La note décrit une expérience pour créer une petite copie d'un entrepôt de données d'entreprise avec des spécifications très limitées. À savoir, basé sur un ordinateur monocarte Raspberry Pi.
Le modèle et l'architecture seront simplifiés, mais similaires au stockage d'entreprise. Le résultat est une évaluation de la possibilité d'utiliser le Raspberry Pi dans le domaine du traitement et de l'analyse des données.

# 1
Le rôle d'un acteur expérimenté et fort sera joué par le véhicule Exadata X5 (une unité) de la société Oracle.
Le processus de traitement des données comprend les étapes suivantes:
- Lecture à partir d'un fichier de 10,3 Go - 350 millions d'enregistrements en 90 minutes.
- Traitement et nettoyage des données - 2 requêtes SQL et 15 minutes (avec cryptage des données personnelles 180 minutes).
- Chargement des mesures - 10 minutes.
- Téléchargement de tables de faits avec 20 millions de nouveaux enregistrements - 5 requêtes SQL et 35 minutes.
Intégration totale de 350 millions d'enregistrements en 2,5 heures, ce qui équivaut à 2,3 millions d'enregistrements par minute, soit environ 39 000 enregistrements de données sources par seconde.
# 2
L'adversaire expérimental sera le Raspberry Pi 3 Model B + avec un processeur 4 cœurs 1,4 GHz.
Sqlite3 est utilisé comme stockage, les fichiers sont lus en utilisant PHP. Les fichiers et la base de données se trouvent sur une carte SD de classe 10 de 32 Go dans un lecteur intégré. La sauvegarde est créée sur un lecteur flash de 64 Go connecté à USB.
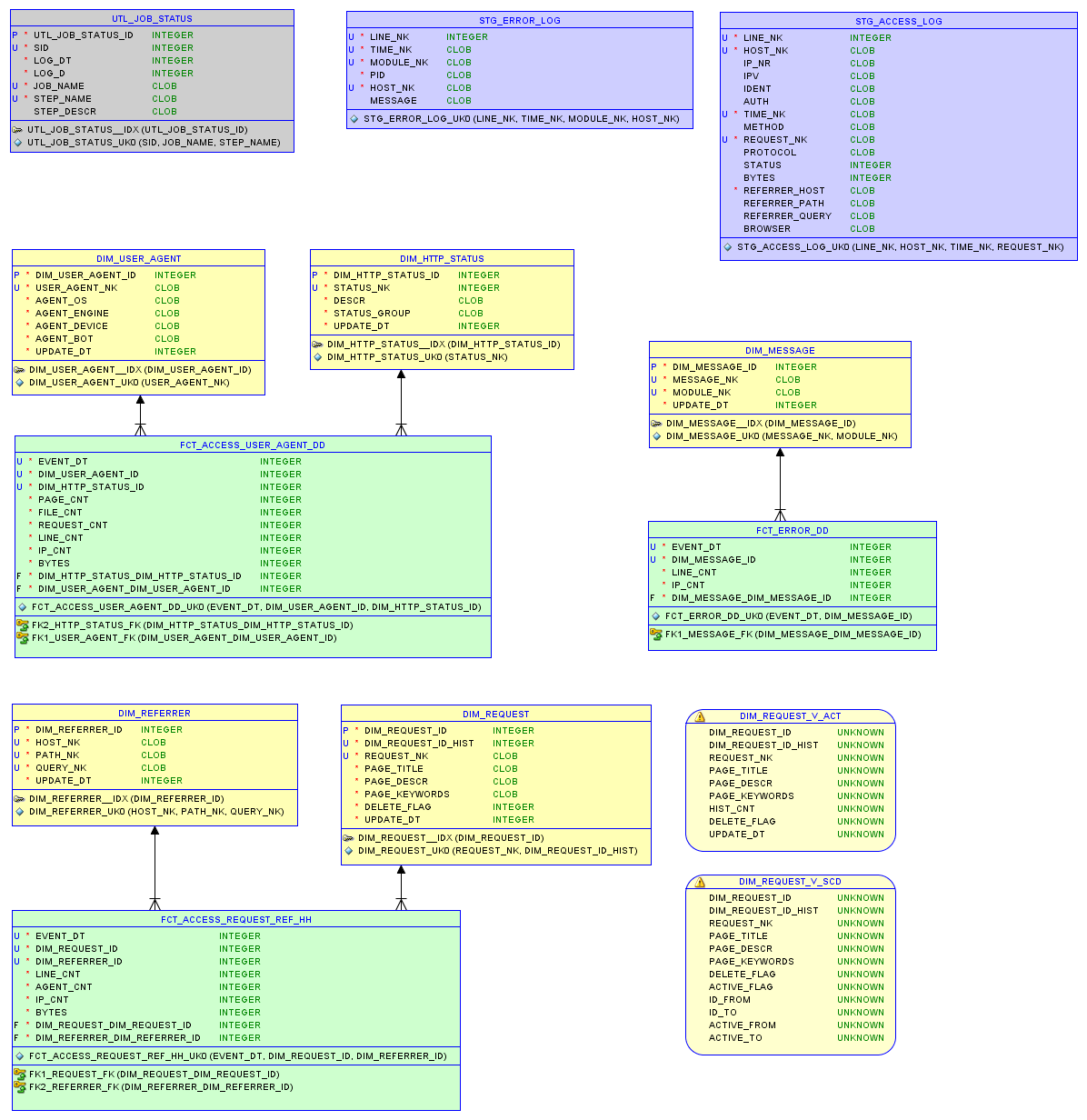
Le modèle de données dans la base de données relationnelle sqlite3 et les rapports sont décrits dans l' article sur le petit stockage .
Modèle de données
Tester un
Le fichier source access.log fait 37 Mo avec 200 000 entrées.
- Il a fallu 340 secondes pour lire le journal et écrire dans la base de données.
- Le chargement des mesures avec 5 000 enregistrements a duré 5 secondes.
- Chargement des tables de faits avec 90 000 nouveaux enregistrements - 32 secondes.
Au total , l'intégration de 200 000 enregistrements a pris près de 7 minutes, ce qui équivaut à 28 000 enregistrements par minute ou 470 enregistrements de données brutes par seconde. La base de données occupe 7,5 Mo; Seulement 8 requêtes SQL pour le traitement des données.
Test seconde
Fichier de site plus actif. Le fichier original access.log fait 67 Mo avec 290 Ko d'entrées.
- Il a fallu 670 secondes pour lire le journal et écrire dans la base de données.
- Le chargement des mesures avec 25 000 enregistrements a pris 8 secondes.
- Chargement des tables de faits avec 240 000 nouveaux enregistrements - 80 secondes.
Au total , l'intégration de 290 000 enregistrements a pris un peu plus de 12 minutes, ce qui équivaut à 23 000 enregistrements par minute ou 380 enregistrements de données sources par seconde. La base de données occupe 22,9 Mo
Production
Pour obtenir des données sous la forme d'un modèle qui permettra une analyse efficace, des ressources informatiques et matérielles importantes sont nécessaires, et du temps en tout cas.
Par exemple, une unité Exadata coûte plus de 100K. Un Raspberry Pi coûte 60 unités.
Ils ne peuvent pas être comparés linéairement, car Avec l'augmentation des volumes de données et des exigences de fiabilité, des difficultés surgissent.
Cependant, si vous imaginez le cas où un millier de Raspberry Pi travaillent en parallèle, alors, sur la base de l'expérience, ils traiteront environ 400000 enregistrements de données sources par seconde.
Et si la solution pour Exadata est optimisée à 60 ou 100 000 enregistrements par seconde, c'est nettement moins de 400 000. Cela confirme le sentiment intérieur que les prix des solutions d'entreprise sont trop élevés.
Dans tous les cas, le Raspberry Pi est excellent pour gérer les données et les modèles relationnels de l'échelle appropriée.
Lien
Le Raspberry Pi domestique a été configuré en tant que serveur Web. Je décrirai ce processus dans le prochain post.
Vous pouvez tester vous-même les performances du Raspberry Pi et du fichier access.log sur . Le modèle de base de données (DDL), les procédures de chargement (ETL) et la base de données elle-même peuvent y être téléchargés. L'idée est de se faire rapidement une idée de l'état du site à partir du journal avec les données des dernières semaines.
Modifications
Grâce aux commentaires, le bogue de chargement du fichier Exadata a été corrigé et les numéros dans la note ont été corrigés. Sqlloader est utilisé pour la lecture, certains bogues ont supprimé les paramètres BINDSIZE et ROWS. En raison du démarrage instable du lecteur distant, la méthode conventionnelle a été choisie à la place du chemin direct, ce qui pourrait augmenter la vitesse de 30 à 50% supplémentaires.