L' algorithme de recherche de chaîne Boyer-Moore est un algorithme à usage général pour trouver une sous-chaîne dans une chaîne.
Essayons de trouver l'occurrence d'une sous-chaîne dans une chaîne.
Notre code source sera :
Text: somestring
Et le modèle que nous chercherons
Pattern: string
Mettons les index dans notre texte pour voir à quel index quelle lettre se trouve.
0 1 2 3 4 5 6 7 8 9
s o m e s t r i n g
Écrivons une méthode qui détermine si le motif est dans une chaîne. La méthode renverra l'index d'où le motif entre dans la chaîne.
int find (string text, string pattern){}
Dans notre exemple, il devrait renvoyer 4.
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
pattern: s t r i n g
Si aucune réponse n'est trouvée, nous retournerons -1
int find (string text, string pattern) {
int t = 0; .
int last = pattern.length — 1;
Créons une boucle pour parcourir le texte.
while (t < text.length — last)
? , . .
:
last = 5 ( string 5)
10 (somestring)
text.length — last = 10–5 = 5;
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
pattern: s t r i n g
, 5 , 4 , ,
0 1 2 3 4 5 6 7 8 9
text: s o m e X t r i n g
^
pattern: s t r i n g
, .
:
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last){
}
}
int p = 0, .
while( p <= last && text[ t + p ] == pattern[p] ){
}
p <= last —
text[ t + p ] = pattern[p] — .
, text[ t + p ] = pattern[p]
4
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
^
pattern: s t r i n g
t = 4, p = 0; text[ t + p ] = text[ 4 + 0 ] = s, pattern[0] = s, .
:
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = 0;
while( p <= last && text[ t + p ] = pattren[p] ){
, p .
p ++;
}
p == pattern.length
.
if (p == pattern.length){
return t;
}
.
t ++;
}
}
:
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = 0;
while( p <= last && text[ t + p ] == pattern[p] ) {
p ++;
}
if (p == pattern.length) {
return t;
}
t ++;
}
return — 1;
}
? ?
, .
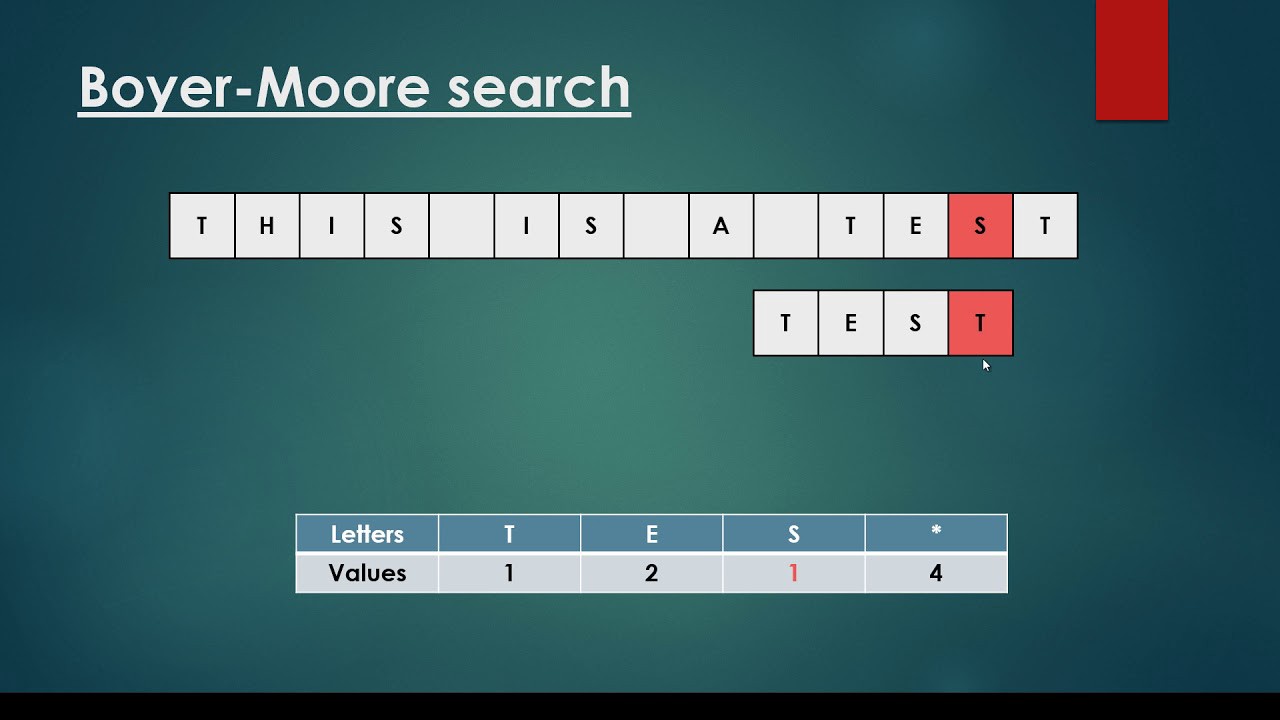
text: some*string , ?
?
,
text: somestring
^
pattern: string
^
. , ?
, .
text: somestring
pattern: string
.
text: somestring
^
pattern: string
^
pattern[i] = ‘g’, text[i] = ’t’,
pattern.length — ’t’ .
’t’ = 1, 5–1 = 4, 4 .
text: somestring
^
pattern: >>>>string
^
.
, .
, . * .
:
s 0
t 1
r 2
i 3
n 4
g 5
* -1
, , , :
pattern:
4
2 — ,
-1
-1
5
, , .
:
int[] createOffsetTable(string pattern) {
int[] offset = new int[128]; //
//
for (int i = 0; i < prefix.length; i++){
offset[i] = -1; //
}
for (int i = 0; i < pattern.length; i++){
offset[pattern[i]] = i;
}
return offset;
}
, :
int find (string text, string pattern) {
int[] offset = createOffsetTable(pattern);
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last){
int p = last; //
// ,
//
while( p >= 0 && text[ t + p ] == pattern[p] ){
p — ;
}
if (p == -1){
return t;
}
t += last — offset[ text[ t + last ] ];
}
return — 1;
}
t + last ? . , , + .
:
:
= 4
= 2
= 5
1:
0 1 2 3 4 5 6 7 8 9 10
text:
pattern:
last = 7;
t += last — offset[text[t + last]]
t += last — offset[text[0 + 7]]
t += last — offset[‘’]
t += 7–5 = 2;
t = 2;
2:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text:
pattern: > >
t = 2;
t += last — offset[text[t + last]]
t += last — offset[text[2 + 7]]
t += last — offset[‘’]
t += 7–5 = 2;
t = 4;
3:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text:
pattern: > > > >
t = 4;
t += last — offset[text[t + last]]
t += last — offset[text[4 + 7]]
t += last — offset[‘’]
t += 7–5 = 2;
t = 6;
4:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text:
pattern: > > > > > >
t = 6;
t += last — offset[text[t + last]]
t += last — offset[text[6 + 7]]
t += last — offset[‘’]
t += 7–5 = 2;
t = 8;
5:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text:
pattern: > > > > > > > >
.
- .
. ?
abcdadcd
. .
d, ? . 2 d 2 4. 2 .
4
-----—
| 2
| ---
| | |
abcdadcd
^
cd. d 2.
2
abcdadcd
cd,
-- 4 .
= 4.
842
abcdadcd
dcd. dcd .
--- = 8
8, .
.
* *, c , 1.
1
*
—
41
*
-—
441
*
--—
4441
*
---—
4441
*
----
Pour Okol, nous écrivons également le 4 . Parce que notre préfixe est le même que le suffixe.
Essayons d'écrire le code pour cela
createSuffix(string pattern){
int[] suffix = new int[pattern.length + 1]; // +1
for(int i = 0; i < pattern.length; i ++){
suffix[i] = pattern.length; // ,
// .
}
suffix[pattern.length] = 1; // 1
// , .
for (int i = pattern.length — 1; i >= 0; i — ) {
for (int at = i; at < pattern.lenth; at ++){
string s = pattern.substring(at); //
Par exemple, avec quoi comparer la cloche ?
--—
--—
---
---
---
, , ,
for (int j = at — 1; j >= 0; j — ) {
string p = pattern.substring(j, s.length); //
//
if (p.equals(s)) {
suffix[j] = at — i;
break;
}
}
}
}
return suffix;}
Il existe un algorithme plus optimal, mais plus individuellement.
Quel code avons-nous en ce moment ?
int[] createSuffix (string pattern) {
int[] suffix = new int[pattern.length + 1];
for (int i = 0; i < pattern.length; i ++){
suffix[i] = pattern.length;
}
suffix[pattern.length] = 1;
for (int i = pattern.length — 1; i >=0; i — ){
for(int at = i; i < pattern.length; i ++){
string s = pattern.substring(at);
for (int j = at — 1; j >= 0; j — ){
string p = pattern.substring(j, s.length);
if (p == s) {
suffix[i] = at — 1;
at = pattern.length;
break;
}
}
}
}
return suffix;
}
int find(string text, string pattern) {
int[] offset = createOffset(pattern);
int[] suffix = createSuffix(pattern);
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = last;
while (p >= 0 && text[t + p] == pattern[p]) {
p — ;
}
if (p == -1) {
return t;
}
t += Math.max (p — offset[text[t + p]], suffix[p + 1]);
}
return -1;
}
p - préfixe [texte [t + p]] - le dernier caractère trouvé et ajuster le décalage de notre modèle pour cela
suffix [p + 1] - La valeur du suffixe du dernier élément comparé.
Et on passe à la valeur maximale afin d'aller le plus vite possible.
Ceci conclut l'analyse de l'algorithme de Boyer-Moore. Merci pour l'attention! =)