Une base de données en mémoire n'est pas un nouveau concept. Mais il est trop étroitement associé aux mots « cache » et « non persistant ». Aujourd'hui, je vais expliquer pourquoi ce n'est pas nécessairement le cas. Les solutions en mémoire ont un champ d'application beaucoup plus large et un niveau de fiabilité beaucoup plus élevé qu'il n'y paraît.
Dans cet article, je discute des principes architecturaux des solutions en mémoire. Comment pouvez-vous tirer le meilleur parti du monde de la mémoire - des performances incroyables - et ne pas sacrifier les vertus des systèmes relationnels basés sur disque. Tout d'abord, la fiabilité - comment pouvez-vous être sûr que vos données sont en sécurité.
Cette histoire condense 10 ans d'expérience avec des solutions en mémoire en un seul texte. Le seuil d'entrée est le plus bas possible. Vous n'avez pas besoin d'avoir autant d'années d'expérience pour profiter de la lecture, une compréhension de base de l'informatique suffit.
- introduction
- Histoire du développement
- Tarantool aujourd'hui
- Comment fonctionne le noyau
- Lua
- Fibre et multitâche coopératif
- Fonctionnalité de la base de données
- Comparaison avec d'autres systèmes
- Scénarios d'utilisation
- Conclusion et conclusions
- Liens
introduction
Je m'appelle Vladimir Perepelitsa, mais je suis mieux connu sous le nom de Mons Anderson. Je suis architecte et chef de produit pour Tarantool. Je l'utilise depuis de nombreuses années en production, par exemple lors de la construction d'un stockage d'objets compatible S3 [1]. Par conséquent, je le connais assez bien à l'intérieur et à l'extérieur.
Pour comprendre la technologie, il est utile de se plonger dans l'histoire. Nous allons découvrir à quoi ressemblait Tarantool, ce qu'il a vécu, ce qu'il est aujourd'hui, le comparer avec d'autres solutions, considérer sa fonctionnalité, comment il peut fonctionner sur le réseau, ce qu'il y a dans l'écosystème autour.
Cet exemple nous permettra de comprendre quels avantages vous pouvez obtenir des solutions en mémoire. Vous apprendrez comment éviter de sacrifier la fiabilité, l'évolutivité et la convivialité.
PS : il s'agit d'une transcription d'une leçon ouverte, adaptée pour l'article. Si vous préférez écouter YouTube en 2x, un lien vers la vidéo vous attend à la fin de l'article [2].
Histoire du développement
Tarantool a été créé par l'équipe de développement interne du groupe Mail.ru en 2008, initialement sans aucune possibilité d'open source. Cependant, après deux ans de fonctionnement au sein de l'entreprise, nous nous sommes rendu compte que le produit était suffisamment mature pour le partager avec le public. C'est ainsi que l'histoire open source de Tarantool a commencé.
commit 9b8dd7032d05e53ffcbde78d68ed3bd47f1d8081 Author: Yuriy Vostrikov <vostrikov@corp.mail.ru> Date: Thu Aug 12 11:39:14 2010 +0400
Mais pourquoi a-t-il été créé ?
Tarantool a été initialement développé pour le réseau social My World. À cette époque, nous étions déjà une assez grande entreprise. Un cluster MySQL qui stocke des profils, des sessions et des utilisateurs coûte cher. A tel point qu'en plus de la productivité, nous avons pensé à l'argent. De là est née l'histoire "Comment économiser un million de dollars sur la base de données" [3].
C'est-à-dire que Tarantool a été conçu pour économiser de l'argent sur d'énormes clusters MySQL. Il a connu une évolution progressive : ce n'était qu'un cache, puis un cache persistant , puis une base de données à part entière .
Ayant acquis une réputation interne dans un projet, il a commencé à se propager à d'autres : courrier, bannières publicitaires, cloud. Du fait d'une utilisation généralisée au sein de l'entreprise, de nouveaux projets sont souvent lancés par défaut sur Tarantool.
Si vous suivez l'historique du développement de Tarantool, vous pouvez voir l'image suivante. Tarantool était à l'origine un cache en mémoire. À sa création, il n'était presque pas différent de memcached.
Pour résoudre les problèmes de cache froid, Tarantool est devenu persistant. Une réplication supplémentaire y a été ajoutée. Lorsque nous avons un cache persistant avec réplication, il s'agit déjà d'une base de données clé-valeur. Des index ont été ajoutés à cette base de données clé-valeur, c'est-à-dire que nous avons pu utiliser Tarantool presque comme une base de données relationnelle.
Et puis nous avons ajouté des fonctions Lua. Initialement, il s'agissait de procédures stockées pour travailler avec des données. Les fonctions Lua ont ensuite évolué vers un environnement d'exécution coopératif et un serveur d'applications.
Peu à peu, tout cela a été envahi par diverses fonctionnalités, capacités et autres moteurs de stockage supplémentaires. Aujourd'hui, c'est déjà une base de données multi-paradigmes. Plus à ce sujet.
Tarantool aujourd'hui
Aujourd'hui, Tarantool est une plate-forme informatique flexible de schéma de données en mémoire.
Tarantool peut et doit être utilisé pour créer des applications à forte charge . C'est-à-dire de mettre en œuvre des solutions complexes de stockage et de traitement des données, et pas seulement de créer des caches. De plus, ce n'est pas seulement une base de données, mais une plate-forme sur laquelle vous pouvez créer quelque chose.
Tarantool est disponible en deux versions. Disponible pour la plupart, la plus compréhensible et la plus connue est la version open source. Tarantool est développé sous une licence BSD simplifiée, hébergée entièrement sur GitHub par l'organisation Tarantool.
Là, nous avons Tarantool lui-même, son noyau, des connecteurs vers des systèmes externes, des topologies telles que le sharding ou les files d'attente ; modules, bibliothèques, à la fois de l'équipe de développement et de la communauté. Les modules communautaires peuvent très bien être hébergés par nous.
En plus de la version open source, Tarantool dispose également d'une branche entreprise. Tout d'abord, il s'agit d'assistance, de produits d'entreprise, de formation, de développement personnalisé et de conseil. Aujourd'hui, nous allons parler des principales fonctionnalités disponibles dans toutes les versions du produit.
Tarantool est aujourd'hui un composant de base pour les applications centrées sur les bases de données.
Comment fonctionne le noyau ?
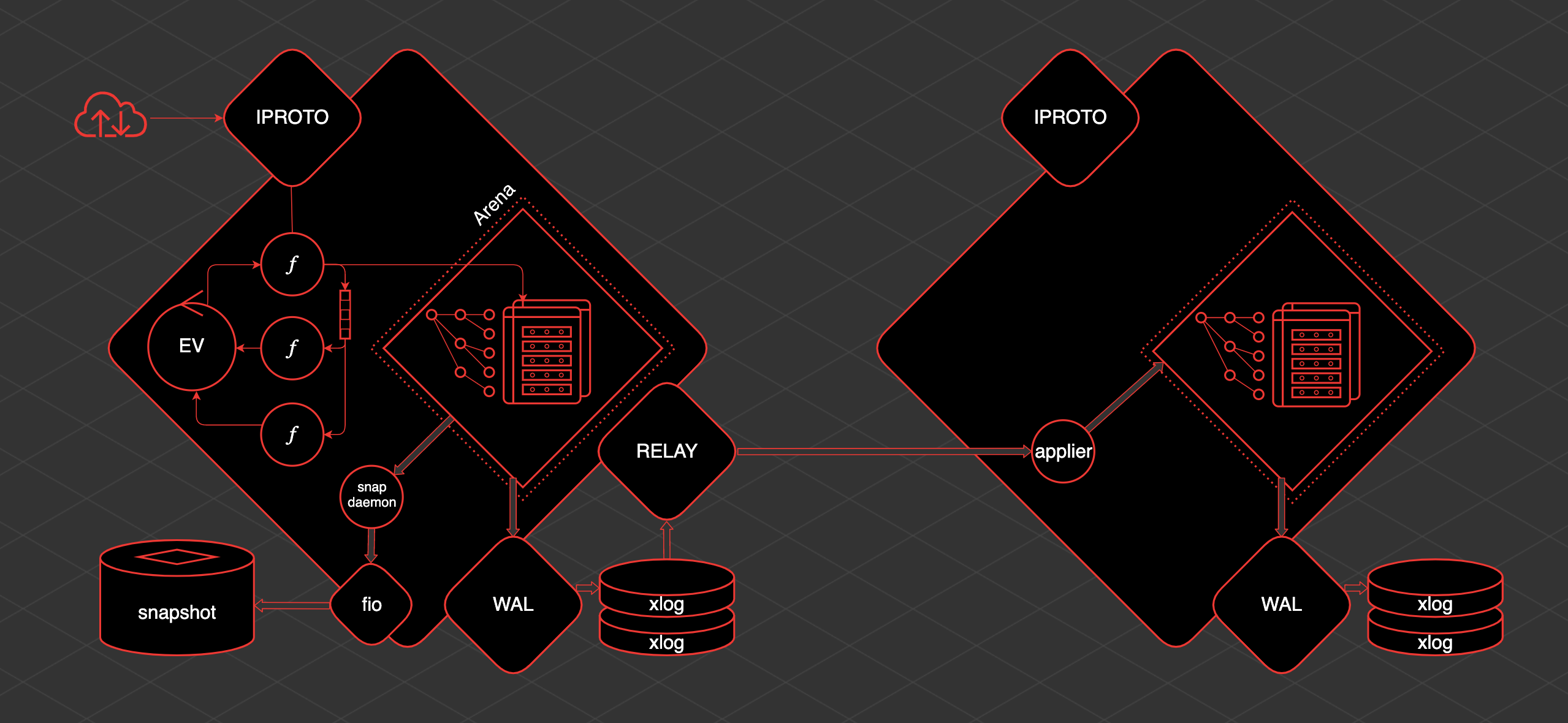
L'idée principale autour de laquelle Tarantool est né et s'est développé est que les données sont en mémoire. Ces données sont toujours accessibles à partir d'un thread. Les modifications que nous apportons sont écrites de manière linéaire dans le journal d'écriture anticipée.
Les index sont construits sur les données en mémoire. C'est-à-dire que nous avons un accès indexé et prévisible aux données. Un instantané de ces données est enregistré périodiquement. Ce qui est écrit sur le disque peut être répliqué.
Tarantool a un fil transactionnel principal. Nous l'appelons le fil TX. Dans ce fil, il y a Arena. Il s'agit d'une zone de mémoire allouée par Tarantool pour le stockage des données. Les données sont stockées dans Tarantool dans des espaces.
L'espace est un ensemble, une collection d'unités de stockage - des tables. Tapl est comme une ligne dans un tableau. Les index sont construits sur ces données. Arena et les répartiteurs spécialisés qui travaillent au sein d'Arena sont chargés de stocker et d'organiser tout cela.
- Tapl = chaîne
- Espace = tableau
Également à l'intérieur du thread TX, il y a une boucle d'événement, une boucle d'événement. Les fibres fonctionnent dans la boucle d'événement. Ce sont des primitives coopératives à partir desquelles nous pouvons communiquer avec les espaces. Nous pouvons lire des données à partir de là, nous pouvons créer des données. De plus, les fibres peuvent interagir avec la boucle d'événements et entre elles directement ou à l'aide de primitives spéciales - des canaux.

Afin de travailler avec l'utilisateur de l'extérieur, il existe un fil distinct - iproto. iproto accepte les demandes du réseau, traite le protocole Tarantool, transmet la demande à TX et exécute la demande de l'utilisateur dans une fibre distincte.
Lorsqu'un changement de données se produit, un thread séparé appelé WAL (à partir du journal d'écriture anticipée) écrit des fichiers appelés xlog.
Lorsque Tarantool accumule une grande quantité de xlog, il peut être difficile pour lui de démarrer rapidement. Par conséquent, pour accélérer le lancement, il y a une sauvegarde périodique de l'instantané. Pour enregistrer des instantanés, il existe une fibre appelée démon d'instantané. Il lit le contenu cohérent de l'ensemble de l'arène et l'écrit sur le disque dans un fichier instantané.
Il n'est pas possible d'écrire directement sur le disque depuis Tarantool en raison du multitâche coopératif. Vous ne pouvez pas bloquer, et le disque est une opération de blocage. Par conséquent, le travail avec le disque est effectué via un pool de threads distinct de la bibliothèque fio.

Tarantool a une réplication et est assez simple à organiser. S'il y a une réplique de plus, alors afin de lui fournir des données, un autre thread est déclenché - relais. Sa tâche est de lire les xlog et de les envoyer aux répliques. Un applicateur fibre est lancé sur la réplique, qui reçoit les modifications de l'hôte distant et les applique à l'Arena.
Et ces modifications sont exactement les mêmes que si elles étaient faites localement, via WAL, elles sont écrites dans le xlog. Sachant comment tout cela fonctionne, vous pouvez comprendre et prédire le comportement de telle ou telle section Tarantool et comprendre quoi en faire.
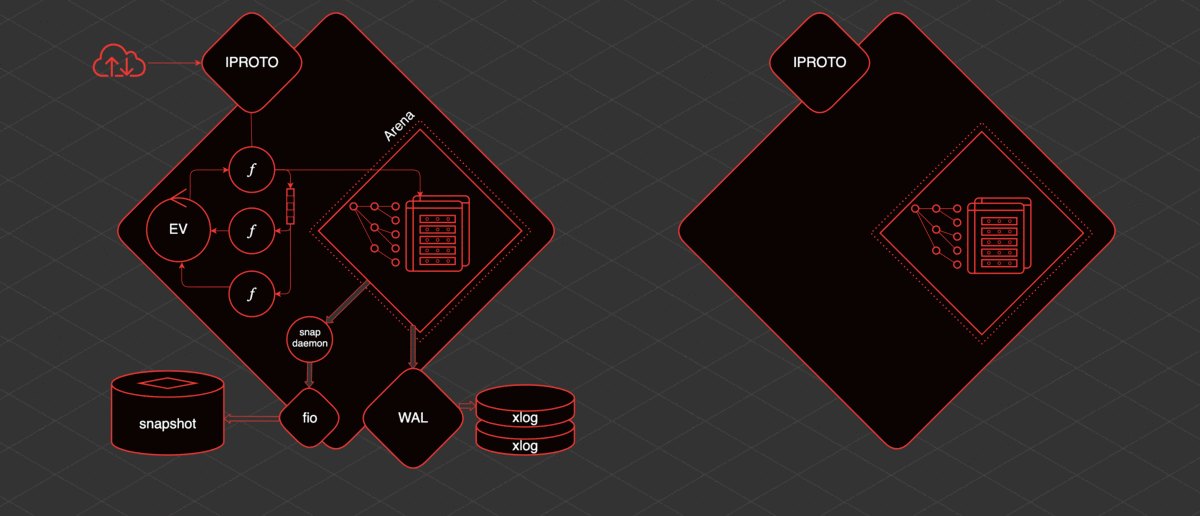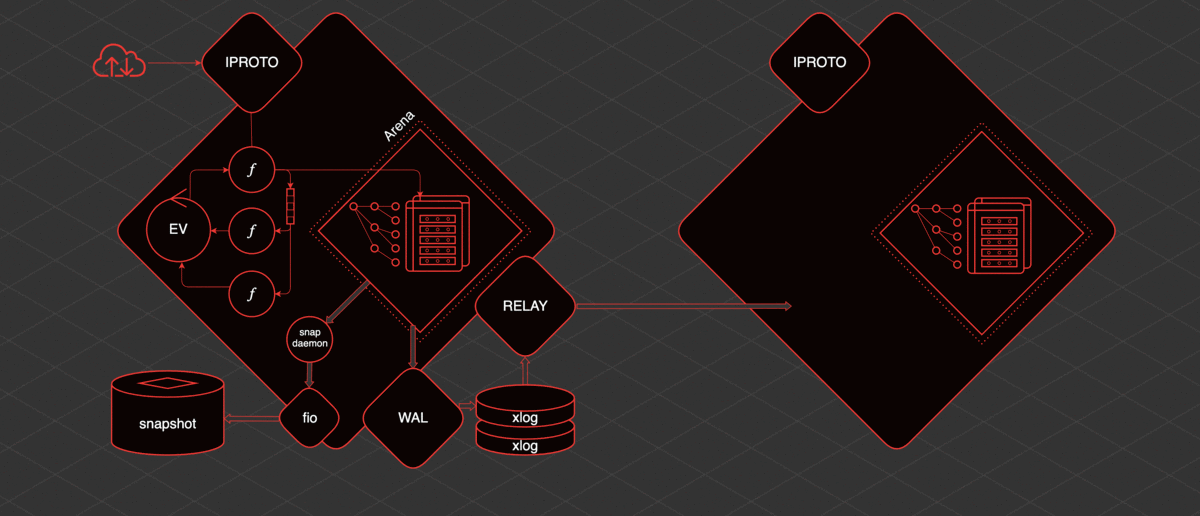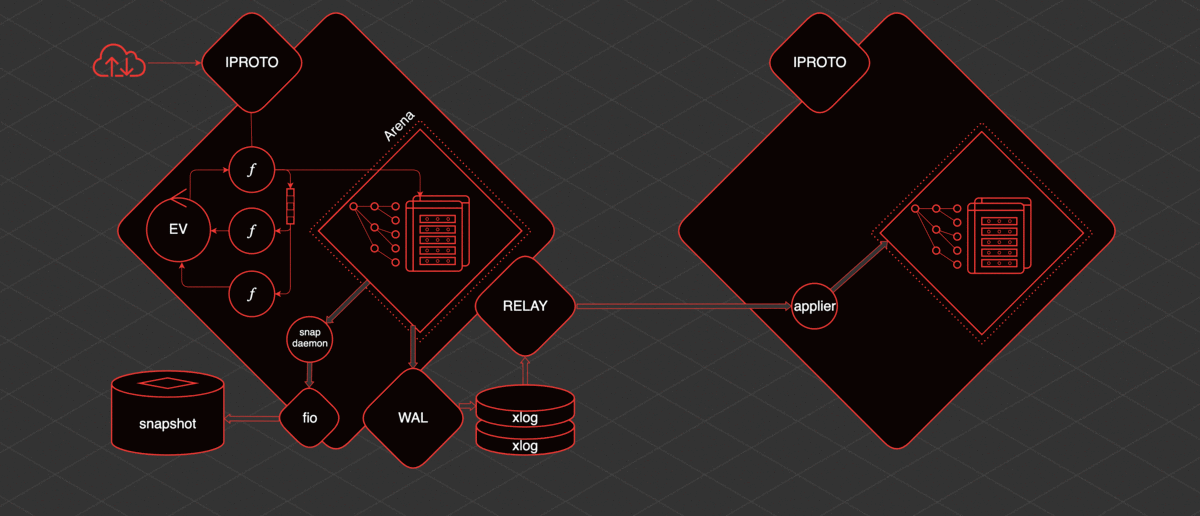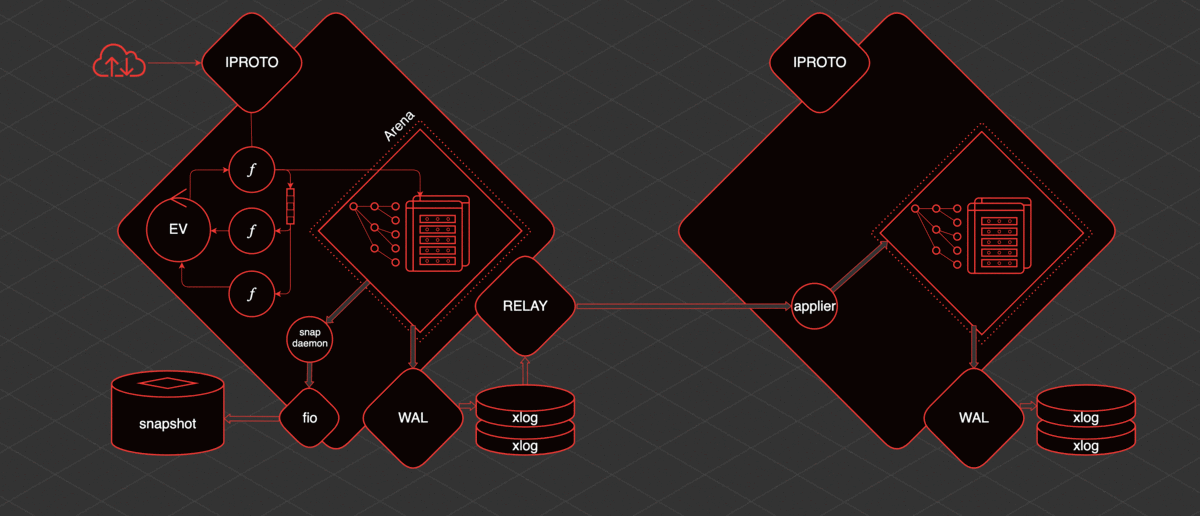
Que se passe-t-il lorsque vous redémarrez ? Imaginons que Tarantool fonctionne depuis un moment, il y a un instantané, il y a un xlog. Si vous le redémarrez :
- Tarantool trouve le dernier instantané et commence à le lire.
- Lit et regarde quel xlog il y a après cet instantané. les lit.
- À la fin de la lecture de l'instantané et du xlog, nous avons un instantané des données qui étaient au moment du redémarrage.
- Ensuite, Tarantool complète les index. Au moment de la lecture de l'instantané, seuls les index primaires sont créés.
- Lorsque toutes les données ont été hissées en mémoire, nous pouvons construire des index secondaires.
- Tarantool lance l'application.
La structure du noyau en six lignes :
- Les données sont en mémoire
- Accéder aux données à partir d'un thread
- Les modifications sont écrites dans le journal d'écriture anticipée
- Les index sont construits sur les données
- L'instantané sera enregistré périodiquement
- WAL est répliqué.
Lua
Les applications Tarantool sont implémentées dans LuaJIT. Ici, vous pouvez vous arrêter et expliquer pourquoi LuaJIT.
Premièrement, Lua est un langage de script accessible qui a été créé à l'origine non pas pour les programmeurs, mais pour les ingénieurs. C'est-à-dire pour les personnes qui sont techniquement instruites, mais pas très profondément immergées dans les spécificités de la programmation.
Lua a été aussi simple que possible. Par conséquent, il s'est avéré possible de créer un compilateur JIT qui vous permet d'apporter les performances d'un langage de script presque aux performances de C. Vous pouvez trouver des exemples lorsqu'un petit programme Lua compilé en LuaJIT rattrape pratiquement un C similaire programme en performance [4].
Lua permet d'écrire assez facilement des choses efficaces. En général, il y avait une idée autour de Tarantool - travailler côte à côte avec les données. En exécutant le programme dans le même espace de noms et le processus dans lequel se trouvent les données, nous ne pouvons pas perdre de temps à parcourir le réseau.
Nous accédons directement à la mémoire, la lecture a donc une latence presque nulle et prévisible. Tout cela aurait pu être réalisé simplement avec les fonctions Lua, mais à l'intérieur de Tarantool, il y a une boucle d'événement plus des fibres. Lua est intégré à eux.
Le total:
- Lua : un langage de script simple pour les ingénieurs
- Compilation JIT très efficace
- Travailler aux côtés des données
- Pas de procédures, mais un runtime coopératif
Fibre et multitâche coopératif
La fibre est le fil conducteur de l'exécution. Il est similaire à un thread, mais plus léger et implémente une primitive multitâche coopérative. Cela nous impose les propriétés suivantes.
- Plusieurs tâches ne sont pas exécutées à la fois.
- Le système n'a pas de programmateur. Toute fibre doit se rendre volontairement.
L'absence d'un ordonnanceur et l'exécution simultanée de tâches réduisent la consommation de surcharge parasite et améliorent les performances. L'ensemble permet de construire un serveur d'applications. Vous pouvez quitter Tarantool vers le monde extérieur.
Tarantool dispose de bibliothèques pour travailler à la fois avec les réseaux et les données. Vous pouvez l'utiliser comme un langage de programmation familier, similaire à Python, Perl, JavaScript, et résoudre des tâches qui ne sont pas du tout liées à la base de données.
À l'intérieur de Tarantool, il existe des fonctions, à l'intérieur du serveur d'applications lui-même, pour travailler avec la base de données. Au cours du développement de Tarantool, la plate-forme a évolué sur ce serveur d'applications. Nous entendons ce qui suit dans le terme plate-forme.
La plate-forme est essentiellementbase de données en mémoire et serveur d'applications intégré. Ou vice versa, un serveur d'applications plus une base de données. Mais Tarantool est également livré avec des outils de réplication, de partitionnement ; des outils de clustering et de gestion de ce cluster, et des connecteurs vers des systèmes externes.
Le total:
- Fiber est un thread d'exécution léger qui implémente le multitâche coopératif
- La tâche suivante est exécutée après que la tâche en cours a annoncé le transfert de contrôle
- Serveur d'applications
- Boucle événementielle avec fibres
- Prise de courant non bloquante
- Collection de bibliothèques de réseaux et de données
- Fonctions pour travailler avec la base de données
- Plateforme Tarantool
- Base de données en mémoire
- Serveur d'applications intégré
- Outils de clustering
- Connecteurs vers des systèmes externes
Fonctionnalité de la base de données
Nous utilisons des bandes pour stocker les données. Ce sont des tuples. C'est un tableau avec des données qui ne sont pas typées. Les tuples ou les taples sont combinés dans des espaces. L'espace n'est essentiellement qu'une collection de bandes. L'analogue du monde de SQL est une table.
Tarantool dispose de deux moteurs de stockage. Vous pouvez définir différents espaces de stockage en mémoire ou sur disque. Pour travailler avec des données, un index primaire est requis. Si nous créons uniquement l'index primaire, Tarantool ressemblera à une valeur-clé.
Mais nous pouvons avoir plusieurs index. Les index peuvent être composites. Ils peuvent être constitués de plusieurs champs. On peut sélectionner par correspondance partielle avec l'index. On peut travailler sur des indices, c'est-à-dire une itération séquentielle sur l'itérateur.
Les index sont de différents types. Par défaut, Tarantool utilise l'arbre B + *. Et puis il y a le hachage, le bitmap, le rtree, les index fonctionnels et les index sur les chemins JSON. Toute cette diversité nous permet d'utiliser Tarantool avec assez de succès là où les bases de données relationnelles sont adaptées.
Tarantool dispose également d'un mécanisme de transaction ACID. Un seul périphérique d'accès aux données à thread nous permet d'atteindre le niveau d'isolement sérialisable. Lorsque nous nous référons à l'arène, nous pouvons y lire ou y écrire, c'est-à-dire faire des modifications de données. Tout ce qui se passe est exécuté séquentiellement et exclusivement dans un thread.
Deux fibres ne peuvent pas fonctionner en parallèle. Mais si nous parlons de transactions interactives, il existe un moteur MVCC distinct. Il vous permet d'effectuer des transactions sérialisables qui sont déjà interactives, mais vous devrez en plus gérer les conflits de transactions potentiels.
En plus du moteur d'accès Lua, Tarantool dispose de SQL. Nous avons souvent utilisé Tarantool comme stockage relationnel. Nous avons conclu que nous allons concevoir le stockage selon des principes relationnels.
Là où les tables ont été utilisées en SQL, nous avons des espaces. C'est-à-dire que chaque ligne est représentée par un robinet. Nous avons défini un schéma pour nos espaces. Il est devenu clair que vous pouvez prendre n'importe quel moteur SQL et simplement mapper des primitives et exécuter SQL sur Tarantool.
Dans Tarantool, nous pouvons appeler SQL depuis Lua. Nous pouvons utiliser SQL directement, ou à partir de SQL, nous pouvons appeler ce qui est défini dans Lua.
SQL est un mécanisme complémentaire, vous pouvez l'utiliser, vous n'avez pas besoin de l'utiliser, mais c'est un très bon ajout qui étend les possibilités d'utilisation de Tarantool.
Total :
primitives de stockage de données
- tapl (tuple, chaîne)
- espace (table) - collection de bandes
- moteur:
- memtx - toute la quantité de données tient dans la mémoire et une copie fiable sur le disque
- vynil - stocké sur disque, la quantité de données peut dépasser la quantité de mémoire
- index primaire
Index
- peut-être beaucoup
- composite
- types d'index
- arbre (B⁺ *)
- hacher
- bitmap
- rtree
- fonctionnel
- chemin json
Transactions
- ACIDE
- Sérialisable (sans rendement)
- Interactif (MVCC)
SQL et Lua
- TABLEAU : espace
- LIGNE : tuple
- Schéma : format d'espace
- Lua -> SQL : box.execute
Comparaison avec d'autres systèmes
Pour bien comprendre la place de Tarantool dans le monde des SGBD, nous allons le comparer avec d'autres systèmes. Vous pouvez beaucoup comparer avec quelqu'un, mais je suis intéressé par quatre groupes principaux :
- Plateformes en mémoire
- SGBD relationnel
- Solutions clé-valeur
- Systèmes orientés document
Plateformes en mémoire
GridGain, GigaSpaces, Redis Enterprise, Hazelcast, Tarantool.
En quoi sont-ils similaires ? Moteur en mémoire, base de données en mémoire, ainsi qu'un certain temps d'exécution d'application. Ils vous permettent de créer de manière flexible des systèmes de cluster pour différentes quantités de données.
En particulier, c'est l'utilisation dans le rôle de Data Grid. Ces plates-formes visent à résoudre des problèmes commerciaux. Chaque grille, chaque plateforme en mémoire est construite sur sa propre architecture, alors qu'elles appartiennent à la même classe. De plus, différentes plates-formes ont un ensemble d'outils différent, car chacune d'entre elles s'adresse à un segment différent.
Tarantool est une plate-forme sans segment à usage général. Cela offre des opportunités plus larges et une gamme de scénarios commerciaux à résoudre.
Bases de données relationnelles
Comparons maintenant le moteur de base de données en mémoire Tarantool avec MySQL et PostgreSQL. Cela permet de positionner le moteur lui-même, isolé du serveur applicatif et encore plus de la plateforme.
Tarantool est similaire aux bases de données relationnelles en ce sens qu'il stocke les données sous forme de tableau (dans des bandes et des espaces). Les index sont construits sur les données, tout comme dans les bases de données relationnelles. Dans Tarantool, vous pouvez définir un schéma, il existe même du SQL, avec lequel vous pouvez travailler avec des données.
Mais c'est le schéma SQL qui distingue Tarantool des bases de données relationnelles classiques. Parce que même si SQL est là, vous n'avez pas à l'utiliser. Ce n'est pas l'outil principal pour interagir avec la base de données.
Le schéma de Tarantool n'est pas strict. Vous ne pouvez le définir que pour un sous-ensemble de vos données.
Dans les bases de données relationnelles conventionnelles, une table en mémoire n'est pas un stockage persistant utilisé pour certains types d'opérations rapides. Dans Tarantool, toute la quantité de données tient dans la mémoire, est servie à partir de la mémoire et est en même temps fiable et persistante .
C'est si important que je vais écrire à nouveau - Tarantool stocke l'ensemble des données en mémoire et en même temps, les données sont enregistrées en toute sécurité sur le disque .
Base de données clé-valeur
La classe suivante à comparer est la valeur-clé - memcached, Redis, Aerospike. En quoi Tarantool leur ressemble-t-il ? Il peut fonctionner en mode clé-valeur, vous pouvez utiliser exactement un index. Dans ce cas, Tarantool se comporte comme un magasin clé-valeur classique.
Par exemple, Tarantool peut être utilisé en remplacement de memcached. Il existe un module qui implémente le protocole correspondant, et dans ce cas nous imitons complètement memcached.
Tarantool est similaire dans son architecture en mémoire à Redis, il a juste un style différent de description des données. Partout où Redis s'applique aux scénarios architecturaux, vous pouvez utiliser Tarantool. La bataille de ces yokozun est décrite dans l'article au lien [5].
La différence entre Tarantool et les bases de données clé-valeur réside précisément dans la présence d'index secondaires, de transactions, d'itérateurs et d'autres éléments inhérents aux bases de données relationnelles.
Bases de données orientées documents
Comme quatrième catégorie, je voudrais citer les bases de données documentaires. L'exemple le plus frappant ici est MongoDB. Tarantool peut également stocker des documents. Par conséquent, nous pouvons dire que Tarantool a sa propre manière, y compris une base orientée document.
Le format de stockage interne de Tarantool lui-même est msgpack. C'est un JSON tellement binaire. Il est presque équivalent au format utilisé par Mongo. C'est BSON. Il a la même compacité. Il reflète les mêmes types de données. Ce faisant, vous pouvez indexer le contenu de ces documents. En savoir plus sur msgpack dans un article récent [6].
La bibliothèque Avro Schema est également incluse avec Tarantool. Il permet d'analyser des documents d'une structure régulière en lignes et ces lignes sont déjà stockées directement dans la base de données.
Mais Tarantool n'a pas été conçu à l'origine comme une base de données orientée document. C'est un bonus pour lui et la possibilité de stocker une partie des données sous forme de document. Par conséquent, il a des mécanismes d'indexation légèrement plus faibles par rapport au même Mongo.
Tour bonus : bases de colonnes
De telles questions se posent parfois. La réponse ici est simple - Tarantool n'est pas une base de données en colonnes (qui l'aurait pensé). Les scripts qui conviennent aux bases en colonnes ne fonctionnent pas avec Tarantool. On peut noter qu'ils se complètent extrêmement bien.
Je pense que beaucoup d'entre vous connaissent Click House. C'est une excellente solution analytique. Il s'agit d'une base de colonne. De plus, ClickHouse n'aime pas les microtransactions. Si vous lui envoyez beaucoup de petites transactions, il n'atteindra pas son débit maximum. Vous devez lui envoyer des données par lots.
Dans le même temps, les microtransactions peuvent et doivent être envoyées à Tarantool. Il est capable de les accumuler. Puisqu'il dispose de plusieurs connecteurs, il peut cumuler ces transactions et les envoyer en batch vers un stockage de type ClickHouse. Le yin et le yang.
Le total:
| vs | ||
|---|---|---|
| In-memory |
|
|
|
|
|
| Key-value |
|
|
| - |
|
|
|
|
Nous commencerons par des exemples de cas où Tarantool ne doit pas être utilisé. Le scénario principal est l'analyse, alias OLAP, y compris l'utilisation de SQL.
Les raisons en sont assez simples. Tarantool est essentiellement une application à thread unique. Il n'a pas de verrous d'accès aux données. Mais si un thread exécute un SQL long, personne d'autre ne pourra s'exécuter pendant son exécution.
Par conséquent, les bases de données analytiques utilisent généralement le mode d'accès aux données multithread. Ensuite, vous pouvez tricher quelque chose dans des fils séparés. Dans le cas de Tarantool, un thread est plus rapide que de nombreuses autres solutions. Mais c'est un, et il n'y a aucun moyen de travailler avec les données de plusieurs threads.
Mais si vous souhaitez créer des analyses pré-calculées, par exemple, vous savez que vous aurez besoin de données cumulatives comme celle-ci. Vous avez un flux de données et vous pouvez immédiatement dire que vous avez besoin d'une sorte de compteur. Cette analyse préfigurée s'appuie bien sur Tarantool.
Quand utiliser
Le scénario principal vient de son héritage historique, de ce pour quoi il a été créé. Beaucoup de petites transactions.
Il peut s'agir de sessions, de profils d'utilisateurs et de tout ce qui en a découlé pendant cette période. Par exemple, Tarantool est souvent utilisé comme magasin vectoriel à côté de Machine Learning, car il est pratique de l'y stocker. Il peut être utilisé comme des compteurs très chargés qui font passer tout le trafic à travers eux-mêmes, des systèmes anti-force brute.
Sous-total :
exemples de mauvaise utilisation
- Analytique (OLAP)
- Incl. en utilisant SQL
Exemples de bon usage
- Microtransactions à haute fréquence (OLTP)
- Des profils d'utilisateurs
- Comptoirs et enseignes
- Proxy de cache de données
- Courtiers de file d'attente
Conclusion et conclusions
Tarantool est persistant et a la capacité de marcher vers de nombreux autres systèmes. Par conséquent, il est utilisé comme proxy de cache pour les systèmes hérités. Trop lourd, complexe, à la fois en écriture vraie proxy et en écriture derrière proxy.
De plus, l'architecture de Tarantool, la présence de fibres dans celui-ci et la possibilité d'écrire des applications complexes en font un bon outil pour écrire des files d'attente. Je connais 6 implémentations de file d'attente, certaines d'entre elles sont sur GitHub, d'autres dans des référentiels privés ou quelque part dans des projets.
La raison principale en est la faible latence garantie pour l'accès. Lorsque nous sommes à l'intérieur de Tarantool et que nous venons chercher des données, nous les donnons de mémoire. Nous avons un accès rapide et compétitif aux données. Ensuite, vous pouvez créer des mashups qui s'exécutent juste à côté des données.
Essayez Tarantool sur notre site Web et posez des questions au chat Telegram .
Liens
- Architecture S3 : 3 ans d'évolution pour Mail.ru Cloud Storage
- Vidéo - Tarantool comme base pour les applications à forte charge
- Tarantool : comment économiser un million de dollars sur une base de données sur un projet à forte charge
- https://github.com/luafun/luafun
- Tarantool vs Redis : ce que les technologies en mémoire peuvent faire
- Fonctionnalités avancées de MessagePack