Conseils pour séparer les distractions des informations utiles

Si vous suivez un cours d'introduction aux statistiques, vous vous rendrez compte que les données peuvent être utilisées pour trouver l'inspiration ou tester la théorie, mais jamais pour les deux. Pourquoi donc?
Les gens sont trop bons pour trouver des modèles dans tout. Vous déterminez vous-même quels modèles existent réellement et lesquels sont inventés. Nous sommes des créatures qui trouvent le visage d'Elvis dans une croustille. Si vous êtes tenté d'assimiler des modèles à des concepts, n'oubliez pas qu'il existe trois types de modèles:
- Modèles qui existent à la fois dans votre ensemble de données et au-delà.
- Modèles qui n'existent que dans votre ensemble de données.
- Des motifs qui n'existent que dans votre imagination (apophénie).
Les modèles de données peuvent exister (1) dans toute la population d'intérêt, (2) seulement dans un échantillon, ou (3) seulement dans votre tête.
Quels modèles et modèles de données peuvent vous être utiles? Cela dépend de vos objectifs.
Inspiration
Si vous avez besoin d'une pure inspiration, les données peuvent faire des merveilles. Même l'apophénie (la tendance humaine à percevoir à tort les connexions et le sens entre des choses sans rapport) peut faire fonctionner votre créativité au maximum. La créativité n'a pas de bonnes réponses, il vous suffit donc de regarder vos données et de jouer avec. En prime, essayez de ne pas perdre trop de temps (le vôtre ou ceux qui sont intéressés) en vain.
Les faits
Lorsque votre gouvernement souhaite collecter des impôts auprès de vous, il ne peut ignorer les valeurs qui vont au-delà de vos données financières pour l'année. Le service fiscal doit prendre une décision factuelle sur le montant que vous devez et la principale façon de prendre cette décision est d'analyser les données de l'année dernière. En d'autres termes, regardez les données et appliquez la formule. Dans ce cas, nous parlons d'analyses purement descriptives liées aux données disponibles. N'importe lequel des deux premiers types de motifs est bien adapté pour cela.
Analyse descriptive liée aux données existantes.
(Je n'ai jamais caché mes états financiers, mais je pense que le gouvernement des États-Unis ne serait pas ravi si j'utilisais les méthodes de calcul des données que j'ai apprises au lycée pour payer des impôts statistiquement pour les remplacer.)
Des décisions face à l'incertitude
Parfois, les faits disponibles ne correspondent pas à ceux souhaités. Lorsque vous ne disposez pas de toutes les informations nécessaires pour prendre une décision, vous devez naviguer dans l'incertitude, en essayant de choisir un plan d'action raisonnable.
C'est précisément ce que sont les statistiques - la science de la façon de changer d'avis face à l'incertitude. Le jeu consiste à sauter dans l'inconnu comme Icare ... et à ne pas être brisé en miettes.
C'est la tâche principale de la science des données: comment ne pas être * mal informé * à la suite de l'étude des données.
Avant de sauter de cette falaise, il est préférable d'espérer que les modèles que vous avez trouvés dans votre vision limitée de la réalité fonctionnent réellement en dehors de votre vue. En d'autres termes, pour vous être utiles, les modèles doivent être généralisés.

Des trois types de modèles, lors de la prise de décisions dans l'incertitude, seul le premier (généralisé) est sûr. Malheureusement, vous trouverez d'autres types de modèles dans vos données - c'est le gros problème sous-jacent à la science des données: comment ne pas perdre votre conscience à la suite de l'étude des données.
Généralisation
Si vous pensez que trouver des modèles inutiles dans les données est un privilège purement humain, détrompez-vous! Si vous ne faites pas attention, les voitures peuvent faire la même stupidité automatiquement.
L'intérêt de l'apprentissage automatique et de l'IA est de généraliser correctement les nouvelles situations.
L'apprentissage automatique est une approche permettant de prendre de nombreuses décisions similaires, ce qui implique une recherche algorithmique des modèles dans vos données et leur utilisation pour répondre correctement à des données complètement nouvelles. Dans le jargon de l'apprentissage automatique et de l'IA, la généralisation fait référence à la capacité de votre modèle à bien fonctionner avec des données qu'il n'a pas encore vues. Quel est l'intérêt d'un modèle basé sur un modèle qui ne fonctionne correctement qu'avec d'anciennes données? Pour ce faire, vous pouvez simplement utiliser la table de recherche. L'intérêt de l'apprentissage automatique et de l'IA est de faire les bonnes généralisations dans de nouvelles situations.

C'est pourquoi le premier type de modèle sur notre liste est le seul qui fonctionne bien pour l'apprentissage automatique. Ce type de données est un signal, tout le reste n'est que du bruit (facteurs qui n'existent que dans vos anciennes données et interfèrent avec la création d'un modèle généralisable).
Signal: modèles qui existent à la fois dans votre ensemble de données et au-delà.
Bruit: modèles qui n'existent que dans votre ensemble de données.
En fait, obtenir une solution qui traite les vieux bruits plutôt que les nouvelles données est ce que l'on appelle le surapprentissage de l'apprentissage automatique (nous prononçons ce terme sur le même ton que celui dans lequel vous prononcez votre juron préféré). En apprentissage automatique, presque tout est fait pour éviter le surajustement.
Alors, à quel type * cet * échantillon appartient-il?
Supposons que le modèle que vous (ou votre ordinateur) avez extrait de vos données existe au-delà de votre imagination - à quelle catégorie appartient-il? Est-ce un phénomène réel qui existe dans la population d'intérêt (signal) ou est-ce une caractéristique de votre jeu de données (bruit)? Comment déterminer le type de motif détecté lors de l'utilisation de données?
Si vous examinez toutes les données disponibles, vous ne pourrez pas le faire. Vous serez perplexe et ne pourrez pas dire si votre modèle existe ailleurs. Toute la rhétorique sur le test d'hypothèses statistiques dépend de l'imprévu, et prétendre que le modèle déjà connu vous surprend est de mauvais goût (en fait, c'est du piratage).

C'est comme voir un nuage en forme de lapin, puis vérifier si tous les nuages ressemblent à des lapins ... regardant le même nuage. J'espère que vous comprenez que vous aurez besoin de nouveaux nuages pour tester votre théorie.
Les données utilisées pour formuler une théorie ou une question ne peuvent pas être utilisées pour vérifier la même théorie.
Que feriez-vous si vous saviez que vous n'avez accès qu'à un seul cloud? Médité dans le garde-manger, c'est quoi. Posez votre question avant de consulter les données.
Les mathématiques ne contredisent jamais le bon sens.
Nous arrivons ici à la conclusion la plus triste. Si vous utilisez votre ensemble de données pour vous inspirer, vous ne pouvez pas l'utiliser à nouveau pour tester en profondeur la théorie qu'il a inspirée (quels que soient les astuces de jiu-jitsu que vous utilisez, les mathématiques ne vont jamais à l'encontre du bon sens).
Choix difficile
Le fait est que vous devez faire un choix! Si vous n'avez qu'un seul ensemble de données, alors vous devez vous demander: «Je médite dans le placard, je formule mes hypothèses pour des tests statistiques, puis j'adopte doucement une approche rigoureuse - tout cela pour que je puisse me prendre au sérieux? Ou suis-je simplement en train de collecter des données pour m'inspirer, et pourtant je me rends compte que je me trompe peut-être et que je me souviens que je devrais utiliser des expressions comme «je ressens» ou «cela inspire» ou «je ne suis pas sûr»? Choix difficile!
Ou est-il possible de manger deux fois un morceau de gâteau? Le problème est que vous n'avez qu'un seul ensemble de données et que vous avez besoin de plus d'un ensemble de données. Et si vous avez suffisamment de données, alors j'ai un truc. Va exploser. Votre. Cerveau.

Tricky trick
Pour réussir dans la science des données, il vous suffit de transformer un ensemble de données en deux (au moins) en divisant vos données. Utilisez ensuite l'un pour l'inspiration et l'autre pour des tests rigoureux. Si le motif qui vous a initialement inspiré existe également dans les données qui ne pouvaient pas influencer votre opinion, alors il est probable que ce motif soit une règle générale en vigueur dans la litière pour chat dont vous tirez vos données.
Si le même phénomène est observé dans les deux ensembles de données, il s'agit probablement d'une règle générale, qui se manifeste dans toutes les sources de ces données.
RSChD!
Puisque la vie sans exploration n'est pas du tout la vie, voici quatre mots pour vivre: Partagez vos fichues données .
Le monde serait meilleur si tout le monde partageait ses données. Nous aurions de meilleures réponses (grâce aux statistiques) et de meilleures questions (grâce à l'analytique). La seule raison pour laquelle les gens ne considèrent pas le partage de données comme une habitude obligatoire est que, au siècle dernier, c'était un luxe que très peu de gens pouvaient se permettre. Les jeux de données étaient si petits que si vous tentiez de les diviser, il ne resterait peut-être plus rien.
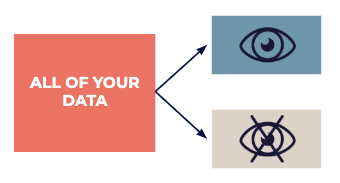
Divisez vos données en un jeu de données exploratoire accessible au public qui peut être utilisé pour l'inspiration, et un jeu de données de test qui sera ensuite utilisé par des experts pour identifier les «suppositions» trouvées pendant la phase d'exploration.
Certains projets sont toujours confrontés à ce problème, en particulier dans la recherche médicale (j'avais l'habitude de faire des neurosciences, j'ai donc un grand respect pour la complexité de travailler avec de petits ensembles de données), mais beaucoup d'entre vous ont tellement de données que vous avez besoin d'embaucher des ingénieurs, juste pour faire en sorte qu'ils soient déplacés ... quelle est votre excuse?! Ne lésinez pas, partagez vos données.
Si vous n'avez pas l'habitude de partager des données, vous êtes peut-être coincé dans le 20e siècle.
Si vous avez beaucoup de données et que leurs ensembles ne sont pas séparés, alors vous existez dans un paradigme dépassé. Les personnes existant dans ce paradigme ont accepté la pensée archaïque et ont refusé d'aller plus loin dans le temps.
L'apprentissage automatique est un descendant du partage de données
En fin de compte, l'idée est simple. Utilisez un ensemble de données pour former une théorie, découvrez cet ensemble de données, puis faites la magie - prouvez vos idées sur un tout nouvel ensemble de données.
Le partage de données est la solution rapide la plus simple pour une culture de données plus saine.
De cette façon, vous pouvez utiliser en toute sécurité des méthodes statistiques et vous assurer contre le sur-ajustement. En fait, l'histoire du machine learning est l'histoire du partage de données.
Comment utiliser la meilleure idée en science des données
Pour tirer parti de la meilleure idée de la science des données, tout ce que vous avez à faire est de vous assurer de garder vos données de test hors de portée des regards indiscrets, puis de laisser vos analystes devenir fous pour le reste.
Pour réussir dans la science des données, il suffit de transformer un ensemble de données en (au moins) deux en divisant vos données.
Lorsque vous pensez qu'ils vous ont apporté des informations utiles au-delà de ce qu'ils ont appris, utilisez votre réserve secrète de données de test pour tester vos résultats.

Découvrez les détails sur la façon d'obtenir une profession de premier plan à partir de zéro ou de monter de niveau en compétences et en salaire en suivant les cours en ligne payés de SkillFactory:
- Cours d'apprentissage automatique (12 semaines)
- Apprendre la science des données à partir de zéro (12 mois)
- (9 )
- «Python -» (9 )