J'étais chef d'équipe et j'étais en charge de quelques services essentiels. Et si quelque chose n'allait pas chez eux, cela arrêtait de vrais processus métier. Par exemple, les commandes ont cessé d'être assemblées à l'entrepôt.
Je suis récemment devenu chef de direction et je suis maintenant en charge de trois équipes au lieu d'une. Chacun d'eux dispose d'un système informatique. Je veux comprendre ce qui se passe dans chaque système et ce qui peut se briser.
Dans cet article, je vais parler de
- ce que nous surveillons
- comment nous surveillons
- et surtout: que faisons-nous des résultats de ces observations.

Lamoda a de nombreux systèmes. Tous sont libérés, quelque chose change en eux, quelque chose arrive à la technique. Et je veux au moins avoir l'illusion que nous pouvons facilement localiser la panne. Je suis constamment bombardé d'alertes que j'essaie de comprendre. Afin de m'éloigner des abstractions et aller aux détails, je vais vous donner le premier exemple.
De temps en temps, quelque chose explose: les chroniques d'un incendie
Un matin d'été chaud, sans déclaration de guerre, comme c'est généralement le cas, notre surveillance a fonctionné. Nous utilisons Icinga comme alerte. Alert a dit qu'il nous reste 50 Go de disque dur sur le serveur SGBD. Très probablement, 50 gigaoctets est une goutte dans l'océan, et cela se terminera très rapidement. Nous avons décidé de voir exactement combien d'espace libre restait. Vous devez comprendre que ce ne sont pas des machines virtuelles, mais des serveurs de fer, et la base est sous forte charge. Il existe un SSD de 1,5 téraoctet. Bientôt, ce souvenir prendra fin: il durera 20 à 30 jours. C'est très petit; vous devez résoudre rapidement le problème.
Ensuite, nous avons également vérifié la quantité de mémoire réellement consommée en 1-2 jours. Il s'avère que 50 gigaoctets suffisent pour environ 5-7 jours. Après cela, le service qui fonctionne avec cette base prendra fin de manière prévisible. Nous commençons à réfléchir aux conséquences: archiver de toute urgence les données que nous allons supprimer. Le service d'analyse des données dispose de toutes les sauvegardes, vous pouvez donc supprimer en toute sécurité tout ce qui date de plus de 2015.
Nous essayons de le supprimer et nous rappelons que MySQL ne fonctionnera pas comme ça avec un demi-coup. Les données supprimées sont excellentes, mais la taille du fichier alloué pour la table et pour la base de données ne change pas. MySQL utilise alors cet espace. Autrement dit, le problème n'a pas été résolu, il n'y a plus d'espace.
Nous essayons une approche différente: migrer les étiquettes des SSD à fermeture rapide vers des disques plus lents. Pour ce faire, nous sélectionnons les plaques qui pèsent beaucoup, mais sous peu de charge, et utilisons la surveillance Percona. Nous avons déplacé les tables et réfléchissons déjà à déplacer les serveurs eux-mêmes. Après le deuxième mouvement, les serveurs ne prennent pas 1,5, mais 4 téraoctets de SSD.
Nous avons éteint ce feu: nous avons organisé un déménagement et, bien sûr, corrigé la surveillance. Désormais, l'avertissement ne sera pas déclenché sur 50 gigaoctets, mais sur un demi-téraoctet, et la valeur de surveillance critique sera déclenchée sur 50 gigaoctets. Mais en réalité ce n'est qu'une couverture de l'arrière de l'arrière. Cela durera un moment. Mais si nous permettons une répétition de la situation, sans diviser la base en parties et sans penser à l'éclatement, tout finira mal.
Supposons que nous ayons changé de serveur. À un certain stade, il était nécessaire de redémarrer le maître. Probablement, des erreurs apparaîtront dans ce cas. Dans notre cas, le temps d'arrêt était d'environ 30 secondes. Mais les demandes arrivent, il n'y a nulle part où écrire, les erreurs sont arrivées, la surveillance a fonctionné. Nous utilisons le système de surveillance Prometheus - et nous y voyons que la métrique de 500 erreurs ou le nombre d'erreurs lors de la création d'une commande a bondi. Mais nous ne connaissons pas les détails: quel type d'ordre n'a pas été créé, et ainsi de suite.
Ensuite, je vous expliquerai comment nous travaillons avec la surveillance pour ne pas tomber dans de telles situations.
Examen de la surveillance et description claire du service d'assistance
Nous avons plusieurs directions et indicateurs que nous surveillons. Il y a des téléviseurs partout dans le bureau, sur lesquels il existe de nombreux labels techniques et commerciaux différents, qui, en plus des développeurs, sont surveillés par un service d'assistance.
Dans cet article, je parle de la façon dont nous l'avons et j'ajoute ce à quoi nous voulons en venir. Cela s'applique également aux examens de contrôle. Si nous faisions régulièrement un inventaire de notre "propriété", nous pourrions mettre à jour tout ce qui est obsolète et le réparer, empêchant une répétition du fakap. Cela nécessite une liste cohérente.
Dans notre référentiel, il y a des config-icings avec des alertes, où il y a maintenant 4678 lignes. À partir de cette liste, il est difficile de comprendre de quoi parle chaque surveillance spécifique. Disons que notre métrique est appelée db_disc_space_left. Le service d'assistance ne comprendra pas immédiatement de quoi il s'agit. Quelque chose à propos de l'espace libre, super.
Nous voulons creuser plus profondément. Nous regardons la configuration de cette surveillance et comprenons d'où elle vient.
pm_host: "{{ prometheus_server }}"
pm_query: ”mysql_ssd_space_left"
pm_warning: 50
pm_critical: 10 pm_nanok: 1
Cette métrique a un nom, ses propres limitations, quand activer la surveillance d'avertissement, alerte pour signaler une situation critique. Nous utilisons une convention de dénomination métrique. Au début de chaque métrique se trouve le nom du système. Grâce à cela, la zone de responsabilité devient claire. Si la personne en charge du système démarre la mesure, il est immédiatement clair à qui s'adresser.
Les alertes sont versées dans les télégrammes ou lâches. Le service d'assistance est le premier à y répondre 24h / 24 et 7j / 7. Les gars regardent exactement ce qui a explosé, si c'est une situation normale. Ils ont des instructions:
- ceux qui sont donnés pour remplacer,
- et des instructions fixées en confluence sur une base continue. Par le nom de la surveillance éclatée, vous pouvez trouver ce que cela signifie. Pour les plus critiques, il est décrit ce qui a éclaté, quelles sont les conséquences, qui doit être élevé.
Nous avons également des quarts de travail dans les équipes responsables des systèmes clés. Chaque équipe a quelqu'un qui est constamment disponible. Si quelque chose arrivait, ils le ramassent.
Lorsque l'alerte est déclenchée, l'équipe de support doit trouver rapidement toutes les informations clés. Ce serait bien d'avoir un lien vers la description de la surveillance attaché au message d'erreur. Par exemple, pour qu'il y ait de telles informations:
- description de cette surveillance en termes clairs et relativement simples;
- l'adresse où il se trouve;
- une explication de ce qu'est la métrique;
- conséquences: comment cela se terminera si nous ne corrigeons pas l'erreur;
- , , . , , . -, .
Il serait également pratique de voir immédiatement la dynamique du trafic dans l'interface Prometheus.
Je voudrais faire de telles descriptions pour chaque surveillance. Ils vous aideront à construire votre avis et à faire des ajustements. Nous mettons en œuvre cette pratique: la configuration de givrage contient déjà un lien de confluence avec ces informations. Je travaille sur un système depuis près de 4 ans, il n'y a fondamentalement aucune description de ce type. Par conséquent, maintenant je rassemble des connaissances ensemble. Les descriptions résolvent également le manque de sensibilisation de l’équipe.
Nous avons des instructions pour la plupart des alertes, où il est écrit ce qui conduit à un certain impact commercial. C'est pourquoi nous devons rapidement régler la situation. La criticité des éventuels incidents est déterminée par le service d'assistance en collaboration avec l'entreprise.
Je vais vous donner un exemple: si le suivi de la consommation de mémoire sur le serveur RabbitMQ du service de traitement des commandes a fonctionné, cela signifie que le service de file d'attente peut tomber en quelques heures voire quelques minutes. Et cela, à son tour, arrêtera de nombreux processus métier. En conséquence, les clients attendront en vain les commandes, les notifications SMS / push, les changements de statut et bien plus encore.
Les discussions sur la surveillance avec les entreprises ont souvent lieu après des incidents graves. Si quelque chose tombe en panne, nous recueillons une commission avec des représentants de la direction qui s'est accrochée à notre libération ou à notre incident. Lors de la réunion, nous analysons les causes de l'incident, comment nous assurer qu'il ne se reproduira plus, quels dommages nous avons subis, combien d'argent nous avons perdu et sur quoi.
Il se trouve que vous devez connecter une entreprise pour résoudre les problèmes créés pour les clients. Nous discutons des actions proactives là-bas: quel type de surveillance mettre en place pour que cela ne se reproduise plus.
Le service d'assistance surveille les valeurs des métriques à l'aide d'un robot de télégramme. Lorsqu'un nouveau contrôle apparaît, le personnel de support a besoin d'un outil simple qui vous permettra de savoir où il s'est cassé et comment y remédier. Le lien vers la description de l'alerte résout ce problème.
Je vois le fakap en réalité: nous utilisons Sentry pour analyser les vols
Il ne suffit pas de découvrir l'erreur, je veux voir les détails. Notre cas d'utilisation standard est le suivant: déployer la version et recevoir des alertes de la pile K8S. Grâce à la surveillance, nous regardons l'état des foyers: quelles versions de l'application déployées, comment le déploiement s'est terminé et si tout va bien.
Ensuite, nous regardons le RMM, que nous avons avec la base et avec la charge sur elle. Pour Grafana et les cartes, nous examinons le nombre de connexions à Rabbit. Il est cool, mais sait comment fuir quand la mémoire est épuisée. Nous surveillons ces choses, puis nous vérifions la sentinelle. Il vous permet de regarder en ligne comment se déroule le prochain fiasco avec tous les détails. Dans ce cas, la surveillance post-publication signale ce qui s'est cassé et comment.
Dans les projets PHP, nous utilisons un client corbeau, enrichi en plus de données. Sentry regroupe tout bien. Et nous voyons la dynamique de chaque fakap, la fréquence à laquelle cela se produit. Et nous examinons également des exemples, quelles demandes n'ont pas abouti, quelles extensions sont sorties.
C'est à peu près à quoi ça ressemble. Je vois que sur la prochaine version, il y a plus d'erreurs que d'habitude. Nous allons vérifier ce qui est exactement cassé. Et puis, si nécessaire, nous obtiendrons les commandes échouées en fonction du contexte et les corrigerons.
Nous avons quelque chose de cool - lier à Jira. Il s'agit d'un outil de suivi des tickets: j'ai cliqué sur un bouton et une erreur de tâche a été créée dans Jira avec un lien vers Sentry et une trace de pile de cette erreur. La tâche est marquée par des étiquettes spécifiques.
L'un des développeurs a lancé une initiative sensée - "Clean Project, Clean Sentry". Pendant la planification, chaque fois que nous lançons dans le sprint au moins 1 à 2 tâches créées à partir de Sentry. Si quelque chose est constamment cassé dans le système, Sentry est jonché de millions de petites erreurs stupides. Nous les nettoyons régulièrement pour ne pas manquer accidentellement les plus sérieuses.
Des flammes pour une raison quelconque: on se débarrasse de la surveillance, sur laquelle tout le monde se bouche
- S'habituer aux erreurs
Si quelque chose clignote constamment et semble cassé, cela donne le sentiment d'une fausse norme. Le service d'assistance peut se tromper en pensant que la situation est adéquate. Et quand quelque chose de grave se brise, ils l'ignoreront. Comme dans une fable sur un garçon qui criait: "Loups, loups!"
Le cas classique est notre projet, qui est responsable du traitement des commandes. Il fonctionne avec le système d'automatisation de l'entrepôt et y transfère les données. Ce système est généralement libéré à 7 heures du matin, après quoi nous commençons la surveillance. Tout le monde y est habitué et se bouche, ce qui n'est pas très bon. Il serait sage de désactiver ces commandes. Par exemple, pour lier la sortie d'un système spécifique et certaines alertes via Prometheus, n'activez simplement pas la signalisation inutile.
- La surveillance ne prend pas en compte les mesures commerciales
Le système de traitement des commandes transfère les données vers l'entrepôt. Nous avons ajouté des moniteurs à ce système. Aucun d'eux n'a tiré, et il semble que tout va bien. Le compteur indique que les données partent. Cette affaire utilise du savon. En réalité, le compteur peut ressembler à ceci: la partie verte correspond aux échanges entrants, la partie jaune aux échanges sortants.
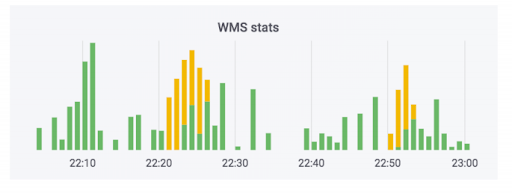
Nous avons eu un cas où les données ont vraiment plu, mais les courbes. Les commandes n'ont pas été payées, mais elles ont été marquées comme payées. Autrement dit, l'acheteur pourra les récupérer gratuitement. Cela semble effrayant. Mais l'inverse est plus amusant: une personne vient chercher une commande payée, et on lui demande de payer à nouveau à cause d'une erreur dans le système.
Pour éviter cette situation, nous surveillons non seulement la technologie, mais également les mesures commerciales. Nous avons un suivi spécifique qui surveille le nombre de commandes qui nécessitent un paiement à réception. Tout saut sérieux dans cette métrique montrera si quelque chose s'est mal passé.
Le suivi des indicateurs métier est une évidence, mais ils sont souvent oubliés lors de la sortie de nouveaux services, dont nous. Tout le monde couvre les nouveaux services avec des métriques purement techniques liées aux disques, processus, peu importe. En tant que boutique en ligne, nous avons un élément essentiel: le nombre de commandes créées. Nous savons combien de personnes achètent habituellement, ajusté pour les promotions marketing. Par conséquent, avec les versions, nous suivons cet indicateur.
Autre point important: lorsqu'un client commande à plusieurs reprises la livraison à la même adresse, nous ne le tourmentons pas en communiquant avec le centre d'appels, mais confirmons automatiquement la commande. Un crash système a un impact énorme sur l'expérience client. Nous surveillons également cette métrique, car les versions de différents systèmes peuvent l'influencer fortement.
Observer le monde réel: prendre soin d'un sprint sain et de nos performances
Afin que l'entreprise puisse suivre les différents indicateurs, nous avons filmé un petit système de tableau de bord en temps réel. Il a été initialement conçu dans un but différent. L'entreprise a un plan pour le nombre de commandes que nous voulons vendre un jour particulier du mois à venir. Ce système montre la conformité des plans et fait en fait. Pour le calendrier, elle prend les données de la base de production, lit à partir de là à la volée.
Une fois que notre réplique s'est effondrée. Il n'y avait pas de surveillance, nous n'avons donc pas eu le temps de le découvrir. Mais l'entreprise a vu que nous ne respections pas le plan de 10 unités de commandes conventionnelles et a lancé des commentaires. Nous avons commencé à comprendre les raisons. Il s'est avéré que des données non pertinentes sont lues à partir d'une réplique cassée. C'est un cas dans lequel une entreprise observe des indicateurs intéressants, et nous nous entraidons lorsque des problèmes surviennent.
Je vais vous parler d'une autre surveillance du monde réel, qui est en développement depuis longtemps et est constamment mise au point par chaque équipe. Nous avons Jira Viewer - il vous permet de suivre le processus de développement. Le système est extrêmement simple: le framework PHP Symfony, qui va à l'API Jira et y prend des données sur les tâches, les sprints, etc., en fonction de ce qui a été donné en entrée. Jira Viewer écrit régulièrement des mesures relatives aux équipes et à leurs projets dans Prometeus. Là, ils sont surveillés, alertés et, de là, affichés à Grafana. Grâce à ce système, nous suivons les travaux en cours.
- Nous surveillons combien de temps la tâche a été en cours depuis le moment de son exécution jusqu'au déploiement jusqu'à la production. Si le nombre est trop grand, cela indique théoriquement un problème avec les processus, l'équipe, la description de la tâche, etc. La durée de vie d'une tâche est une métrique importante, mais pas suffisante en soi.
- . , , . , .
- – ready for release, . - - , « ».
- : , . .
- . 400 150. , , .
- J'ai suivi dans mon équipe le nombre de pull requests de développeurs en dehors des heures de travail. Particulièrement après 20h. Et lorsque la métrique jaillit, c'est un signe alarmant: une personne n'a pas le temps pour quelque chose, ou investit trop d'efforts et tôt ou tard, elle s'épuise tout simplement.
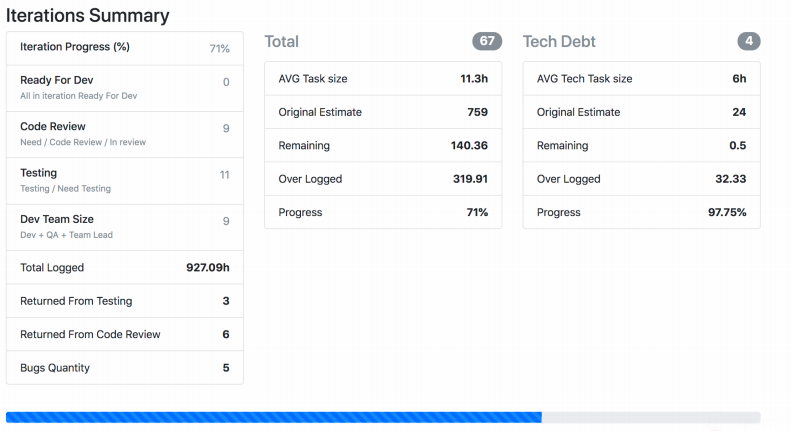
La capture d'écran montre comment Jira Viewer génère des données. Il s'agit d'une page contenant un résumé de l'état des tâches du sprint, du poids de chacune, etc. De telles choses se rassemblent également et s'envolent pour Prométhée.
Pas seulement des métriques techniques: ce que nous surveillons déjà, ce que nous pouvons surveiller et pourquoi tout cela est nécessaire
Pour mettre tout cela ensemble, je suggère de surveiller à la fois la technologie et les mesures liées aux processus, au développement et aux affaires. Les mesures techniques à elles seules ne suffisent pas.
- , -, Grafana-. . , , .
- : , . , , crontab supervisor. . , , .
- – , , .
- : , - , . , .
- , . – Sentry . - , . - , . Sentry , , .
- . , , .
- , . , - , - . .