
principaux fournisseurs de cloud connectent des disques virtuels à des serveurs physiques dédiés. Mais si vous regardez dans le système d'exploitation du serveur, il y aura un disque physique avec le nom du fournisseur dans le champ "fabricant". Aujourd'hui, nous allons analyser comment cela est possible.
Qu'est-ce que la carte réseau intelligente ?
Au cœur de cette « magie » se trouvent les cartes réseau à puce (Smart NIC). Ces cartes réseau ont leur propre processeur, RAM et stockage. En fait, il s'agit d'un mini-serveur réalisé sous la forme d'une carte PCIe. La tâche principale des cartes à puce est de décharger le processeur des opérations d'E/S.
Dans cet article, nous parlerons d'un périphérique spécifique - NVIDIA BlueField 2. NVIDIA appelle de tels périphériques DPU (Data Processing Unit), dont le but est, selon le fabricant, de "libérer" le processeur central de diverses tâches d'infrastructure - stockage, mise en réseau , la sécurité de l'information et même la gestion des hôtes.
Nous avons à notre disposition un appareil qui ressemble à une carte réseau 25GE ordinaire, mais il dispose d'un processeur ARM Cortex-A72 à huit cœurs avec 16 Go de RAM et 64 Go de mémoire eMMC permanente.
De plus, les connecteurs Mini-USB, NC-SI et RJ-45 sont visibles. Le premier connecteur est destiné uniquement au débogage et n'est pas utilisé dans les solutions de produit. NC-SI et RJ-45 vous permettent de vous connecter au module BMC du serveur via les ports de carte.
Assez de théorie, il est temps de se lancer.
Premier démarrage
Après l'installation de la carte réseau, le premier démarrage du serveur sera anormalement long. Le fait est que le micrologiciel UEFI du serveur interroge les périphériques PCIe connectés et que la carte réseau à puce bloque ce processus jusqu'à ce qu'il démarre lui-même. Dans notre cas, le processus de démarrage du serveur a pris environ deux minutes.
Après avoir démarré le système d'exploitation du serveur, vous pouvez voir deux ports de la carte réseau à puce.
root@host:~# lspci 98:00.0 Ethernet controller: Mellanox Technologies MT42822 BlueField-2 integrated ConnectX-6 Dx network controller (rev 01) 98:00.1 Ethernet controller: Mellanox Technologies MT42822 BlueField-2 integrated ConnectX-6 Dx network controller (rev 01) 98:00.2 DMA controller: Mellanox Technologies MT42822 BlueField-2 SoC Management Interface (rev 01)
À ce stade, la carte réseau à puce se comporte comme une carte normale. Pour interagir avec la carte, vous devez télécharger et installer les pilotes BlueField à partir de la page NVIDIA DOCA SDK . A la fin du processus, le programme d'installation vous invitera à redémarrer le service openibd afin que les pilotes installés soient chargés. Redémarrez :
/etc/init.d/openibd restart
Si tout a été fait correctement, une nouvelle interface réseau tmfifo_net0 apparaîtra dans le système d'exploitation .
root@host:~# ifconfig tmfifo_net0 tmfifo_net0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet6 fe80::21a:caff:feff:ff02 prefixlen 64 scopeid 0x20<link> ether 00:1a:ca:ff:ff:02 txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 13 bytes 1006 (1.0 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Par défaut, BlueField est 192.168.100.2/24, nous attribuons donc 192.168.100.1/24 à l'interface tmfifo_net0. Ensuite, nous démarrons le service rshim et le mettons en chargement automatique.
systemctl enable rshim systemctl start rshim
Après cela, l'accès à l'OS de la carte depuis le serveur est possible de deux manières :
- via l'interface SSH et tmfifo_net0 ;
- via la console - le caractère device /dev/rshim0/console .
La deuxième méthode fonctionne quel que soit l'état du système d'exploitation de la carte.
D'autres méthodes de connexion à distance à l'OS de la carte sont également possibles, qui ne nécessitent pas d'accès au serveur sur lequel la carte est installée :
- via SSH via un port de gestion hors bande 1GbE ou via des interfaces de liaison montante (y compris celles avec prise en charge du démarrage PXE) ;
- accès à la console via un port RS232 dédié ;
- Interface RSHIM via port USB dédié.
Vue intérieure
Maintenant que nous avons eu accès à l'OS de la carte, il est possible d'être surpris par le fait qu'il y ait un serveur plus petit à l'intérieur de notre serveur. L'image du système d'exploitation préinstallée sur la carte contient tous les logiciels dont vous avez besoin pour gérer la carte et, semble-t-il, même plus. La carte réseau contient une distribution Linux à part entière, dans notre cas, Ubuntu 20.04.
Si nécessaire, il est possible d'installer n'importe quel kit de distribution Linux sur la carte réseau prenant en charge l'architecture aarch64 (ARMv8) et UEFI. Si vous êtes connecté via la console, appuyez sur ESC pendant le chargement de la carte pour accéder à son propre utilitaire de configuration UEFI. Il y a inhabituellement peu de paramètres ici, par rapport à l'homologue du serveur.
Le système d'exploitation sur BlueField 2 peut être chargé à l'aide de PXE et l'utilitaire de configuration UEFI vous permet de personnaliser l'ordre de démarrage. Imaginez : la carte réseau PXE s'initialise d'abord, puis le serveur !

Il a donc été découvert que le docker est disponible par défaut dans le système d'exploitation, bien qu'il semble que cela soit redondant pour une carte réseau. Cependant, si nous parlons de redondance, nous avons installé la JVM à partir du gestionnaire de packages et lancé le serveur Minecraft sur la carte réseau. Bien qu'aucun test sérieux n'ait été effectué, il est assez confortable de jouer sur le serveur avec une petite entreprise.
Le système d'exploitation de la carte réseau affiche de nombreuses interfaces réseau :
ubuntu@bluefield:~$ ifconfig | grep -E '^[^ ]' docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 oob_net0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 p0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 p1: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 p0m0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 p1m0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 pf0hpf: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 pf0sf0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 pf1hpf: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 pf1sf0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 tmfifo_net0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
Les interfaces tmfifo_net0 , lo et docker0 que nous connaissons déjà. L'interface oob_net0 correspond au port de gestion hors bande RJ-45. Les autres interfaces sont connectées à des ports optiques :
- pX - dispositif de représentation du port physique de la carte ;
- pfXhpf est une fonction physique de l'hôte, une interface accessible à l'hôte ;
- pfXvfY - représentation de la fonction virtuelle hôte (Host Virtual Function), interfaces virtuelles utilisées pour virtualiser SR-IOV sur l'hôte ;
- pXm0 est une interface de sous-fonction PCIe spéciale qui est utilisée pour communiquer entre la carte et le port. Cette interface peut être utilisée pour accéder à la carte au réseau ;
- pfXsf0 - Représentation de la sous-fonction PCIe de l'interface pXm0.
La façon la plus simple de comprendre le but des interfaces est à partir du schéma :

interfaces BlueField 2 à l' hôte (source NVIDIA) Les interfaces sont directement connectées au commutateur virtuel, qui est implémenté dans BlueField 2. Mais nous en reparlerons dans un autre article. Dans le même article, nous souhaitons examiner l'émulation NVMe, qui vous permet de connecter un stockage défini par logiciel (SDS) à des serveurs dédiés en tant que disques physiques. Cela vous permettra d'utiliser tous les avantages du SDS sur le bare metal.
Configuration de l'émulation NVMe
Par défaut, le mode d'émulation NVMe est désactivé. Nous l' activons avec la commande mlxconfig .
mst start # mlxconfig -d 03:00.0 s INTERNAL_CPU_MODEL=1 PF_BAR2_ENABLE=0 PER_PF_NUM_SF=1 mlxconfig -d 03:00.0 s PF_SF_BAR_SIZE=8 PF_TOTAL_SF=2 mlxconfig -d 03:00.1 s PF_SF_BAR_SIZE=8 PF_TOTAL_SF=2 # NVMe mlxconfig -d 03:00.0 s NVME_EMULATION_ENABLE=1 NVME_EMULATION_NUM_PF=1
Après avoir activé le mode d'émulation NVMe, vous devez redémarrer la carte. La configuration de l'émulation NVMe se résume en deux étapes :
- Configuration du SPDK.
- Configuration de snap_mlnx.
Pour le moment, seules deux méthodes d'accès au stockage distant ont été officiellement annoncées : NVMe-oF et iSCSI. Et seul NVMe-oF a une accélération matérielle. Cependant, il est également possible d'utiliser d'autres protocoles. Notre intérêt est de connecter le référentiel ceph.
Malheureusement, il n'y a pas de support prêt à l'emploi pour rbd. Par conséquent, pour vous connecter au stockage ceph, vous devez utiliser le module noyau rbd, qui créera le périphérique bloc /dev/rbdX . Et la pile pour l'émulation NVMe, à son tour, fonctionnera avec un périphérique de bloc.
Tout d'abord, vous devez indiquer où se trouve le stockage, que nous représenterons comme NVMe. Cela se fait via les arguments du script spdk_rpc.py... Pour la persistance lors des redémarrages de la carte, les commandes sont écrites dans /etc/mlnx_snap/spdk_rpc_init.conf .
Pour connecter un périphérique bloc, utilisez la commande bdev_aio_create <path to block device> <name> <block size in bytes> . Le paramètre <nom> est utilisé plus tard dans les paramètres, et il ne doit pas nécessairement être le même que le nom du périphérique de bloc. Par example:
bdev_aio_create /dev/rbd0 rbd0 4096
Pour une connexion directe du périphérique rbd, il est nécessaire de recompiler SPDK et mlnx_snap avec le support rbd. Nous avons compilé les exécutables avec le support rbd du support technique. Pour nous connecter, nous avons utilisé la commande bdev_rbd_create <pool name> <rbd name> <block size in bytes> . Cette commande ne vous permet pas de définir le nom du périphérique, mais le propose lui-même et l'affiche une fois terminé. Dans notre cas, Ceph0. Le nom de l'appareil doit être mémorisé, nous en aurons besoin dans une configuration ultérieure.
Bien que la décision de connecter rbd via un module du noyau et d'utiliser un périphérique bloc au lieu d'utiliser directement rbd semble être une décision quelque peu incorrecte, il s'est avéré que c'est le cas lorsque les "béquilles" fonctionnent mieux que la solution "intelligente". Lors des tests de performances, il s'est avéré que la solution "correcte" était plus lente.Ensuite, vous devez configurer la vue que l'hôte verra. La configuration se fait via snap_rpc.py , et les commandes sont enregistrées dans /etc/mlnx_snap/snap_rpc_init.conf . Tout d'abord, nous créons un lecteur avec la commande suivante.
subsystem_nvme_create <NVMe Qualified Name (NQN)> < > <>
Ensuite, nous créons un contrôleur.
controller_nvme_create <NQN> < > -c < > --pf_id 0
Le gestionnaire d'émulation est le plus souvent appelé mlx5_x . Si vous n'utilisez pas l'accélération matérielle, vous pouvez utiliser la première qui rencontre , c'est-à-dire mlx5_0 . Après avoir exécuté cette commande, le nom du contrôleur sera affiché. Dans notre cas - NvmeEmu0pf0 .
Enfin, ajoutez un espace de noms (NVMe Namespace) au contrôleur créé.
controller_nvme_namespace_attach < > < > -c < >
Nous avons toujours le type de périphérique spdk , nous avons obtenu l'ID de périphérique à l'étape de configuration de spdk et le nom du contrôleur à l'étape précédente. En conséquence, le fichier /etc/mlnx_snap/snap_rpc_init.conf ressemble à ceci :
subsystem_nvme_create nqn.2020-12.mlnx.snap SSD123456789 "Selectel ceph storage" controller_nvme_create nqn.2020-12.mlnx.snap mlx5_0 --pf_id 0 -c /etc/mlnx_snap/mlnx_snap.json controller_nvme_namespace_attach -c NvmeEmu0pf0 spdk Nvme0n10 1
Redémarrez le service mlnx_snap :
sudo service mlnx_snap restart
Si tout est configuré correctement, le service démarrera. Sur l'hôte NVMe, le disque n'apparaîtra pas seul. Vous devez recharger le module du noyau nvme.
sudo rmmod nvme
sudo modprobe nvme
Et ainsi, notre disque physique virtuel est apparu sur l'hôte.
root@host:~# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 SSD123456789 Selectel ceph storage 1 515.40 GB / 515.40 GB 4 KiB + 0 B 1.0
Nous avons maintenant un disque virtuel présenté au système comme un disque physique. Vérifions-le sur les tâches habituelles pour les disques physiques.
Essai
Tout d'abord, nous avons décidé d'installer l'OS sur un disque virtuel. Le programme d'installation de CentOS 8 a été utilisé. Il a vu le disque sans aucun problème.

installation a été effectuée comme d'habitude. Nous vérifions le chargeur de démarrage CentOS dans l'utilitaire de configuration UEFI.
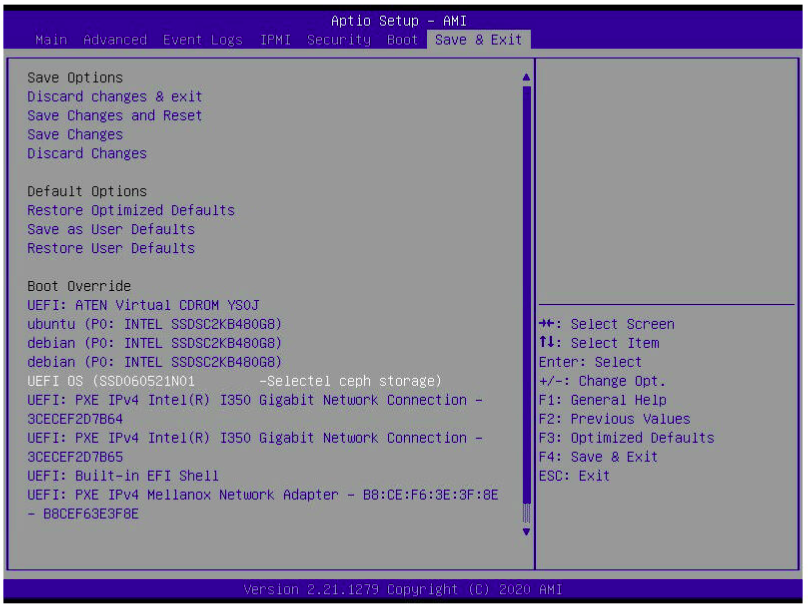
Nous avons démarré dans le CentOS installé et nous nous sommes assurés que la racine FS se trouve sur le disque NVMe.
[root@localhost ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 447.1G 0 disk |-sda1 8:1 0 1M 0 part |-sda2 8:2 0 244M 0 part |-sda3 8:3 0 977M 0 part `-sda4 8:4 0 446G 0 part `-vg0-root 253:3 0 446G 0 lvm sdb 8:16 0 447.1G 0 disk sr0 11:0 1 597M 0 rom nvme0n1 259:0 0 480G 0 disk |-nvme0n1p1 259:1 0 600M 0 part /boot/efi |-nvme0n1p2 259:2 0 1G 0 part /boot `-nvme0n1p3 259:3 0 478.4G 0 part |-cl-root 253:0 0 50G 0 lvm / |-cl-swap 253:1 0 4G 0 lvm [SWAP] `-cl-home 253:2 0 424.4G 0 lvm /home
[root@localhost ~]# uname -a Linux localhost.localdomain 4.18.0-305.3.1.el8.x86_64 #1 SMP Tue Jun 1 16:14:33 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Nous avons également testé le disque émulé avec l'utilitaire fio. Voici ce qui s'est passé.
| Test | AIO bdev, IOPS | Ceph RBD bdev, IOPS |
|---|---|---|
| randread, 4k, 1 | 1 329 | 849 |
| écriture aléatoire, 4k, 1 | 349 | 326 |
| lecture, 4k, 32 | 15 100 | 15 000 |
| écriture aléatoire, 4k, 32 | 9445 | 9 712 |
Conclusion
Les cartes réseau « intelligentes » sont une véritable magie technique qui permet non seulement de décharger le processeur central des opérations d'E/S, mais aussi de le « tromper », en présentant un lecteur distant comme local.
Cette approche vous permet de tirer parti du stockage défini par logiciel sur des serveurs dédiés : d'un simple clic, transférez des disques entre serveurs, redimensionnez, prenez des instantanés et déployez des images prêtes à l'emploi des systèmes d'exploitation en quelques secondes.
