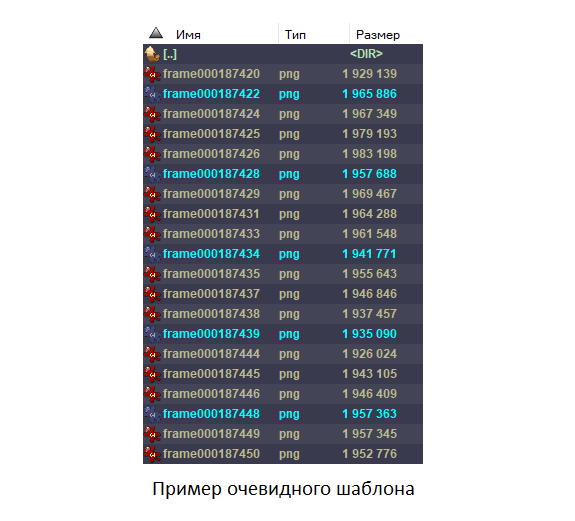
Dans ce cas, le motif semblait aléatoirement périodique, de petits morceaux sont répétés, mais en général, l'essence n'est pas claire. Alors qu'est-ce que c'est maintenant ? Soit abandonner toute l'idée, soit inverser l'algorithme de répétition.
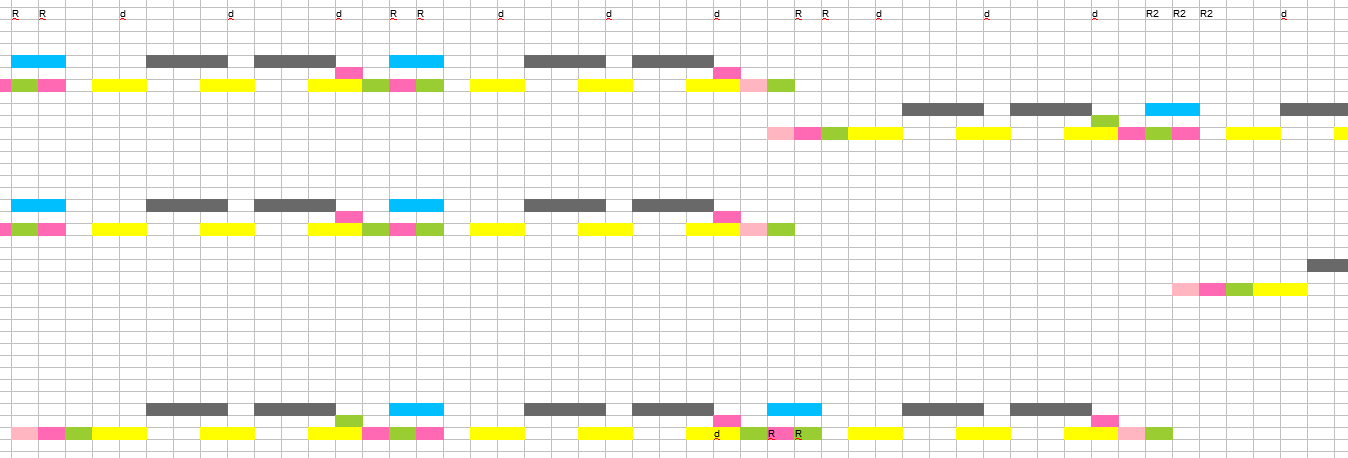
En changeant le script de recherche de doublons, des étiquettes seront désormais ajoutées aux noms de fichiers en fonction du type de duplication. Nous transférons toute la liste des fichiers vers Excel et ne laissons que les étiquettes, transformons la colonne en une ligne et sortons du nombre autorisé de colonnes. Nous devons maintenant la diviser en deux feuilles. Nous mettons en évidence des cadres dupliqués du même type dans une couleur, ce qui nous permettra d'utiliser l'analyseur de modèle biologique.

Les courtes répétitions sont regroupées. Nous vérifions avec quelle précision un long groupe est répété. Les groupes sont similaires, mais il y a de légères différences. C'est un fiasco. Il y a plusieurs raisons possibles à cette image : des changements aléatoires ont été faits volontairement, ou plusieurs algorithmes pour compléter les trames ont été utilisés, ou le contenu des trames est pris en compte, ou la méthode utilise une fonction non intuitive. Écrire une séquence de répétitions beaucoup plus longue pour le calcul semblait exagéré.

Vous devrez supprimer le bruit avec vos mains à l'aide d'un échantillon. Nous exécutons le script de recherche en double sur l'épisode qui nous intéresse et chargeons la séquence de cadres dans Excel, peignons et insérons un modèle d'une longue séquence à côté. Nous posons le marquage là où il semble sans ambiguïté, nous supprimons le marquage incorrect. Ensuite, nous devinons où devraient être les cadres, et maintenant la majeure partie de l'image est restaurée. Il reste quelques endroits peu clairs. Nous mettons des notes exactement selon le modèle ou par intuition. Bien sûr, quelque part, il y aura des erreurs, mais quelque part nous nous retrouverons que dans le contexte général de la séquence correcte, ce n'est plus critique, d'autant plus que dans l'ancienne chronique, certaines images sont presque toujours perdues, et dans ce cas, cela ne fait aucun sens de presser l'idéal absolu.
En utilisant la liste finale, nous supprimons l'inutile, vérifions-le et le tour est joué, le problème semble résolu par 9 sur 10.
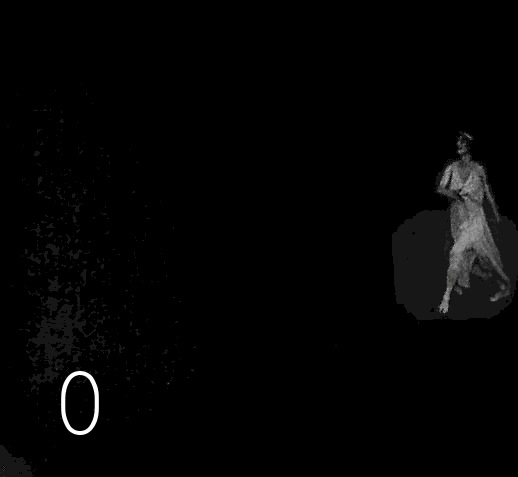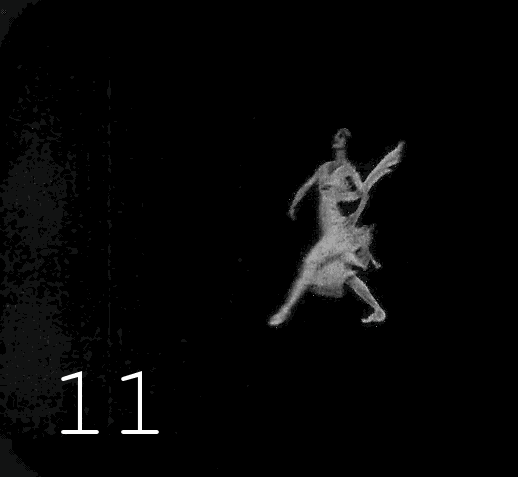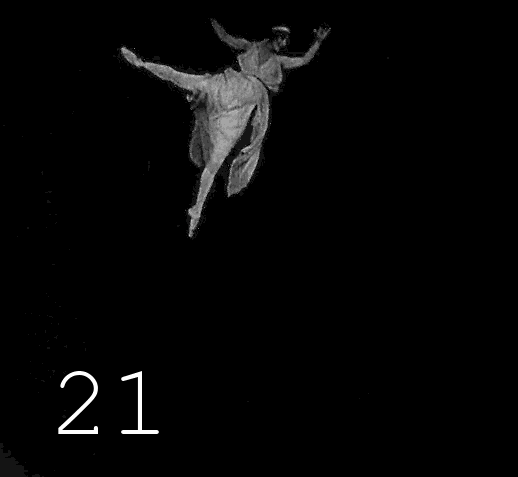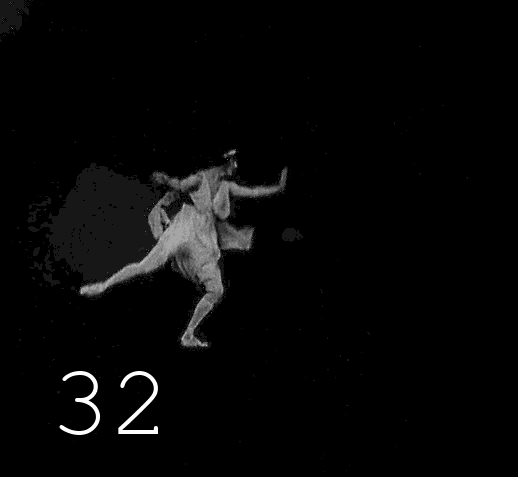
▍
Ceci est suivi de 17 opérations de magie noire, au cours desquelles 17 dossiers sont formés sur le disque contenant des images vidéo après chaque manipulation. En plus de la décoloration elle-même, une correction automatique des cadres décolorés sans succès est effectuée, une augmentation significative de la clarté de l'image, l'image restaurée revient à "l'analogie" (pour se débarrasser de la sensation de Photoshop), pour tout cela, 5 différents outils d'amélioration d'image sont utilisés, interconnectés par des scripts, qui sont versés dans les deux sens des canaux de luminance et de couleur. Les noms des outils resteront mon secret professionnel, désolé, trop de travail et de temps passé à collectionner ce zoo et à le modifier. Quand j'ai vu les résultats de Deoldify 2, il est devenu clair pour moi que mon désir d'être le meilleur dans ce domaine n'a pas de sens,peu importe à quel point je presse les pourcentages de qualité, chaque nouvel algorithme similaire dépasse parfois l'ancien. J'ai abandonné la décoloration et j'ai plongé dans l'apprentissage automatique dans le but de créer mon Deoldify, mais une série d'événements se sont produits qui m'ont détourné de cet objectif. En conséquence, j'ai combiné plusieurs projets prêts à l'emploi dans un processus commun, dont les résultats remplacent en quelque sorte mon algorithme de colorisation échoué. Peut-être que dans le prochain article je vous dirai comment utiliser le coloriseur de Google, si vous pouvez freiner son appétit pour la mémoire, il y aura un code et des détails.En conséquence, j'ai combiné plusieurs projets prêts à l'emploi dans un processus commun, dont les résultats remplacent en quelque sorte mon algorithme de colorisation qui a échoué. Peut-être que dans le prochain article je vous dirai comment utiliser le coloriseur de Google, si vous pouvez freiner son appétit pour la mémoire, il y aura un code et des détails.En conséquence, j'ai combiné plusieurs projets prêts à l'emploi dans un processus commun, dont les résultats remplacent en quelque sorte mon algorithme de colorisation qui a échoué. Peut-être que dans le prochain article je vous dirai comment utiliser le coloriseur de Google, si vous pouvez freiner son appétit pour la mémoire, il y aura un code et des détails.
Pour terminer le travail sur la vidéo, vous devez essayer de retirer les jambages, pour cela le récolteur vidéo professionnel Davinci Resolve est le mieux adapté . Si vous ouvrez l'image suivante séparément, vous pouvez voir le nombre d'éléments dans la chaîne de retouche. Cette conception rend l'arrière-plan noir, rapproche les couleurs du naturel, lutte contre les couleurs inutiles, crée une imitation du faisceau du projecteur (masque les traces mineures d'utilisation de la correction).
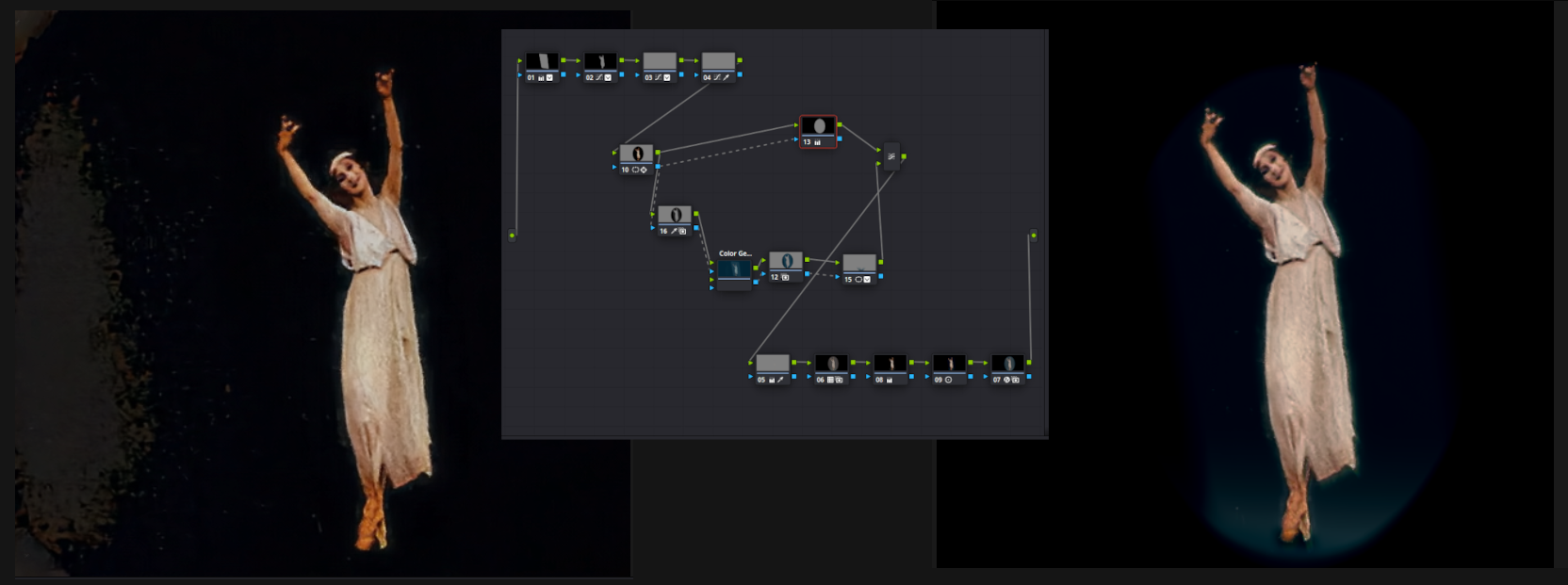
Il reste à faire l'interpolation d'images, la mise à l'échelle cosmétique à 2K, et maintenant notre vidéo est prête. L'image originale est trop sombre et il n'y a pas lieu de s'attendre à des miracles, mais il est maintenant possible de considérer les mouvements fluides de la silhouette claire du danseur.
Le film lui-même contient de nombreuses scènes avec une image relativement bonne, ce qui permet d'évaluer à quel point le traitement algorithmique peut améliorer l'image. Les images de résolution 2K sont trop grandes pour l'article, par conséquent, les images finales réduites en 2 fois sont insérées à côté de l'image complète de l'image originale.





Résultats
L'intrigue de la danse contient 1251 images (avant interpolation), le travail a duré 5 jours .
Musique ajoutée à partir de la bibliothèque musicale gratuite de Youtube.
Le film contient 19660 images (avant interpolation), 14 jours ont été traités (uniquement des algorithmes, la retouche manuelle n'a pas été appliquée). Avec la musique c'était plus difficile ici, au début il y avait une version assemblée à partir de morceaux de l'opéra, qui forme la base du scénario du film, mais à cause du droit d'auteur il n'était pas possible de publier cette version, j'ai dû utiliser des compositions adaptées de la première bibliothèque trouvée, ils disent que cela s'est avéré mieux que la première fois.
Caractéristiques de l'ordinateur : Amd Ryzen 3 1200, 4 Go de RAM, GTX 1060 3 Go
▍- Liens vers mes travaux :
Youtube Not.
Rutube Not.
Ps je n'ai pas pu résister, j'ai colorié.

