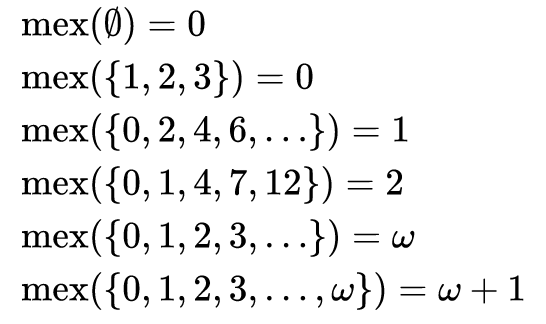
Nous allons décomposer trois algorithmes et examiner leurs performances.
Bienvenue sous la coupe
Avant-propos
Avant de commencer, je voudrais vous dire - pourquoi ai-je commencé cet algorithme ?
Tout a commencé avec un puzzle sur OZON.

Comme vous pouvez le voir à partir du problème, en mathématiques, le résultat de la fonction MEX sur un ensemble de nombres est la plus petite valeur de l'ensemble qui n'appartient pas à cet ensemble. C'est-à-dire qu'il s'agit de la valeur minimale de l'ensemble des additions. Le nom "MEX" est un raccourci pour la valeur "Minimum EXcluded".
Et après avoir fouillé dans le réseau, il s'est avéré qu'il n'y a pas d'algorithme généralement accepté pour trouver MEX ...
Il existe des solutions simples , il existe des options avec des tableaux supplémentaires, des graphiques, mais d'une manière ou d'une autre, tout cela est dispersé dans différents coins d'Internet et il n'y a pas un seul article normal sur cette question. L'idée est donc née - d'écrire cet article. Dans cet article, nous analyserons trois algorithmes pour trouver MEX et verrons ce que nous obtenons en termes de vitesse et de mémoire.
Le code sera en C#, mais en général il n'y aura pas de constructions spécifiques.
Le code de base pour les contrôles sera comme ceci.
static void Main(string[] args)
{
//MEX = 2
int[] values = new[] { 0, 12, 4, 7, 1 };
//MEX = 5
//int[] values = new[] { 0, 1, 2, 3, 4 };
//MEX = 24
//int[] values = new[] { 11, 10, 9, 8, 15, 14, 13, 12, 3, 2, 0, 7, 6, 5, 27, 26, 25, 4, 31, 30, 28, 19, 18, 17, 16, 23, 22, 21, 20, 43, 1, 40, 47, 46, 45, 44, 35, 33, 32, 39, 38, 37, 36, 58, 57, 56, 63, 62, 60, 51, 49, 48, 55, 53, 52, 75, 73, 72, 79, 77, 67, 66, 65, 71, 70, 68, 90, 89, 88, 95, 94, 93, 92, 83, 82, 81, 80, 87, 86, 84, 107, 106, 104 };
//MEX = 1000
//int[] values = new int[1000];
//for (int i = 0; i < values.Length; i++) values[i] = i;
//
int total = 0;
int mex = GetMEX(values, ref total);
Console.WriteLine($"mex: {mex}, total: {total}");
Console.ReadKey();
}
Et encore un point dans l'article, je mentionne souvent le mot "array", bien que "set" serait plus correct, alors je tiens à m'excuser d'avance auprès de ceux qui seront coupés par cette hypothèse.
Note 1 basée sur les commentaires : Beaucoup ont trouvé des défauts avec O (n), ils disent que tous les algorithmes sont en O (n) et ne se soucient pas du fait que "O" est différent partout et ne compare pas réellement le nombre d'itérations. Ensuite, pour plus de tranquillité, nous changeons O en T. Où T est une opération plus ou moins compréhensible : vérification ou affectation. Donc, si j'ai bien compris, ce sera plus facile pour tout le monde
Note 2 basée sur les commentaires : nous considérons le cas où l'ensemble original n'est PAS commandé. Le tri de ces ensembles prend également du temps.
1) Décision au front
Comment trouve-t-on le « nombre minimum manquant » ? L'option la plus simple consiste à créer un compteur et à parcourir le tableau jusqu'à ce que nous trouvions un nombre égal au compteur.
static int GetMEX(int[] values, ref int total)
{
for (int mex = 0; mex < values.Length; mex++)
{
bool notFound = true;
for (int i = 0; i < values.Length; i++)
{
total++;
if (values[i] == mex)
{
notFound = false;
break;
}
}
if (notFound)
{
return mex;
}
}
return values.Length;
}
}
Le cas le plus basique. La complexité de l'algorithme est T (n * cellule (n / 2)) ... pour le cas {0, 1, 2, 3, 4} nous devrons itérer sur tous les nombres puisque faire 15 opérations. Et pour une rangée complètement complète de 100, dont 5050 opérations... Des performances moyennes.
2) Dépistage
La deuxième option d'implémentation la plus complexe rentre dans T(n)... Bon, ou presque T(n), les mathématiciens sont rusés et ne tiennent pas compte de la préparation des données... Car, au moins, il faut connaître le nombre maximum dans l'ensemble.
Du point de vue des mathématiques, cela ressemble à ceci.
Un tableau de bits S de longueur m est pris (où m est la longueur du tableau V) rempli de 0. Et en un seul passage, l'ensemble d'origine (V) du tableau (S) est mis à 1. Après cela, en un seul passage, on trouve la première valeur vide. Toutes les valeurs supérieures à m peuvent être simplement ignorées. si le tableau contient des valeurs "pas assez" jusqu'à m, alors il sera évidemment inférieur à la longueur de m.
static int GetMEX(int[] values, ref int total)
{
bool[] sieve = new bool[values.Length];
for (int i = 0; i < values.Length; i++)
{
total++;
var intdex = values[i];
if (intdex < values.Length)
{
sieve[intdex] = true;
}
}
for (int i = 0; i < sieve.Length; i++)
{
total++;
if (!sieve[i])
{
return i;
}
}
return values.Length;
}
Parce que Les « mathématiciens » sont des gens rusés. Ensuite, ils disent qu'il n'y a qu'un seul passage à travers le tableau d'origine, l'algorithme T (n) ... Ils
s'assoient et se réjouissent qu'un algorithme aussi cool ait été inventé, mais la vérité est.
Tout d'abord, vous devez parcourir le tableau d'origine et marquer cette valeur dans le tableau S T1 (n)
.Ensuite, vous devez parcourir le tableau S et y trouver la première cellule disponible T2 (n)
. toutes les opérations en général ne sont pas compliquées, tous les calculs peuvent être simplifiés à T (n * 2)
Mais c'est clairement mieux qu'une solution simple... Vérifions nos données de test :
- Pour le cas {0, 12, 4, 7, 1} : Front : 11 itérations, tamisage : 8 itérations
- { 0, 1, 2, 3, 4 }: : 15 , : 10
- { 11,…}: : 441 , : 108
- { 0,…,999}: : 500500 , : 2000
Le fait est que si la «valeur manquante» est un petit nombre, alors dans ce cas, une décision frontale s'avère plus rapide, car ne nécessite pas de triple traverser le tableau. Mais en général, aux grandes dimensions, il perd clairement au tamisage, ce qui n'est pas vraiment surprenant.
Du point de vue du "mathématicien" - l'algorithme est prêt, et c'est génial, mais du point de vue du "programmeur" - c'est terrible à cause de la quantité de RAM gaspillée et de la passe finale à trouver la première valeur vide veut clairement être accélérée.
Faisons-le et optimisons le code.
static int GetMEX(int[] values, ref int total)
{
var max = values.Length;
var size = sizeof(ulong) * 8;
ulong[] sieve = new ulong[(max / size) + 1];
ulong one = 1;
for (int i = 0; i < values.Length; i++)
{
total++;
var intdex = values[i];
if (intdex < values.Length)
{
sieve[values[i] / size] |= (one << (values[i] % size));
}
}
var maxInblock = ulong.MaxValue;
for (int i = 0; i < sieve.Length; i++)
{
total++;
if (sieve[i] != maxInblock)
{
total--;
for (int j = 0; j < size; j++)
{
total++;
if ((sieve[i] & (one << j)) == 0)
{
return i * size + j;
}
}
}
}
return values.Length;
}
Qu'avons-nous fait ici. Premièrement, la quantité de RAM nécessaire a été réduite de 64 fois.
var size = sizeof(ulong) * 8;
ulong[] sieve = new ulong[(max / size) + 1];
En conséquence, l'algorithme de tamis nous donne le résultat suivant :
- Pour le cas {0, 12, 4, 7, 1} : criblage : 8 itérations, criblage d'optimisation : 8 itérations
- Pour le cas {0, 1, 2, 3, 4} : criblage : 10 itérations, criblage d'optimisation : 11 itérations
- Pour le cas {11, ...} : tamisage : 108 itérations, tamisage avec optimisation : 108 itérations
- Pour le cas {0, ..., 999} : criblage : 2000 itérations, criblage avec optimisation : 1056 itérations
Alors, quel est le résultat final de la théorie de la vitesse ?
Nous avons transformé T (n * 3) en T (n * 2) + T (n / 64) dans son ensemble, augmenté légèrement la vitesse et même réduit la quantité de RAM jusqu'à 64 fois. Quoi bien)
3) Trier
Comme vous pouvez le deviner, le moyen le plus simple de trouver un élément manquant dans un ensemble est d'avoir un ensemble trié.
L'algorithme de tri le plus rapide est "quicksort", qui a une complexité de T1 (n log (n)). Et au total, on obtient la complexité théorique pour trouver MEX dans T1 (n log (n)) + T2 (n)
static int GetMEX(int[] values, ref int total)
{
total = values.Length * (int)Math.Log(values.Length);
values = values.OrderBy(x => x).ToArray();
for (int i = 0; i < values.Length - 1; i++)
{
total++;
if (values[i] + 1 != values[i + 1])
{
return values[i] + 1;
}
}
return values.Length;
}
Magnifique. Rien de plus.
Vérifier le nombre d'itérations
- Pour le cas {0, 12, 4, 7, 1} : tamisage avec optimisation : 8, tri : ~ 7 itérations
- Pour le cas {0, 1, 2, 3, 4} : tamisage avec optimisation : 11 itérations, tri : ~ 9 itérations
- { 11,…}: : 108 , : ~356
- { 0,…,999}: : 1056 , : ~6999
Ce sont des valeurs moyennes, et elles ne sont pas tout à fait justes. Mais en général : le tri ne nécessite pas de mémoire supplémentaire et permet clairement de simplifier la dernière étape de l'itération.
Note : values.OrderBy (x => x) .ToArray() - oui, je sais que de la mémoire a été allouée ici, mais si vous le faites à bon escient, vous pouvez changer le tableau, pas le copier...
J'ai donc eu un idée d'optimiser le tri rapide pour la recherche MEX. Je n'ai pas trouvé cette version de l'algorithme sur Internet, ni du point de vue des mathématiques, et encore plus du point de vue de la programmation. Ensuite, nous écrirons le code à partir de 0 en chemin, en indiquant à quoi il ressemblera : D
Mais d'abord, rappelons-nous comment le tri rapide fonctionne en général. Je donnerais un lien, mais il n'y a en fait pas d'explication normale de quicksort sur les doigts, il semble que les auteurs des manuels eux-mêmes comprennent l'algorithme tout en en parlant...
Voilà donc ce qu'est quicksort :
Nous avons un tableau non ordonné {0, 12, 4, 7 , 1}
Nous avons besoin d'un "nombre aléatoire", mais il est préférable de prendre l'un des tableaux - c'est ce qu'on appelle le numéro de référence (T).
Et deux pointeurs : L1 - regarde le premier élément du tableau, L2 regarde le dernier élément du tableau.
0, 12, 4, 7, 1
L1 = 0, L2 = 1, T = 1 (T a pris les derniers stupides)
Première étape d'itération :
Jusqu'à ce que nous travaillions uniquement avec le pointeur L1.
Déplacez-le le long du tableau vers la droite jusqu'à ce que nous trouvions un nombre supérieur à notre référence.
Dans notre cas, L1 est égal à 8. La
deuxième étape de l'itération :
Maintenant, nous déplaçons le pointeur L2
le long du tableau vers la gauche jusqu'à ce que nous trouvions un nombre inférieur ou égal à notre référence.
Dans ce cas, L2 est égal à 1. Puisque J'ai pris le numéro de référence égal à l'élément extrême du tableau et j'y ai également regardé L2.
La troisième étape de l'itération :
Changer les nombres dans les pointeurs L1 et L2, ne pas déplacer les pointeurs.
Et nous passons à la première étape de l'itération.
Nous répétons ces étapes jusqu'à ce que les pointeurs L1 et L2 soient égaux, non pas leurs valeurs, mais des pointeurs. Ceux. ils doivent pointer vers un élément.
Une fois que les pointeurs ont convergé sur un élément, les deux parties du tableau ne seront toujours pas triées, mais à coup sûr, d'un côté des "pointeurs fusionnés (L1 et L2)", il y aura des éléments inférieurs à T, et sur le autre, plus que T. À savoir, ce fait nous permet de diviser le tableau en deux groupes indépendants qui peuvent être triés dans des flux différents lors d'itérations ultérieures.
Un article sur le wiki, si je ne comprends pas ce qui est écrit
Écrivons Quicksort
static void Quicksort(int[] values, int l1, int l2, int t, ref int total)
{
var index = QuicksortSub(values, l1, l2, t, ref total);
if (l1 < index)
{
Quicksort(values, l1, index - 1, values[index - 1], ref total);
}
if (index < l2)
{
Quicksort(values, index, l2, values[l2], ref total);
}
}
static int QuicksortSub(int[] values, int l1, int l2, int t, ref int total)
{
for (; l1 < l2; l1++)
{
total++;
if (t < values[l1])
{
total--;
for (; l1 <= l2; l2--)
{
total++;
if (l1 == l2)
{
return l2;
}
if (values[l2] <= t)
{
values[l1] = values[l1] ^ values[l2];
values[l2] = values[l1] ^ values[l2];
values[l1] = values[l1] ^ values[l2];
break;
}
}
}
}
return l2;
}
Vérifions le nombre réel d'itérations :
- { 0, 12, 4, 7, 1 }: : 8, : 11
- { 0, 1, 2, 3, 4 }: : 11 , : 14
- { 11,…}: : 108 , : 1520
- { 0,…,999}: : 1056 , : 500499
Essayons de réfléchir à ce qui suit. Le tableau {0, 4, 1, 2, 3} n'a pas d'éléments manquants et sa longueur est de 5. Autrement dit, il s'avère qu'un tableau sans éléments manquants est égal à la longueur du tableau - 1. C'est-à-dire m = {0, 4, 1, 2, 3}, Longueur (m) == Max (m) + 1. Et le plus important en ce moment est que cette condition est vraie si les valeurs du tableau sont réarrangé. Et l'important est que cette condition puisse être étendue à des parties du tableau. A savoir, comme ceci :
{0, 4, 1, 2, 3, 12, 10, 11, 14} sachant que sur la partie gauche du tableau, tous les nombres sont inférieurs à un certain numéro de référence, par exemple 5, et à droite, tout ce qui est plus grand n'a pas de sens chercher le nombre minimum à gauche.
Ceux. si nous savons avec certitude que dans l'une des parties il n'y a pas d'éléments supérieurs à une certaine valeur, alors ce nombre manquant lui-même doit être recherché dans la deuxième partie du tableau. En général, c'est ainsi que fonctionne l'algorithme de recherche binaire.
En conséquence, j'ai eu l'idée de simplifier le tri rapide pour les recherches MEX en le combinant avec la recherche binaire. Laissez-moi vous dire tout de suite que nous n'aurons pas besoin de trier complètement l'ensemble du tableau, seulement les parties dans lesquelles nous allons rechercher.
En conséquence, nous obtenons le code
static int GetMEX(int[] values, ref int total)
{
return QuicksortMEX(values, 0, values.Length - 1, values[values.Length - 1], ref total);
}
static int QuicksortMEX(int[] values, int l1, int l2, int t, ref int total)
{
if (l1 == l2)
{
return l1;
}
int max = -1;
var index = QuicksortMEXSub(values, l1, l2, t, ref max, ref total);
if (index < max + 1)
{
return QuicksortMEX(values, l1, index - 1, values[index - 1], ref total);
}
if (index == values.Length - 1)
{
return index + 1;
}
return QuicksortMEX(values, index, l2, values[l2], ref total);
}
static int QuicksortMEXSub(int[] values, int l1, int l2, int t, ref int max, ref int total)
{
for (; l1 < l2; l1++)
{
total++;
if (values[l1] < t && max < values[l1])
{
max = values[l1];
}
if (t < values[l1])
{
total--;
for (; l1 <= l2; l2--)
{
total++;
if (values[l2] == t && max < values[l2])
{
max = values[l2];
}
if (l1 == l2)
{
return l2;
}
if (values[l2] <= t)
{
values[l1] = values[l1] ^ values[l2];
values[l2] = values[l1] ^ values[l2];
values[l1] = values[l1] ^ values[l2];
break;
}
}
}
}
return l2;
}
Vérifier le nombre d'itérations
- Pour le cas {0, 12, 4, 7, 1} : tamisage avec optimisation : 8, tri MEX : 8 itérations
- { 0, 1, 2, 3, 4 }: : 11 , MEX: 4
- { 11,…}: : 108 , MEX: 1353
- { 0,…,999}: : 1056 , MEX: 999
Nous avons différentes options de recherche MEX. Lequel est le meilleur dépend de vous.
Généralement. J'aime le plus le dépistage , et voici les raisons :
Il a un temps d'exécution très prévisible. De plus, cet algorithme peut être facilement utilisé en mode multithread. Ceux. divisez le tableau en parties et exécutez chaque partie dans un thread séparé :
for (int i = minIndexThread; i < maxIndexThread; i++)
sieve[values[i] / size] |= (one << (values[i] % size));
La seule chose dont vous avez besoin est de verrouiller lors de l'écriture de sieve [values [i] / size] . Et encore une chose - l'algorithme est idéal pour décharger les données de la base de données. Vous pouvez charger des packs de 1000 pièces, par exemple, dans chaque flux et cela fonctionnera toujours.
Mais si nous avons une grave pénurie de mémoire, le tri MEX semble clairement meilleur.
PS
J'ai commencé mon histoire avec un concours pour OZON auquel j'ai essayé de participer, en faisant une "version préliminaire" de l'algorithme de tamisage, je n'ai jamais reçu de prix pour cela, OZON l'a trouvé insatisfaisant ... Pour quelles raisons - il n'a jamais avoué . .. Et le code du gagnant je n'ai pas vu non plus. Quelqu'un peut-il avoir des idées sur la façon de mieux résoudre le problème de recherche MEX ?