
-, , .
, , . – , , – .
, ,
Tous les effets physiques énumérés dans les articles précédents ( un , deux , trois ) sont importants à comprendre non seulement pour savoir comment fonctionne le monde. Ils devront probablement être pris en compte lors de la construction d'un modèle capable de prédire correctement l'avenir. Pourquoi devrions-nous être en mesure de prédire l'avenir de la production pétrolière si le prix du pétrole et du coronavirus n'est toujours pas prévisible? Mais alors, pourquoi et partout: pour prendre les bonnes décisions.

Dans le cas du champ, nous ne pouvons pas observer directement ce qui se passe sous terre entre les puits. Presque tout ce qui nous est disponible est lié à des puits, c'est-à-dire à des points rares dans les vastes étendues de marais (tout ce que nous pouvons mesurer est contenu dans environ 0,5% de la roche, nous ne pouvons que «deviner» les propriétés des 99,5% restants). Ce sont des mesures prises sur des puits lors de la construction du puits. Ce sont les relevés des instruments installés sur les puits (pression de fond, proportion d'huile, d'eau et de gaz dans le produit). Et ce sont les paramètres mesurés et définis des puits: quand allumer, quand éteindre, à quelle vitesse pomper.
Le bon modèle est celui qui prédit correctement l'avenir. Mais comme l'avenir n'est pas encore venu, et je veux comprendre si le modèle est bon maintenant, alors ils le font: ils mettent toutes les informations factuelles disponibles sur le terrain dans le modèle, conformément aux hypothèses, ils ajoutent leurs suppositions sur des informations inconnues (le slogan «deux géologues - trois opinions »à propos de ces conjectures) et ils simulent les processus de filtrage, de redistribution de la pression qui se sont déroulés sous terre, etc. Le modèle indique quels indicateurs de performance devraient avoir été observés et ils sont comparés aux indicateurs réels observés. En d'autres termes, nous essayons de construire un modèle qui reproduit l'histoire.
En fait, vous pouvez tricher et simplement demander au modèle de produire les données dont vous avez besoin. Mais, premièrement, il est impossible de faire cela, et deuxièmement, ils le remarqueront de toute façon (experts dans les agences étatiques mêmes où le modèle doit être remis).
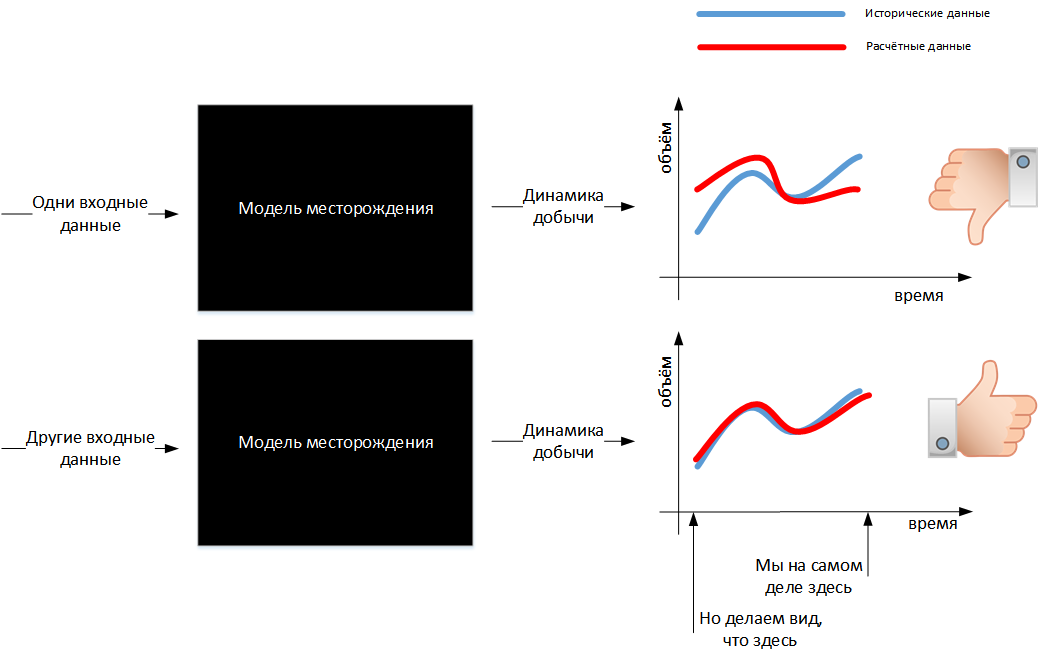
Si le modèle ne peut pas reproduire l'histoire, ses entrées doivent être modifiées, mais lesquelles? Les données réelles ne peuvent pas être modifiées: c'est le résultat de l'observation et de la mesure de la réalité - des données provenant d'appareils. Les appareils, bien sûr, ont leur propre erreur, et les appareils sont utilisés par des personnes qui peuvent également bousiller et mentir, mais l'incertitude des données réelles dans le modèle est généralement faible. Il est possible et nécessaire de changer ce qui présente la plus grande incertitude: nos hypothèses sur ce qui se passe entre les puits. En ce sens, la construction d'un modèle est une tentative de réduire l'incertitude dans notre connaissance de la réalité (en mathématiques, ce processus est connu comme la résolution d'un problème inverse, et des problèmes inverses dans notre région - comme les vélos à Pékin!).
Si le modèle reproduit suffisamment correctement l'histoire, nous avons l'espoir que notre connaissance de la réalité, intégrée dans le modèle, ne diffère pas beaucoup de cette réalité même. Ce n'est qu'à ce moment-là que nous pourrons lancer un tel modèle de prévision, et nous aurons plus de raisons de croire à une telle prévision.
Et s'il était possible de faire non pas un, mais plusieurs modèles différents qui reproduisent tous assez bien l'histoire, mais en même temps donnent une prévision différente? Nous n'avons pas d'autre choix que de vivre avec cette incertitude, de prendre des décisions en ayant cela à l'esprit. De plus, ayant plusieurs modèles donnant un éventail de prévisions possibles, on peut essayer de quantifier les risques de prendre une décision, tout en ayant un modèle, on restera dans une confiance injustifiée que tout se passera comme le modèle le prédit.
Modèles dans la vie du terrain
Afin de prendre des décisions dans le processus de développement d'un champ, vous avez besoin d'un modèle holistique de l'ensemble du champ. De plus, sans un tel modèle, il est désormais impossible de développer un domaine: un tel modèle est requis par les organes gouvernementaux de la Fédération de Russie.

Tout commence par un modèle sismique, qui est créé par les résultats de l'exploration sismique. Un tel modèle permet de «voir» des surfaces tridimensionnelles souterraines - des couches spécifiques à partir desquelles les ondes sismiques sont bien réfléchies. Il ne donne presque aucune information sur les propriétés dont nous avons besoin (porosité, perméabilité, saturation, etc.), mais montre comment certaines couches se plient dans l'espace. Si vous avez fait un sandwich à plusieurs couches, puis que vous l'avez plié (enfin, ou que quelqu'un s'est assis dessus), vous avez toutes les raisons de croire que toutes les couches se sont pliées à peu près de la même manière. Par conséquent, nous pouvons comprendre comment le gâteau de couches a été courbé à partir de divers sédiments attaquant le fond de l'océan, même si nous ne voyons qu'une seule des couches du modèle sismique, qui, par chance, reflète bien les ondes sismiques. À ce stade, les ingénieurs en science des données ont relancé,parce que la sélection automatique de ces horizons réfléchissants dans un cube, c'est ce que les participants de l'un de nosLes hackathons sont un problème classique de reconnaissance de formes.
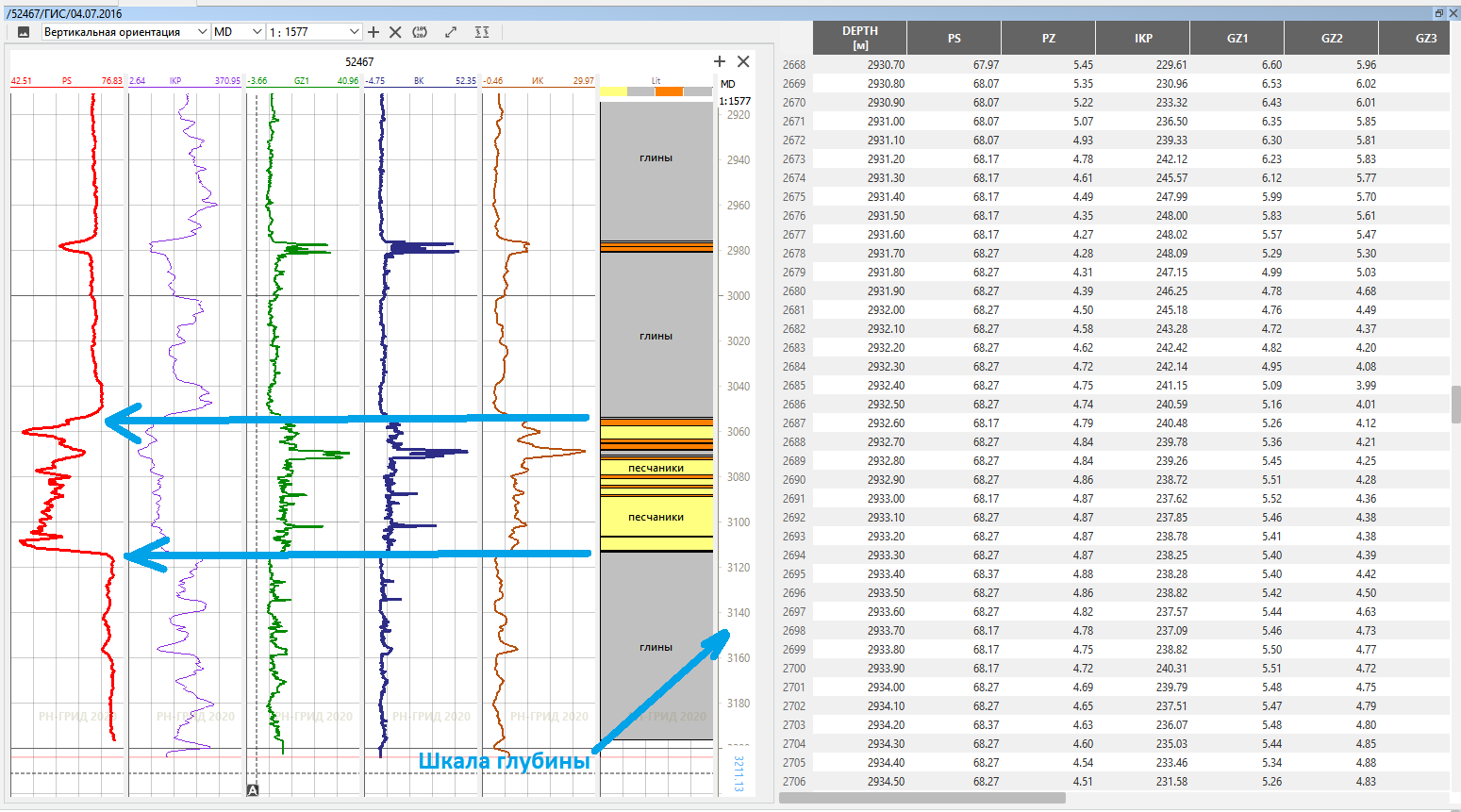
Ensuite, le forage exploratoire commence, et au fur et à mesure que les puits sont forés, les instruments sont abaissés sur un câble pour mesurer toutes sortes d'indicateurs différents le long du puits, c'est-à-dire qu'ils effectuent des SIG (levés géophysiques des puits). Le résultat d'une telle étude est la diagraphie, c'est-à-dire une courbe d'une certaine quantité physique mesurée avec un certain pas le long du puits de forage. Différents instruments mesurent différentes quantités, et des ingénieurs formés interprètent ensuite ces courbes pour obtenir des informations significatives. Un instrument mesure la radioactivité gamma naturelle de la roche. L'argile «fonit» est plus forte, le grès «fonit» est plus faible - tout ingénieur-interprète le sait et le met en évidence sur la courbe de diagraphie: ici il y a des argiles, ici une couche de grès, ici quelque chose entre les deux. Un autre appareil mesure le potentiel électrique naturel entre des points voisins,résultant de la pénétration de fluide de forage dans la roche. Un potentiel élevé indique la présence d'un lien de filtration entre les points du réservoir, l'ingénieur connaît et confirme la présence de roche perméable. Le troisième appareil mesure la résistance du fluide saturant la roche: l'eau salée passe le courant, le pétrole ne passe pas le courant - et vous permet de séparer les roches saturées en huile des roches saturées en eau, etc.
À ce stade, les ingénieurs en science des données ont repris connaissance, car les données d'entrée pour ce problème sont de simples courbes numériques, et le remplacement de l'interpréteur par un modèle ML qui peut tirer une conclusion sur les propriétés de la roche au lieu d'un ingénieur utilisant la forme d'une courbe signifie résoudre le problème de classification classique. Ce n'est qu'à ce moment-là que les ingénieurs en science des données ont commencé à se tordre les yeux quand il s'est avéré que certaines de ces courbes accumulées à partir de vieux puits n'étaient que sous la forme de longues nappes en papier.
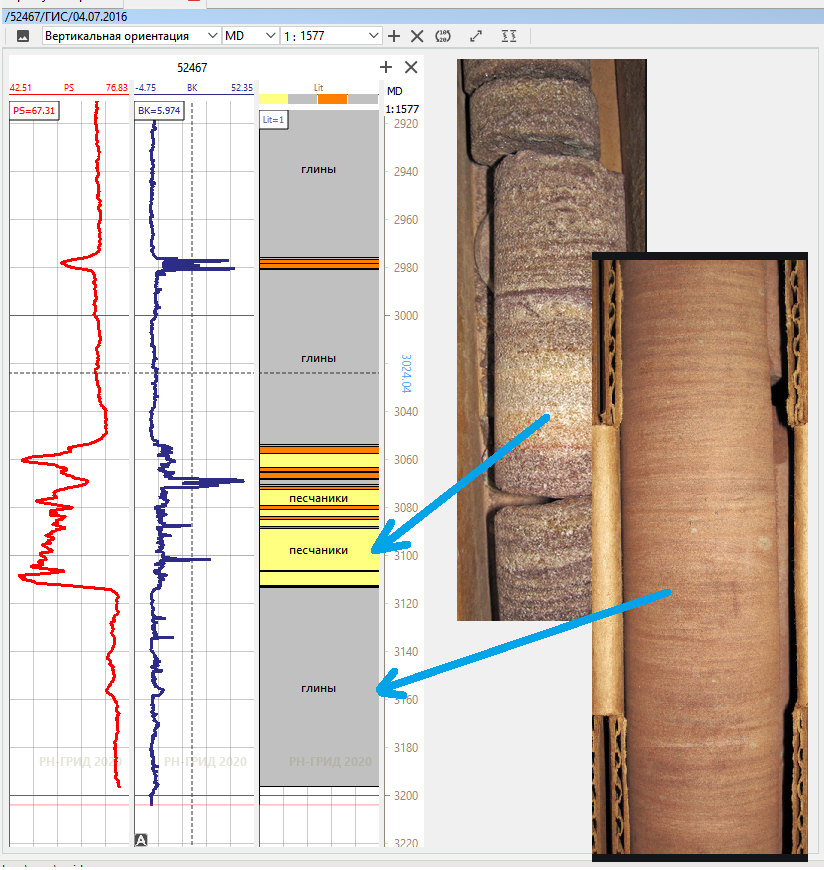
De plus, pendant le forage, une carotte est prélevée du puits - des échantillons de roche plus ou moins intacte (si chanceuse) et non perturbée pendant le forage. Ces échantillons sont envoyés au laboratoire, où ils déterminent leur porosité, perméabilité, saturation et toutes sortes de propriétés mécaniques différentes. Si l'on sait (et si cela est fait correctement) à partir de quelle profondeur un carotte spécifique a été prélevée, alors quand les données du laboratoire arriveront, il sera possible de comparer quelles valeurs à cette profondeur ont été montrées par tous les instruments géophysiques et quelles valeurs de porosité, perméabilité et La roche avait une saturation à cette profondeur selon les recherches du laboratoire principal. Ainsi, il est possible de «cibler» les lectures d'instruments géophysiques et ensuite uniquement à partir de leurs données, sans avoir de noyau, de tirer une conclusion sur les propriétés de la roche dont nous avons besoin pour construire un modèle. Tout le diable est dans les détails:Les instruments ne mesurent pas exactement ce qui est déterminé en laboratoire, mais c'est une histoire complètement différente.
Ainsi, après avoir foré plusieurs puits et effectué des recherches, nous pouvons affirmer en toute confiance quelle roche et avec quelles propriétés se trouve là où ces puits ont été forés. Le problème est que nous ne savons pas ce qui se passe entre les puits. Et c'est là que le modèle sismique vient à notre secours.

Dans les puits, nous savons exactement quelles sont les propriétés de la roche à quelle profondeur, mais nous ne savons pas comment les couches de roche observées dans les puits se propagent et se plient entre elles. Le modèle sismique ne nous permet pas de déterminer avec précision quelle couche est située à quelle profondeur, mais il montre avec confiance la nature de la propagation et de la flexion de toutes les couches à la fois, la nature de la litière. Ensuite, les ingénieurs marquent certains points caractéristiques sur les puits, en plaçant des marqueurs à une certaine profondeur: sur ce puits à cette profondeur - le haut de la formation, à cette profondeur - le bas. Et la surface du haut et du bas entre les puits, grosso modo, est dessinée parallèlement à la surface que l'on voit dans le modèle sismique. Le résultat est un ensemble de surfaces tridimensionnelles qui couvrent l'espace qui nous intéresse, et nous nous intéressons bien sûr aux formations contenant du pétrole. Cette,ce qui s'est passé s'appelle un modèle structurel, car il décrit la structure du réservoir, mais pas son contenu interne. Le modèle structurel ne dit rien sur la porosité et la perméabilité, la saturation et la pression à l'intérieur du réservoir.
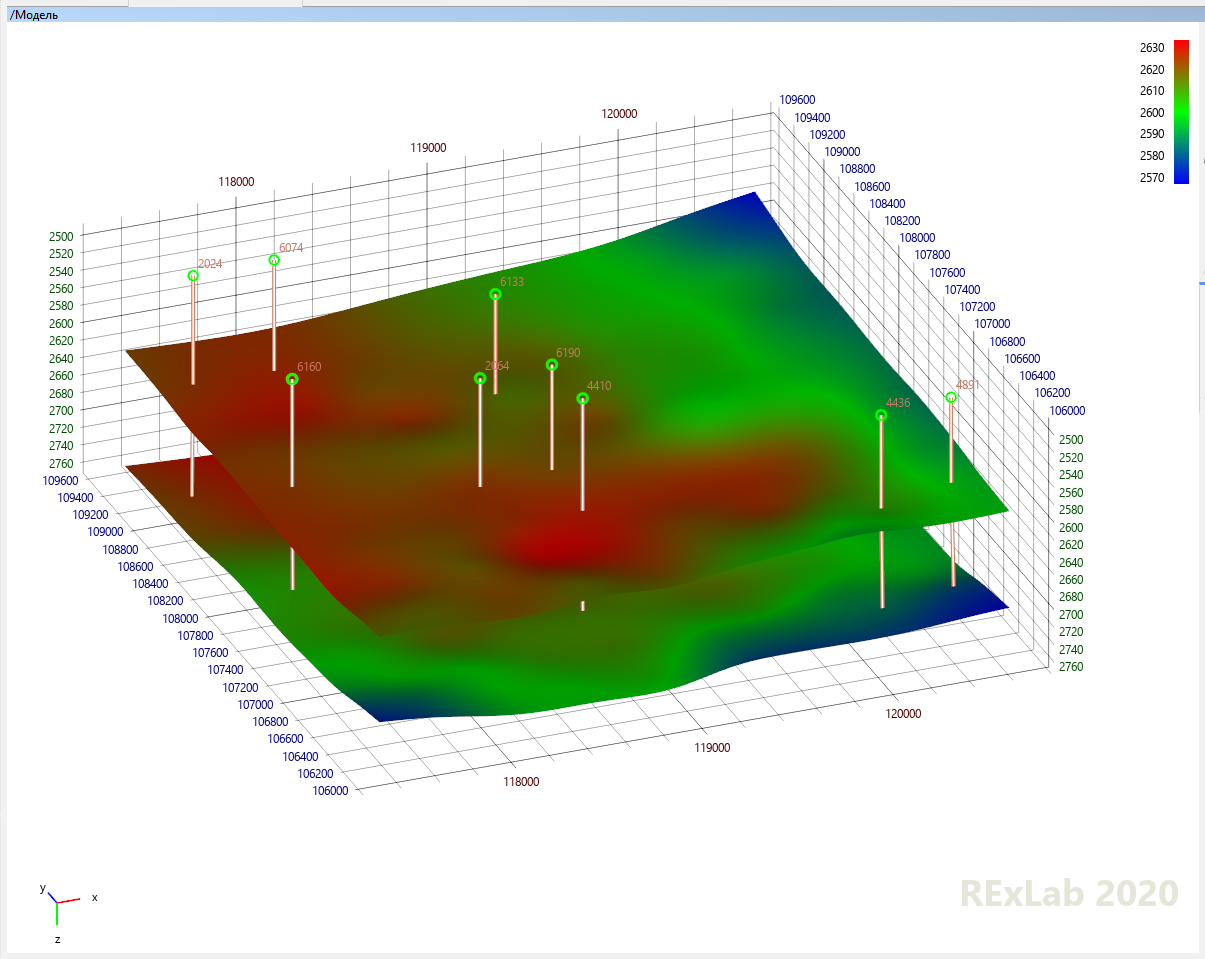
Vient ensuite l'étape de la discrétisation, dans laquelle la zone d'espace occupée par le champ est divisée en un tel parallélépipède incurvé de cellules (dont la nature est visible même sur le modèle sismique!). Chaque cellule de ce parallélépipède courbe est identifiée de manière unique par trois nombres, I, J et K.Toutes les couches de ce parallélépipède courbe se trouvent en fonction de la distribution des couches, et le nombre de couches en K et le nombre de cellules en I et J est déterminé par le détail que nous pouvons nous permettre.
Combien d'informations détaillées sur la roche avons-nous le long du puits de forage, c'est-à-dire verticalement? Aussi détaillé que la fréquence à laquelle le dispositif géophysique mesurait sa taille en se déplaçant le long du puits de forage, c'est-à-dire en règle générale tous les 20 à 40 cm, chaque couche peut donc mesurer 40 cm ou 1 m.
Dans quelle mesure nos informations latérales sont-elles détaillées, c'est-à-dire éloignées du puits? Pas combien: nous n'avons aucune information sur le côté du puits, donc il n'y a généralement aucun intérêt à se diviser en très petites cellules le long de I et J, et le plus souvent elles sont à 50 ou 100 m le long des deux coordonnées. Le choix de la taille de ces cellules est l'un des défis techniques importants.
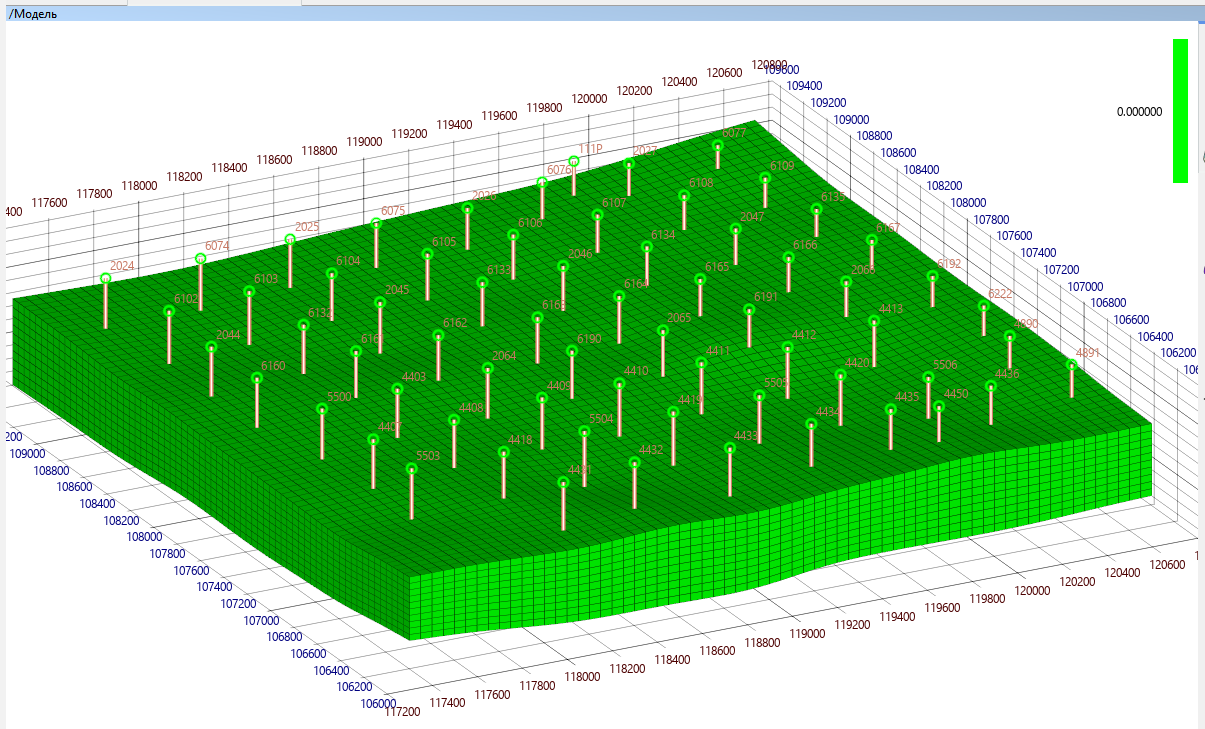
Une fois que toute la surface de l'espace est divisée en cellules, la simplification attendue est effectuée: dans chaque cellule, la valeur de l'un des paramètres (porosité, perméabilité, pression, saturation, etc.) est considérée comme constante. Bien sûr, ce n'est pas le cas en réalité, mais comme on sait que le dépôt de sédiments sur le fond de la mer s'est fait par couches, les propriétés de la roche vont changer beaucoup plus verticalement qu'horizontalement.
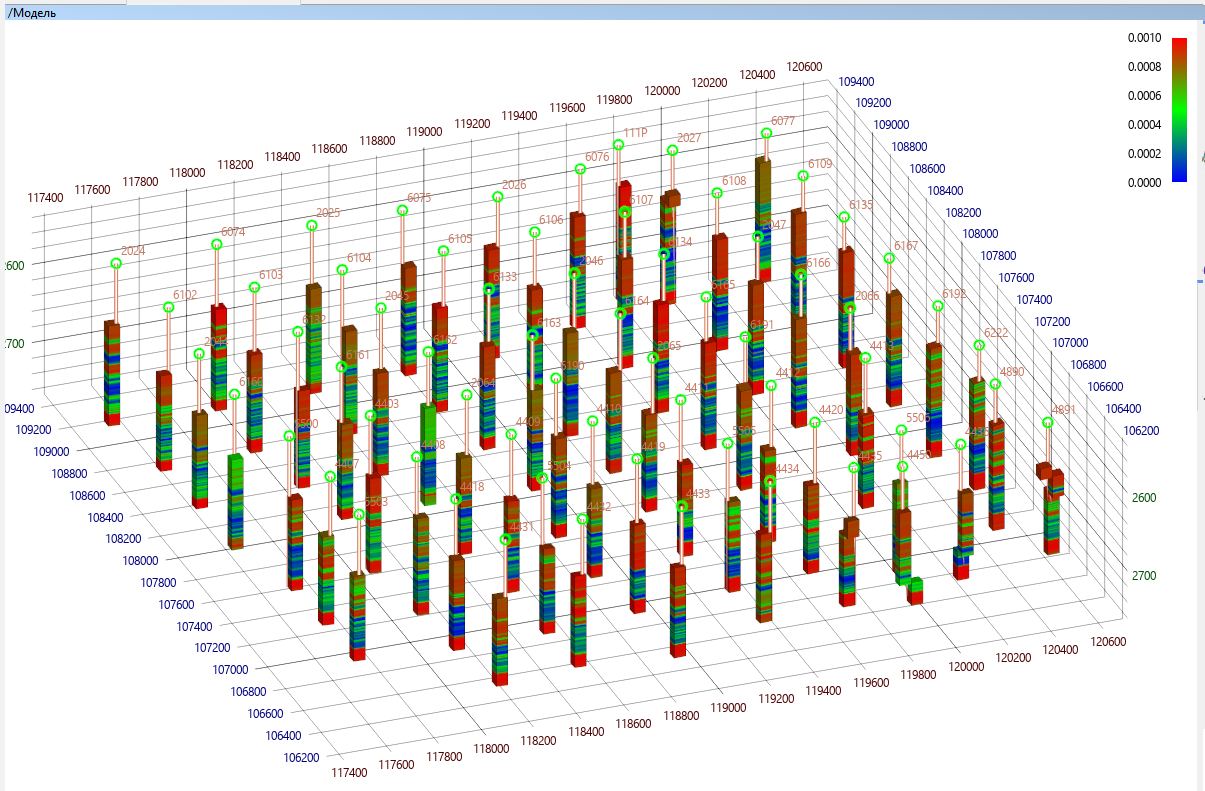
Donc, nous avons une grille de cellules, chaque cellule a sa propre valeur (inconnue de nous) de chacun des paramètres importants décrivant à la fois la roche et sa saturation. Jusqu'à présent, cette grille est vide, mais les puits traversent certaines cellules, dans lesquelles nous avons passé le dispositif et obtenu les valeurs des courbes des paramètres géophysiques. Les ingénieurs en interprétation, à l'aide d'études de laboratoire, de corrélations, d'expérience et d'une telle mère, convertissent les valeurs des courbes des paramètres géophysiques en valeurs des caractéristiques de la roche et du fluide saturant dont nous avons besoin, et transfèrent ces valeurs du puits aux cellules de la grille à travers lesquelles ce puits passe. Le résultat est une grille qui, à certains endroits, a des valeurs dans les cellules, mais dans la plupart des cellules, il n'y a toujours pas de valeurs. Les valeurs de toutes les autres cellules devront être imaginées en utilisant l'interpolation et l'extrapolation. L'expérience d'un géologue, sa connaissance dela manière dont les propriétés de la roche sont généralement propagées vous permet de sélectionner les algorithmes d'interpolation corrects et de renseigner correctement leurs paramètres. Mais en tout cas, vous devez vous rappeler que tout cela n'est que spéculation sur l'inconnu qui se trouve entre les puits, et ce n'est pas pour rien qu'ils disent, encore une fois cette vérité commune, je vous rappelle que deux géologues auront trois opinions différentes sur le même gisement.
Le résultat de ce travail sera un modèle géologique - un parallélépipède incurvé tridimensionnel, divisé en cellules, décrivant la structure du champ et plusieurs tableaux tridimensionnels de propriétés dans ces cellules: le plus souvent, ce sont des tableaux de porosité, de perméabilité, de saturation et de l'attribut "grès" - "argile".
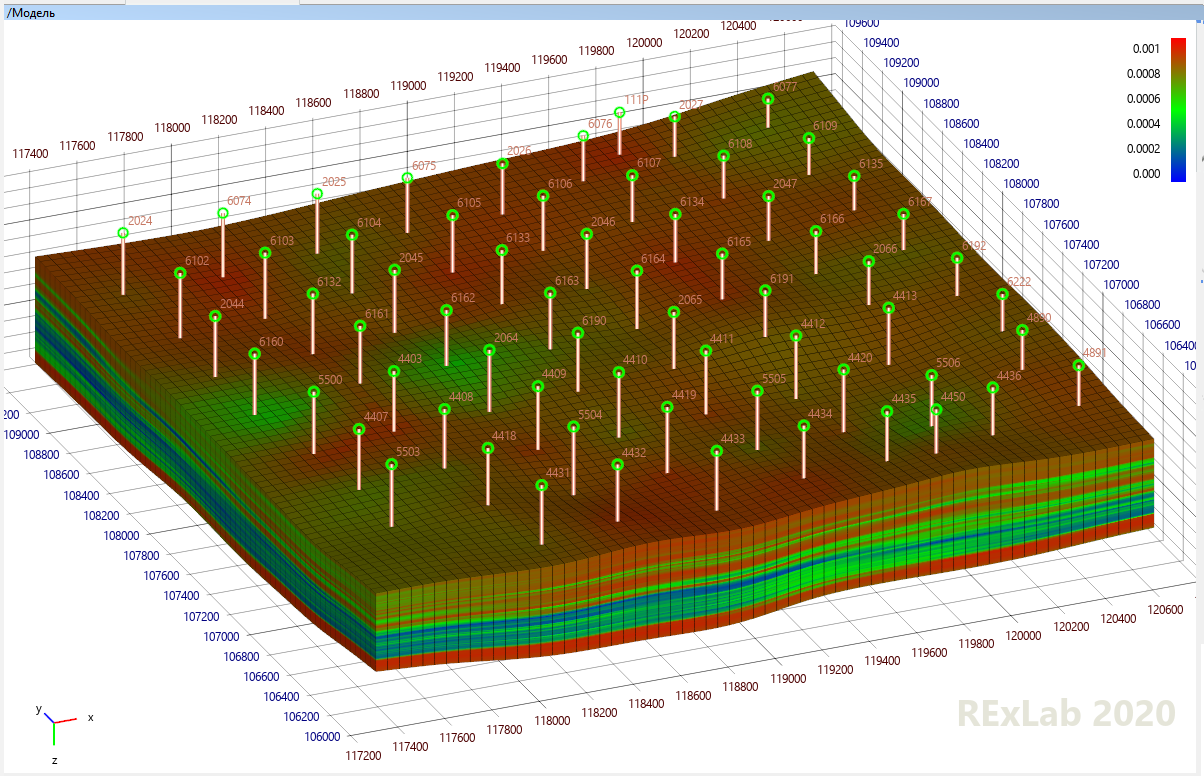
Ensuite, des spécialistes en hydrodynamique reprennent le travail. Ils peuvent agrandir le modèle géologique en combinant plusieurs couches verticalement et en recalculant les propriétés de la roche (c'est ce qu'on appelle «l'upscaling» et c'est un défi distinct). Ensuite, ils ajoutent le reste des propriétés nécessaires pour que le simulateur hydrodynamique puisse simuler ce qui s'écoulera où: en plus de la porosité, de la perméabilité, de l'huile, de l'eau, de la saturation en gaz, ce seront la pression, la teneur en gaz, etc. Ils ajouteront des puits au modèle et entreront des informations sur eux pour savoir quand et dans quel mode ils ont travaillé. Avez-vous oublié que nous essayons de reproduire l'histoire pour espérer une prévision correcte? L'hydrodynamique prendra les rapports du laboratoire et ajoutera au modèle les propriétés physico-chimiques du pétrole, de l'eau, du gaz et de la roche,toutes leurs dépendances (le plus souvent sur la pression) et tout ce qui s'est avéré, et ce sera un modèle hydrodynamique, seront envoyés à un simulateur hydrodynamique. Il calculera honnêtement à partir de quelle cellule tout va couler à quel moment, donnera des graphiques d'indicateurs technologiques pour chaque puits et les comparera scrupuleusement avec des données historiques réelles. Le haut-parleur hydrodynamique poussera un soupir, regardant leur divergence, et ira changer tous les paramètres incertains qu'il essaie de deviner pour que la prochaine fois qu'il démarre le simulateur, il obtienne quelque chose de proche des données réelles observées. Ou peut-être la prochaine fois que vous commencerez. Ou peut-être le suivant et ainsi de suite.émettra des graphiques d'indicateurs technologiques pour chaque puits et les comparera méticuleusement avec des données historiques réelles. Le haut-parleur hydrodynamique poussera un soupir, regardant leur divergence, et ira changer tous les paramètres incertains qu'il essaie de deviner pour que la prochaine fois qu'il démarre le simulateur, il obtienne quelque chose de proche des données réelles observées. Ou peut-être la prochaine fois que vous commencerez. Ou peut-être la prochaine fois, et ainsi de suite.Il produira des graphiques d'indicateurs technologiques pour chaque puits et les comparera soigneusement avec des données historiques réelles. L'ingénieur hydrodynamique soupira, en regardant leur divergence, et va changer tous les paramètres indéfinis qu'il essaie de deviner afin que la prochaine fois que le simulateur soit lancé, il obtiendra quelque chose de proche des données réellement observées. Ou peut-être au prochain départ. Ou peut-être la prochaine fois, et ainsi de suite.
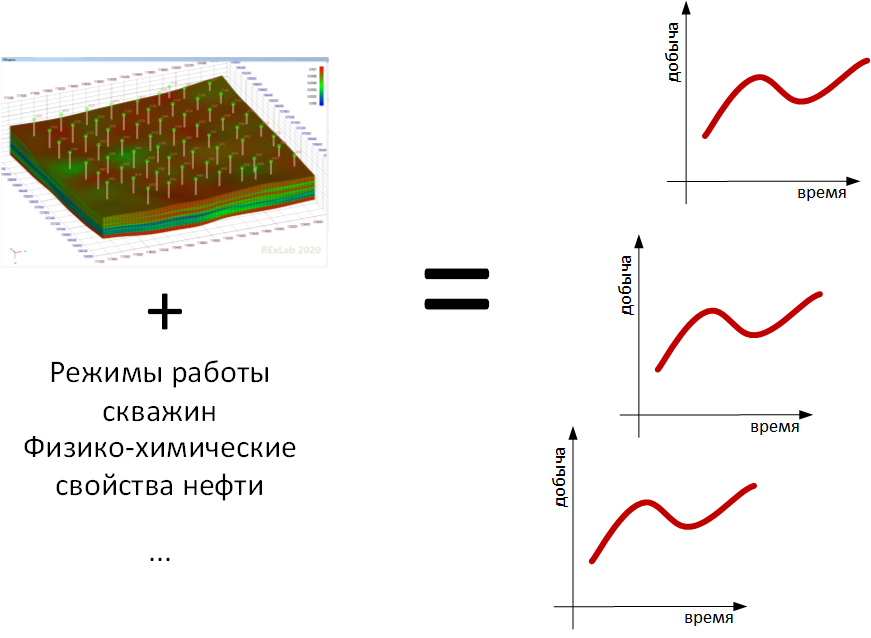
L’ingénieur préparant le modèle de disposition de surface prendra les débits que le champ produira en fonction des résultats de la simulation et les mettra dans son modèle, qui calculera quel pipeline aura quelle pression et si le système de pipeline existant peut «digérer» la production du champ: nettoyer le produit huile, préparez le volume requis d'eau injectée et ainsi de suite.
Et enfin, au plus haut niveau, au niveau du modèle économique, l'économiste calculera le flux de dépenses pour la construction et l'entretien des puits, l'électricité pour le fonctionnement des pompes et des pipelines et le flux de revenus de la livraison du pétrole extrait au réseau de pipelines, multiplier par le degré de coefficient d'actualisation souhaité et obtenir la VAN totale à partir d'un projet de développement de terrain terminé.
La préparation de tous ces modèles, bien sûr, nécessite l'utilisation active de bases de données pour stocker les informations, de logiciels d'ingénierie spécialisés qui implémentent le traitement de toutes les informations d'entrée et la modélisation elle-même, c'est-à-dire prédire l'avenir à partir du passé.
Pour construire chacun des modèles ci-dessus, un produit logiciel distinct est utilisé, le plus souvent bourgeois, souvent pratiquement incontesté et donc très coûteux. De tels produits se développent depuis des décennies et répéter leur chemin avec l'aide d'une petite institution n'est pas une tâche facile. Mais les dinosaures n'étaient pas mangés par d'autres dinosaures, mais par de petits furets affamés et déterminés. L'important est que, comme dans le cas d'Excel, seulement 10% des fonctionnalités sont nécessaires pour le travail quotidien, et nos doublons, comme ceux de Strugatsky, seront "seulement ceux qui savent cela ... - mais ils savent comment bien le faire" juste ces 10%. En général, nous sommes pleins d'espoirs pour lesquels nous avons déjà certains motifs.
Cet article ne décrit qu'un seul, le chemin du pilier du cycle de vie du modèle de l'ensemble du domaine, et il existe déjà une place pour les développeurs de logiciels, et avec les modèles de tarification actuels, les concurrents ont suffisamment de travail pendant longtemps. Dans le prochain article, il y aura un spin-off
À suivre…