
Avec le recul, je peux dire que toutes les actions de placement depuis lors sont des mouvements forcés. Et seulement maintenant, dans la quinzième année, nous pouvons configurer l'infrastructure comme nous en avons besoin.
Nous nous trouvons maintenant dans 4 centres de données physiquement différents, connectés par un anneau d'optiques sombres, y plaçant 5 pools de ressources indépendants. Et il se trouve que si une météorite tombe dans l'un des croisements, alors 3 de ces piscines tomberont immédiatement et les deux autres ne tireront pas la charge. Nous avons donc entamé un rééquilibrage complet pour remettre les choses en ordre.
Premier centre de données
Au début, il n'y avait pas du tout de centre de données. Il y avait un ancien systémiste dans le dortoir de l'Université d'État de Moscou. Puis, presque immédiatement - hébergement partagé chez Masterhost (ils sont toujours en vie, enfer). Le trafic sur le site Web avec un horaire de train a doublé toutes les 4 semaines, donc très bientôt nous sommes passés au KVM-VPS, c'est arrivé vers 2005. À un moment donné, nous nous sommes heurtés à des restrictions de trafic, car il était alors nécessaire de maintenir un équilibre entre les arrivées et les sorties. Nous avons eu deux installations, et nous avons transféré une paire de fichiers lourds de l'un à l'autre tous les soirs pour maintenir les proportions requises.
En mars 2009, il n'y avait que des VPS... C'est une bonne chose, nous avons décidé de passer en colocation. Nous avons acheté quelques serveurs en fer physiques (l'un d'eux est celui du mur, dont nous stockons le corps comme mémoire). Nous avons mis Fiord dans le centre de données (et ils sont toujours en vie, les démons). Pourquoi? Parce que ce n'était pas loin du bureau d'alors, un ami m'a recommandé, et j'ai dû me lever rapidement. De plus, c'était relativement bon marché.
Le partage de charge entre les serveurs était simple: chacun avait un back-end, MySQL avec réplication maître-esclave, le front était au même endroit que la réplique. Eh bien, c'est-à-dire presque aucune séparation par type de charge. Bientôt, ils ont également commencé à manquer, a acheté un troisième.
Vers le 1er octobre 2009, nous nous sommes rendu compte qu'il y avait déjà plus de serveurs, mais nous allons nous coucher pour la nouvelle année... Les prévisions de trafic ont montré que la capacité potentielle sera coupée avec une marge. Et nous avons rencontré les performances de la base de données. Il a fallu un mois et demi pour se préparer avant la croissance du trafic. C'était l'époque des premières optimisations. Nous avons acheté quelques serveurs uniquement sous la base de données. Ils se sont concentrés sur des disques rapides avec une vitesse de rotation de 15krpm (je ne me souviens pas de la raison exacte pour laquelle nous n'avons pas utilisé de disques SSD, mais très probablement, ils avaient une limite basse sur le nombre d'opérations d'écriture, et en même temps un coût comme un avion). Nous avons divisé l'avant, l'arrière, les bases, modifié les paramètres de nginx, MySQL et effectué un redimensionnement pour optimiser les requêtes SQL. Survécu.

Nous nous trouvons maintenant dans une paire de centres de données de niveau III et dans une interface utilisateur de niveau II (avec un recul sur T3, mais sans certificats). Mais Fiord n'a même jamais été un T-II. Ils avaient des problèmes de survie, il y avait des situations de la catégorie «tous les fils électriques dans un collecteur, et il y avait un incendie, et le générateur a roulé pendant trois heures». En général, nous avons décidé de déménager.
Choisissez un autre centre de données, Caravan... Tâche: comment déplacer des serveurs sans temps d'arrêt? Nous avons décidé de vivre dans deux centres de données pendant un certain temps. Heureusement, le trafic à l'intérieur du système à cette époque n'était pas autant qu'il l'est maintenant, il était possible de générer du trafic via VPN entre les emplacements pendant un certain temps (surtout hors saison). Fait un équilibrage du trafic. Nous avons progressivement augmenté la part de la Caravane, après un certain temps nous avons complètement déménagé là-bas. Et maintenant, il nous reste un centre de données. Et vous en avez besoin de deux, nous l'avons déjà compris, grâce aux échecs du Fjord. En regardant en arrière, je peux dire que le TIER III n'est pas non plus une panacée, la capacité de survie sera de 99,95, mais la disponibilité est différente. Un seul centre de données n'est donc certainement pas suffisant pour une disponibilité de 99,95 et plus.
La deuxième Stordata choisie, et il y avait déjà la possibilité d'un lien optique avec le site Caravan. Nous avons réussi à étirer la première veine. Je viens de commencer à charger un nouveau centre de données, car la caravane a annoncé qu'elle avait un cul. Ils ont dû quitter le site car le bâtiment était en cours de démolition. Déjà. Surprise! Il y a un nouveau site, ils proposent de tout éteindre, de soulever les racks avec du matériel avec des grues (alors nous avions déjà 2,5 racks de fer), de traduire, de l'allumer, et tout fonctionnera ... 4 heures pour tout ... les contes de fées ... Je suis déjà silencieux que nous avons même une heure d'arrêt ne correspondait pas, mais ici l’histoire aurait duré au moins un jour. Et tout cela a été servi dans l'esprit "Tout est parti, le plâtre est enlevé, le client s'en va!" Le 29 septembre, le premier appel, et le 10 octobre, ils voulaient tout prendre et le prendre. Pendant 3 à 5 jours, nous avons dû développer un plan de déménagement, et en 3 étapes,éteindre 1/3 de l'équipement à la fois avec une préservation totale du service et de la disponibilité pour transporter les voitures à Stordata. En conséquence, ce fut 15 minutes simples dans un service pas le plus critique.
Encore une fois, nous nous sommes retrouvés avec un centre de données.
En ce moment, nous sommes fatigués de traîner avec des serveurs sous le bras et de jouer aux déménageurs. De plus, fatigué de gérer le matériel lui-même dans le centre de données. Ils ont commencé à regarder vers les nuages publics.
De 2 à 5 (presque) data centers
Nous avons commencé à chercher des options avec des nuages. Nous sommes allés à Krok, l'avons essayé, testé, convenu des conditions. Nous sommes entrés dans le cloud, qui se trouve dans le centre de données Compressor. Fait un anneau d'optiques sombres entre Stordata, Compressor et office. Partout sa propre liaison montante et deux bras d'optique. Le fait de couper l'un des rayons ne détruit pas le réseau. La perte d'une liaison montante ne détruit pas le réseau. Obtention du statut LIR, possède son propre sous-réseau, annonces BGP, redondance du réseau, beauté. Je ne décrirai pas comment ils sont entrés dans le cloud du point de vue du réseau, mais il y avait des nuances.
Nous avons donc 2 centres de données.
Krok dispose également d'un centre de données sur Volochaevskaya, ils y ont également étendu leur cloud, proposé d'y transférer une partie de nos ressources. Mais en me souvenant de l'histoire de la Caravane, qui, en fait, n'a jamais récupéré après la démolition du centre de données, j'ai voulu prendre des ressources cloud de différents fournisseurs afin de réduire le risque que l'entreprise cesse d'exister (le pays est tel qu'un tel risque ne peut être ignoré). Par conséquent, Volochaevskaya n'a pas été contacté à ce moment-là. Eh bien, le deuxième fournisseur fait aussi de la magie avec les prix. Parce que lorsque vous pouvez prendre et partir avec élasticité, cela donne une position de négociation solide sur les prix.
Nous avons examiné différentes options, mais le choix s'est porté sur #CloudMTS. Il y avait plusieurs raisons à cela: le cloud sur les tests s'est avéré bon, les gars savent aussi travailler avec le réseau (un opérateur télécom après tout), et la politique marketing très agressive de conquérir le marché, en conséquence, des prix intéressants.
Total 3 centres de données.
Ensuite, après tout, nous avons également connecté Volochaevskaya - des ressources supplémentaires étaient nécessaires, et dans Compressor, c'était déjà un peu encombré. En général, nous avons redistribué la charge entre les trois nuages et nos équipements dans le Stordat.
4 centres de données. Et déjà en termes de survivabilité, T3 est partout. Il semble que tout le monde ne possède pas de certificats, mais je ne dirai pas avec certitude.
MTS avait une nuance. Rien d'autre que MGTS ne pouvait y aller au dernier kilomètre. Dans le même temps, il n'était pas possible d'extraire entièrement l'optique sombre de MGTS du centre de données au centre de données (pendant une période longue et coûteuse, et si je ne confond pas, ils ne fournissent pas un tel service). Je devais le faire avec un joint, sortie deux faisceaux du centre de données vers les puits les plus proches, où se trouve notre fournisseur d'optique sombre Mastertel. Ils ont un vaste réseau d'optiques dans toute la ville, et si quelque chose, ils se contentent de souder l'itinéraire souhaité et de vous donner une veine. Pendant ce temps, la Coupe du Monde de la FIFA est arrivée dans la ville, de manière inattendue, comme de la neige en hiver, et l'accès aux puits de Moscou a été fermé. Nous avons attendu la fin de ce miracle et nous pouvons jeter notre lien. Il semblerait qu'il fût nécessaire de quitter le centre de données MTS avec l'optique en main, en sifflant pour atteindre la trappe souhaitée et l'abaisser là. Conditionnellement. Nous l'avons fait pendant trois mois et demi. Plus précisément, le premier rayon a été fait assez rapidement,début août (je me souviens que la Coupe du monde s'est terminée le 15 juillet). Mais j'ai dû bricoler ma deuxième épaule - la première option impliquait que nous devions creuser l'autoroute Kashirskoye, pour laquelle nous avons dû la bloquer pendant une semaine (il y avait un tunnel dans la reconstruction où certaines communications se trouvaient, nous avons dû creuser). Heureusement, ils ont trouvé une alternative: un autre itinéraire, le même géo-indépendant. Il s'est avéré que deux veines de ce centre de données à différents points de notre présence. L'anneau optique s'est transformé en anneau avec une poignée.Il s'est avéré que deux veines de ce centre de données à différents points de notre présence. L'anneau optique s'est transformé en anneau avec une poignée.Il s'est avéré que deux veines de ce centre de données à différents points de notre présence. L'anneau optique s'est transformé en anneau avec une poignée.
Courant un peu en avant, je dirai qu'ils nous l'ont quand même proposé. Heureusement, au tout début de l'opération, quand peu de choses ont été transférées. Il y avait un feu dans un puits, et pendant que les installateurs juraient dans la mousse, dans le deuxième puits, quelqu'un s'est retiré pour regarder le connecteur (c'était une sorte de nouveau design, c'est intéressant). Mathématiquement, la probabilité d'une défaillance simultanée était négligeable. Nous l'avons pratiquement attrapé. En fait, nous avons eu de la chance dans le fjord - la nourriture principale y a été coupée, et au lieu de la rallumer, quelqu'un a mélangé l'interrupteur et a éteint la ligne de secours.
Il n'y avait pas que des exigences techniques pour la répartition de la charge entre les sites: il n'y a pas de miracle, et une politique commerciale agressive avec de bons prix implique certains taux de croissance de la consommation des ressources. Nous avons donc toujours gardé à l'esprit le pourcentage de ressources à envoyer à MTS. Nous avons redistribué tout le reste entre les autres centres de données plus ou moins uniformément.
Ton fer à nouveau
L'expérience de l'utilisation des clouds publics nous a montré qu'il était pratique de les utiliser lorsque vous avez besoin d'ajouter rapidement des ressources, pour des expériences, pour un pilote, etc. Lorsqu'il est utilisé sous une charge constante, il s'avère plus coûteux que de tordre votre propre fer. Mais nous ne pouvions plus abandonner l'idée de conteneurs, de migrations fluides de machines virtuelles au sein d'un cluster, etc. Nous avons écrit l'automatisation pour éteindre certaines voitures la nuit, mais l'économie n'a toujours pas fonctionné. Nous n'avions pas assez de compétences pour prendre en charge un cloud privé, nous avons dû le développer.
Nous recherchions une solution qui vous permettrait d'obtenir un cloud sur votre matériel relativement facilement. A cette époque, nous n'avions jamais travaillé avec des serveurs Cisco, seulement avec une pile réseau, c'était un risque. Dellah dispose d'un matériel simple et familier, aussi fiable qu'un fusil d'assaut Kalachnikov. Nous avons cela depuis des années, et cela existe encore quelque part. Mais l'idée derrière Hyperflex est qu'il prend en charge l'hyper-convergence de la solution finale prête à l'emploi. Et chez Della, tout vit sur des routeurs ordinaires, et il y a des nuances. En particulier, la performance n'est en fait pas aussi cool que dans les présentations en raison de la surcharge. Dans un sens, ils peuvent être configurés correctement et seront excellents, mais nous avons décidé que ce n'était pas notre affaire, et laissez Dell préparer ceux qui trouvent un appel à cela. En conséquence, nous avons choisi Cisco Hyperflex. Cette option a été globalement la plus intéressante: moins d'hémorroïdes dans la configuration et le fonctionnement,et tout allait bien pendant les tests. À l'été 2019, le cluster a été lancé dans la bataille. Nous avions un rack à moitié vide dans le compresseur, occupé en grande partie uniquement avec des équipements réseau, et nous l'avons placé là. Ainsi, nous avons obtenu le cinquième «centre de données» - physiquement quatre, mais cinq par les pools de ressources.
Nous avons pris, calculé le volume de la charge constante et le volume de la variable. Ils ont transformé la constante en une charge sur leur fer. Mais au niveau matériel, cela donne des avantages au cloud en termes de résilience et de redondance.
Le retour sur investissement du projet fer est au prix moyen de nos nuages pour l'année.
Tu es là
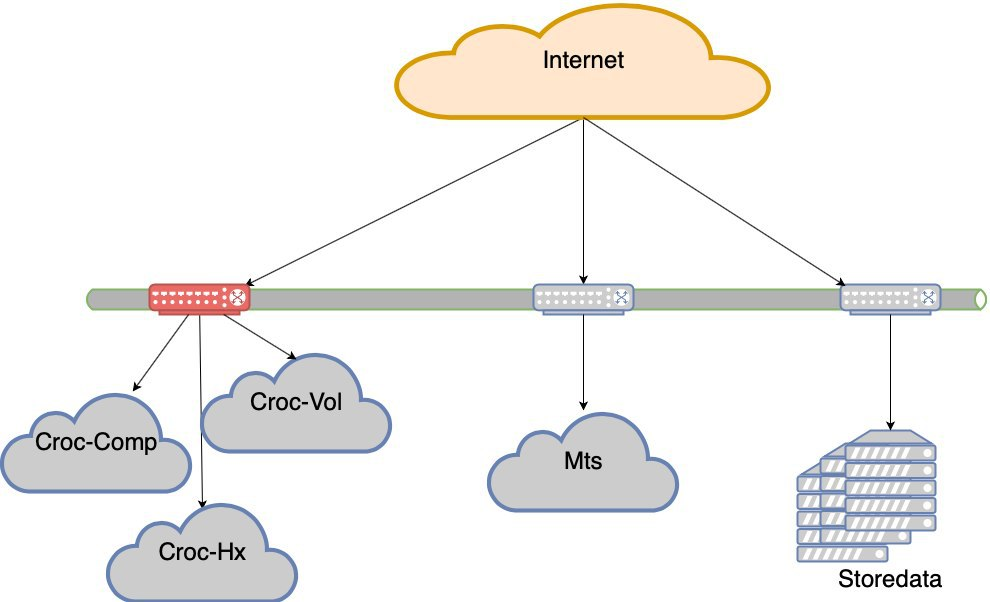
À ce moment, nous avons mis fin aux mouvements forcés. Comme vous pouvez le voir, nous n’avions pas beaucoup d’options économiques et nous avons constamment chargé où nous devions nous lever pour une raison quelconque. Cela a conduit à une situation étrange que la charge est inégale. L'échec d'un segment (et le segment avec les centres de données de Croc est détenu par deux Nexus dans un goulot d'étranglement) est une perte d'expérience utilisateur. Autrement dit, le site sera préservé, mais il y aura des difficultés évidentes d'accessibilité.
Il y a eu une panne dans MTS avec l'ensemble du centre de données. Il y en avait deux autres dans les autres. De temps en temps, des nuages tombaient, ou des contrôleurs de cloud, ou un problème de réseau complexe se posait. En bref, nous perdons de temps en temps des centres de données. Oui, brièvement, mais toujours désagréable. À un moment donné, ils ont pris pour acquis que les centres de données tombaient en panne.
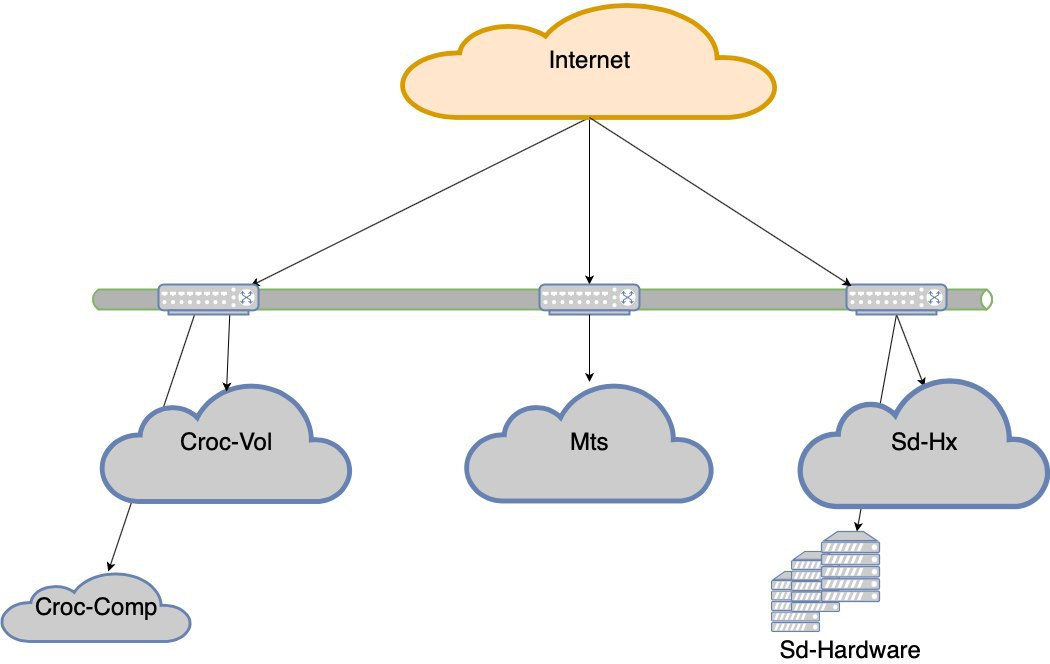
Nous avons décidé d'opter pour la tolérance aux pannes au niveau du centre de données.
Maintenant, nous n'irons pas au lit si l'un des 5 centres de données tombe en panne. Mais si nous perdons l'épaule de Croc, il y aura des retraits très sérieux. C'est ainsi qu'est né le projet de tolérance aux pannes des data centers. Le but est le suivant: si le DC meurt, le réseau meurt avant lui ou l'équipement meurt, le site doit fonctionner sans aucune intervention manuelle. De plus, après l'accident, nous devons récupérer correctement.
Quels sont les pièges
Maintenant:
Besoin de:
Maintenant:
Besoin de:
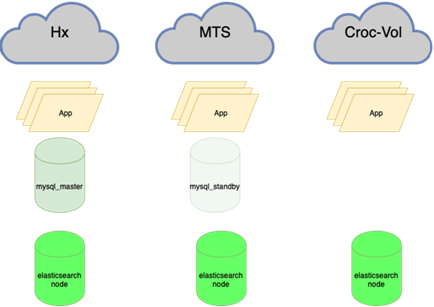
L'élastique résiste à la perte d'un nœud:
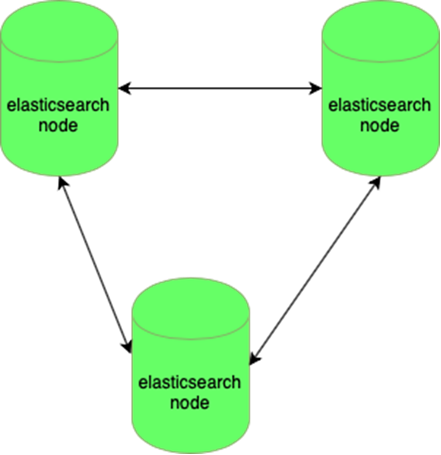
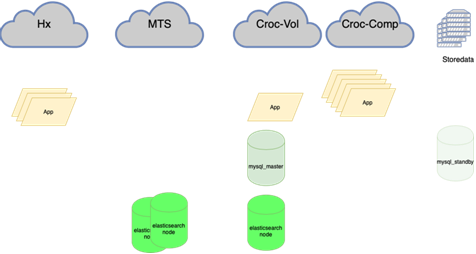
Les bases de données MySQL (de nombreuses petites) sont difficiles à gérer:
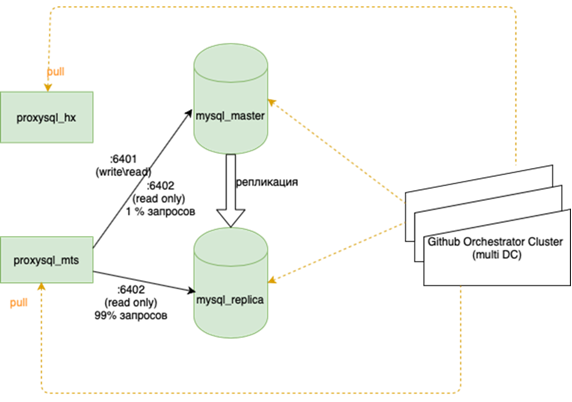
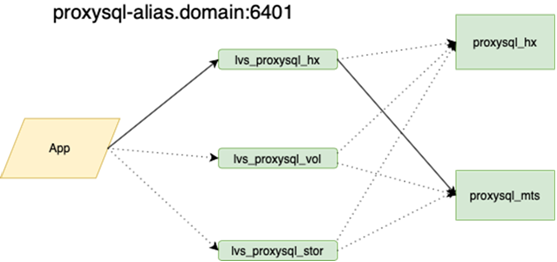
Mon collègue, qui a fait l'équilibrage, écrira à ce sujet plus en détail. L'important est qu'avant de l'accrocher, si nous perdions le maître, nous devions aller à la réserve avec nos mains et cocher la case r / o = 0, reconstruire toutes les répliques avec cet ensemble, et il y en a plus de deux dans la guirlande principale des dizaines, modifiez les configurations d'application, puis déployez les configurations et attendez la mise à jour. Maintenant, l'application parcourt un anycast-ip, qui examine l'équilibreur LVS. La configuration permanente ne change pas. Toute la topologie de base sur l'orchestrateur.
Désormais, des optiques sombres sont étirées entre nos centres de données, ce qui vous permet d'accéder à n'importe quelle ressource de notre anneau en tant que ressource locale. Le temps de réponse entre les centres de données et le temps à l'intérieur du plus ou du moins est le même. C'est une différence importante par rapport aux autres entreprises qui construisent des géoclusters. Nous sommes très liés à notre matériel et à notre réseau, et nous n'essayons pas de localiser les demandes à l'intérieur du centre de données. D'une part, c'est cool, mais d'autre part, si nous voulons aller en Europe ou en Chine, nous ne retirerons pas nos optiques sombres.
Cela signifie rééquilibrer presque tout, en particulier les bases de données. Il existe de nombreux schémas où le maître actif pour la lecture et l'écriture détient toute la charge, et à côté se trouve une réplique synchrone pour une commutation rapide (nous n'écrivons pas en deux à la fois, à savoir nous répliquons, sinon cela ne fonctionne pas très bien). La base principale se trouve dans un centre de données et la réplique dans un autre. Il peut également y avoir des copies partielles dans le troisième pour les applications individuelles. Il en existe de 10 à 15, selon la saison. Orchestrator est un cluster étendu entre les centres de données et 3 centres de données. Ici, nous vous en dirons plus en détail lorsque vous aurez la force de décrire comment toute cette musique joue.
Vous aurez besoin de fouiller dans les applications. Cela est toujours nécessaire maintenant: il arrive parfois que si une connexion est rompue, il est correct d'éteindre l'ancienne, d'ouvrir une nouvelle. Mais parfois, les demandes adressées à une connexion déjà perdue sont répétées en boucle jusqu'à ce que le processus meure. La dernière chose qui a été prise était la tâche de la couronne, un rappel sur le train n'a pas été écrit.
En général, il reste encore beaucoup à faire, mais le plan est clair.