 Chez ABBYY, nous traitons depuis longtemps des
problèmes de traitement du langage naturel (NLP). Les technologies de traitement du langage naturel sont au cœur de nombreuses solutions NLP d'ABBYY pour la recherche et l'extraction de données. Avec leur aide, nous avons aidé le géant industriel NPO Energomash
à effectuer une recherche d'après les documents accumulés dans l'entreprise depuis près de 100 ans, et l'une des grandes banques
utilisenotre technologie pour surveiller le gigantesque flux d'informations et gérer les risques. Dans cet article, nous expliquerons comment nos technologies NLP fonctionnent en interne pour extraire des informations à partir de texte solide. Nous ne parlerons pas de texte sous forme de tableaux et de formulaires clairement structurés, comme les lettres de voiture, mais de documents non structurés de plusieurs pages : contrats de location, dossiers médicaux et bien plus encore.
Chez ABBYY, nous traitons depuis longtemps des
problèmes de traitement du langage naturel (NLP). Les technologies de traitement du langage naturel sont au cœur de nombreuses solutions NLP d'ABBYY pour la recherche et l'extraction de données. Avec leur aide, nous avons aidé le géant industriel NPO Energomash
à effectuer une recherche d'après les documents accumulés dans l'entreprise depuis près de 100 ans, et l'une des grandes banques
utilisenotre technologie pour surveiller le gigantesque flux d'informations et gérer les risques. Dans cet article, nous expliquerons comment nos technologies NLP fonctionnent en interne pour extraire des informations à partir de texte solide. Nous ne parlerons pas de texte sous forme de tableaux et de formulaires clairement structurés, comme les lettres de voiture, mais de documents non structurés de plusieurs pages : contrats de location, dossiers médicaux et bien plus encore.
Nous vous montrerons ensuite comment cela fonctionne dans la pratique. Par exemple, comment extraire X entités d'un accord bancaire de 200 pages en X minutes. Assurez-vous que le contrat légal est correct ou obtenez rapidement des informations sur les effets secondaires rares à partir d'une collection d'articles médicaux. Notre expérience montre que les entreprises doivent obtenir ces données rapidement et sans erreur, car le bien-être des entreprises et des personnes en dépend.
À la fin de l'article, nous mentionnerons plusieurs difficultés que nous avons rencontrées lors de la conduite de tels projets et partagerons notre expérience sur la façon dont nous avons réussi à les résoudre. Eh bien, bienvenue au chat.
Alors que faisons nous?
En général, les technologies de traitement et d'analyse du langage naturel permettent beaucoup de choses : filtrer le spam dans les e-mails, créer des systèmes de traduction automatique, reconnaître la parole et développer et former des robots de discussion. Les technologies NLP d'ABBYY aident les banques, les entreprises industrielles et autres à extraire et structurer rapidement une grande quantité d'informations à partir de documents commerciaux. Les grandes entreprises automatisent depuis longtemps, ou du moins s'efforcent de réduire, le nombre d'opérations manuelles et routinières. Il s'agit de rechercher dans un document papier la date, le nom complet, le montant, le NIF, le numéro de facture ; réimprimer les données dans les systèmes d'information de l'entreprise, vérifier si tout est correctement renseigné.
Rappelons qu'initialement nous étions capables d'extraire du texte de documents en fonction de caractéristiques géométriques, en particulier la structure et la disposition des lignes et des champs. Ainsi, il est toujours commode de traiter les informations issues de questionnaires structurés, de formulaires stricts, de questionnaires, de demandes, de formulaires de recensement, etc. Soit dit en passant, nous avons parlé sur Habré d'un tel cas - avec l'aide d' ABBYY FlexiCapture, le ministère de la Santé du Bangladesh a traité des questionnaires de recensement médical remplis par les résidents de la république.
Il est clair que les informations importantes ne sont pas stockées uniquement dans des formulaires, nous avons donc formé nos solutions NLP à « extraire » des données à partir de documents qui n'ont aucune structure du tout ou sont extrêmement complexes. Beaucoup de gens se souviennent probablement de ABBYY Compreno pour l'analyse et la compréhension du langage naturel. Nous avons développé et amélioré la technologie et, par la suite, elle a constitué la base de bon nombre de nos solutions de PNL. L'un des cas d'utilisation de la PNL est un projet de surveillance de l'actualité dans plusieurs grandes banques russes. En bref, notre moteur est capable d'effectuer le travail d'un souscripteur bancaire - une personne qui capte les événements concernant les contreparties à partir d'un gigantesque flux d'informations et évalue les risques. En savoir plus à ce sujet ici .
Ci-dessous, nous parlerons d'un autre aspect - l'extraction d'informations à partir de documents non structurés tels que des contrats, des dossiers médicaux, des nouvelles de diverses sources.

Comment fonctionnent nos technologies de PNL
Conceptuellement, le traitement du document à partir du moment où il est chargé dans ABBYY FlexiCapture jusqu'à ce que les champs requis soient extraits ressemble à ceci :
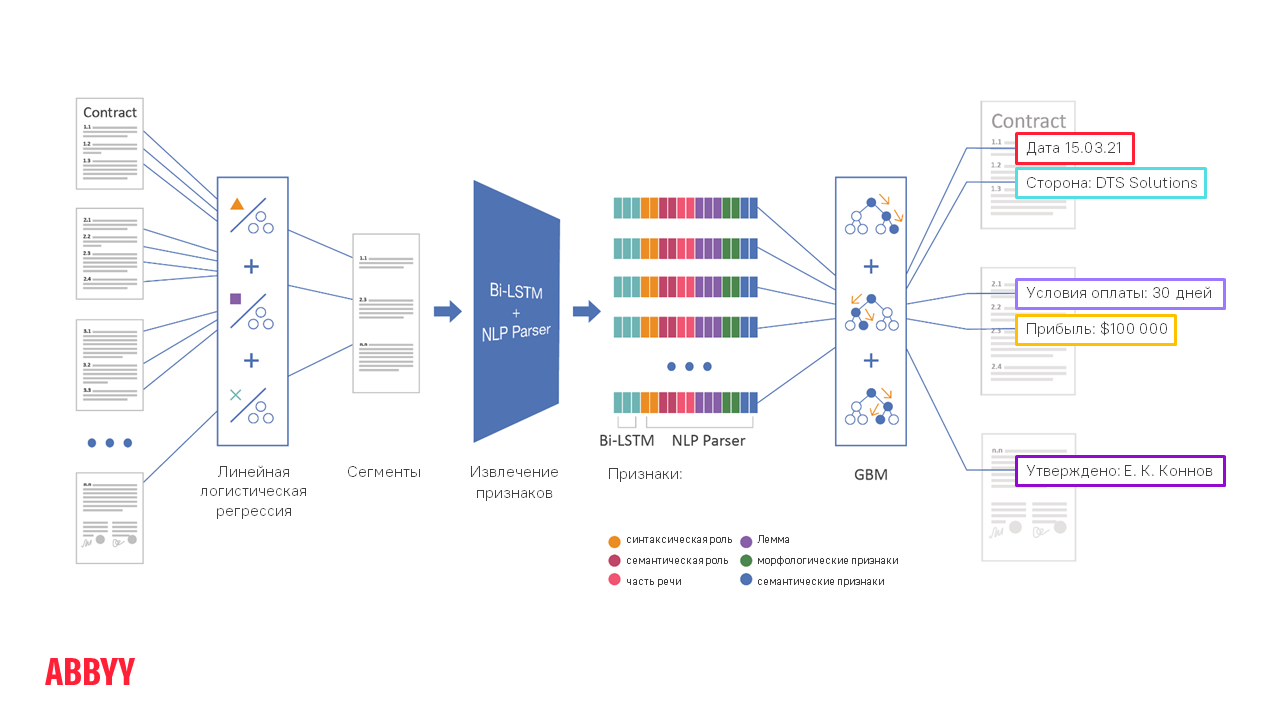
Disons que vous devez extraire la date et le lieu de signature, ainsi que les noms des entreprises participantes d'un contrat de 50 pages . 50 pages, Karl ! Et il y a beaucoup de dates ! Comment trouver la page recherchée par le client ? La technologie permet de le faire en plusieurs étapes.
Étape de segmentation
Ensuite, le document est segmenté , c'est-à-dire que nous réduisons la zone de recherche d'informations et ne traitons pas toutes les 50 pages, mais seulement, disons, 5 segments par paragraphe, là où la date dont nous avons besoin peut être. Il est donc beaucoup plus facile pour les algorithmes de fonctionner, ainsi que de distinguer la date requise d'une autre.
Toutes les étapes à droite de la segmentation sur le schéma décrivent le fonctionnement des algorithmes de PNL - étude détaillée, lecture et compréhension du texte. Ces processus prennent 10 à 20 fois plus de temps que la classification et la segmentation, il n'est donc pas tout à fait correct de les exécuter sur un document entier de plusieurs pages. Il est plus facile de les « inciter » à une petite quantité de texte.
Comment fonctionnent l'analyseur NLP + Bi-LSTM
Avec leur aide, des signes (caractéristiques) sont extraits de chaque phrase du texte. Il s'agit de la technologie ABBYY Compreno, qui fonctionne dans le cadre de FlexiCapture. Le moteur lit le texte en détail et en extrait de nombreuses fonctionnalités de généralisation. Il comprend non seulement ce qui est spécifiquement formulé dans cette phrase, mais aussi le sens - ce qui est réellement signifié.
L'extraction de caractéristiques est une étape longue. Il y a des signes de haut niveau. En gros, ils indiquent que dans ce fragment, quelque chose comme un nom fait quelque chose comme une action avec un objet d'une classe sémantique. Ensuite, sur les caractéristiques de haut niveau extraites, une méthode ML-GBM assez simple et classique est appliquée. C'est un ensemble d'arbres de décision qui apporte une solution générale et met en évidence les champs extraits. Pour que GBM puisse apprendre rapidement et extraire des informations de qualité, il est important de disposer d'un nombre suffisant de documents pour la formation. S'il y en a peu, la qualité de l'extraction de l'information peut diminuer. Cela est dû au fait que le noyau des cas devient plus petit et, par conséquent, la "machine" est moins apte à généraliser - pour distinguer les cas individuels des cas fréquents.

Où est-il utilisé ?
Voici quelques exemples de notre pratique - projets mis en œuvre, pilotes ou cas de concept.
La PNL pour les institutions financières

Les clients nous demandent souvent de traiter les factures (factures) et les bons de commande. Certaines données (ou champs), blocs de texte ou d'adresse, peuvent être extraits selon les méthodes traditionnelles, en s'appuyant sur des mots-clés. Mais si vous avez besoin de regarder à l'intérieur d'un bloc de texte, alors la PNL est nécessaire. Il arrive aussi que vous ayez besoin de "récupérer" non pas le bloc entier avec l'adresse, mais seulement une partie de cette adresse : rue, état, ville, code postal, pays. Ou vous devez analyser les dates et les pourcentages de remise si la facture nécessite un paiement avant une date spécifique. Nos technologies aident à prendre en compte ces variables : combien coûtera une commande si elle est payée à l'avance ou en gros, et combien si elle est payée en retard.
Nous aidons également les services juridiques des grandes entreprises à extraire des données importantes des contrats de service, des rapports d'avancement, des NDA (documents de non-divulgation). Prenons l'exemple d'un de nos projets portant sur des baux commerciaux. Il s'agissait de documents de 30 pages, des données des champs de chaque page que le client avait préalablement saisis manuellement dans le système d'information. Cela prenait généralement une heure pour un document. FlexiCapture a terminé la tâche en deux minutes et, selon les calculs du client, lui a permis d'économiser 5 000 heures de travail en un an.
Ou prenez des accords de prêt. Les prêts sont contractés non seulement par des personnes, mais aussi par de grandes entreprises. Pour ce faire, ils fournissent à la banque un gros paquet de documents. Disons des informations sur les prêts commerciaux disponibles. Et ce n'est pas une sorte d'hypothèque de 6 millions de roubles, mais une hypothèque de 100 millions de dollars (pour les immeubles, les bureaux). Et puis la banque doit extraire 50 à 70 entités ou conditions d'un tel document de 250 pages. Selon les calculs de notre client, le traitement manuel a pris beaucoup de temps - 2 à 3 heures par document. Avec FlexiCapture, tout était prêt en 9 minutes. Pas instantanément, nous comprenons. La raison est dans la conception des documents : ils ont généralement une densité de texte élevée, et un grand nombre d'entités différentes doivent être extraites. Pas une seconde chose :)
Les demandes de prêt sont également souvent traitées. Il s'agit d'un document préliminaire avec des questions que la banque envoie au client. Plus le montant du prêt est élevé, plus il y a de questions dans un tel questionnaire. Par exemple, dans les informations sur le lieu de travail, la banque peut vous demander d'indiquer son identifiant et son adresse légale. Les banques exigent souvent des éclaircissements sur l'état matrimonial, la disponibilité des prêts, les dettes pour les services publics, la pension alimentaire et d'autres choses qui peuvent interférer avec le remboursement du prêt. Parfois, les questions dans les demandes de prêt sont assez complexes, donc certaines entreprises aident leurs clients à traduire du juridique au langage public afin de comprendre et de décrire de manière humaine ce qu'ils attendent du client.
Dans le traitement de ces documents complétés, la principale difficulté réside dans le grand nombre de champs (dans notre cas, il y en avait 105). Il est facile pour un employé de banque de s'y perdre, mais cela ne peut pas faire baisser la technologie. FlexiCapture consacre 5 minutes à tout, un employé - jusqu'à 2-3 heures. Sentez la différence, comme on dit.
Santé
Une partie des projets d'ABBYY est liée à l'extraction d'informations à partir de documents médicaux.

Par exemple, en utilisant la PNL, vous pouvez traiter le résumé d'articles médicaux scientifiques. Il existe une telle direction en pharmacologie - Pharmacovigilance. Il étudie les effets secondaires que les nouveaux médicaments peuvent provoquer chez les patients qui n'ont pas encore été décrits. Les organisations médicales collectent des informations sur ces cas critiques auprès des patients et rédigent des rapports détaillés à leur sujet - Rapports individuels de sécurité des cas (ICSR). Si une nouvelle pilule fait du mal à une personne, le fabricant doit le signaler rapidement à l'organisme de réglementation, sinon il risque une lourde amende. Pour éviter de telles conséquences, les employés hautement qualifiés des sociétés pharmaceutiques lisent l'ICSR en grande quantité. Une tâche assez fastidieuse.
Il est beaucoup plus facile de confondre les technologies avec celles-ci. Dans le cadre de l'un des pilotes de pharmacovigilance, notre technologie a extrait des données d'articles médicaux tels que le sexe et l'âge du patient, des informations sur l'événement qui lui est arrivé et le nom du médicament. Tout sauf le dernier a été extrait à l'aide de l'apprentissage automatique. Mais pour les noms des médicaments, nous avons utilisé une méthode plus simple - les dictionnaires. En fin de compte, le client a demandé d'extraire non pas tous les médicaments possibles des articles, mais des médicaments d'une liste de 80 noms. Dans ce cas, la correspondance par dictionnaire a très bien fonctionné. Les dictionnaires font également partie de FlexiCapture NLP. La morphologie est utilisée pour trouver le nom d'un médicament. Peu importe sous quelle forme ou dans quel registre le mot est écrit, surtout en anglais, il n'y en a pas tellement.
Le traitement des histoires de cas est également automatisé, car il y a beaucoup d'informations à parcourir. Il s'agit de tableaux, de reçus et d'une description de la décision de la compagnie d'assurance. Par exemple, l'un des régulateurs aux États-Unis accepte les plaintes des patients concernant l'assurance. Il arrive que la compagnie d'assurance refuse de payer le traitement. Les raisons peuvent être différentes, mais le patient a le droit de le découvrir et de s'adresser à l'agence gouvernementale. Et le régulateur doit analyser l'information et rendre un verdict, le refus était-il vraiment justifié ?
Si les tableaux sont facilement traités à l'aide de FlexiLayout, les morceaux de texte avec la décision d'assurance ne doivent pas être traités. Nous avons utilisé la PNL pour extraire la solution elle-même et sa justification du texte.
Les antécédents médicaux doivent être soigneusement analysés lorsqu'un patient est transféré d'un hôpital à un autre. Étant donné que nous vivons à une époque de coronavirus, il y a parfois beaucoup de ces patients, et il est difficile pour le personnel hospitalier de faire face à trop de paperasse. L'affaire à laquelle nous avons participé n'avait rien à voir avec la couronne, mais potentiellement notre expérience est toujours précieuse.
Immobilier
- Un de nos clients potentiels loue beaucoup de terrain pour la construction et les bureaux. En conséquence, la société conclut de nombreux contrats de location... Elle doit traiter automatiquement ces documents : en extraire les dates et les échéances, afin de pouvoir plus tard savoir s'ils manquent des paiements, quand le bail se termine, où le contrat est automatiquement renouvelé, combien cela coûte.
- Les entreprises de construction ont également des spécialistes tels que des analystes de portefeuille... Ils analysent les contrats, découvrent combien coûte une propriété particulière et aident à évaluer sa qualité et les revenus qu'elle peut apporter au propriétaire. Comme la notation bancaire. Aux États-Unis, en passant, vous pouvez vendre ou acheter partiellement un ensemble de prêts hypothécaires. C'est une sécurité, elle peut aussi monter ou baisser de prix. Par exemple, si les prix de l'immobilier augmentent, une hypothèque moins chère peut être refinancée. Et si tout devient moins cher, alors le client essaie de se débarrasser de ce papier.
Dans un tel contrat, il y a des informations qui sont récupérées à la fois avec l'aide de la PNL et sans elle. Données tabulaires - en utilisant FlexiLayout (c'est ce que nous pouvions faire auparavant). Et tous les autres champs sont des paragraphes extraits par le segmenteur, ou des champs dans des paragraphes extraits par des modèles d'extraction.
L'avantage des technologies NLP est qu'il s'agit d'un autre mécanisme par lequel plus de types de champs et de documents peuvent être traités.

- L'un de nos clients est l' association des propriétaires, conditionnellement notre SNT . Si un nouveau participant conclut un tel SNT, il reçoit alors un ensemble de 9 types de documents - Actes (cela peut être un contrat de vente et d'achat). Ensuite, les données de ces documents complétés doivent être traitées, vérifiées et saisies dans le système d'information. 8 d'entre eux sont structurés et traités par FlexiLayout. Mais le 9 avec une prise. Pour mener à bien ce projet, notre société avait également besoin de traiter des actes non structurés.
C'est ce que nous avons fait en utilisant la PNL. Les documents eux-mêmes, d'une part, ne sont pas trop volumineux : 1-2 pages. En revanche, ils sont très divers et de mauvaise qualité. Malgré cela, notre solution a pu extraire les informations requises. Ce projet est intéressant en ce que sa partie NLP peut être très petite, mais en même temps critique, car le projet ne peut tout simplement pas être achevé sans lui.
- NLP a besoin d'automatiser le processus d' approbation des contrats (Contract Approval Automation). Les entreprises concluent souvent un accord-cadre - un accord-cadre (cadre) qui définit les conditions générales d'un certain nombre d'opérations futures. Par exemple, ce que le client doit remplir, dans quel délai, quelles sanctions pour les retards, quand payer les services.
Le processus d'approbation automatique d'un contrat ressemble à ceci : nous extrayons un certain nombre de champs et de conditions (clause) du document. Les champs sont un ou plusieurs mots, et la clause est un ou plusieurs paragraphes qui peuvent contenir de longues descriptions. Une entreprise doit extraire des champs afin d'y indexer des documents, de les stocker électroniquement, puis de les rechercher. Sur la clause, l'approbation se produit - vérifier si les conditions sont correctes. Les termes technologiques extraits sont comparés aux termes du contrat-cadre. Si tout correspond, alors il n'y a aucun risque pour l'entreprise, vous pouvez automatiquement approuver (réviser) et envoyer le contrat à la base de données. Cela facilite grandement la vie des avocats : au lieu de traiter le même type de contrats, ils peuvent passer à des tâches plus importantes.Le contrat ne devra être revu que si le système révèle dans le document des incohérences avec le contrat principal.

Ce qui unit tous les projets PNL
Dans les factures structurées, où l'on reconnaît le montant et l'adresse, on sait immédiatement où se trouvent les champs obligatoires, et les documents eux-mêmes occupent une ou plusieurs pages. Dans le cas de documents non structurés, il n'est pas toujours possible de déterminer rapidement de quelles données et où extraire - c'est la principale caractéristique des projets NLP. De plus, les documents eux-mêmes n'occupent pas une page, mais 100 à 200 pages. Ainsi, au stade de l'élaboration des besoins, nous demandons d'abord au client de dresser une liste de plusieurs dizaines de champs à récupérer. De tels projets nécessitent la participation d'un expert en la matière - un expert dans ce domaine, qui répondra aux questions de savoir quoi et dans quel cas doit être extrait du document et à quelles nuances prêter attention.
Parfois, un client demande d'extraire plusieurs centaines de champs d'un document à la fois. Cette approche n'est pas constructive et conduit au fait qu'il faut plus d'un mois pour discuter des exigences du projet. C'est pourquoi, en règle générale, nous ne commençons pas avec des centaines de champs, mais avec 10, clarifions les exigences, montrons comment tout fonctionnera. En conséquence, nous et le client comprenons les étapes ultérieures du projet et les jalons.
De plus, pour tout projet d'apprentissage automatique, ML, y compris NLP, un échantillon représentatif est nécessaire - des échantillons de documents client sur lesquels le système sera formé. Le plus, le mieux.
Conclusion
À l'aide de ces exemples, nous avons montré comment la technologie permet d'économiser notre principale ressource : le temps. En anglais, le schéma s'appelle gagnant-gagnant : les robots assument des tâches répétitives, et les employés libèrent leurs mains pour s'engager dans des projets plus intelligents et intéressants. Les entreprises dans lesquelles non pas des spécialistes, mais des machines sont engagées dans la routine, peuvent construire des interactions avec les clients plus efficacement, éviter les erreurs dans le traitement de certains documents et augmenter la rentabilité plus rapidement.