Nous continuons à nous familiariser avec différents tas et algorithmes de tri utilisant ces tas. Aujourd'hui, nous avons le soi-disant arbre des tournois.
L'idée principale du tri Tournoi est d'utiliser un tas auxiliaire relativement petit (par rapport au tableau principal), qui agit comme une file d'attente prioritaire. Dans ce tas, les éléments aux niveaux inférieurs sont comparés, à la suite de quoi les éléments plus petits (dans ce cas, l'arbre que nous avons MIN-HEAP) monte, et le minimum actuel de la partie des éléments du tableau qui sont tombés dans ce tas flotte jusqu'à la racine. Le minimum est transféré à un tableau supplémentaire de "gagnants", à la suite de quoi les éléments restants sont comparés / déplacés dans le tas - et maintenant un nouveau minimum est à la racine de l'arbre. Notez qu'avec un tel système, le minimum suivant a une valeur plus grande que le précédent - alors un nouveau tableau ordonné de "gagnants" est facilement assemblé, où de nouveaux minimums sont simplement ajoutés à la fin du tableau supplémentaire.
EDISON .
, . , .
computer science ;-)


Déplacer les minimums vers un tableau supplémentaire conduit au fait que des postes vacants apparaissent dans le tas pour les éléments suivants du tableau principal - à la suite de quoi tous les éléments sont traités dans l'ordre de la file d'attente.
La principale subtilité est qu'en plus des «gagnants», il y a aussi des «perdants». Si certains éléments ont déjà été transférés dans le tableau des "gagnants", alors si les éléments non traités sont plus petits que ces "gagnants", il ne sert à rien de les passer au crible à ce stade - insérer ces éléments dans le tableau des "gagnants" sera trop coûteux (en Vous ne pouvez pas les terminer, mais pour les mettre au début, vous devez décaler les minimums insérés précédemment). Les éléments qui n'ont pas réussi à s'intégrer dans le tableau des «gagnants» sont envoyés au tableau des «perdants» - ils passeront par l'arborescence du tournoi dans l'une des itérations suivantes, lorsque toutes les actions seront répétées pour les perdants restants.
Il n'est pas facile de trouver une implémentation de cet algorithme sur Internet, mais une implémentation claire et agréable dans Ruby a été trouvée sur YouTube. Le code Java est également mentionné dans la section "Liens", mais il n'y paraît pas si lisible.
#
require_relative "pqueue"
#
MAX_SIZE = 16
def tournament_sort(array)
# , ""
return optimal_tourney_sort(array) if array.size <= MAX_SIZE
bracketize(array) # , ""
end
#
def bracketize(array)
size = array.size
pq = PriorityQueue.new
#
pq.add(array.shift) until pq.size == MAX_SIZE
winners = [] # ""
losers = [] # ""
#
until array.empty?
# "" ?
if winners.empty?
# ""
winners << pq.peek
#
pq.remove
end
# , ""
if array.first > winners.last
pq.add(array.shift) #
else # ""
losers << array.shift # ""
end
# , ""
winners << pk.peek unless pk.peek.nil?
pq.remove #
end
# , - ?
until pq.heap.empty?
winners << pq.peek # ""
pq.remove #
end
# "" , , ,
# "" -
return winners if losers.empty?
# , ""
# ""
array = losers + winners
array.pop while array.size > size
bracketize(array) #
end
#
def optimal_tourney_sort(array)
sorted_array = [] #
pq = PriorityQueue.new
array.each { |num| pq.add(num) } # -
until pq.heap.empty? # -
sorted_array << pq.heap[0]
pq.remove #
end
sorted_array #
end
#
if $PROGRAM_NAME == __FILE__
#
shuffled_array = Array.new(30) { rand(-100 ... 100) }
#
puts "Random Array: #{shuffled_array}"
#
puts "Sorted Array: #{tournament_sort(shuffled_array)}"
endIl s'agit d'une implémentation naïve, dans laquelle, après chaque division en «perdants» et «gagnants», ces tableaux sont combinés, puis toutes les actions sont répétées à nouveau pour le tableau combiné. Si les éléments «perdants» iront en premier dans le tableau combiné, alors le tri dans la pile du tournoi les triera avec les «gagnants».

Cette implémentation est assez simple et intuitive, mais vous ne pouvez pas l'appeler efficace. Les "gagnants" triés passent plusieurs fois dans l'arbre du tournoi, ce qui est évidemment redondant. Je suppose que la complexité temporelle ici est log-quadratique,
Option de fusion multichemin
L'algorithme est sensiblement accéléré si les éléments ordonnés passant à travers le tamis ne sont pas passés à plusieurs reprises dans les courses du tournoi.
Une fois que le tableau non ordonné est divisé en "gagnants" triés et "perdants" non triés, l'ensemble du processus est répété uniquement pour les "perdants". À chaque nouvelle itération, un ensemble de tableaux avec des "gagnants" sera accumulé et cela continuera jusqu'à ce qu'à un moment donné il ne reste plus de "perdants". Après cela, il ne reste plus qu'à fusionner tous les tableaux de «gagnants». Étant donné que ces tableaux sont tous triés, cette fusion se déroule avec un effort minimal.

Sous cette forme, l'algorithme peut déjà trouver une application utile. Par exemple, si vous devez travailler avec du Big Data, alors tout au long du processus d'utilisation du tas de tournoi, des paquets de données commandées seront publiés avec lesquels vous pouvez déjà faire quelque chose pendant que tout le reste est en cours de traitement.
Chacun des n éléments du tableau ne traverse l'arborescence du tournoi qu'une seule fois, ce qui coûte
Dans la finale de la saison
La série sur les sortes de tas est presque terminée. Reste à parler des plus efficaces d'entre eux.
Liens
:
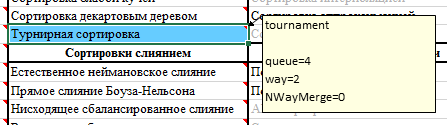
Le tri d'aujourd'hui a été ajouté à l'application AlgoLab, qui l'utilise - mettre à jour le fichier Excel avec des macros.
Dans les commentaires de la cellule avec le nom du tri, vous pouvez spécifier certains paramètres.
La manière variable est un arbre de tournois à plusieurs voies (juste au cas où, il est possible de rendre cet arbre non seulement binaire, mais aussi ternaire, quaternaire et pentaire).
La variable de file d'attente est la taille de la file d'attente d'origine (le nombre de nœuds au niveau le plus bas de l'arborescence). Étant donné que les arborescences sont pleines, si, par exemple, avec way = 2, spécifiez queue = 5, la taille de la file d'attente sera augmentée à la puissance la plus proche de deux (dans ce cas, jusqu'à 8).
Variable NWayMerge prend la valeur 1 ou 0 - il indique s'il faut utiliser une fusion par trajets multiples ou non.